个你应该用用看的用于文本分类的最新开源预训练模型
作者:PURVA HUILGOL
编译:ronghuaiyang
英文原文: https://www.analyticsvidhya.com/blog/2020/03/6-pretrained-models-text-classification/
导读: 文本分类是 NLP 的基础任务之一,今天给大家介绍 6 个最新的预训练模型,做 NLP 的同学一定要用用看。
介绍
我们正站在语言和机器的交汇处。我对这个话题很感兴趣。机器能写得和莎士比亚一样好吗?如果一台机器可以提高我自己的写作技能呢?机器人能听懂讽刺的话吗?
我相信你以前问过这些问题。自然语言处理(NLP)的另一目的是为了回答这些问题,我必须说,在这个领域已经有了突破性的研究成果来拉近人和机器之间的差距了。

NLP 的核心思想之一是文本分类。如果机器可以区分名词和动词,或者如果它可以通过评论检测客户是否对产品满意,我们可以使用这种理解能力用在其他高级 NLP 等任务上,比如上下文理解,或者生成一个全新的故事!
这就是我们看到很多关于文本分类的研究的主要原因。是的,迁移学习的出现无疑帮助加速了研究。现在,我们可以使用在大型数据集上构建的预训练的模型,并对其进行调优,以实现不同数据集上的其他任务。
迁移学习和预训练的模型有两个主要优势:
- 它降低了训练新的深度学习模型的成本
- 这些数据集是被行业接受的标准,因此预训练的模型在质量方面已经得到了检验
你可以看到为什么预训练的模特越来越受欢迎。我们看到的谷歌 BERT 和 OpenAI 的 GPT-2 在这方面就做的很好。在本文中,我将介绍 6 种最先进的文本分类预训练模型。
我们的文本分类预训练模型包括:
- XLNet
- ERNIE
- Text-to-Text Transfer Transformer (T5)
- Binary Partitioning Transfomer (BPT)
- Neural Attentive Bag-of-Entities (NABoE)
- Rethinking Complex Neural Network Architectures
预训练模型 #1: XLNet
说到最先进的预训练模型,就不能不提 XLNet!
谷歌的最新模型,XLNet 在 NLP 的主要任务上比如文本分类,情感分析,问答,以及自然语言推理上都达到最先进的水平。不仅仅在文本分类上击败了 BERT,还包括高级的 NLP 任务。
XLNet 的核心思想是:
- 语言理解的广义自回归预训练
- Transformer-XL
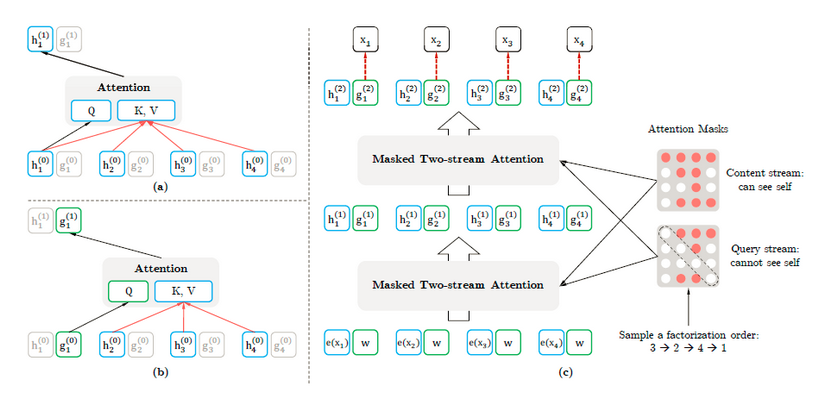
如果这听起来很复杂,不要担心!我会用简单的语言来解释。
自回归建模使用问题中缺失单词之前或之后的上下文单词来预测下一个单词。但是,我们不能同时处理向前和向后两个方向。
尽管 BERT 的自动编码器确实解决了这方面的问题,但它也有其他的缺点,比如假设 mask 掉的单词之间没有相关性。为了解决这个问题,XLNet 提出了一种称为排列语言建模的技术。这种技术使用排列来同时从正向和反向产生信息。
众所周知,Transformer 结构是一个改变游戏规则的工具。XLNet 使用 Transformer XL。正如我们所知,Transformer 替代了递归神经网络(RNN),允许不相邻的 tokens 同时进行处理。这提高了对文本中长距离关系的理解。Transformer-XL 基本上是 BERT 中使用的 Transformer 的增强版,增加了两个组件:
- 特定片段的递归,给出两个序列之间的上下文
- 一种相对位置的嵌入,它包含两个 tokens 之间的相似性信息
如前所述,XLNet 几乎在所有任务(包括文本分类)上都优于 BERT,并且在其中 18 个任务上实现了 SOTA 的性能!下面是对文本分类任务的总结,以及 XLNet 如何在这些不同的数据集上执行,以及它在这些数据集上取得的高排名:
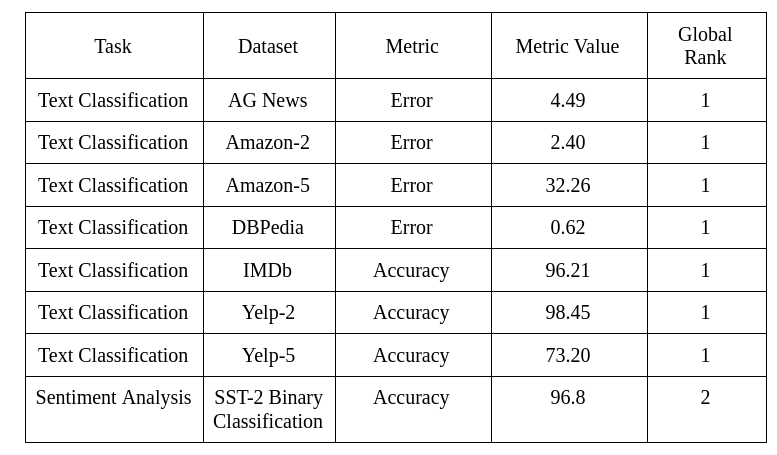
- 论文链接: XLNet: Generalized Autoregressive Pretraining for Language Understanding
- GitHub 链接: https://github.com/zihangdai/xlnet
预训练模型 #2: ERNIE
尽管 ERNIE 1.0(发布于 2019 年 3 月)一直是文本分类的流行模式,但在 2019 年下半年,ERNIE 2.0 成为了热门话题。ERNIE 由科技巨头百度开发,在英语 GLUE 基准测试中,它的表现超过了谷歌 XLNet 和 BERT。
ERNIE 的意思是 Enhanced Representation through kNowledge IntEgration,ERNIE 2.0 是 ERNIE 1.0 的升级版。ERNIE 1.0 在它自己的方式上是开创性的 —— 它是第一个利用知识图谱的模型之一。这种集成进一步增强了高级任务的训练模型,如关系分类和命名实体识别(NER)。
与之前的版本一样, ERNIE 2.0 带来了另一项创新,即递增的多任务学习。基本上,这意味着模型已经定义了 7 个明确的任务,并且
- 可以同时生成多个任务的输出。例如,完成句子“I like going to New…”—>“I like going to New York”,并将其归类为有积极情绪的句子。合并任务的损失也相应计算。
- 递增地使用前一个任务的输出到下一个任务。例如,将 Task 1 的输出作为 Task 1、Task 2 的训练,为此,Task 1 和 Task 2 用于训练 Task 1、Task 2 和 Task 3……等等。
我真的很喜欢这个过程,非常的直观,因为它遵循了人类理解文本的方式。我们的大脑不仅认为“I like going to New York”是一个积极情绪的句子,是不是?它同时理解了名词“New York”和“I”,理解了“like”这个动词,并推断出 New York 是一个地方。
ERNIE 在关系提取任务中获得了 88.32 的 SOTA 的****F1-Score
- 论文链接: https://arxiv.org/pdf/1905.07129v3.pdf
- GitHub 链接: https://github.com/thunlp/ERNIE
预训练模型 #3: Text-to-Text Transfer Transformer (T5)
说实话,与其他模型相比,研究这个模型最有趣。谷歌新的 Text-to-Text Transfer Transformer (T5)模型使用 Transfer learning 来完成各种 NLP 任务。
最有趣的部分是它将每个问题转换为文本输入—文本输出模型。因此,即使对于分类任务,输入也将是文本,输出也将是单词而不是标签。这可以归结为所有任务上的一个模型。不仅如此,一个任务的输出可以用作下一个任务的输入。
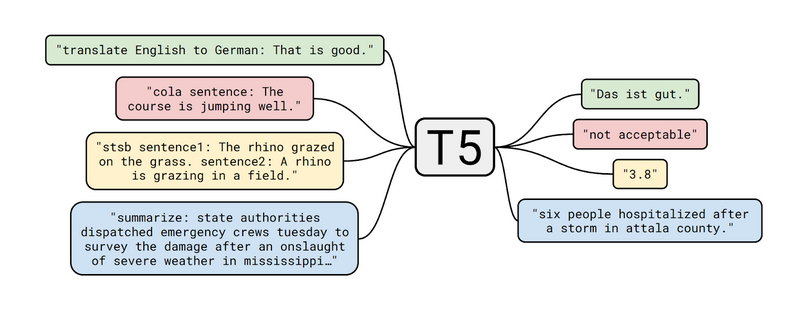
语料库使用普通抓取的增强版本。基本上就是从 Web 上抓取文本。这篇论文强调了清理数据的重要性,并清楚地说明了这是如何做到的。虽然抓取的数据每个月生成 20TB 的数据,但是大部分数据并不适合 NLP 任务。
即使只保留文本内容(包含标记、代码内容等的页面已被删除),语料库的大小仍然高达 750GB,比大多数数据集大得多。
注意:这也已经在 TensorFlow 上发布了: https://www.tensorflow.org/datasets/catalog/c4
要执行的任务被编码为输入的前缀。正如你在上面的图表中所看到的,不管是分类还是回归任务,T5 模型仍然会生成新的文本来获得输出。
T5 在超过 20 个已建立的 NLP 任务上实现了 SOTA —— 这是很少见的,看看指标,它和人类的输出非常接近。
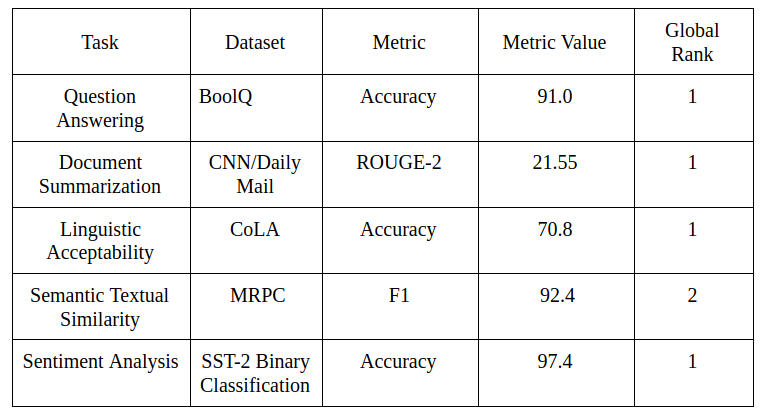
T5 模型跟随了最近的趋势,对未标注的数据进行了训练,然后对标注文本进行微调。可以理解的是,这个模型是巨大的,但是可以看到对它进行进一步的研究,缩小这个模型是非常有趣的,可以让它得到更广泛的使用。
- 论文链接: https://arxiv.org/pdf/1910.10683.pdf
- GitHub 链接: https://github.com/googl-research/text-to-text-transfer-transformer
预训练模型 #4: Binary-Partitioning Transformer (BPT)
正如我们到目前为止所看到的,Transformer architecture 在 NLP 研究中非常流行。BP Transformer 再次使用 Transformer,或者更确切地说,使用它的一个增强版本来进行文本分类,机器翻译等等。
然而,使用 Transformer 仍然是一个昂贵的过程,因为它使用了自注意力机制。自注意只是指我们对句子本身进行注意力操作,而不是两个不同的句子。自注意力有助于识别一句话中单词之间的关系。正是这种自注意力的机制导致了使用 Transformer 的成本。
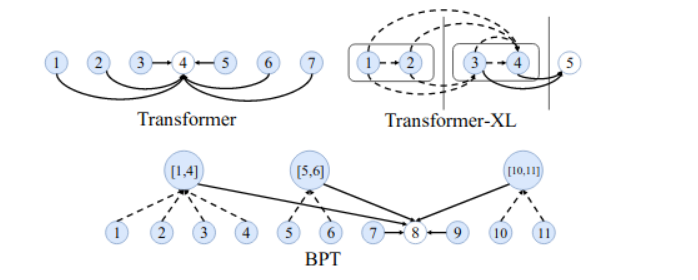
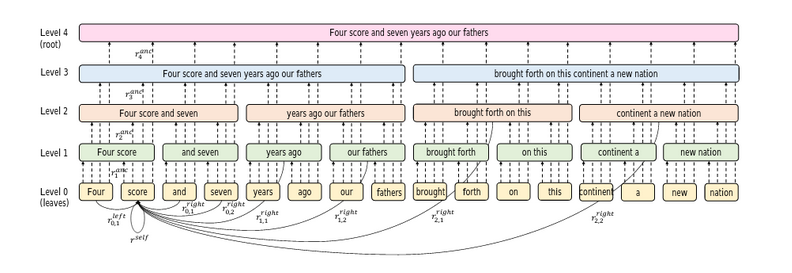
Binary-Partitioning Transformer (BPT)将 Transformer 视为一个图神经网络,旨在提高自注意力机制的效率。本质上,这个图中的每个节点表示一个输入 token。
BP Transformer 的工作原理如下:
第一步:递归地把句子分成两部分,直到达到某个停止条件。这称为二元分区。例如,“I like going to New York”这句话有以下几个部分:
- I like going; to New York
- I like; going; to New; York
- I; like; going; to; New; York
注意:一个包含 n 个单词的句子会有 2 n - 1 个分区,最后,你会得到一个完整的二叉树。*
第二步:每个分区现在都是图神经网络中的一个节点。有两种类型的边:
- 连接父节点及其子节点的边
- 连接叶节点与其他节点的边
第三步:对图中相邻节点的每个节点进行自注意力:
BPT 达到了:
- 在中英机器翻译上达到了 SOTA 的成绩(BLEU 评分:19.84)
- IMDb 数据集情绪分析的准确率为 92.12(结合 GloVE embedding)
我很欣赏这个模型,因为它让我重新审视了图的概念,让我敢于去研究图神经网络。我承认我来晚了,但在不久的将来,我一定会在图神经网络上进行更多的探索!
- 论文链接: https://arxiv.org/pdf/1911.04070v1.pdf
- GitHub 链接: https://github.com/yzh119/BPT
预训练模型 #5: Neural Attentive Bag-of-Entities Model for Text Classification (NABoE)
神经网络一直是最受欢迎的 NLP 任务模型,它们的表现优于传统的模型。此外,在构建语料库知识库的同时,用单词代替实体,也改善了模型 de 学习。
这意味着我们不是从语料库中的单词构建词汇表,而是使用实体链接构建大量实体。虽然已有研究将语料库表示为模型,但 NABoE 模型更进一步:
- 使用神经网络来检测实体
- 使用注意力机制来计算被检测实体的权重(这决定了这些实体与文档的相关性)
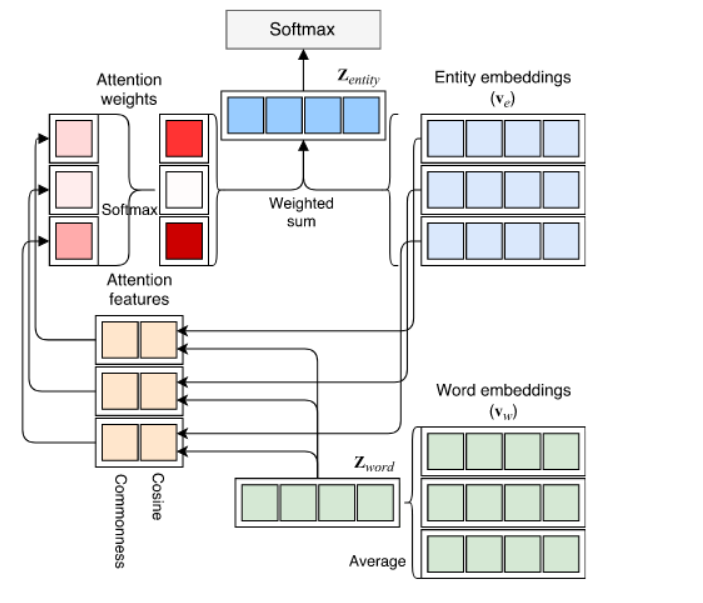
实体模型的神经注意包使用 Wikipedia 语料库来检测与单词相关的实体。例如,单词“Apple”可以指水果、公司和其他可能的实体。检索所有这些实体后,使用基于 softmax 的注意力函数计算每个实体的权重。这提供了只与特定文档相关的实体的一个更小的子集。
最后,通过向量嵌入和与词相关的实体的向量嵌入,给出了词的最终表示。
NABoE 模型在文本分类任务中表现得特别好:
!
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E4%B8%AA%E4%BD%A0%E5%BA%94%E8%AF%A5%E7%94%A8%E7%94%A8%E7%9C%8B%E7%9A%84%E7%94%A8%E4%BA%8E%E6%96%87%E6%9C%AC%E5%88%86%E7%B1%BB%E7%9A%84%E6%9C%80%E6%96%B0%E5%BC%80%E6%BA%90%E9%A2%84%E8%AE%AD%E7%BB%83%E6%A8%A1%E5%9E%8B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


