为什么机器学习项目非常难管理
英文原文: https://medium.com/@l2k/why-are-machine-learning-projects-so-hard-to-manage-8e9b9cf49641
作者:Lukas Biewald
编译:ronghuaiyang
导读
我看到过很多公司尝试使用机器学习 —— 有些大获成功,有些惨败。一个不变的事实是,机器学习团队很难设定目标和期望。这是为什么呢?
1. 很难预先分辨出什么是难的,什么是容易的
是在国际象棋中击败卡斯帕罗夫更困难,还是捡起棋子并移动棋子更困难?计算机在二十多年前打败了国际象棋世界冠军,但是可靠地抓取和举起物体仍然是一个未解决的研究问题。人类不擅长评估什么对人工智能来说是困难的,什么是容易的。即使在一个领域中,性能也可能有很大差异。预测情绪的准确性有多高?在影评中,有大量的文本和作者很容易搞清楚他们的想法,现在能期待的准确率是90-95%。在推特上,两个人在80%的情况下对一条推文的观点是一致的。在推文中,只要是关于航空公司的,那么总是把这条推文的情绪预测成负面的,就可以达到95%以上的准确率。
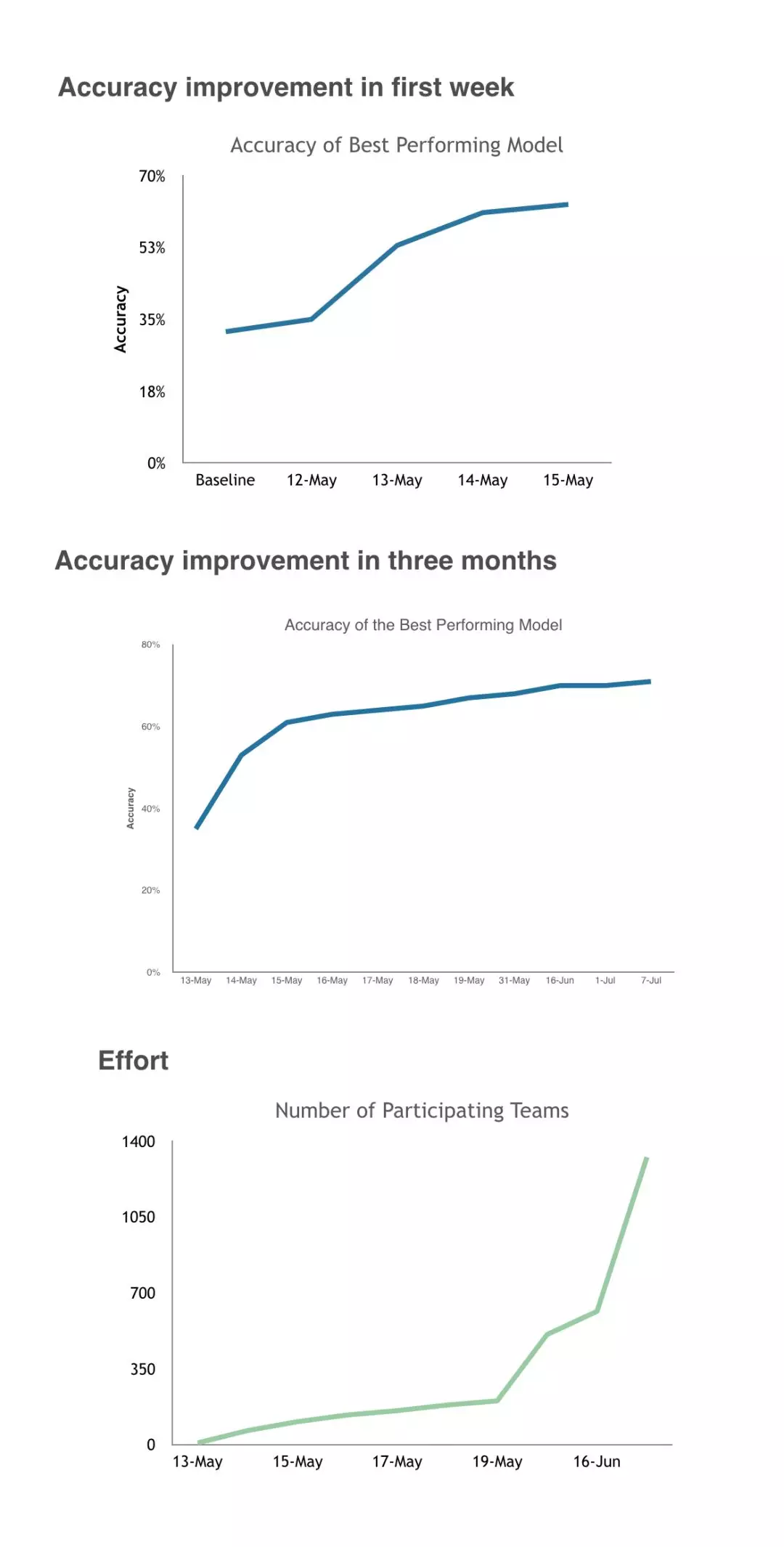
度量标准也可能在项目的早期提升很多,然后突然碰壁。我曾经举办过一场Kaggle竞赛,全世界成千上万的人竞相为我的数据建模。在第一周,准确率从35%上升到65%,但在接下来的几个月里,准确率从未超过68%。68%的准确率显然是数据对于最先进的机器学习技术的限制。那些在Kaggle竞赛中竞争的人非常努力地获得了68%的正确率,我确信这是一个巨大的成就。但在大多数情况下,65%和68%是完全无法区分的。如果这是一个内部项目,我肯定会对结果感到失望。
我的朋友Pete Skomoroch最近告诉我,作为一名研究机器学习的数据科学家,在工程部门工作是多么令人沮丧。工程项目通常会向前推进,但机器学习项目可能会完全停滞。花一周时间对数据进行建模,结果可能(甚至很常见)没有任何改进。
2. 机器学习很容易以意想不到的方式失败.
机器学习通常工作得很好,只要你有大量的训练数据以及你在生产中运行的数据看起来很像你的训练数据。人类非常善于从训练数据中归纳归纳,因此我们对此有着可怕的直觉。我做了一个小机器人,带着摄像机和一个视觉模型,这个模型是根据从网上获取的成百万的ImageNet图像制作的。我对我的机器人相机上的图像进行了预处理,使其看起来像来自网络的图像,但准确性比我预期的要差得多。为什么?网络上的图片往往会针对目标物体进行构图,但是我的机器人不一定会像人类摄影师那样直视一个物体。人类甚至可能都没有注意到这种差异,但使用现代深度学习网络的时候就会非常痛苦。有很多方法可以处理这种现象,但我之所以注意到它,只是因为它的性能下降非常严重,我花了很多时间调试它。
更厉害的是,导致性能下降的细微差异很难被发现。接受《纽约时报》训练的语言模型不能很好地概括社交媒体文本。我们可以预料到。但很显然,从2017年开始接受文本训练的模型,在2018年写的文本中表现不佳。上游分布随时间以多种方式变化。当对手适应了欺诈模型所做的事情时,欺诈模型就会完全崩溃。
3. 机器学习需要大量相关的训练数据.
每个人都知道这一点,但这是一个巨大的障碍。如果你能够收集并标记大�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E4%B8%BA%E4%BB%80%E4%B9%88%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E9%A1%B9%E7%9B%AE%E9%9D%9E%E5%B8%B8%E9%9A%BE%E7%AE%A1%E7%90%86/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


