为什么要使用交叉验证
【AD】如何提升大数据行业影响力?给数据分析网[投稿],辐射50万大数据爱好者!什么是交叉验证法?它的基本思想就是将原始数据(dataset)进行分组,一部分做为训练集来训练模型,另一部分做为测试集来评价模型。
什么是交叉验证法?它的基本思想就是将原始数据(dataset)进行分组,一部分做为训练集来训练模型,另一部分做为测试集来评价模型。
为什么用交叉验证法?
交叉验证用于评估模型的预测性能,尤其是训练好的模型在新数据上的表现,可以在一定程度上减小过拟合。
还可以从有限的数据中获取尽可能多的有效信息。
#主要有哪些方法?
1. 留出法 (holdout cross validation)
在机器学习任务中,拿到数据后,我们首先会将原始数据集分为三部分:训练集、验证集和测试集。
训练集用于训练模型,验证集用于模型的参数选择配置,测试集对于模型来说是未知数据,用于评估模型的泛化能力。
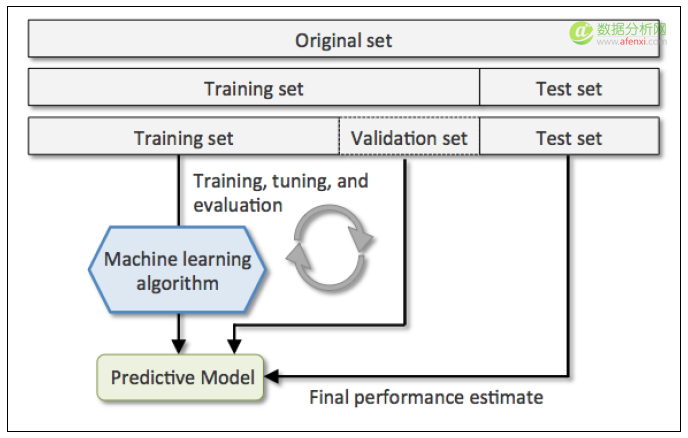
这个方法操作简单,只需随机把原始数据分为三组即可。
不过如果只做一次分割,它对训练集、验证集和测试集的样本数比例,还有分割后数据的分布是否和原始数据集的分布相同等因素比较敏感,不同的划分会得到不同的最优模型,而且分成三个集合后,用于训练的数据更少了。
于是有了 2. k 折交叉验证(k-fold cross validation)加以改进:
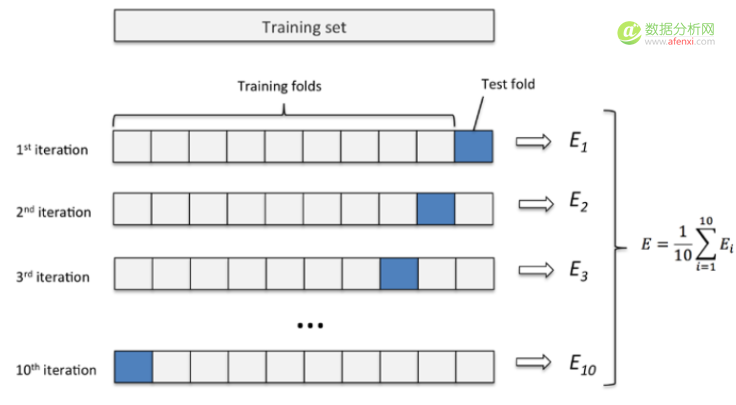
k 折交叉验证通过对 k 个不同分组训练的结果进行平均来减少方差,因此模型的性能对数据的划分就不那么敏感。
-
第一步,不重复抽样将原始数据随机分为 k 份。
-
第二步,每一次挑选其中 1 份作为测试集,剩余 k-1 份作为训练集用于模型训练。
-
第三步,重复第二步 k 次,这样每个子集都有一次机会作为测试集,其余机会作为训练集。
-
在每个训练集上训练后得到一个模型,
-
用这个模型在相应的测试集上测试,计算并保存模型的评估指标,
-
第四步,计算 k 组测试结果的平均值作为模型精度的估计,并作为当前 k 折交叉验证下模型的性能指标。
k 一般取 10, 数据量小的时候,k 可以设大一点,这样训练集占整体比例就比较大,不过同时训练的模型个数也增多。
数据量大的时候,k 可以设小一点。
当 k=m 即样本总数时,叫做 3. 留一法(Leave one out cross validation),每次的测试集都只有一个样本,要进行 m 次训练和预测。
这个方法用于训练的数据只比整体数据集少了一个样本,因此最接近原始样本的分布。
但是训练复杂度增加了,因为模型的数量与原始数据样本数量相同。
一般在数据缺乏时使用。
此外:
-
多次 k 折交叉验证再求均值,例如:10 次 10 折交叉验证,以求更精确一点。
-
划分时有多种方法,例如对非平衡数据可以用分层采样,就是在每一份子集中都保持和原始数据集相同的类别比例。
-
模型训练过程的所有步骤,包括模型选择,特征选择等都是在单个折叠 fold 中独立执行的。
还有一种比较特殊的交叉验证方式, Bootstrapping: 通过自助采样法,即在含有 m 个样本的数据集中,每次随机挑选一个样本,再放回到数据集中,再随机挑选一个样本,这样有放回地进行抽样 m 次,组成了新的数据集作为训练集。
这里会有重复多次的样本,也会有一次都没有出现的样本,原数据集中大概有 36.8% 的�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E4%B8%BA%E4%BB%80%E4%B9%88%E8%A6%81%E4%BD%BF%E7%94%A8%E4%BA%A4%E5%8F%89%E9%AA%8C%E8%AF%81/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


