傅轶网易数帆云原生日志平台架构实践

分享嘉宾:傅轶 网易数帆
编辑整理:张德通 Treelab
出品平台:DataFunTalk
导读: 网易从2015年就开始了云原生的探索与实践,作为可观测性的重要一环,日志平台也经历了从主机到容器的演进,支撑了集团内各业务部门的大规模云原生化改造。本文会讲述在这个过程中我们遇到的问题,如何演进和改造,并从中沉淀了哪些经验与最佳实践。
主要内容包括:
- Operator化的⽇志采集
- ⼤规模场景下的困境与挑战
- 开源Loggie的现在与未来
01 云原⽣最初的探索
Operator化的⽇志采集
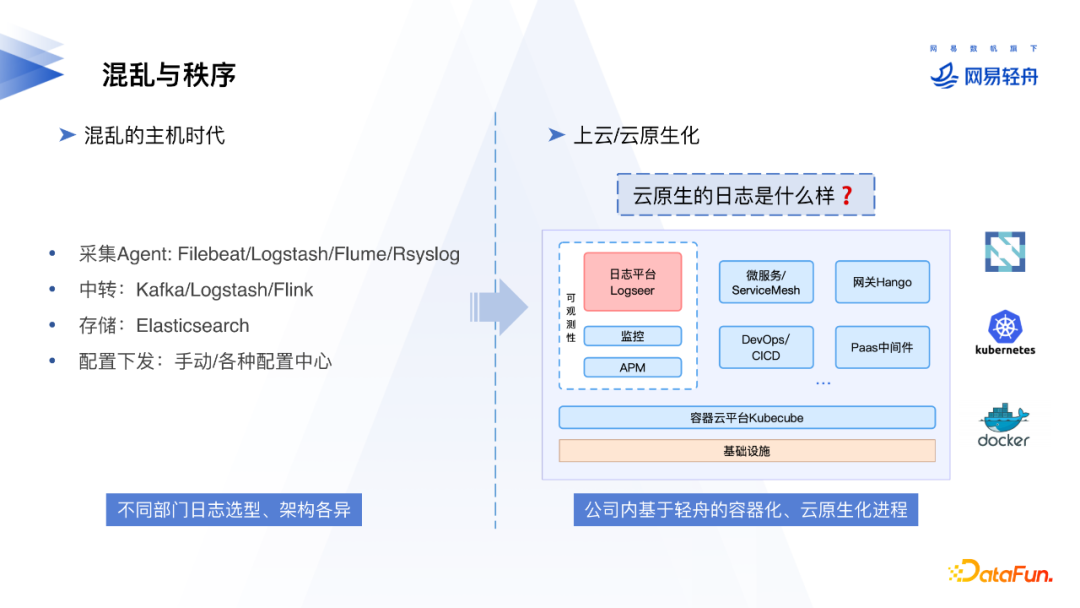
早期公司内部业务跑在物理机上时,各业务使用的日志采集工具、日志中转和存储、配置下发都比较混乱,选型种类多。公司内基于轻舟平台推进了各服务容器化和云原生化,随着服务不断地迁移到K8s上,我们关于采集K8s容器日志和日志平台方面积累很多实践经验。
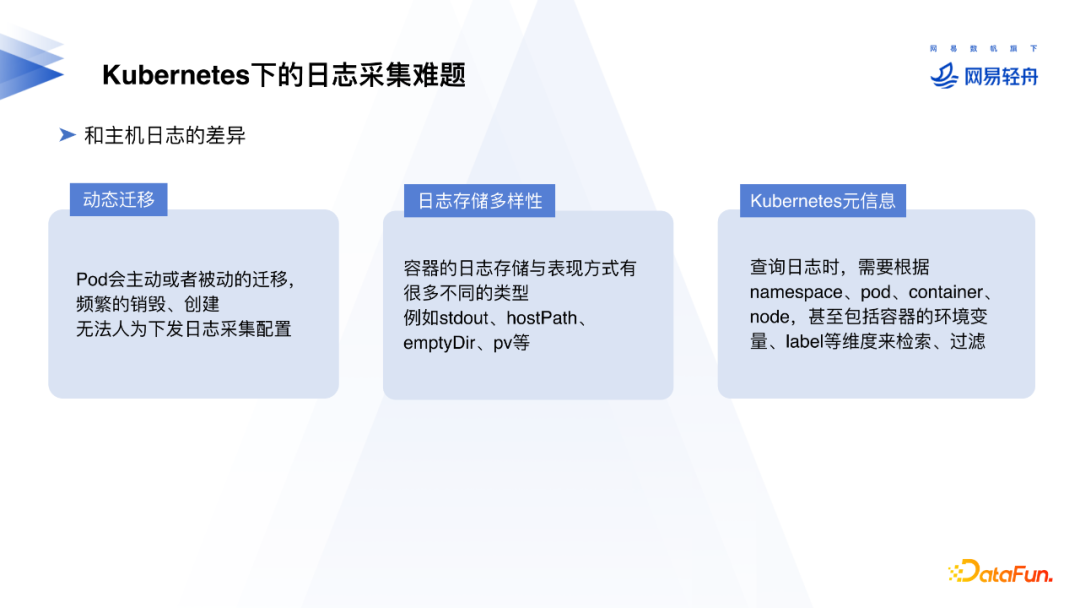
云原生日志是什么样的,容器日志采集和主机上服务的日志采集有什么差异?首先Pod在K8s中会频繁地发生迁移,手动去节点上变更配置日志采集配置不太切实际。 同时,云原生环境中日志存储的形式多样,有容器标准输出和HostPath,EmptyDir,PV等。另外,采集日志后,一般会根据云原生环境的Namespace、Pod、Container、Node甚至容器环境变量、Label等维度进行检索和过滤,这些元信息需要在日志采集时被注入。
常见的云原生环境日志采集有以下三种思路:
1. 只采集标准输出
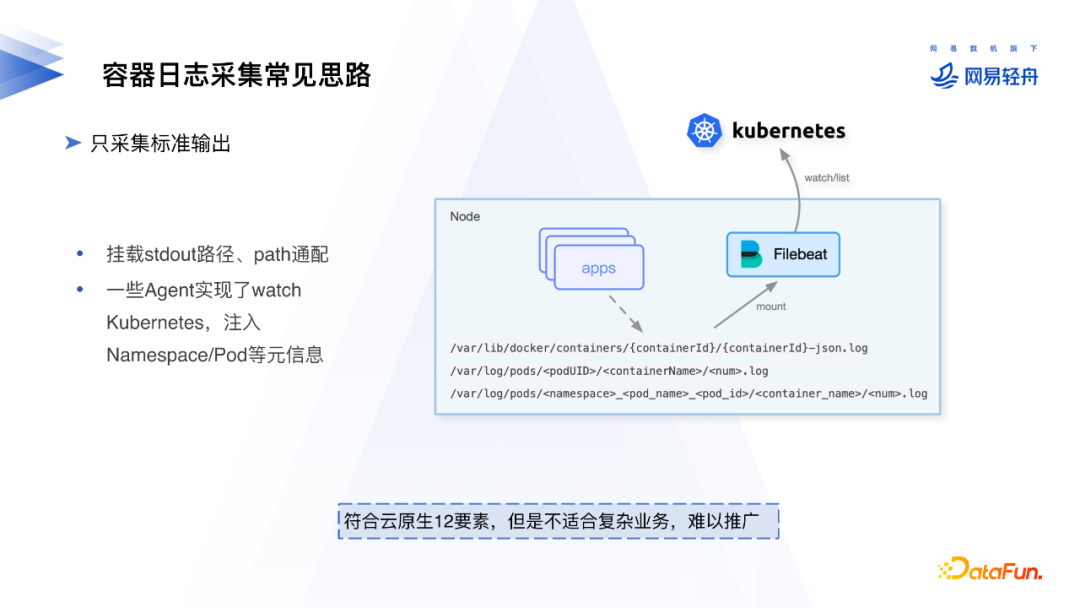
日志打印到标准输出的操作虽然符合云原生十二要素,但是很多业务还是习惯输出到日志文件中,而且只采集标准输出日志难以满足一些复杂业务的需求。常规的采集标准输出日志的方式是挂载/var/lib/docker,/var/log/pods下的目录。同时需要注意选型的日志Agent是否支持注入k8s元信息。
2. Agent⽇志路径全局挂载
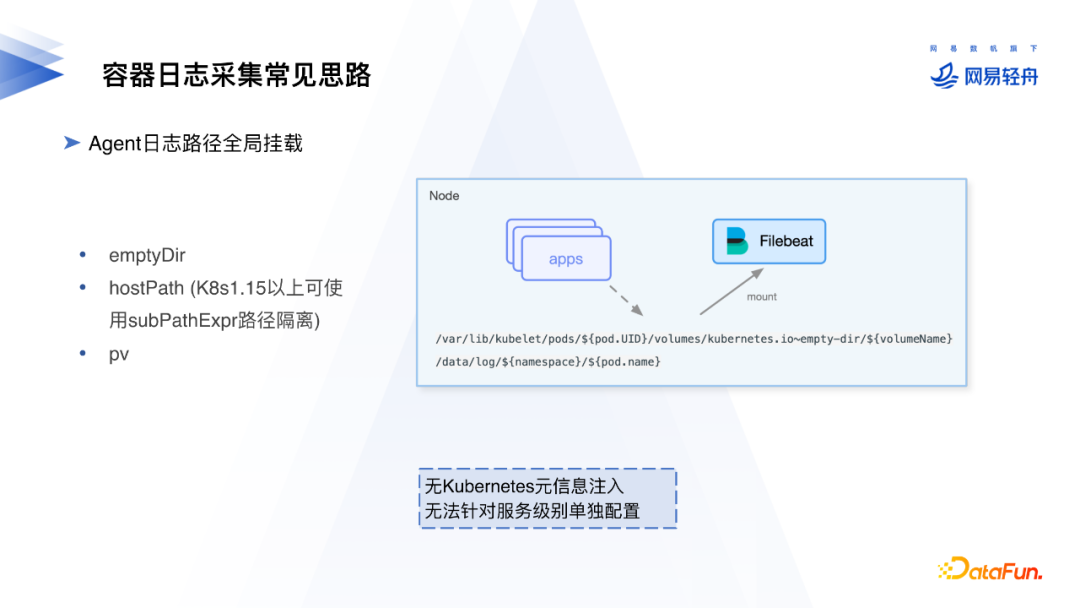
日志可以放在EmptyDir,HostPath或PV存储中,通过DaemonSet方式把日志采集Agent部署到每一台k8s节点上。EmptyDir等存储映射到节点的目录可以通过通配的方式配置到Agent进行采集,由Agent读取配置路径下的日志文件。
但这种通用匹配的方式无法根据服务级别进行单独配置。如果需要配置只采集某些服务的日志、或是某一个应用和其他应用的格式不同,例如某个应用的日志是多行的日志,此时需要单独修改配置,管理成本比较高。
3. Sidecar⽅式
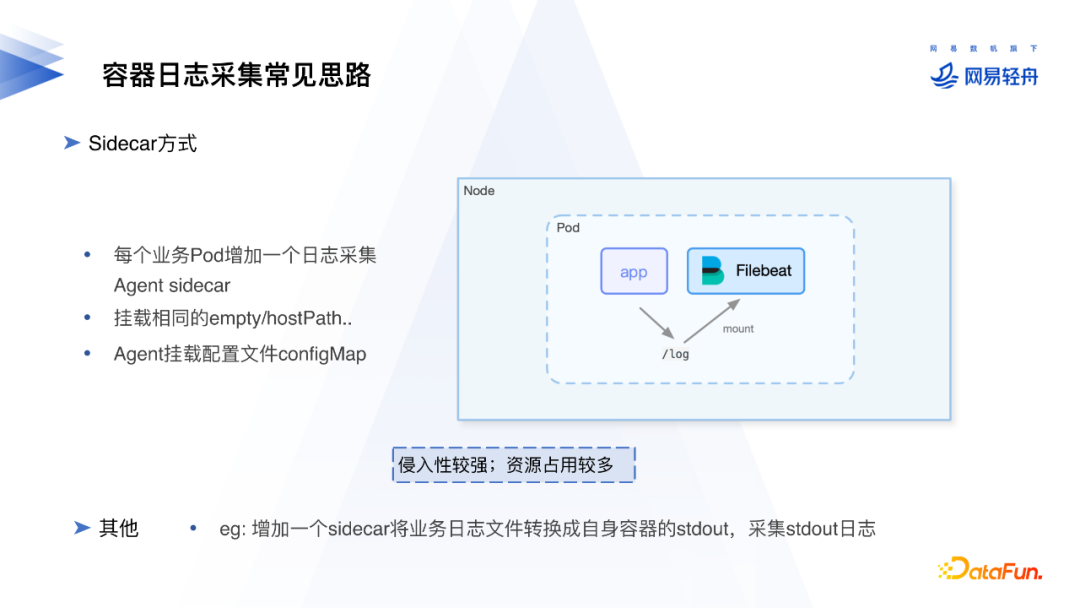
每个业务Pod在部署时都增加一个日志采集的Agent SideCar,可以通过容器平台或k8s webhook的方式把日志采集Agent注入到Pod内。Agent可以通过挂载相同的HostPath或EmptyDir的方式采集到业务容器的日志。
这种方式的弊端是对Pod侵入性强,Pod数量多时资源消耗较大。

对比DaemonSet和SideCar两种部署方式,DaemonSet在稳定性、侵入性、资源占用方面有优势,但隔离性、性能方面SideCar方式更好。我们实践中会优先使用DaemonSet方式采集日志。如果某个服务日志量较大、吞吐量较高,可以考虑为该服务的Pod配置Sidecar方式采集日志。
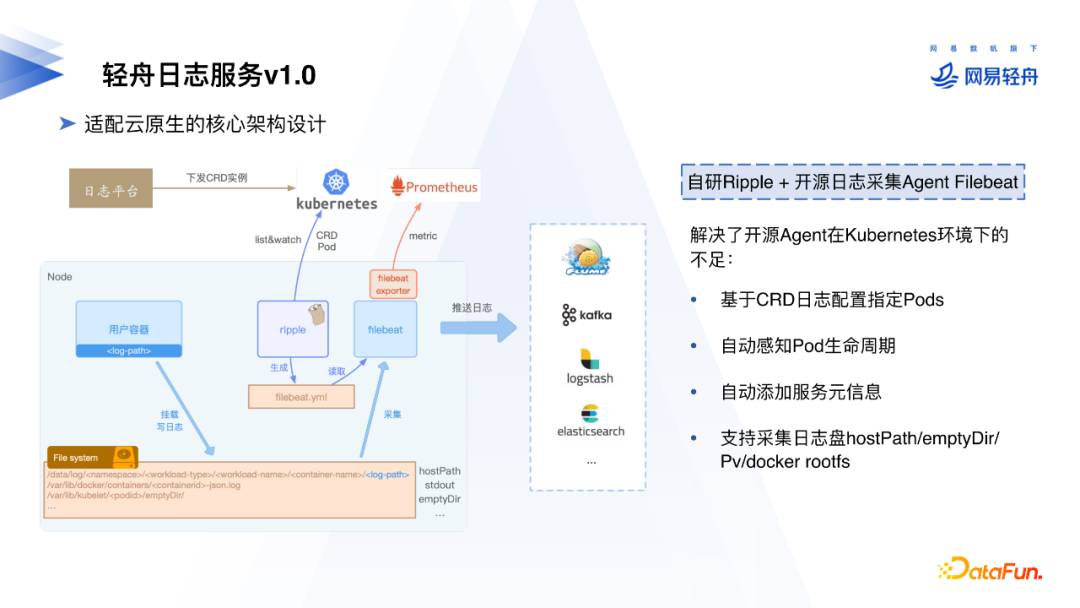
针对日志采集方面的痛点,我们提出的第一个初步方案是:自研的Ripple Operator配合开源的日志采集客户端Filebeat进行业务日志采集。
部署方面,FileBeat、Ripple通过SideCar方式部署在一起,Ripple监听k8s。在使用方面,用户通过CRD,一个CRD可以表示一个服务的日志采集配置,Ripple可以和k8s交互感知到Pod生命周期。Ripple可以下发配置到Agent,自动添加Pod相关元信息并注入到日志中。存储方面HostPath、EmptyDir、PV、Docker Rootfs都可以支持。
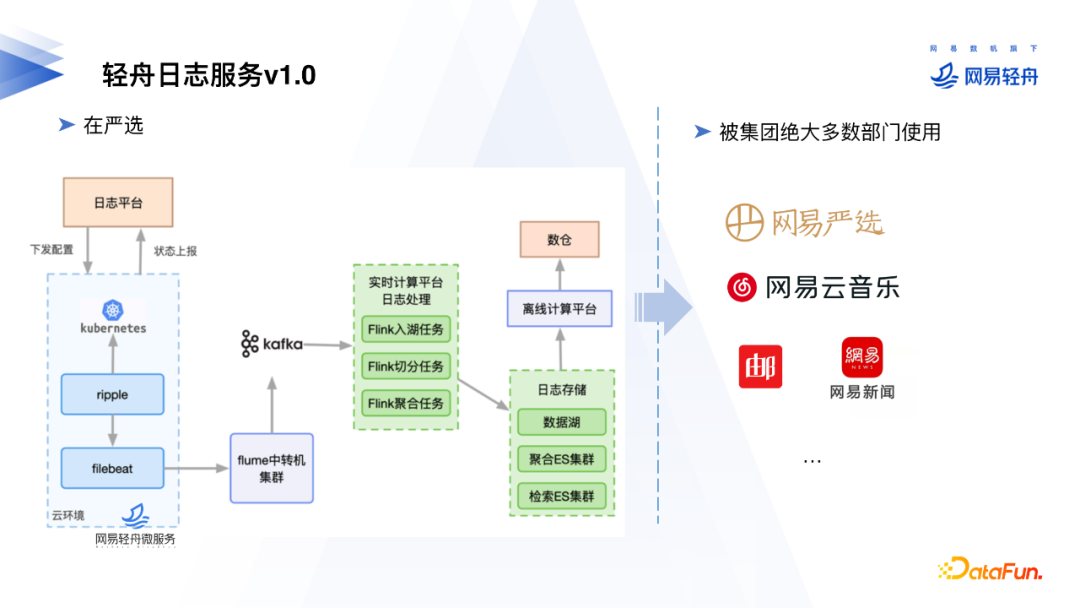
图中日志采集的架构先在网易严选进行了应用, 后面逐渐地被公司内绝大多数部门参考落地,具体架构会根据实际环境有所区别。首先日志平台下发配置,Ripple监听到K8s的CRD配置变动后,把配置下发给Filebeat。Filebeat把采集到的日志发送到中转机,中转机发送给Kafka,Flink消费Kafka数据进行处理后转发给后端日志存储。
02 进⼊深⽔区
⼤规模场景下的困境与挑战
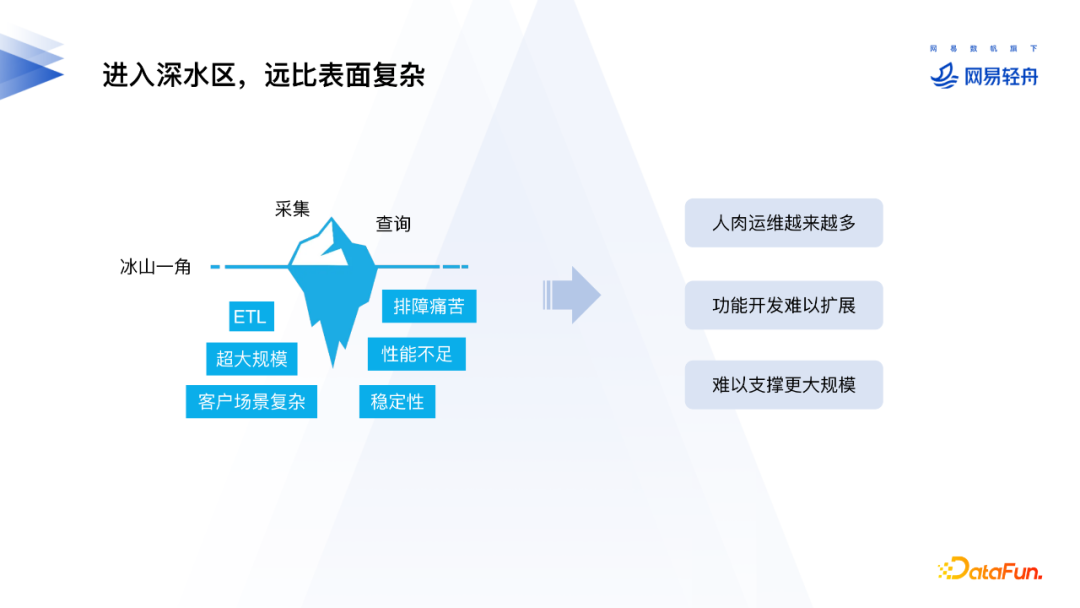
随着接入的业务越来越多,1.0版本的日志架构逐渐暴露了一些问题:超大规模下系统的稳定性问题、日志平台性能问题、排障困难和排障需求不断增多、维护人力成本直线升高等。
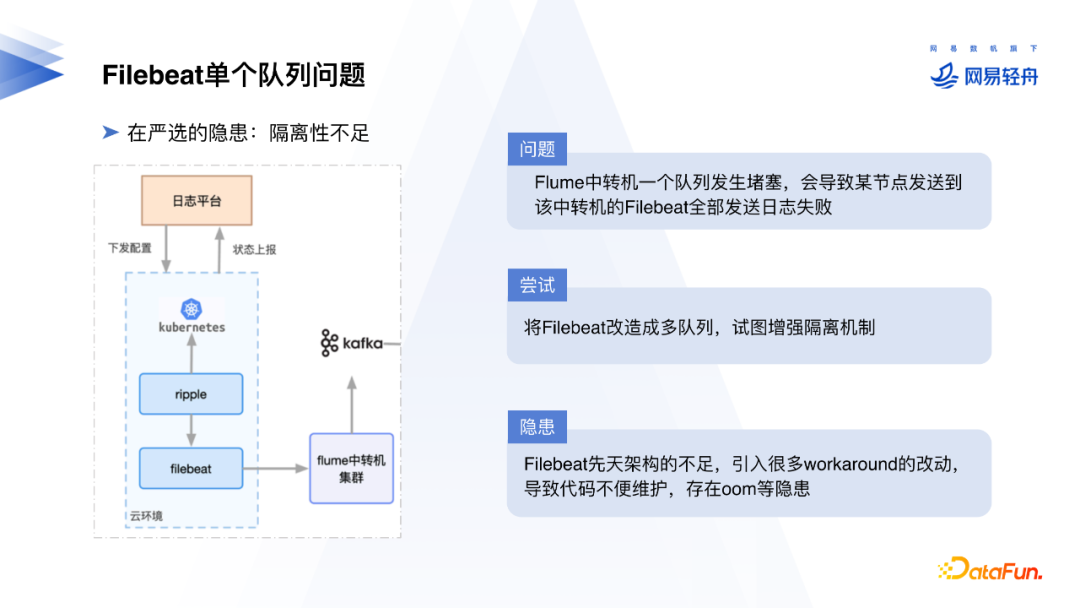
在前面介绍的架构中,Filebeat会把每个服务的日志发送给中转机。但是Filebeat是一个单一的队列架构,在中转机的阻塞会影响整个节点的Filebeat日志上报。
我们尝试把Filebeat改造成多队列的模式增强隔离性,但是由于Filebeat本身的设计架构局限,重构的效果和运行状态都不理想,同时与开源版本的维护和升级存在很大困难。
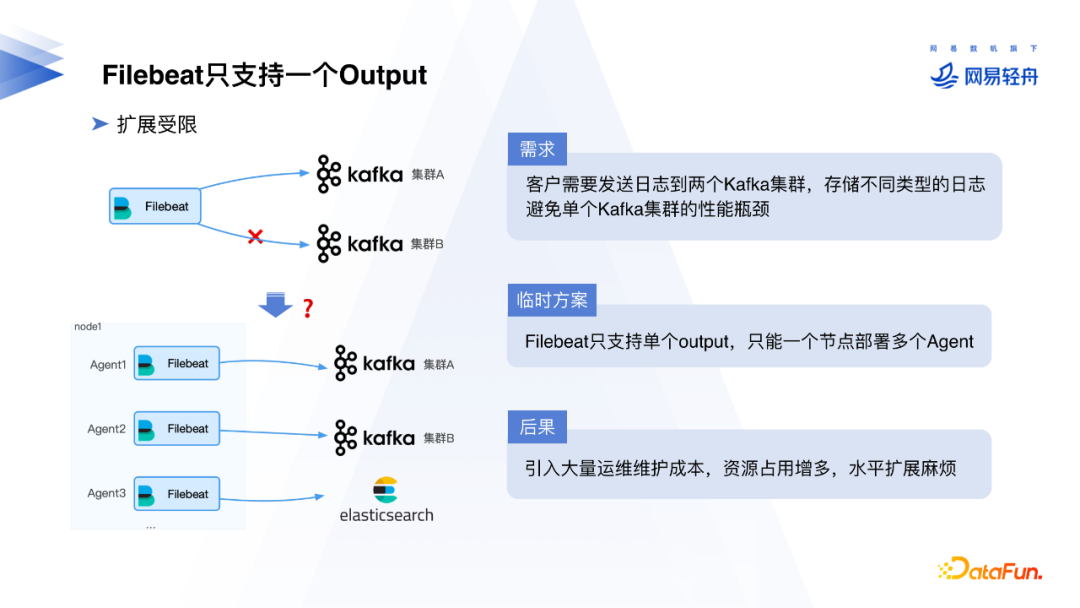
Filebeat只支持单个Output,当用户需要把日志发送到多个Kafka集群时,只能在同一个节点上部署多个Filebeat。导致运维成本高、计算资源消耗大、水平扩展困难。
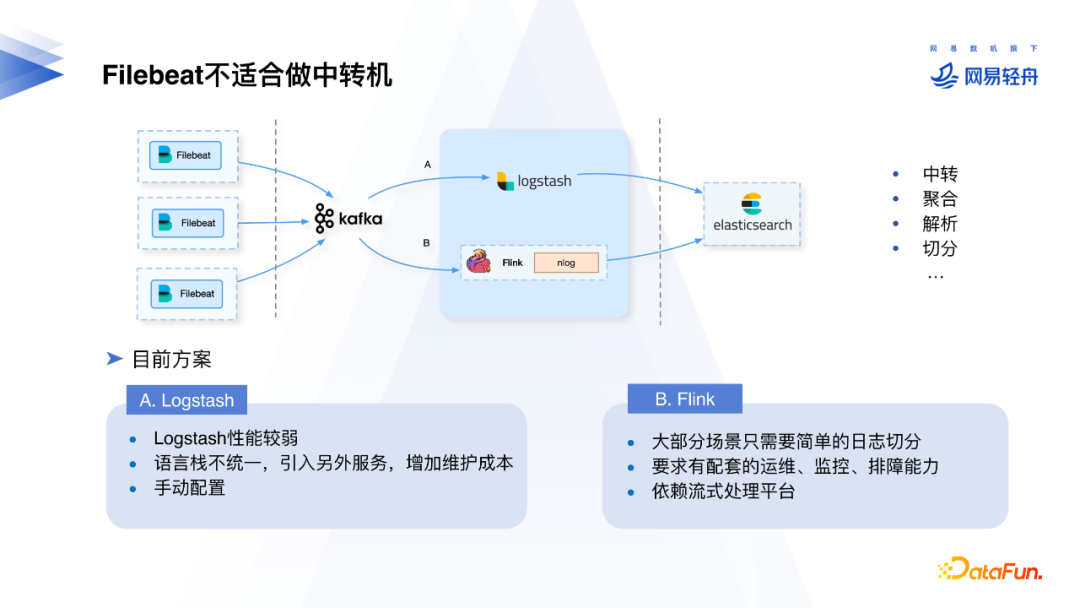
Filebeat设计之初是为了解决Logstash的问题,作为轻量级的日志采集端运行,不适合作为中转。Logstash在日志切分、解析等方面表现出色,但是问题在于性能较弱。虽然Flink性能和表现出色,但我们的很多场景只需要简单的日志切分,Flink一般依赖流式处理基础平台的支持,同时在交付过程中用户要额外付出Flink的机器和运维成本,所以我们需要一个更轻量、成本更低的方案。
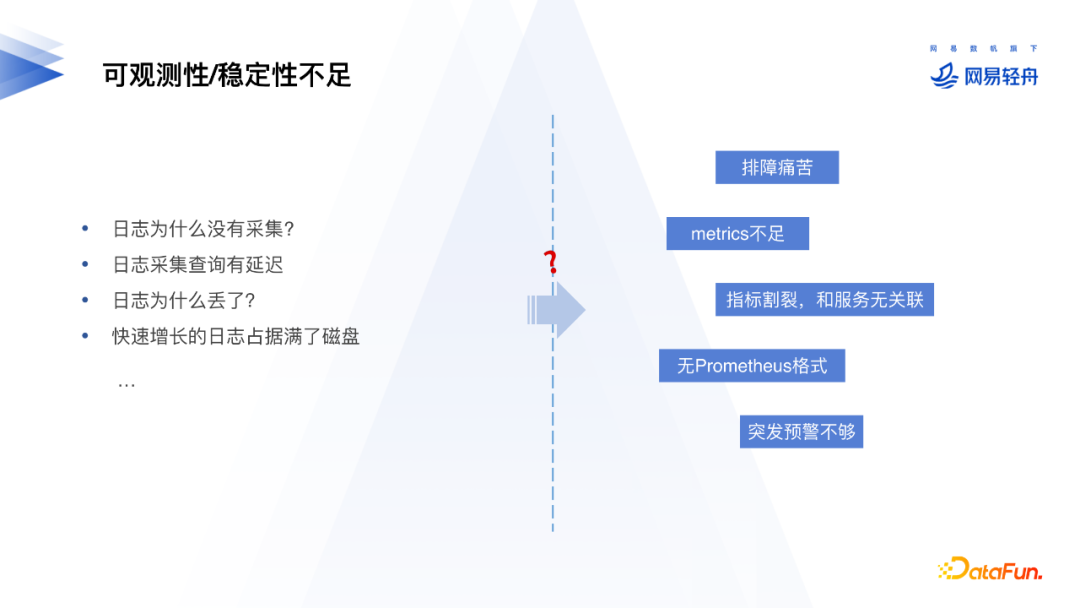
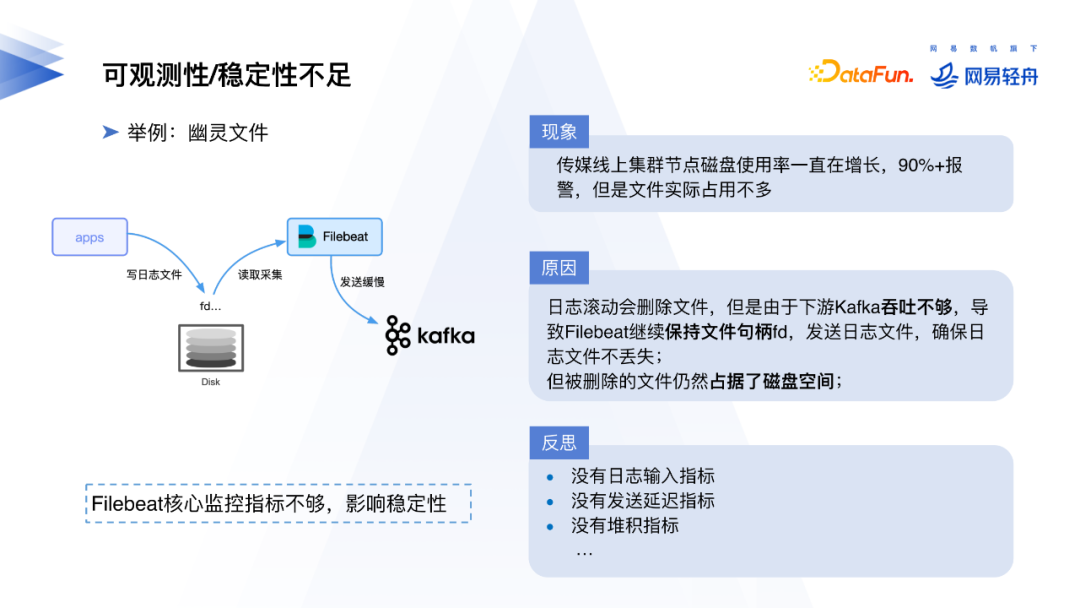
此外,日志采集过程的可观测性和稳定性也很重要。在用户使用过程中经常会遇到日志没有按预期采集、日志采集延迟、日志丢失、日志量增长速度过快磁盘爆满等问题,Filebeat没有提供这些完善等监控指标,同时还需要额外部署prometheus exporter。
我们以一个线上问题为例。线上某集群经常遇到磁盘使用量短时间内暴增到90%以上并触发报警的情况。实际登录节点排查问题后,发现报警的原因在于下游Kafka吞吐量不够,一些日志文件没有完全采集完毕,Filebeat进程默认保留文件句柄直到文件采集完毕,由于文件句柄没有释放,底层的文件无法被真正删除。但在这种情况下,Filebeat缺乏输入延迟、发送延迟和堆积情况等指标,影响稳定性。
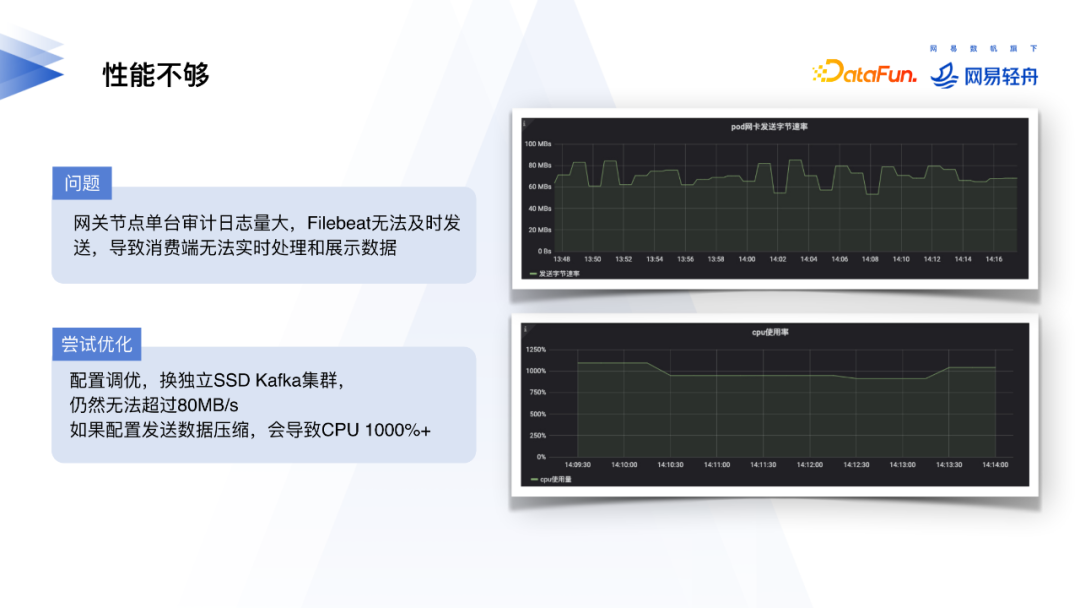
在一个大流量的节点,我们发现Filebeat发送数据到下游Kafka时整体数据处理速度不理想,于是进行了很多优化的尝试,比如换SSD的Kafka集群、改Kafka配置、优化Filebeat配置等调优。我们发现在Filebeat不打开数据压缩的情况下,最大数据发送速度达到80MB/s后很难再有提升,打开数据压缩后Filebeat的CPU的消耗又暴增。调整Kafka或Filebeat参数、机器等配置的优化效果不明显。
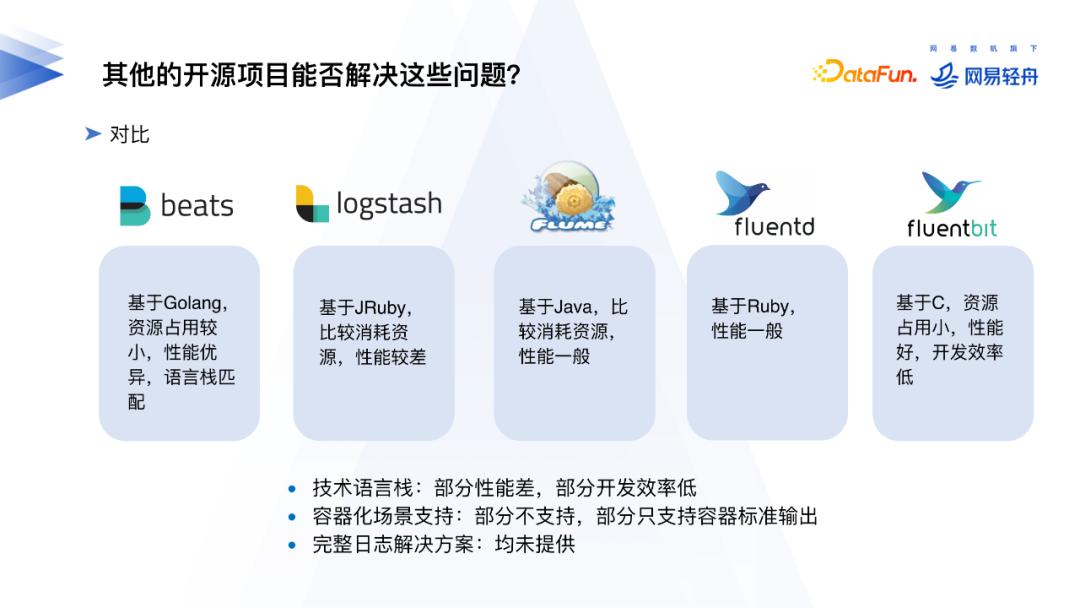
那么除了Filebeat外,其他的日志采集工具能不能满足需求?当前主流的日志采集Agent对容器化场景下的日志采集支持不太理想,大部分开源日志采集工具仅支持到容器标准输出的采集,对云原生下日志采集也没有整体解决方案。
03 新的征程
开源Loggie的现在和未来
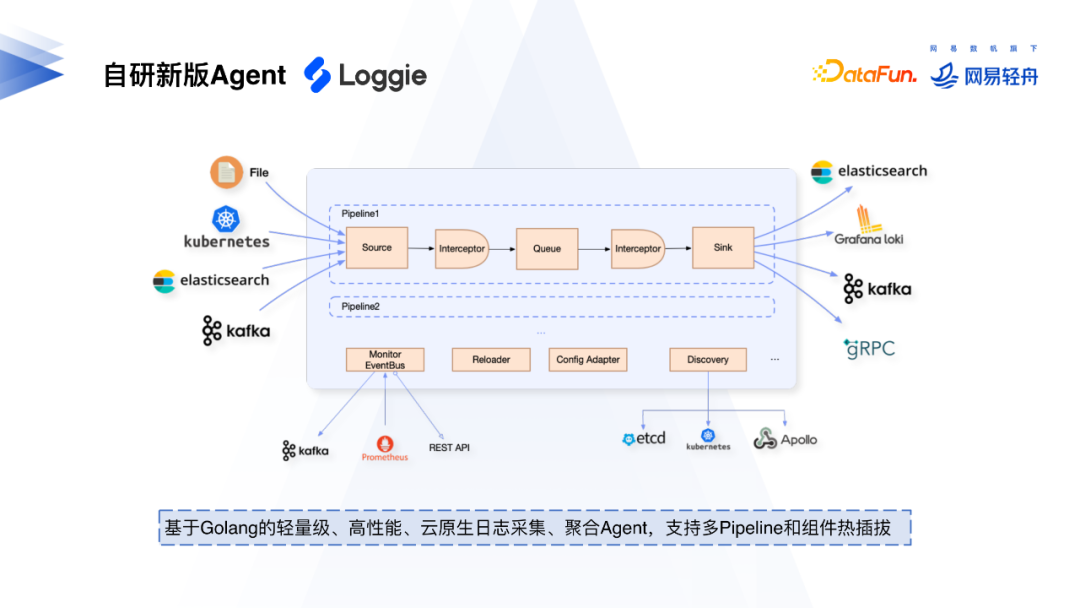
基于Filebeat和现有主流数据采集工具的情况,我们决定自研日志采集Agent——Loggie。它是基于Golang的轻量级、⾼性能、云原⽣⽇志采集、聚合Agent,⽀持多Pipeline和组件热插拔,整体架构如图。

我们加强了Agent的监控和稳定性,可以利用Monitor EventBus上报Agent运行情况,同时暴露了可调用的Restful API和Prometheus拉取监控数据的接口。配置管理方面,目前使用K8S进行配置下发和管理,后续会接入更多配置中心供用户管理配置。

Loggie提供了一栈式日志解决方案,新Agent不再分开维护Agent和中转机。作为一个可插拔组件,Agent既可以作为日志采集端使用,也可以作为中转机使用,同时支持日志中转、过滤、解析、切分、⽇志报警。Loggie同时提供了云原生日志采集完整解决方案,比如通过CRD的形式利用K8s的能力下发配置、部署等。基于我们长期的大规模运维日志收集服务的经验,Loggie沉淀了全⽅位的可观测性、快速排障、异常预警、⾃动化运维能⼒的功能。Loggie基于Golang开发,性能非常好,它资源占⽤小、吞吐性能优异、开发效率高维护成本低。
1. ⼀栈式⽇志解决⽅案
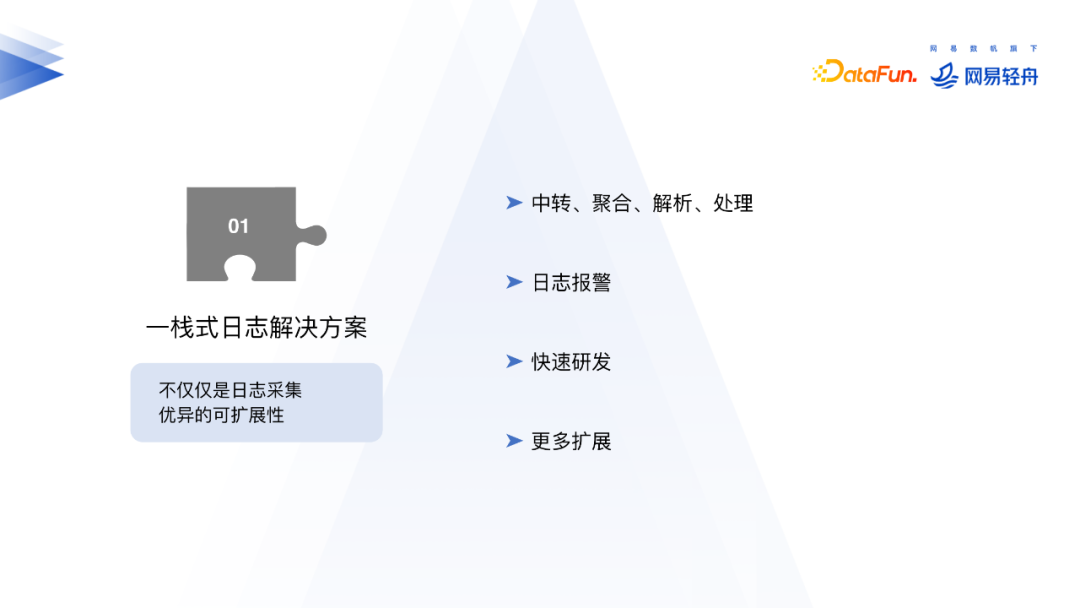
Agent既可以作为日志采集客户端,也可以作为中转机使用。在日志中转方面,我们通过实现Interceptor模块逻辑实现日志的分流、聚合、转存、解析、切分等。通过K8s的CRD可以下发日志采集Agent配置。新的日志采集架构整体维护成本更低。
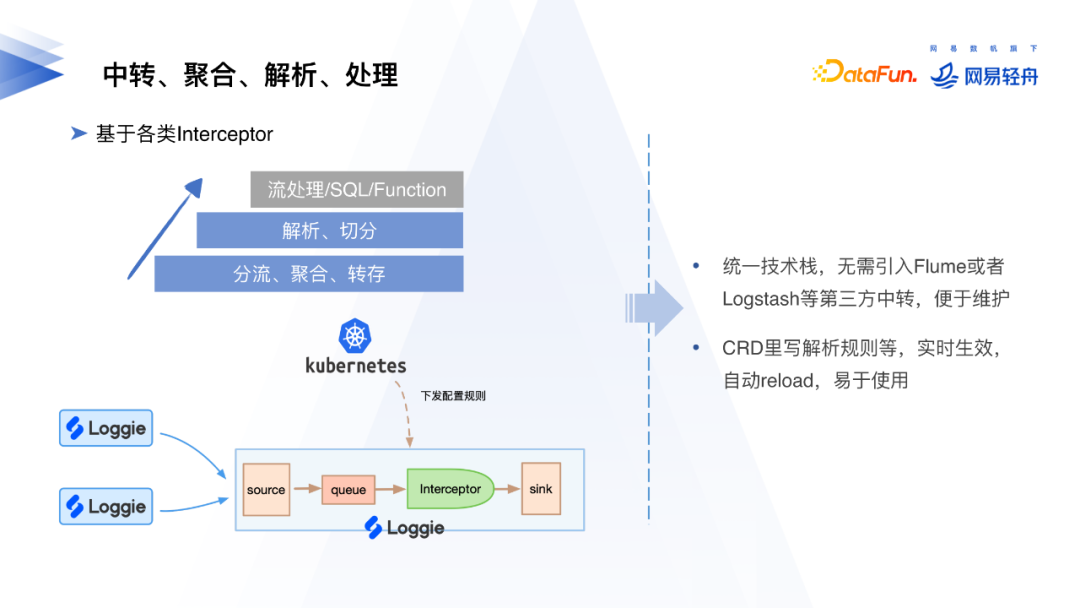
在采用Loggie之前我们有两种报警方案:第一种是基于ElastAlert轮询Elasticsearch进行日志报警,该方案存在配置下发需要手动配置、告警接入不能自动化和高可用不完善等问题;第二种是基于Flink解析关键字或是对日志进行正则匹配进行报警,在前面我们已经介绍过,对于整体日志采集服务而言Flink是比较重量级的。
在采用Loggie后,我们可以使用logAlert Interceptor,在日志采集过程中就可以通过关键字匹配识别info或error进行报警。也可以通过单独部署Elasticsearch Source的Loggie Aggregator对Elasticsearch进行轮询,把信息发送到Prometheus进行报警。新版日志报警架构更轻量,维护起来也更简单。
在项目开发方面,我们秉承微内核、插件化、组件化的原则,把所有组件抽象为component。开发者通过实现生命周期接口,可以快速开发数据发送端逻辑、数据源读取逻辑、处理逻辑和服务注册逻辑。这样的设计让需求能更快更灵活地实现,大大了日志采集侧的开发效率。

基于灵活高效的Agent数据源设计,我们可以配置kubeEvent source采集K8S Event数据作为监控报警的补充。相比重新实现一个采集K8S Event项目,只需要在Loggie上实现对应的source,其他如队列缓存、解�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%82%85%E8%BD%B6%E7%BD%91%E6%98%93%E6%95%B0%E5%B8%86%E4%BA%91%E5%8E%9F%E7%94%9F%E6%97%A5%E5%BF%97%E5%B9%B3%E5%8F%B0%E6%9E%B6%E6%9E%84%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


