全新电商搜索系统
大家好,我是kaiyuan。关于前沿技术在工业界的实践落地应用,我们之前分享过一些文章:
- 大规模搜索+预训练,百度是如何落地的?
- KDD'21 | 淘宝搜索中语义向量检索技术
- 全方位解读 | Facebook的搜索是怎么做的?
- 深度学习在Airbnb搜索的应用实践
- 小红书在推荐多样化的实践——SSD
- KDD'21 | 揭秘Facebook升级版语义搜索技术
今天继续,看看Facebook在KDD'21的工作,从模型到部署介绍了Facebook Marketplace这一电商平台的语义检索系统。
- Que2Search: Fast and Accurate Query and Document Understanding for Search at Facebook
Que2Search可以认为是Facebook在KDD'20工作Embedding-based Retrieval in Facebook Search的升级版本【 Facebook的搜索是怎么做的? 】。但是针对『Facebook maketplace』这一特定场景的向量化检索系统,仍然存在以下几点挑战:
- 商品描述存在 噪声 :由于商品的属性描述(譬如标题、类别等)是由卖家上传的,会存在较多的拼写错误、属性丢失等;
- 国际化 支持 :Facebook Marketplace场景是多国家多语言的,需要模型具备跨语言检索能力;
- 多模态处理 :需要在模型中同时考虑多种模态信息,图片、文本等;
- 严格的延迟性限制 :众所周知线上搜索系统对延迟要求极高,会极大地影响用户体验。尤其是当使用 Transformer-based模型 时,延迟是一个巨大挑战;
本文接下去会深入细节,一起看看是如何一一解决这些问题的。
1. 模型结构
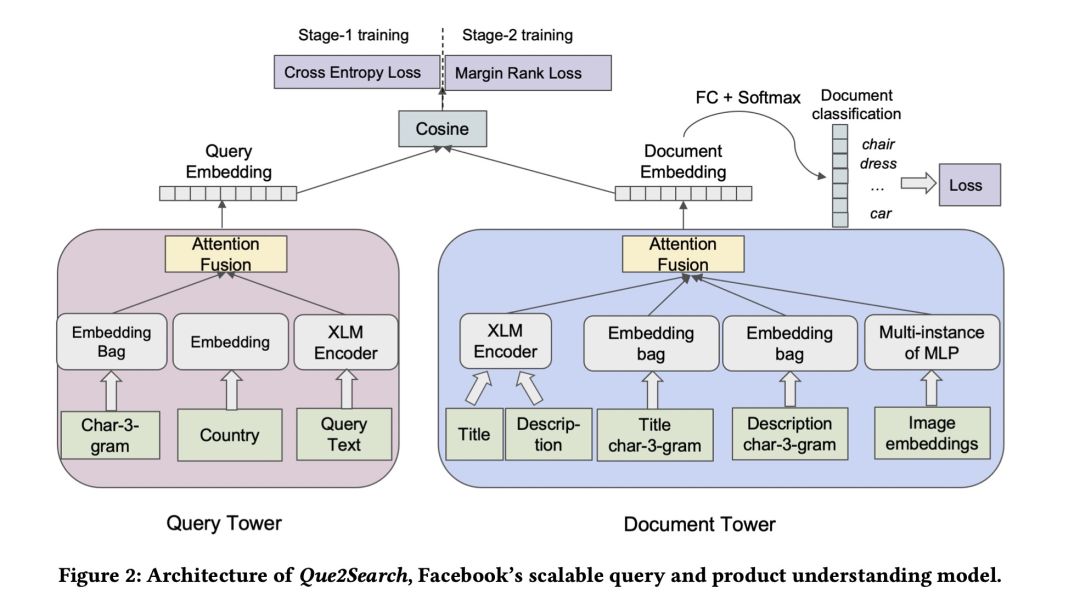 Que2Search模型结构整体模型架构如上,还是使用普遍的双塔形式。
Que2Search模型结构整体模型架构如上,还是使用普遍的双塔形式。
1.1 Query Tower
query侧的特征输入有三部分:
- Query文本的 tri-gram 表示:通过size=3的滑动窗口,得到tri-gram,过hash函数后得到对应的ID,再经过嵌入后得到每个ID的向量表示,然后对所有向量做sum-pooling;
- 用户所在国家:ID类特征,也是经过嵌入后表示成向量;
- Query原始文本:过两层的XLM 编码,取[CLS]对应的向量作为query表示;
1.2 Document Tower
类似的,doc侧的特征输入有五部分:
- 商品标题 :文本类型,使用6层XLM-R编码;
- 商品描述 :文本类型,使用6层XLM-R编码(模型和商品标题的共享);
- 商品标题的3-gram表示 :同query侧处理;
- 商品描述的3-gram表示 :同query侧处理;
- 图像表示 :对于每一个商品,都会附带一些图片,通过预训练模型得到图像表示,然后过MLP和Deep set方法对多个图像表示进行融合得到最终这一路特征表示;
1.3 Late Fusion
late-fusion指的是对上述 双塔 内的多路输入特征如何进行融合,常见的融合方式有
- **concatenation fusion ** :将所有路表示拼接起来过MLP得到固定维度的向量表示;
- simple attention fusion :注意力机制不用多说了
作者通过实验发现简单的 注意力 形式效果更好,

2. 训练阶段
模型整体如上,引入了更多的特征+更精细的融合方式,再来看看训练过程是如何操作的。
2.1 训练数据
正样本来自用户搜索日志,是一对相关的 <query, document> 对;那在论文业务场景中,如何表示相关呢?作者利用下述条件在日志中进行筛选:如果上述四个事件在一定时间内(24小时)发生,则认为是相关的,称为『in-conversation』。
PS. 在描述这一部分的时候可以明显感受到作者的" 求生欲",感受下:
We do not have access to message contents and only know that users interacted with the sellers.
- 用户搜索了一个query
- 用户点击了query下的某个商品
- 用户给该商品的卖家发消息
- 该商品卖家回复消息
负样本来自batch内负采样,也是属于应用很广泛的负样本策略,譬如可以参考我们之前分享的: 大规模搜索+预训练,百度是如何落地的? 。不过这里对负样本的利用,还是有一点点不同,后面会具体介绍。
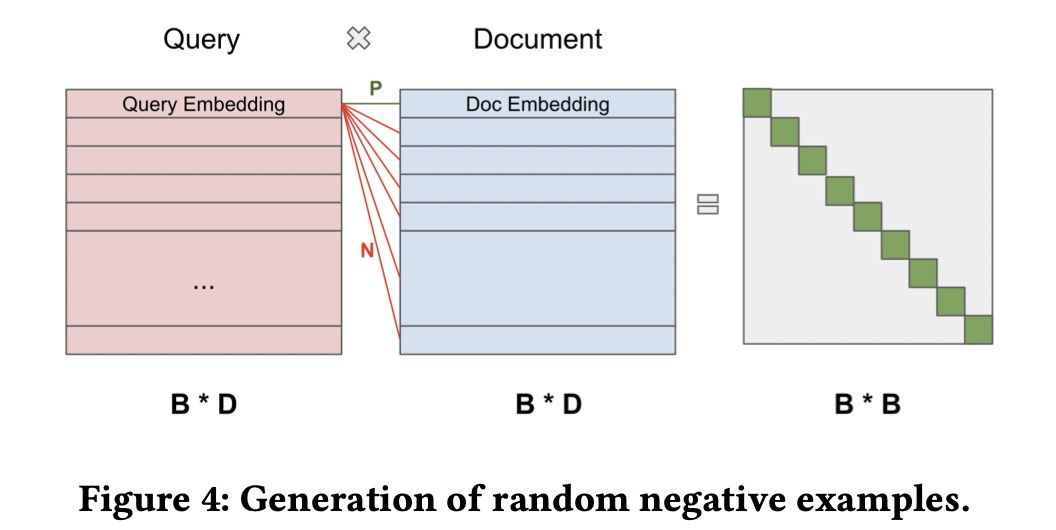 batch内负采样
batch内负采样
2.2 多阶段训练
模型训练分为两个阶段,
- 第一阶段:batch内简单负样本训练,即其他record的doc作为当前query的负样本,然后做一个 multi-class cross-entropy。损失函数为:

其中 为温度系数,目的是拉大logits的区分度,使其更sharpen,需要做实验调参确定值。
- 第二阶段:batch内困难负样本训练,文中称为『课程学习』。使用困难负样本也是比较常见的套路,一般是离线通过各种策略采样得到。不过这里作者还是使用了batch内的数据,具体地,对于每个query ,选取除 对角线 外的相似度分数最高的doc作为负样本 ,因为对角线的doc为该query对应的正样本 。于是这样就有了三元组 ,尝试了二分类交叉熵损失和最大间隔损失函数两种方法,发现margin设置为0.1~0.2的margin rank loss表现最好

2.3 多任务学习
除了上述双塔任务之外,作者还在document tower额外引入了一个任务,document classification。具体地,针对每个doc,选取一系列相关的query。总共保留头部45000的query,然后用doc塔产出的向量做多标签分类
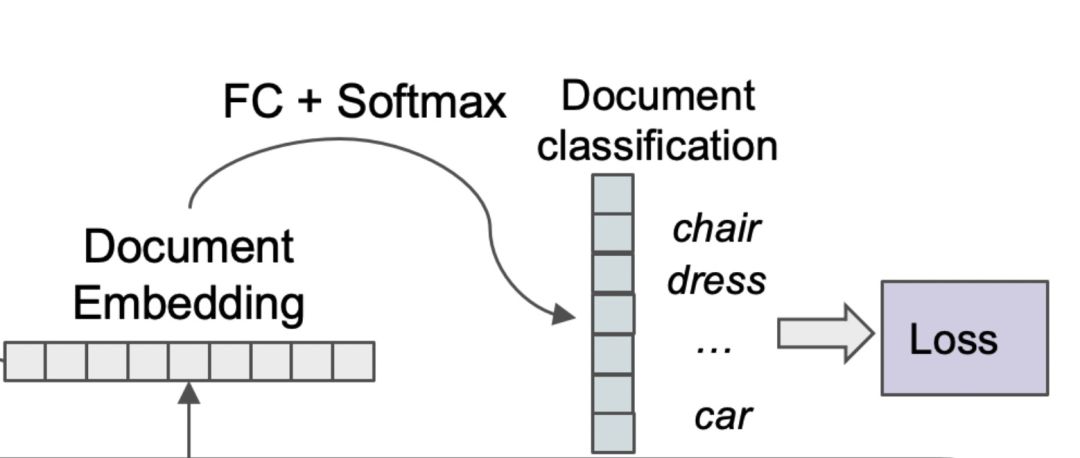 document classification### 2.4 多模态融合
document classification### 2.4 多模态融合
一般而言, 模态 指的是不同类型的数据,譬如文本、图像、视频、语音等等,而常见的融合方式就是Attention。在本文中,模态的概念更加宽泛,作者把不同路的输入认为是不同的模态,同时将 Grandient Blending 梯度融合的形式引入 双塔结构。
梯度融合来源于 CVPR 2020 论文What Makes Training Multi- Modal Networks Hard ,具体做法如下:
训练M+1个模型,M是模态的数量,其中M个模型分别用单个模态特征作为输入来训练,1个模型用所有 模态特征 作为输入来训练。先分别计算每个模型的损失,然后 加权融合 所有模型的损失,每个损失都有提前设定好的权重系数。目的是让模型即使在模态缺失的时候也具备学习能力,更加鲁棒。
针对Que2Search场景下,步骤为:
- 单模态特征训练。因为是双塔,需要"控制变量",及一侧的塔每次只使用一路特征,另一侧塔使用全部特征
 2. 全模态特征训练。
2. 全模态特征训练。
 3. 损失加权融合。
3. 损失加权融合。
注意,梯度融合只在训练阶段使用,预测时使用全部的模态。
3. 实验&效果
3.1 消融实验
主要是看一下,论文新提出的结构或者特征,是否有作用以及提升有多少。
对比Base选取的是KDD'20提出的wide&deep模型,关于 base模型 具体可以参考 全方位解读 | Facebook的搜索是怎么做的?。分别在『in-conversation』数据集和人工标注数据集上进行实验,可以看到,引入额外的特征(原始文本和图像),对效果有较大的提升。一些模型的设计,譬如课程学习、多任务、模块参数共享等,也都带来或多或少的效果增益。
!
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%85%A8%E6%96%B0%E7%94%B5%E5%95%86%E6%90%9C%E7%B4%A2%E7%B3%BB%E7%BB%9F/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


