关键短语抽取及使用的技术实践
AI 算法团队 zacbai 平安寿险 PAI
一、 全文框架概览
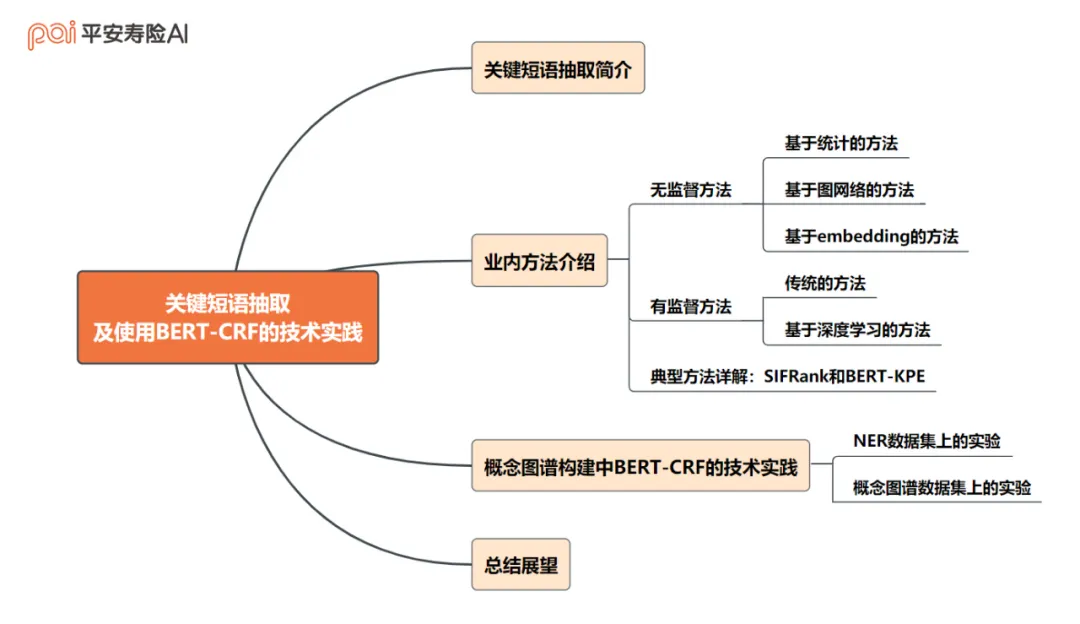
一、关键短语抽取简介
关键短语抽取 (keyphrase extraction),指从文章中提取典型的、有代表性的短语,期望能够表达文章的关键内容。
关键短语抽取对于文章理解、搜索、分类、聚类都很重要。而高质量的关键短语抽取算法,还能有效助力构建知识图谱。
常见的关键短语抽取方法分为有监督 (supervised)和无监督 (unsupervised)。整体抽取流程则分为 2 个步骤:(1) candidate generation,得到候选短语集合;(2) keyphrase scoring,对候选短语进行打分。
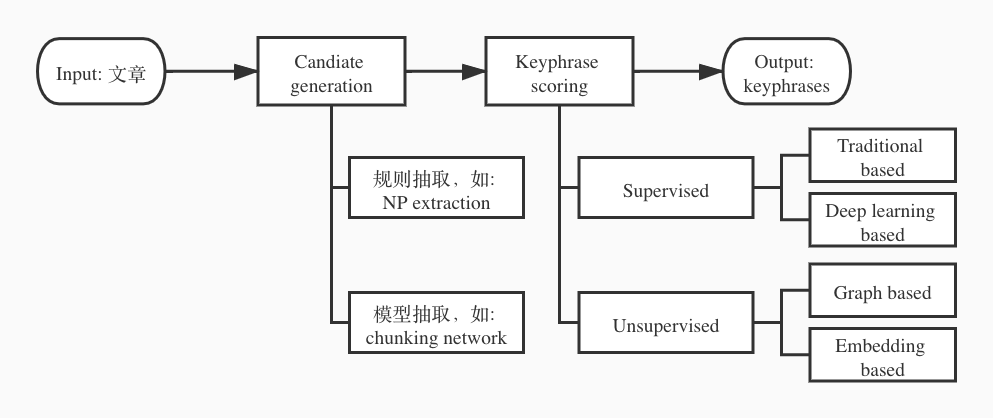
Figure 1 Keyphrase 整体流程
二、业内方法介绍
无监督方法
无监督的方法由于其不需要数据标注及普适性,得到了大范围的应用。
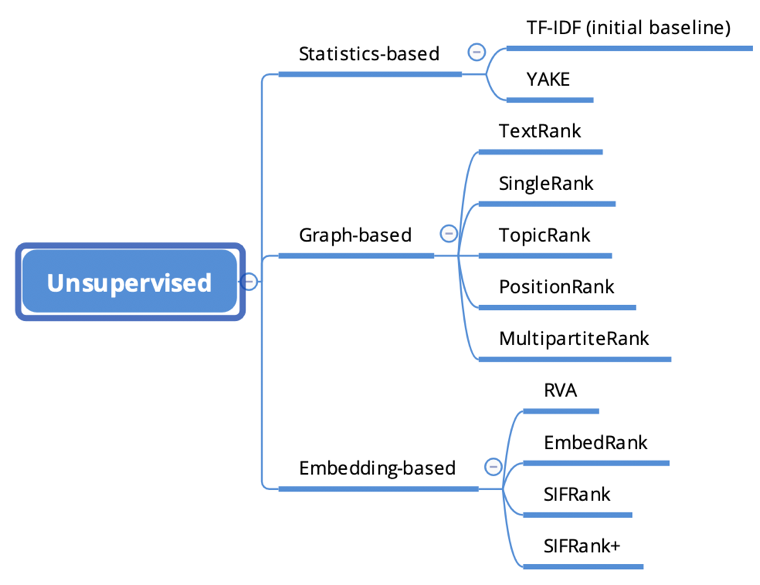
Figure 2 无监督方法概览
1. 基于统计的方法
- 基于 TFIDF 的方法是最基本的版本,在得到候选短语集合的基础上(如,利用 POS tags 抽取 noun phrases (NP)),使用 term frequency, inverse document frequency 对候选短语进行打分,选择高分短语作为关键短语。
- YAKE[1]除了利用 term frequency, term position,还利用了更多基于统计学的特征,希望能更好地表示短语的上下文信息和短语在文章中发挥的作用。
2. 基于图网络的方法
- TextRank[2]是第一个基于图网络的关键短语抽取算法。该方法首先根据 POS tags 抽取候选短语,然后使用候选短语作为节点,创建图网络。两个候选短语如果共现于一定的窗口内,则在节点之间创建一条边,建立节点间的关联。使用 PageRank[3]算法更新该图网络,直至达到收敛条件。
- 此后,各种基于图网络的改进算法不断被提出,该类算法也逐渐成为无监督关键短语抽取中应用最广泛的算法。SingleRank[4]在 TextRank 之上为节点间的边引入了权重。PositionRank[5]通过引入短语的位置信息,创建一个 biased weighted PageRank,从而提供了更准确的关键短语抽取能力。
3. 基于 embedding 的方法:这类方法,利用 embedding 来表达文章和短语在各个层次的信息(如:字、语法、语义等)。
- EmbedRank[6]首先利用 POS tags 抽取候选短语,然后计算候选短语 embedding 和文章 embedding 的 cosine similarity,利用相似度将候选短语排序,得到关键的短语。
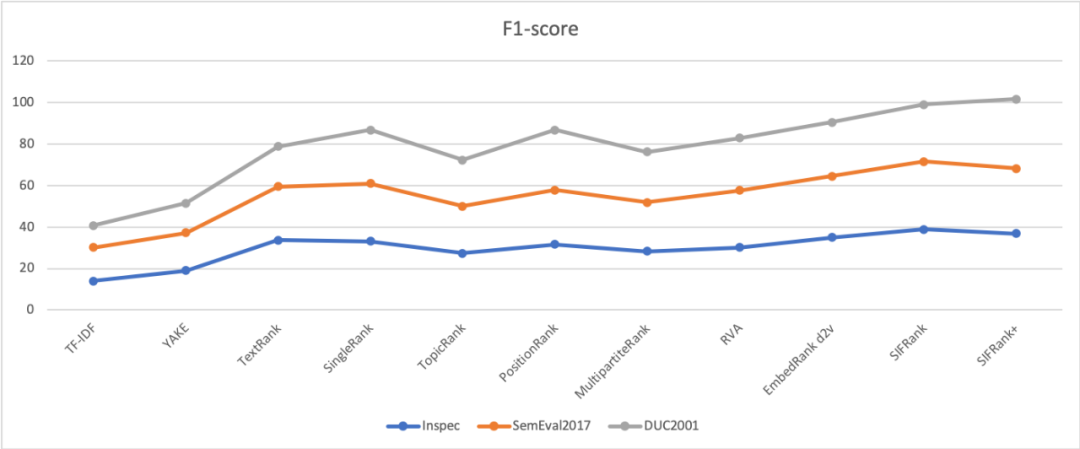
Figure 3 典型无监督方法在 benchmarks 上的效果
有监督方法
虽然需要花费很多精力进行数据标注,但有监督方法在各个特定任务和数据集上,通常能够取得更好的效果。
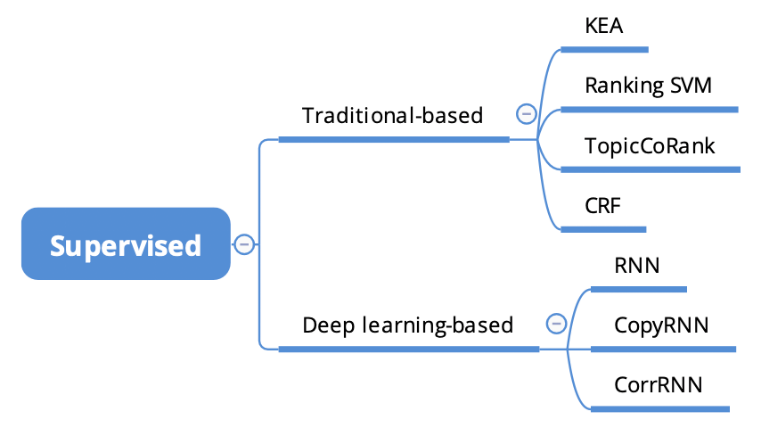
Figure 4 有监督方法概览
1. 传统的方法
- KEA[7]是较早期的算法,利用特征向量表示候选短语,如:tf-idf 分数和初次出现在文章中的位置信息,使用 Na ïve Bayes 作为分类,对候选短语进行打分和分类。在此之上,许多改进版本的算法也被提出,如:Hulth 等人引入语言学知识,提出了改进版本[8]。CeKE[9]在对学术论文进行关键短语抽取时,通过使用论文的引用关系,引入更多特征信息,从而进一步提升了效果。
- RankingSVM[10]使用 learning to rank 来建模该问题,将训练过程抽象为拟合 ranking 函数。
- TopicCoRank[11]是无监督方法 TopicRank 的有监督扩展。该方法在 basic topic graph 之外,结合了第二个图网络。
- CRF[12]是序列标注的经典算法,利用语言学、文章结果等各种来源特征表示文章,通过序列标注,得到文章的关键短语。
2. 基于深度学习的方法
-
RNN[13]使用了双层 RNN 结构,通过两层 hidden layer 来表征信息,并且利用序列标注的 方法,输出最终的结果。
-
CopyRNN[14]使用 encoder-decoder 结构进行关键短语抽取。首先,训练数据被转换为 text-keyphrase pairs,然后训练基于 RNN 的 encoder-decoder 网络,学习从源数据 (sentence)到目标数据 (keyphrase)的映射关系。
-
CorrRNN[15]同样适用 encoder-decoder 结构,但是额外引入了两种限制条件:
① Keyphrases 应该尽量覆盖文章的多个不同话题;
② Keyphrases 应该彼此之间尽量不一样,保证多样性。
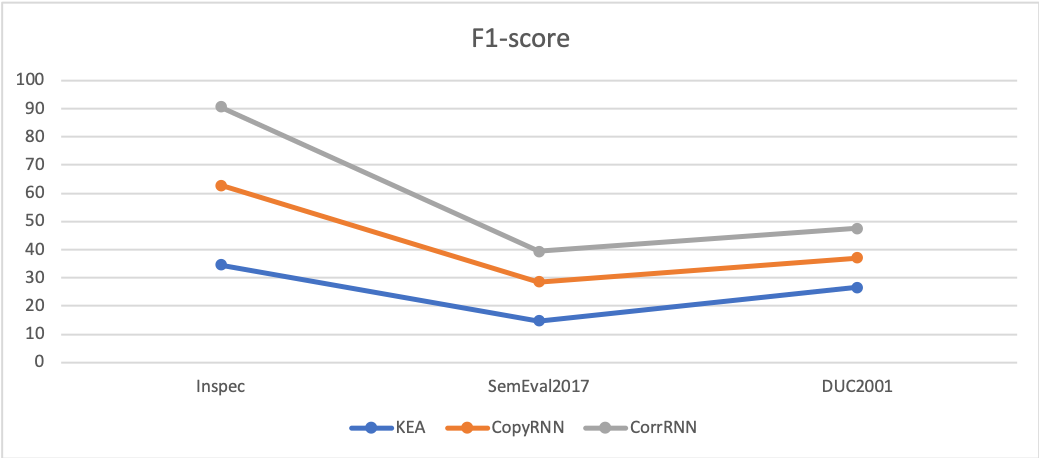
Figure 5 典型有监督方法在 benchmarks 上的效果
典型方法详解
我们分别从有监督和无监督方法中,挑选两种典型的、效果也很好的方法:SIFRank[16]和 BERT-KPE[17],详细介绍其原理和具体流程。这两种方法也符合关键短语抽取的基本流程,均分为两个步骤:
- SIFRank 利用 POS tags 抽取 NP 作为 keyphrase candidates,然后利用 ELMo embedding 分别表示句子和短语,计算 cosine similarity 对候选短语进行打分。
- BERT-KPE 基于 BERT 搭建 chunking network 和 ranking network,按照多任务学习的范式,完成 candidate generation 和 keyphrase scoring 两个环节。
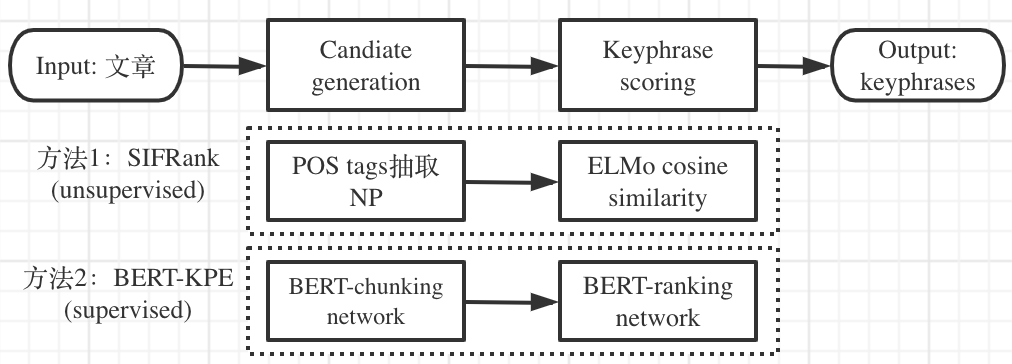
Figure 6 SIFRank 和 BERT-KPE 流程图
1.SIFRank – a good baseline
传统的关键短语抽取方法,主要利用统计、语法等信息。ExpandRank[4], AutoPhrase[18]等算法被提出,通过引入相关的文章,或者利用外部知识图谱等不同方式,引入外部信息。
近来,预训练模型的快速发展给关键短语抽取也带来了新的引入外部知识和信息的方法。SIFRank 通过引入预训练模型 ELMo[19],对文章和短语得到动态的 sentence embedding 和 phrase embedding,从字、词、语法、上下文等多层次表达文章和短语,从而实现了高质量的关键短语抽取。该方法在不同的数据集上,均能取得很好的表现,可以作为一个不错的基准模型,应用于各种不同应用下的关键短语抽取。
- Candidate generation: 利用 POS tags,抽取得到 NP (noun phrases),作为候选短语。
- Keyphrase scoring: 使用 smooth inverse frequency (SIF)[20] 计算文章和短语中各个词语的权重。然后通过 ELMo 得到每个词的 embeddings,相应地加权得到 sentence embedding, phrase embedding。最后计算 cosine similarity 对候选短语进行排序。
2.BERT-KPE
BERT-KPE 是最近由 thunlp 提出的方法,在 OpenKP 和 KP20K 上都达到了 state-of-the-art 和良好的鲁棒性。BERT-KPE 使用预训练模型 BERT,采用多任务学习范式,同时训练 chunking network 和 ranking network,分别完成 candidate chunking 和 ranking 两个任务。此外,该方法也非常灵活,可以根据需要,删除任意一个子网络,仅训练另外一个子网络。该算法主要分为以下几步:
- Token embedding
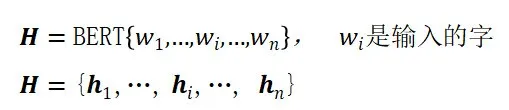
- N-gram representation: 使用 CNN 融合窗口大小为 k 的字对应的 token embeddings,得到相应的 n-gram representation
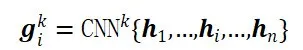
-
Multi-task
▫️️️ Chunking network:预测该 n-gram 是否是关键短语候选

▫️️️ Ranking network: 对 n-gram 进行排序

三、概念图谱构建中 BERT-CRF 的技术实践
在实际业务中,我们需要建设一个概念图谱[21, 22]。
什么是概念?
- 用户视角:从用户视角出发,文章或内容中用户的核心关注点
- 精准和泛化:能准确描述文章、内容或事件,同时不缺乏泛化性

我们通过概念图谱,利用概念对文章和内容进行精准的理解,建立概念和上层应用间的图网络关系,从而支撑相关的业务应用。概念图谱本身是另外一个包含很多内容的话题,不在本文中过多阐述。在此,我们主要介绍概念图谱中用到的关键短语抽取技术,特别是使用 BERT-CRF 进行 candidate 抽取的实践。
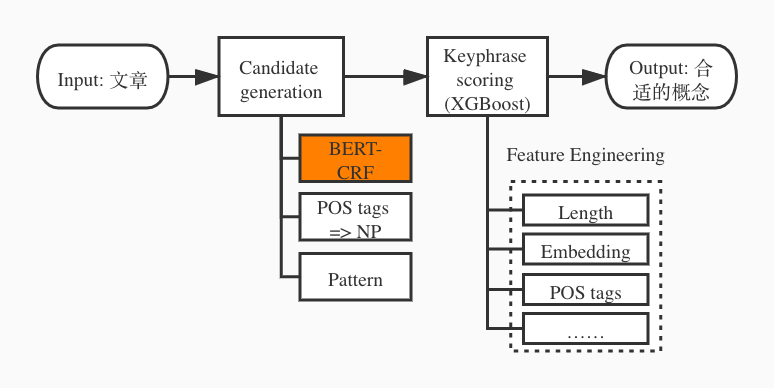
Figure 8 概念图谱构建中的 BERT-CRF 模块
在该任务下, keyphrase 的定义是我们希望获取的概念,因此具有上面提到的两个特点:(1) 用户视角;(2) 精准和泛化。由于这两个特点,不确定因素被无可避免地引入进来,从而导致 keyphrase 飘移的问题(keyphrase 的标准不固定,与各种变量高度相关):
- 与文章来源高度相关:不同来源的文章(如:自有采购文章、网络爬虫),用字用词、行文风格等各方面不同;
- 与用户关注点高度相关:用户的核心关注点,会随时间推移而变化;
- 与文章内容高度相关:文章内容本身也会逐渐迭代,随时间推移而变化。
这些变化是动态且缓慢的过程。我们会定期更新关键短语抽取模块,确保该环节能适应较大的变化。同时,我们也需要稳定的关键短语抽取模块,从而在一定程度上,缓解 keyphrase 飘移的问题,提供具有鲁棒性的概念抽取能力。
BERT[23]是非常优质的预训练模型,包含了很多预训练语料中蕴含的外部知识和信息。我们以此为基础,训练 BERT-CRF 模型,作为 candidate generation 中重要的一路召回。另外的召回路包括基于模板 (pattern)和基于 POS tags 的 NP 抽取系统。CRF[12]是序列标注的经典方法,其核心思想是在进行序列标注时,把序列上的各个点当做一个整体来处理,而不是一个个独立的点,各个点的标注结果是有一定依赖关系的,以路径为单位进行训练。因此,通过训练,模型能在理解文本以外,还能理解输出序列的规则性知识,比如,使用 BIO 标注模式时,O 后面不能直接接 I。如果直接使用 BERT 进行序列标注,最后一层的 softmax,本质上是 n 个 k 分类问题;而 BERT-CRF 由于 CRF layer 的存在,本质上是 1 个 k^n 分类问题[24]。
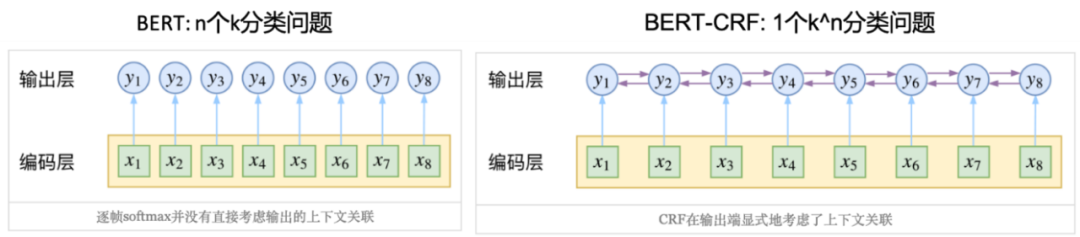
Figure 9 BERT 与 BERT-CRF 的对比[24]
为了验证 BERT-CRF 确实能够提供我们需要的鲁棒的关键短语抽取能力,我们在 NER 和概念图谱(抽取该应用下定义的 keyphrase)两个数据集上进行了以下的实验。
-
NER
▫️️️ 来源: https://github.com/zjy-ucas/ChineseNER (PER, LOC, OR)
▫️️️ 特点:标准明确且基本固定
-
概念图谱中的关键短语抽取
▫️️️ 来源
▪️️️ 自有的标注数据(标准按照前述的两个特点:用户视角 & 精准和泛化)
▪️️️ 训练集:来自于 sourceA (网络爬取文章)
▪️️️ 测试集:来自于 sourceB (平安自有文章)
▫ 特点:存在前述的概念飘移问题
对于概念图谱的关键短语抽取,我们希望在 sourceA 上训练的模型,能够更好地适应于 sourceB(当然,我们最终的系统是在 sourceA + sourceB + all other sources 训练得到的)。实验设定中训练和测试集采用不同来源,是为了在开发阶段,检验搭建的模块是否能够提供我们需要的鲁棒性。
NER 数据集上的实验
NER 数据集上,通过初版实验发现,BERT & BERT-CRF 效果几乎一样,这个结论是与 BiLSTM 和 CNN 添加 CRF layer 的结论是不同的。具体查看模型中的参数,发现 transition matrix 的值很不合理[24]。BERT 是预训练模型,其中的参数、权重本身就比较合理。经验上来说,BERT 适合的学习率一般都很小,在 1e-4 和 1e-5 之间。BERT 部分快速收敛,但是 CRF layer 却远未到最佳。但是由于 BERT 的输出,已经很合理了,因此即使 CRF layer 参数还未收敛,也不影响最终输出比较合理的序列结果。相应地,我们对 CRF 的 learning rate 进行了调整,采用 BERT learning rate 的 100 倍。代码实现如下:
(https://github.com/macanv/BERT-BiLSTM-CRF-NER/blob/master/bert_base/bert/optimization.py, line: 59-81, crf_lr_multipler default value is 100, 修改如下:)
optimizer2 = AdamWeightDecayOptimizer(learning_rate = learning_rate * crf_lr_multiplier, weight_decay_rate = 0.01, beta_1 = 0.9, beta_2 = 0.999, epsilon = 1e-6, exclude_from_weight_decay = [‘LayerNorm’, ‘layer_norm’, ‘bias’]
if use_tpu:
optimizer = tf.contrib.tpu.CrossShardOptimizer(optimizer)
tvars = tf.trainable_variables()
tvars1 = tvars[:-1]// all variables except the CRF layer parameters
tvars2 = tvars[-1:]// parameters in CRF layer
grads = tf.gradients(loss, tvars1 + tvars2)
grads1 = grads[:-1]
grads2 = grads[-1:]
train_op1 = optimizer.apply_gradients(zip(grads1, tvars1), global_step = global_step)
train_op2 = optimizer.apply_gradients(zip(grads2, tvars1), global_step = global_step)
new_global_step = global_step + 1
train_op = tf.group(train_op1, train_op2, [global_step.assign(new_global_step)])
return train_op
调整学习率之后,发生了如下变化:
- 整体 precision, recall 未见明显提升:跟 BERT 相比,BERT-CRF 或者 BERT-CRF (lr change)均未能明显提升 precision, recall (说明 BERT 模型的拟合能力,足够解决该 NER 问题)

-
Transition matrix 变得更合理
分析 transition matrix,比较相对值更容易得到有意义的结论。对于每个类型的 NER (ORG, PER, LOC)。最基本的合理性要求是:p(O => B-xxx) > p(O => I-xxx)

- 不合理的预测结果(O 之后紧跟 I-xxx 这种一定错误的结果)变少:35 个 => 2 个(测试集总共 4336 条数据)
概念图谱数据集上的实验
与 NER 数据集那样标准明确不同的是,概念图谱数据集,由于定义的 keyphrase 具有两个特点:(1) 用户视角; (2) 精准和泛化,存在飘移的问题。在采用 BERT-CRF,并且调整 learning rate 之后,我们发现效果得到了极大的提升:
- 整体 precision, recall 全面提升

- Transition matrix 变得合理
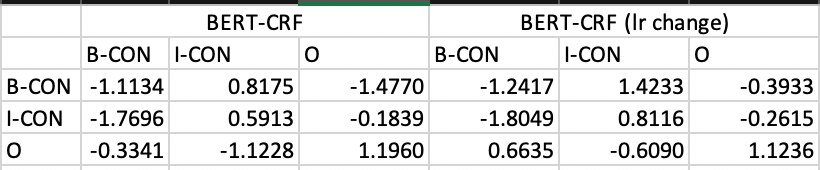
- 不合理的预测结果(O 之后紧跟 I-CON 这种一定错误的结果)大幅减少:66 个 => 2 个(测试集总共 1625 条数据)
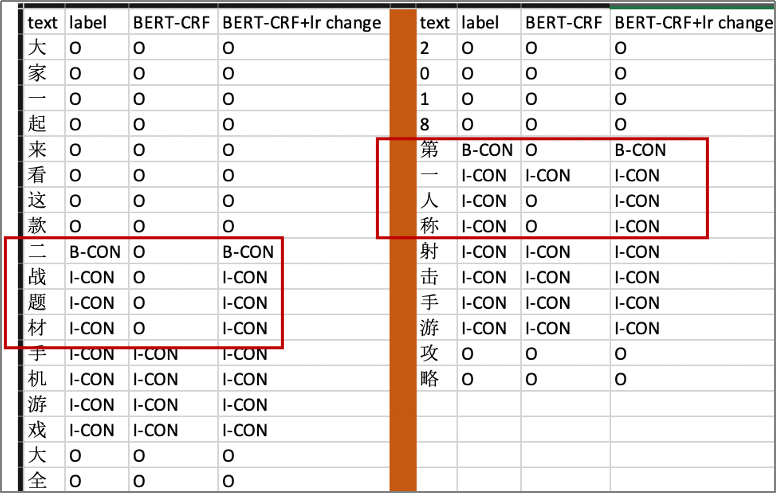 Figure 10 BERT-CRF 调整 learning rate 结果对比实例
Figure 10 BERT-CRF 调整 learning rate 结果对比实例
四、总结展望
关键短语抽取是 NLP 的一个基础任务,对于内容理解、搜索、推荐等各种下游任务,都非常重要。统计学、语法、句法、语义等多来源特征被引入和使用,用来抽取候选短语和对短语进行打分。随着预训练模型的发展,各种知识图谱的构建,更多外部知识和信息能够被引入,从而促进关键短语抽取算法的效果提升。同时,更好的关键短语抽取系统又能反哺各项任务,比如:知识图谱的构建,以及我们正在进行的概念图谱构建,最终整体形成闭环,促进各项技术的进步。
引用:
1.Awajan, A.A. Unsupervised Approach for Automatic Keyword Extraction from Arabic Documents. in Proceedings of the 26th Conference on Com
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%85%B3%E9%94%AE%E7%9F%AD%E8%AF%AD%E6%8A%BD%E5%8F%96%E5%8F%8A%E4%BD%BF%E7%94%A8%E7%9A%84%E6%8A%80%E6%9C%AF%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


