冗余数据一致性到底如何保证
一,为什么要冗余数据
互联网数据量很大的业务场景,往往数据库需要进行 水平切分 来降低单库数据量。
水平切分会有一个patition key,通过patition key的查询能够直接定位到库,但是非patition key上的查询可能就需要扫描多个库了。
此时常见的架构设计方案,是使用 数据冗余 这种反范式设计来满足分库后不同维度的查询需求。
例如:订单业务,对用户和商家都有查询需求:
Order(oid, info_detail);
T(buyer_id, seller_id, oid);
如果用buyer_id来分库,seller_id的查询就需要扫描多库。
如果用seller_id来分库,buyer_id的查询就需要扫描多库。
此时可以使用数据冗余来分别满足buyer_id和seller_id上的查询需求:
T1(buyer_id, seller_id, oid)
T2(seller_id, buyer_id, oid)
同一个数据,冗余两份,一份以buyer_id来分库,满足买家的查询需求;一份以seller_id来分库,满足卖家的查询需求。
如何实施数据的冗余,以及如何保证数据的一致性,是今天将要讨论的内容。
二,如何进行数据冗余
(1)服务同步双写
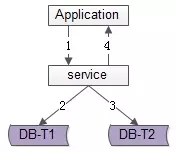
顾名思义,由服务层同步写冗余数据,如上图1-4流程:
-
业务方调用服务,新增数据
-
服务先插入T1数据
-
服务再插入T2数据
-
服务返回业务方新增数据成功
优点:
-
不复杂,服务层由单次写,变两次写
-
数据一致性相对较高(因为双写成功才返回)
缺点:
-
请求的处理时间增加(要插入两次,时间加倍)
-
数据仍可能不一致,例如第二步写入T1完成后服务重启,则数据不会写入T2
如果系统对处理时间比较敏感,引出常用的第二种方案。
(2)服务异步双写
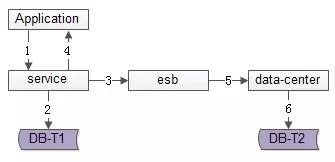
数据的双写并不再由服务来完成,服务层异步发出一个消息,通过消息总线发送给一个专门的数据复制服务来写入冗余数据,如上图1-6流程:
-
业务方调用服务,新增数据
-
服务先插入T1数据
-
服务向消息总线发送一个异步消息(发出即可,不用等返回,通常很快就能完成)
-
服务返回业务方新增数据成功
-
消息总线将消息投递给数据同步中心
-
数据同步中心插入T2数据
优点:
- 请求处理时间短(只插入1次)
缺点:
-
系统的复杂性增加了,多引入了一个组件(消息总线)和一个服务(专用的数据复制服务)
-
因为返回业务线数据插入成功时,数据还不一定插入到T2中,因此数据有一个不一致时间窗口(这个窗口很短,最终是一致的)
-
在消息总线丢失消息时,冗余表数据会不一致
不管是服务同步双写,还是服务异步双写,服务都需要关注“冗余数据”带来的复杂性。如果想解除“数据冗余”对系统的耦合,引出常用的第三种方案。
(3)线下异步双写
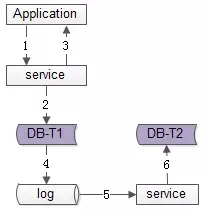
为了屏蔽“冗余数据”对服务带来的复杂性,数据的双写不再由服务层来完成,而是由线下的一个服务或者任务来完成,如上图1-6流程:
-
业务方调用服务,新增数据
-
服务先插入T1数据
-
服务返回业务方新增数据成功
-
数据会被写入到数据库的log中
-
线下服务或者任务读取数据库的log
-
线下服务或者任务插入T2数据
优点:
-
数据双写与业务完全解耦
-
请求处理时间短(只插入1次)
缺点:
-
返回业务线数据插入成功时,数据还不一定插入到T2中,因此数据有一个不一致时间窗口(这个窗口很短,最终是一致的)
-
数据的一致性依赖于线下�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%86%97%E4%BD%99%E6%95%B0%E6%8D%AE%E4%B8%80%E8%87%B4%E6%80%A7%E5%88%B0%E5%BA%95%E5%A6%82%E4%BD%95%E4%BF%9D%E8%AF%81/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


