写吞吐场景资源消耗量化分析及优化
一. 概述
HBase 是一个基于 Google BigTable 论文设计的高可靠性、高性能、可伸缩的分布式存储系统。 网上关于 HBase 的文章很多,官方文档介绍的也比较详细,本篇文章不介绍HBase基本的细节。
本文从 HBase 写链路开始分析,然后针对少量随机读和海量随机写入场景入手,全方面量化分析各种资源的开销, 从而做到以下两点:
- 在给定业务量级的情况下,预先评估好集群的合理规模
- 在 HBase 的众多参数中,选择合理的配置组合
二. HBase 写链路简要分析
HBase 的写入链路基于 LSM(Log-Structured Merge-Tree), 基本思想是把用户的随机写入转化为两部分写入:
Memstore 内存中的 Map, 保存随机的随机写入,待 memstore 达到一定量的时候会异步执行 flush 操作,在 HDFS 中生成 HFile 中。 同时会按照写入顺序,把数据写入一份到 HDFS 的 WAL(Write Ahead Log)中,用来保证数据的可靠性,即在异常(宕机,进程异常退出)的场景下,能够恢复 Memstore 中还没来得及持久化成 HFile 的数据.
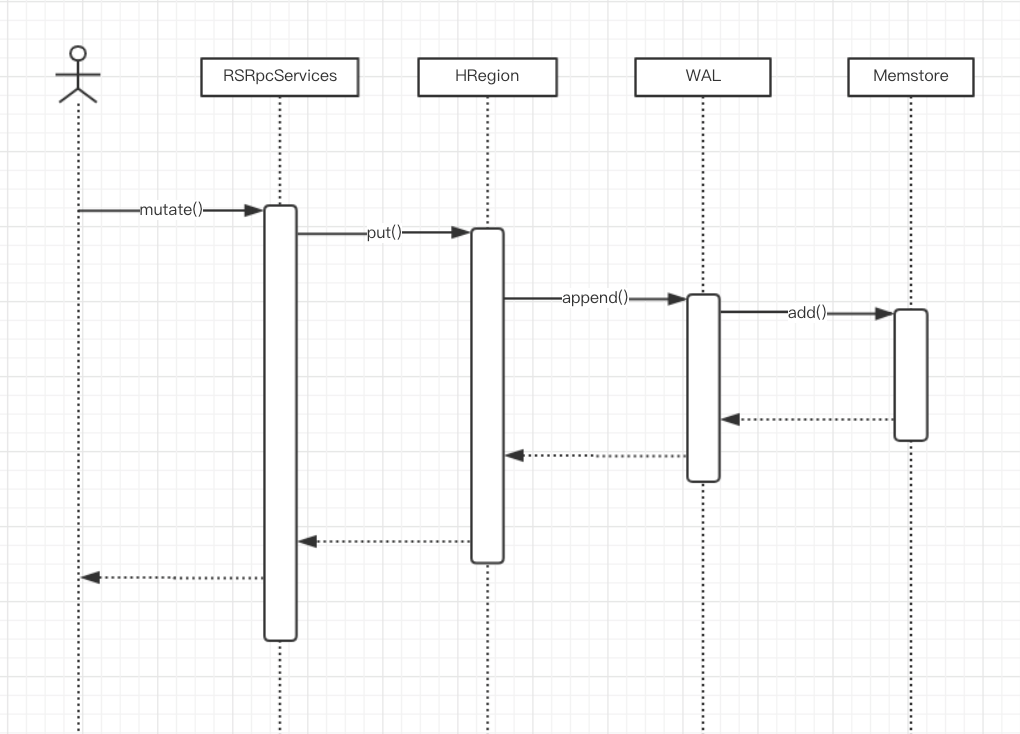
三. Flush & Compaction
上一节中,介绍了 HBase 的写路径,其中 HFile 是 HBase 数据持久化的最终形态, 本节将介绍 HBase 如何生成 HFile 和管理 HFile。关于 HFile, 主要涉及到两个核心操作:
- Flushing
- Compaction
上一节中提到,HBase 的写入最先会放入内存中,提供实时的查询,当 Memstore 中数据达到一定量的阈值(128MB),会通过 Flush 操作生成 HFile 持久化到 HDFS 中,随着用户的写入,生成的 HFile 数目会逐步增多,这会影响用户的读操作,同时也会系统占用(HDFS 层 block 的数目, regionserver 服务器的文件描述符占用), region split 操作,region reopen 操作也会受到不同程度影响。 HBase 通过 Compaction 机制将多个 HFile 合并成一个 HFile 以控制每个 Region 内的 HFile 的数目在一定范围内, 当然 Compaction 还有其他的作用,比如数据本地化率,多版本数据的合并,数据删除标记的清理等等,本文不做展开。
另外还有一点需要知道的是,HBase 中 Flush 操作和 Compaction 操作和读写链路是由独立线程完成的,互不干扰。
四. 系统开销定量分析
为了简化计算,本节针对事件类数据写吞吐型场景,对 HBase 系统中的开销做定量的分析,做以下假设:
- 数据写入的 Rowkey 是打散的,不存在写热点
- 数据写入量及总量是可评估的,会对数据做预先分区,定量分析基于 region 分布稳定的情况下
- 假设随机读的数目很小,小到可以忽略 IO 开销,且对读 RT 不敏感
- 数据没有更新,没有删除操作,有生命周期TTL设置
- HBase 写入链路中不存在随机磁盘,所以随机 IOPS 不会成为瓶颈
- 一般大数据机型的多个 SATA 盘的顺序写吞吐大于万兆网卡
- 忽略掉RPC带来的额外的带宽消耗
4.1 系统变量
- 单条数据大小 -> s (bytes)
- 峰值写 TPS -> T
- HFile 副本数→ R1 (一般为3)
- WAL 副本数 → R2 (一般为3)
- WAL 数据压缩比 → Cwal (一般是1)
- HFile 压缩比 → C (采用 DIFF + LZO, 日志场景压缩比一般为 0.2左右)
- FlushSize → F (这里跟 regionserver 的 memstore 内存容量,region 数目,写入是否平均和 flushsize 的配置有关,简化分析,认为内存是足够的 128MB)
- hbase.hstore.compaction.min → CT (默认是 3, 一般情况下,决定了归并系数,即每次 compaction 参与的文件数目,在不存在 compaction 积压的情况下, 实际运行时也是在 3 左右)
- 数据生命周期 → TTL (决定数据量的大小,一般写吞吐场景,日志会有一定的保存周期, 单位天)
- 单机数据量水位 → D ( 单位 T,这里指 HDFS 上存放 HFile 数据的数据量平均分担到每台机器上)
- MajorCompaction 周期 → M( hbase.hregion.majorcompaction 决定,默认 20 天)
以上 11 个参数,是本次量化分析中需要使用到的变量,系统资源方面主要量化以下两个指标:
- 磁盘开销
- 网络开销
4.2 磁盘容量开销量化分析
这里只考虑磁盘空间方面的占用,相关的变量有:
- 单条数据大小 s
- 峰值写入 TPS
- HFile 副本数 R1
- HFile 压缩比 c
- 数据生命周期 TTL
HFile的磁盘容量量化公式
V = TTL * 86400 * T * s * C * R1
假设 s = 1000, TTL = 365, T = 200000, C = 0.2 , R1 = 3 的情况下,HFile 磁盘空间需求是:
V = 30 * 86400 * 200000 * 1000 * 0.2 * 3 = 311040000000000.0 bytes
= 282T
在这里我们忽略了其他占用比较小的磁盘开销,比如:
- WAL的磁盘开销,在没有 Replication,写入平均的情况下,WAL 的日志量约定于 (hbase.master.logcleaner.ttl /1000) * s * TPS + totalMemstoreSize
- Compaction 临时文件,Split 父 Region 文件等临时文件
- Snapshot 文件
- 等等
4.3 网络开销量化分析
HBase中会造成巨大网络开销的主要由一下三部分组成,他们是相互独立,异步进行的,这里做个比方,HBase 这三个操作和人吃饭很像,这里做个类比
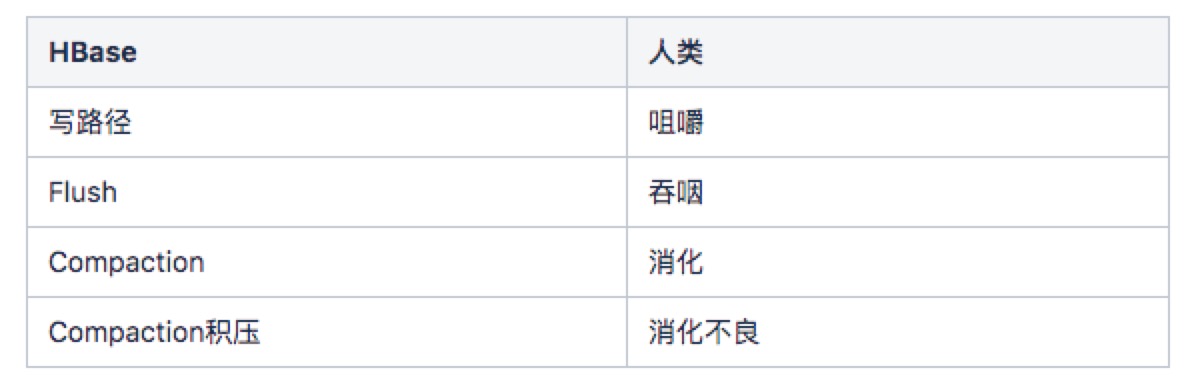
回归正题,下面按照发生顺序,从三个角度分别分析:
- 写路径
- Flush
- Compaction
4.3.1 写路径
写路径的网络开销,主要是写 WAL 日志方面, 相关的变量有:
- 单条数据大小 s
- 峰值写入 TPS
- WAL 副本数 R2
- WAL 压缩比 Cwal
写路径中,产生的网络流量分为两部分,一部分是写 WAL 产生的流量,一部分是外部用户 RPC 写入的流量, In 流量和 Out 流量计算公式为:
NInWrite = T * s * Cwal * (R2 - 1) + (T * s )
NOutWrite = T * s * Cwal * (R2 - 1)
假设 T = 20W,s = 1000, Cwal = 1.0, R2 = 3
NInwrite = 200000 * 1000 * 1 * (3-1) + 200000 * 1000 = 600000000 bytes/s
= 572MB/s
NOutwrite = 200000 * 1000* 1 * (3-1)
= 400000000 bytes/s
= 381MB/s
4.3.2 Flush
Flush 的网络开销,主要是生成 HFile 后,将 HFile 写入到 HDFS 的过程,相关的变量有:
- 单条数据大小 s
- 峰值写入 T
- HFIle 副本数 R1
- HFile 压缩比 C
Flush 产生的 In 流量和 Out 流量计算公式为:
NInWrite = s * T * (R1 - 1) * C
NOutWrite = s * T * (R1 - 1) * C
假设 T = 20W, S = 1000, R1 = 3, C = 0.2
NInwrite = 200000 * 1000 * (3 - 1) * 0.2 = 80000000.0 bytes/s
=76.3MB/s
NOutwrite = 200000 * 1000 * (3 - 1) * 0.2 = 120000000.0 bytes/s
=76.3MB/s
4.3.3 Compaction
Compaction 比较复杂,在有预分区不考虑 Split 的情况下分为两类:
- Major Compaction
- Minor Compaction
两者是独立的,下面将分别针对两种 Compaction 做分析,最后取和:
4.3.3.1 Major Compaction
Major Compaction 的定义是由全部 HFile 参与的 Compaction, 一般在发生在 Split 后发生,或者到达系统的 MajorCompaction 周期, 默认的 MajorCompaction 周期为 20 天,这里我们暂时忽略 Split 造成的 MajorCompaction 流量. 最终 Major Compaction 开销相关的变量是:
- 单机数据量水位 D
- HFIle 副本数 R1
- MajorCompaction 周期 → M (默认 20 天)
这里假设数据是有本地化的,所以 MajorCompaction 的读过程,走 ShortCircuit,不计算网络开销,并且写 HFile 的第一副本是本地流量,也不做流量计算,所以 MajorCompaction 的网络流量计算公式是:
NInMajor = D * (R1 - 1) / M
NOutMajor = D * (R1 - 1) / M
假设 D = 10T, R1 = 3, M = 20
NInMajor = 10 * 1024 * 1024 * 1024 * 1024 * (3 - 1) / (20 * 86400)
= 12725829bytes/s
= 12MB/s
NOutMajor = 10 * 1024 * 1024 * 1024 * 1024 * (3 - 1) / (20 * 86400)
= 12725829bytes /s
= 12MB/s
4.3.3.2 Minor Compaction
量化之前,先问一个问题,每条数据在第一次 flush 成为 HFile 之后,会经过多少次 Minor Compaction?
要回答这个问题之前,要先了解现在 HBase 默认的 compaction 的文件选取策略,这里不展开,只做简单分析,MinorCompaction 选择的文件对象数目,一般处于 hbase.hstore.compaction.min(默认 3)和 hbase.hstore.compaction.max(默认 10)之间, 总文件大小小于 hbase.hstore.compaction.max.size(默认 Max), 如果文件的 Size 小于 hbase.hstore.compaction.min.size(默认是 flushsize), 则一定会被选中; 并且被选中的文件size的差距不会过大, 这个由参数 hbase.hstore.compaction.ratio 和 hbase.hstore.compaction.ratio.offpeak 控制,这里不做展开.
所以,在 Compaction 没有积压的情况下,每次 compaction 选中的文件数目会等于 hbase.hstore.compaction.min 并且文件 size 应该相同量级, 对稳定的表,对每条数据来说,经过的 compaction 次数越多,其文件会越大. 其中每条数据参与 Minor Compaction 的最大次数可以用公式 math.log( 32000 / 25.6, 3) = 6 得到
这里用到的两个变量是:
- FlushSize 默认是 128 MB
- HFile 压缩比例,假设是 0.2
所以刚刚 Flush 生成的 HFile 的大小在 25.6MB 左右,当集齐三个 25.6MB 的 HFile 后,会触发第一次 Minor Compaction, 生成一个 76.8MB 左右的 HFile

对于一般情况,单个 Region 的文件 Size 我们会根据容量预分区好,并且控制单个 Region 的 HFile 的总大小 在 32G 以内,对于一个 Memstore 128MB, HFile 压缩比 0.2, 单个 Region 32G 的表,上表中各个 Size 的 HFile 数目不会超过 2 个(否则就满足了触发 Minor Compaction 的条件)
32G = 18.6G + 6.2G + 6.2G + 690MB + 230MB + 76.8MB + 76.8MB
到这里,我们知道每条写入的数据,从写入到 TTL 过期,经过 Minor Compaction 的次数是可以计算出来的。 所以只要计算出每次 Compaction 的网络开销,就可以计算出,HBase 通过 Minor Compaction 消化每条数据,所占用的总的开销是多少,这里用到的变量有:
- 单条数据大小 s
- 峰值写入 T
- HFIle 副本数 R1
- HFile 压缩比 C
计算公式如下:
NInMinor = S * T * (R1-1) * C * 总次数
NOutMinor = S * T * (R1-1) * C * 总次数
假设 S = 1000, T = 20W, R1 = 3, C = 0.2, 总次数 = 6
NInminor = 1000 * 200000 * (3 - 1) * 0.2 * 6 = 480000000.0bytes/s
= 457.8MB/s
NOutminor = 1000 * 200000 * (3 - 1) * 0.2 * 6 = 480000000.0bytes/s
= 457.8MB/s
4.3.4 网络资源定量分析小结
在用户写入 TPS 20W, 单条数据大小 1000 bytes的场景下,整体网络吞吐为:
NIntotal = NInwrite + NInflush + NInmajor + NInminor
= 572MB/s + 76.3MB/s + 12MB/s + 457.8MB/s
= 1118.1MB/s
NOuttotal = NOutwrite + NOutflush + NOutmajor + NOutminor
= 381MB/s + 76.3MB/s + 12MB/s + 457.8MB/s
= 927.1MB
当然这是理想情况下的最小开销,有很多种情况,可以导致实际网络开销超过这个理论值, 以下情况都会导致实际流量的升高:
- 预分区不足或者业务量增长,导致 Region 发生 Split, Split 会导致额外的 Compaction 操作
- 分区写入不平均,导致少量 region 不是因为到达了 flushsize 而进行 flush,导致 flush 下来的文件 Size 偏小
- HFile 因为 balance 等原因导致本地化率低,也会导致 compaciton 产生更多的网卡开销
- 预分区数目过多,导致全局 memstore 水位高,memstore 没办法到达 flushsize 进行 flush,从而全局都 flush 出比较小的文件
- 等等
有了这个量化分析后,我们能做什么优化呢? 这里不深入展开,简单说几点已经在有赞生产环境得到验证具有实效的优化点:
- 业务�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%86%99%E5%90%9E%E5%90%90%E5%9C%BA%E6%99%AF%E8%B5%84%E6%BA%90%E6%B6%88%E8%80%97%E9%87%8F%E5%8C%96%E5%88%86%E6%9E%90%E5%8F%8A%E4%BC%98%E5%8C%96/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


