分布式机器学习平台架构设计

文章作者:赵喜生 机器学习平台架构师
导读:用户数据大规模积累、用户体验需求升级、算力革新和计算模型的演进,这三大核心要素及其相互作用成为现在和未来基于网络互联用户活动的主要组成部分。机器学习平台作为使数据、计算和用户体验三者相互作用的关键基础设施发挥着作用。
▶ 数据
用户在APP上每个点击,划过,从一个APP切换到另一APP,在每个页面的停留,甚至浏览的注意力和速度;屏幕、电池、GPS定位、运动传感器……等设备的运行数据。人们的各种数据无时不刻的被记录、存储和计算。
数据的用途也从事务交易、统计分析到体验优化进行了一个完整的演进迭代。
▶ 算力&计算模型
从单核CPU到HPC,再到基于微内核的GPU,外存和内存容量和速度的不断增长,万兆网络、InfiniBand、RDMA网络技术的发展和应用。我们走过的短短数十年中,算力的革新已经是有很大的变化,同时适配于计算硬件的新的计算模型的发展:从分布式的RPC,到基于低I/O成本的MapReduce,发展到GPU的矩阵运算等,计算模型也在影响着软件开发的变革。
▶ 用户体验
最开始用户是在基于命令行/桌面进行指令性交互,随后门户时代是基于类目组织的信息浏览,搜索引擎给我们带来的是用户主动信息检索体验,而今各种Feed大行其道。用户在“懒”的道路上一路向前,用户参与信息交互更广、更深,信息获取更加简单高效。
用户、数据和计算正在以前所未有的程度参与并加速重构人类生活方式。
01 全栈机器学习平台
一个良好的机器学习平台产品需要满足整个数据科学的完整生命周期的各个环节。在产品设计方面需要考虑到:
▶ 全栈用户体验
用户数据科学的所有活动需要在一个产品中无缝且无差别体验地完成,这是解放数据科学家生产力,服务数据科学家聚焦于其核心工作的基础
▶ 工程能力和数据科学解耦
完成一个完整的数据接入、特征处理、模型训练优化及模型上线服务的整体工作,尤其在面向大规模/超大规模数据和模型的情况下,数据存储格式,多机多卡协同计算,资源调度管理,模型弹性伸缩等工程化工作是必不可少的。让用户对无感知或者提供易用的自定义完成对复杂工程的应用
▶ 开放性
通常一个团队中的数据科学具有不同的技术背景,不同的计算框架有其特定,通用的机器学习平台面向的场景和任务具有多样性;平台要对变化开发,以高效的方式支持不同用户的需求

02 关键架构因素
构建机器学习平台需要的技术包括了存储、通信、计算、分布式、资源管理等计算机体系中的很多技术,在项目周期及成本条件下设计一个面向业务且具有生命力的机器学习平台架构,需要考虑诸多因素:
▶ 遗留系统集成
通常在组织中已经存在数据存储、资源调度和任务调度系统,架构设计需要拥抱这些遗留系统。对遗留系统良好的集成不仅可以提升用户体验,降低系统复杂程度,还可以缩短实现周期。
▶ 数据和模型规模
数据量、模型的复杂程度和规模以及用户对模型训练周期的容忍度决定了技术选型和核心能力的设计方式。
* ▶ 资源管理调度
依托于Kubernetes或者YARN设计资源队列,进行异构资源管理调度,确保资源的合理高效利用。
▶ Pipeline
一方面对数据接入、特征工程、训练及上线等环节通过Pipeline组织,驱动数据在不同计算组件中运转起来,合理利用内存共享,避免低效I/O,从而系统性降低数据处理周期。
▶ Serving系统
Serving是一个相对独立的子系统,需要考虑E2E预测延时,弹性伸缩能力,模型版本管理,监控,A/B分流等能力,一般Serving都是无状态的,适合用微服务的架构来实现。
▶ 数据存储和表示
在数据源,特征工程及模型训练阶段数据可能以不同形式存储在不同的介质上;同时数据有Dense或者Sparse不同特点,以及数据可能存储在单机或者分布式多节点上。需要考虑数据存储格式,存储介质,分布式表示方式。
▶ 并行化
并行化不仅仅存在于训练阶段,同样存在于数据访问,特征处理甚至在Serving阶段。
▶ 计算加速
除了基于GPU的CUDA加速,我们同样可以在Intel CPU上用合适的计算库来实现加速。
▶ 网络通信
尤其在训练复杂网络的情况下,通信可能是主要的性能瓶颈;合理的网络拓扑和连接方式,以及采用高效的通信协议会降低计算等待。
03 架构设计
此处我们以面向:存储在HDFS上TB级用户和物品数据训练面向CTR场景的Embedding+MLP结构的模型,提供在线低延时且可弹性伸缩的排序服务,这样一个具有通用场景展开机器学习平台的架构设计。
▶ Hadoop集成
数据的传输和存储成本很高,利用已有Hadoop体系的完成机器学习平台中合适的组件将有效降存储和传输成本,同时也在一定程度上让平台变的轻量。利用Hadoop Kerberos安全机制可以将数据和资源调度基于租户隔离开。
在计算方面可以用 Data Locality 特性将计算和数据调度到同一结点上,业界的 TensorFlowOnSpark 和 Angel 都用这个思路实现Hadoop体系和机器学习的结合。简单来说该方案是:
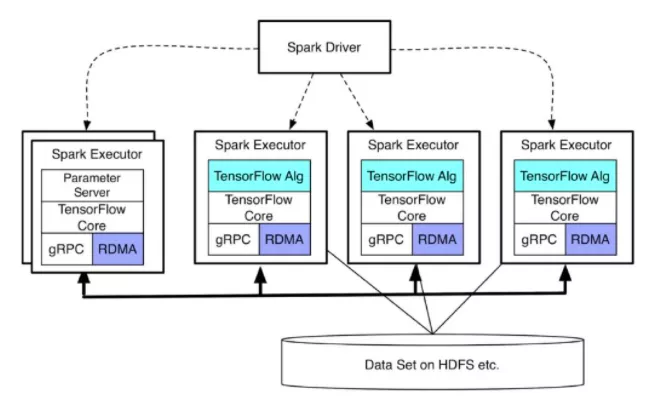
- 通过YARN调度提交一个Spark作业
- 在Spark中调用
foreachPartition,这样每个结点上将会在内存中持有RDD的一个分区 - 在每个Worker中通过JNI调用或者本地进程的方式调用Tensorflow或者Torch进行模型计算
这样相当于Spark变成Container进行计算资源的调度,而充分利用了已有的大数据体系的数据和计算特性。
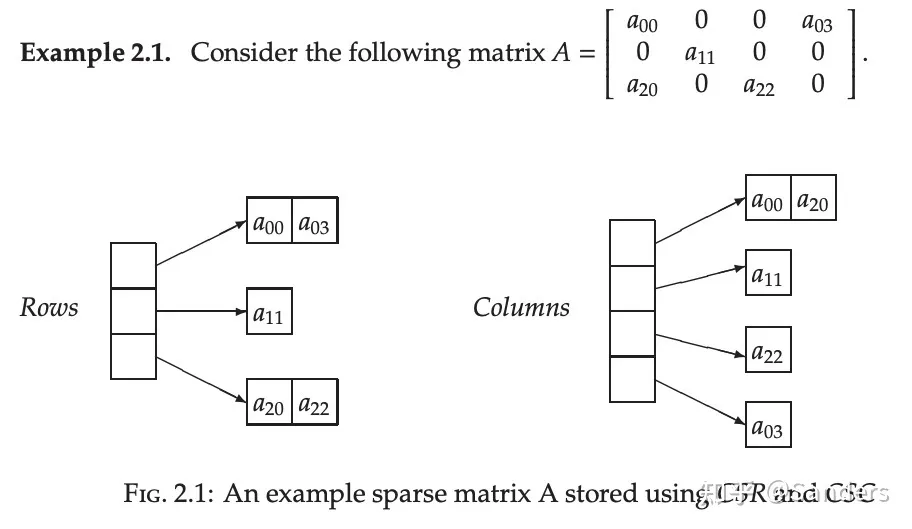
▶ 稀疏特征压缩&向量/矩阵分布式表示
在分布式机器学习计算中对分布式向量和矩阵的分布式表示以及对稀疏特征的压缩处理可以提高数据的并行计算度和存储压缩比,Spark中会采用RowMatrix, CoordinateMatrix和BlockMatrix等存储来对不同形式的数据类型进行矩阵进表示。
业界也有很多标准的稀疏矩阵和分布式矩阵表示方法。
▶ 特征处理Pipeline
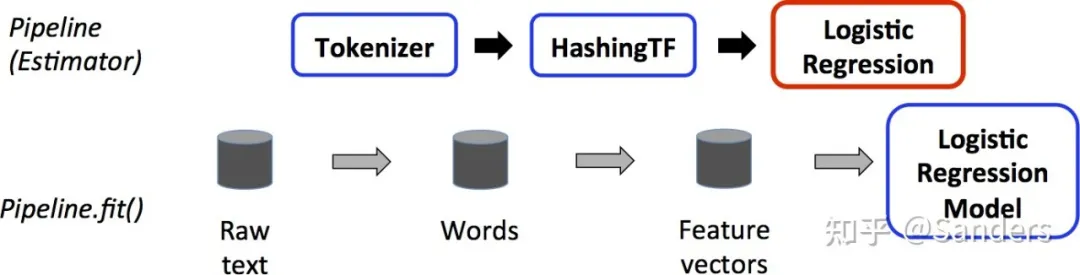
在特征处理过程中,需要对离散和连续的特征进行 分桶, 标准化, Onehot 编码等特征处理。Berkeley Data Analytics Stack中的Spark是非常适用于特征处理,采用Spark进行特征处理可以帮我们解决三个主要的问题:
1. 内存计算,加速特征处理
由于特征处理过程中大部分情况不需要进行数据Shuffle,这样我们可以很好的利用Spark内存计算,将多个特征处理用Spark ML Pipeline串联起来,这样可以在分布式的将多个特征处理环节在一个Job中完成。
2. Feature Map一致性
Pipeline中的每个算子都是一个 Estimator,我们在 fit 阶段计算特征的 Feature Map(例如Onehot编码中离散值对应Index),然后在模型 save 阶段对 Feature Map 进行序列化存储,在 transform 阶段对特征进行编码。 fit 时可以尽可能加载全量数据,这样在特征处理时就降低没有出现过样本值出现的机率,对于 Feature Map 的更新可以根据实时性要求进行Stream更新或者Batch全量更新。
特征处理阶段生成的 Feature Map 也会在Oneline阶段被加载。
3. 特征格式
在进行模型训练阶段,可能 CSR, TFRecordn 或者其他数据格式,可以实现自定义数据类型,让Spark来读写自定义的数据格式。
首先实现自定义 FileReader 和 OutputWriter
在自定义数据源中用自定义 FileReader 和 OutputWriter 实现 read 和 write
def write(kryo: Kryo, out: Output): Unit = {}def read(kryo: Kryo, in: Input): Unit = {}
首先在 org.apache.spark.sql.sources.DataSourceRegister 中添注册自定义数据源类型
然后就可以像处理CSV格式数据一样 spark.read.format("csv"),处理自定义数据格式
▶ 并行计算
在大规模数据和模型训练的场景中,由于训练样本规模大或者网络参数大,通常单个节点不能完成对模型的训练,这时就需要多节点协同的方式完成模型的训练,采用分而治之的思想。一般会有数据并行和模型并行两种思路来实现任务的分解和并行训练。
1. 数据并行
为不同的计算节点保留同一个模型的副本,每个节点分配到不同的数据,每个节点在本地计算持有数据的模型参数,然后将所有计算节点的计算结果按照某种方式合并生成最终的模型。
在这个过程中数据拆分的方式可以是随机的方式,也可以采用shuffle机制保证数据样本的均衡;而参数同步和合并方式主流的有 Parameter Server 和 Ring All-Reduce 方式。
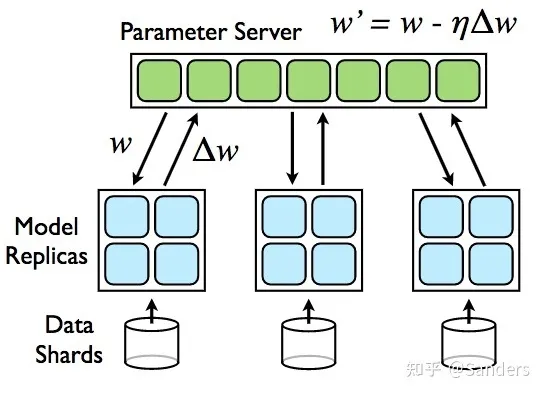
Parameter Server:
在Parameter Server架构中,集群中的节点被分为两类:Parameter Server和Worker。其中Parameter Server存放模型的参数,而Worker负责计算参数的梯度。在每个迭代过程,Worker从Parameter Sever中获得参数,然后将计算的梯度返回给Parameter Server,Parameter Server聚合从Worker传回的梯度,然后更新参数,并将新的参数广播给Worker。
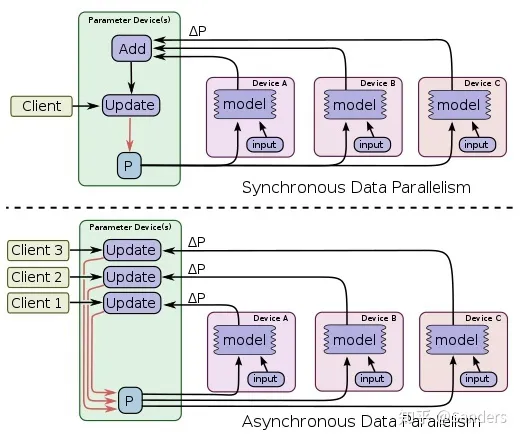
其中参数在Parameter Server和Worker之间的同步既可以是同步的 ( Synchronous ),也可以是异步的 ( Asynchronous )。
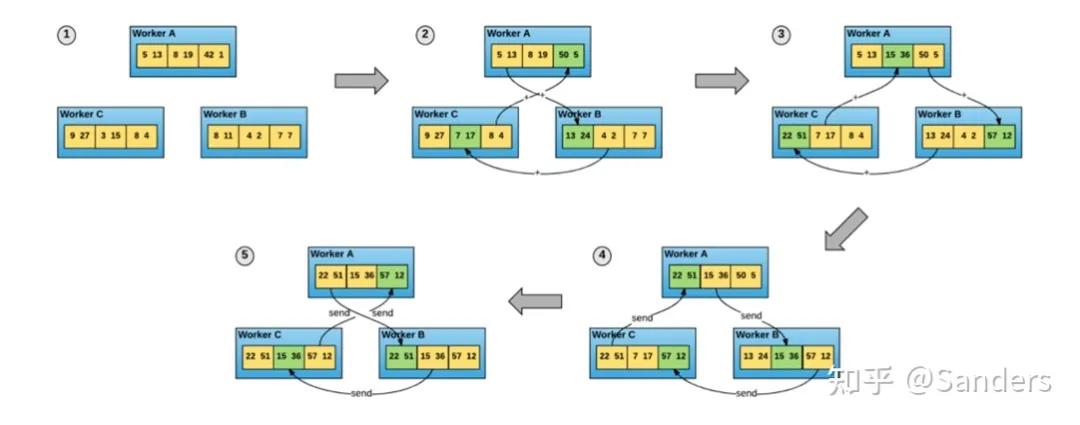
Ring AllReduce:
在Ring-Allreduce架构中,各个节点都是Worker,没有中心节点来聚合所有Worker计算的梯度。在一个迭代过程,每个Worker完成自己的mini-batch训练,计算出梯度,并将梯度传递给环中的下一个Worker,同时它也接收从上一个Worker的梯度。对于一个包含N个Worker的环,各个Worker需要收到其它N-1个worker的梯度后就可以更新模型参数。
2. 模型并行
如果训练模型的规模很大,不能在每个计算节点的本地内存中完全存储,那么就可以对模型进行划分,然后每个计算节点负责对本地局部模型的参数进行更新。通常对线性可分的模型和非线性模型(神经网络),模型并行的方法也会有所不同。
线性模型:
把模型和数据按照特征维度进行划分,分配到不同的计算节点上,在每个计算节点上采用梯度下降优化算法进行优化,局部的模型参数计算不依赖于其他维度的特征,相对独立,那么就不需要与其他节点进行参数交换。
在Angel的实现中就主要使用模型并行的方法使用 ModelPartitioner 实现模型分布式计算。

神经网络:
神经网络中模型具有很强的非线性性,参数之间有较强的关联依赖,通常可以横向按层划分或纵向跨层划分进行网络划分。每个计算节点计算局部参数然后通过RPC将参数传递到其他节点上进行参数的合并,复杂的神经网�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%88%86%E5%B8%83%E5%BC%8F%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E5%B9%B3%E5%8F%B0%E6%9E%B6%E6%9E%84%E8%AE%BE%E8%AE%A1/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


