分布式追踪系统概述及主流开源系统对比
导 读
分布式追踪系列文章来了!
本周推送为该系列的上篇,主要介绍了分布式追踪系统的原理、“可观察性” 的三大支柱、OpenTracing标准,同时对当前主流的开源分布式追踪系统进行简单对比。
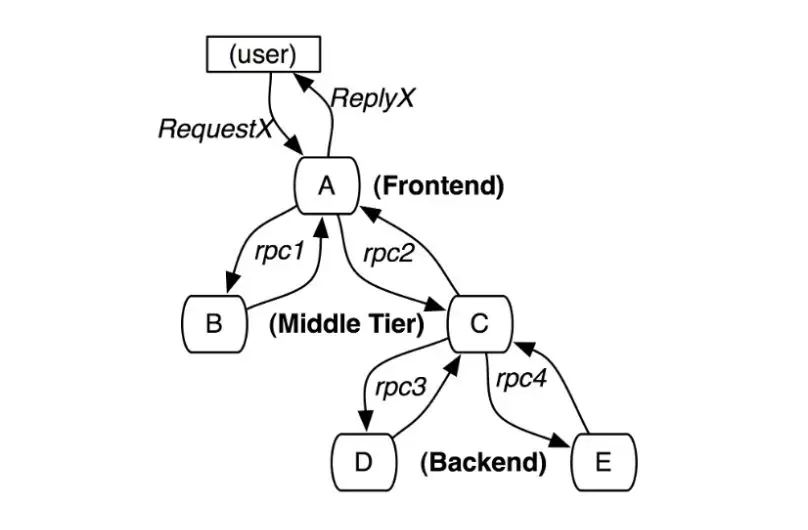
图片来源: Dapper, a Large-Scale Distributed
Systems Tracing Infrastructure
随着应用容器化和微服务的兴起,借由 Docker 和 Kubernetes 等工具,服务的快速开发和部署成为可能,构建微服务应用变得越来越简单。但是随着大型单体应用拆分为微服务,服务之间的依赖和调用变得极为复杂,这些服务可能是不同团队开发的,可能基于不同的语言,微服务之间可能是利用 RPC、 RESTful API,也可能是通过消息队列实现调用或通讯。如何理清服务依赖调用关系、如何在这样的环境下快速 debug、追踪服务处理耗时、查找服务性能瓶颈、合理对服务的容量评估都变成一个棘手的事情。
可观察性
(Observability)
及其三大支柱
为了应对这些问题,可观察性( Observability) 这个概念被引入软件领域。传统的监控和报警主要关注系统的异常情况和失败因素,可观察性更关注的是从系统自身出发,去展现系统的运行状况,更像是一种对系统的自我审视。一个可观察的系统中更关注应用本身的状态,而不是所处的机器或者网络这样的间接证据。我们希望直接得到应用当前的吞吐和延迟信息,为了达到这个目的,我们就需要合理主动暴露更多应用运行信息。在当前的应用开发环境下,面对复杂系统我们的关注将逐渐由点到点线面体的结合,这能让我们更好的理解系统,不仅知道What,更能回答Why。
可观察性目前主要包含以下三大支柱:
-
日志(
Logging):Logging主要记录一些离散的事件,应用往往通过将定义好格式的日志信息输出到文件,然后用日志收集程序收集起来用于分析和聚合。目前已经有 ELK 这样的成熟方案, 相比之下日志记录的信息最为全面和丰富,占用的存储资源正常情况下也最多,虽然可以用时间将所有日志点事件串联起来,但是却很难展示完整的调用关系路径; -
度量(
Metrics)Metric往往是一些聚合的信息,相比Logging丧失了一些具体信息,但是占用的空间要比完整日志小的多,可以用于监控和报警,在这方面 Prometheus 已经基本上成为了事实上的标准; -
分布式追踪(
Tracing)Tracing介于Logging和Metric之间, 以请求的维度,串联服务间的调用关系并记录调用耗时,即保留了必要的信息,又将分散的日志事件通过 Span 串联, 帮助我们更好的理解系统的行为、辅助调试和排查性能问题,也是本文接下来介绍的重点。
Logging, Metrics 和 Tracing 既各自有其专注的部分,也有相互重叠的部分。
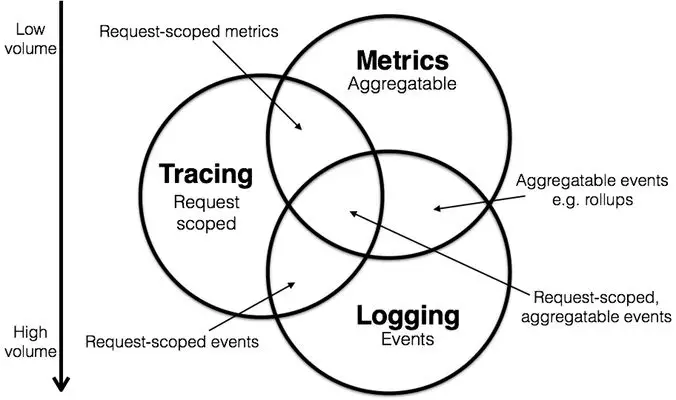
图片来源:Metrics, tracing, and logging
近年来 Metric 和 Tracing 有融合的趋势,现在很多流行的 APM (应用性能管理)系统,如 Datadog 就融合了 Tracing 和 Metric 信息。
就在写这篇文章的同时,在 KubeCon 2019``CNCF 宣布 OpenTracing 和 Google 发起的的 OpenCensus 项目合并。目前新项目仍在建设中,不过已经承诺了对现有 OpenTracing 协议提供兼容。
下面是 CNCF 总结的当前流行的实现可观察性系统的常见软件或服务, Monitoring 栏中以 Prometheus 为代表,本身可以实现 Metric 的收集监控,不过结合图中其他工具可以实现更加强大和完善的监控方案:
 图片来源: CNCF Cloud Native Landscape
图片来源: CNCF Cloud Native Landscape
分布式追踪系统
**(Tracing)** 定位及其标准
Tracing的功能定位
-
故障定位——可以看到请求的完整路径,相比离散的日志,更方便定位问题(由于真实线上环境会设置采样率,可以利用debug开关实现对特定请求的全采样);
-
依赖梳理——基于调用关系生成服务依赖图;
-
性能分析和优化——可以方便的记录统计系统链路上不同处理单元的耗时占用和占比;
-
容量规划与评估;
-
配合
Logging和Metric强化监控和报警。
最早由于Google的论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》,让 Tracing 流行起来。而Twitter基于这篇论文开发了 Zipkin 并开源了这个项目。再之后业界百花齐放,诞生了一大批开源和商业 Tracing 系统。
OpenTracing 标准
由于近年来各种链路监控产品层出不穷,当前市面上主流的工具既有像 Datadog 这样的一揽子商业监控方案,也有 AWS X-Ray 和 Google Stackdriver Trace 这样的云厂商产品,还有像 Zipkin、 Jaeger 这样的开源产品。
云原生基金会( CNCF) 推出了 OpenTracing 标准,推进 Tracing 协议和工具的标准化,统一 Trace 数据结构和格式。 OpenTracing 通过提供平台无关、厂商无关的 API,使得开发人员能够方便的添加(或更换)追踪系统的实现。比如从 Zipkin 替换成 Jaeger/ Skywalking 等后端。
在 OpenTracing 中,主要定义以下基本概念:
-
Trace(调用链): OpenTracing中的Trace(调用链)通过归属于此调用链的Span来隐性的定义。一条Trace(调用链)可以被认为是一个由多个Span组成的有向无环图(DAG图), Span与Span的关系被命名为References;
-
Span(跨度):可以被翻译为跨度,可以被理解为一次方法调用,一个程序块的调用,或者一次RPC/数据库访问,只要是一个具有完整时间周期的程序访问,都可以被认为是一个span。
单个 Trace 中, Span 间的因果关系:
1 [Span A] ←←←(the root span)
2 |
3 +------+------+
4 | |
5 [Span B] [Span C] ←←←(Span C 是 Span A 的孩子节点, ChildOf)
6 | |
7 [Span D] +---+-------+
8 | |
9 [Span E] [Span F] >>> [Span G] >>> [Span H]
10 ↑
11 ↑
12 ↑
13 (Span G 在 Span F 后被调用, FollowsFrom)
每个 Span 包含的操作名称、开始和结束时间、附加额外信息的 Span Tag、可用于记录 Span 内特殊事件 Span Log、用于传递 Span 上下文的 SpanContext 和定义 Span 之间关系的 References。
关于 SpanContext
SpanContext 是 OpenTracing 中非常重要的概念,在创建 Span、向传输协议 Inject(注入)和从传输协议中 Extract(提取)调用链信息时, SpanContext 发挥着重要作用。
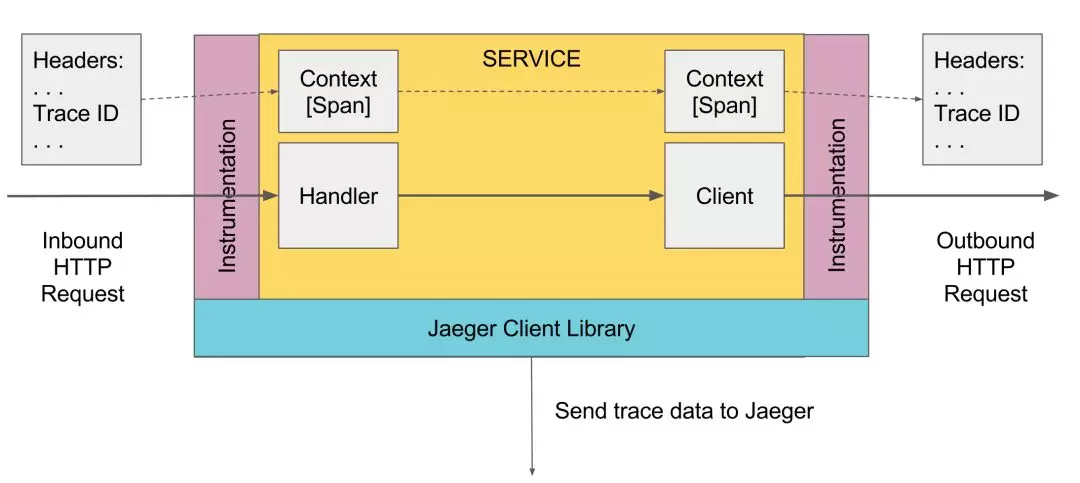
图片来源: Jaeger Architecture
SpanContext 数据结构如下:
1SpanContext:
2- trace_id: "abc123"
3- span_id: "xyz789"
4- Baggage Items:
5 - special_id: "vsid1738"
-
trace_id和span_id区分Trace中的Span; -
Baggage Items和Span Tag结构相同,唯一的区别是:Span Tag只在当前Span中存在,并不在整个trace中传递,而Baggage Items会随调用链传递。
在跨界(跨服务或者协议)传输过程中实现调用关系的传递和关联,需要能够将 SpanContext 向下游介质注入,并在下游传输介质中提取 `SpanContex
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%88%86%E5%B8%83%E5%BC%8F%E8%BF%BD%E8%B8%AA%E7%B3%BB%E7%BB%9F%E6%A6%82%E8%BF%B0%E5%8F%8A%E4%B8%BB%E6%B5%81%E5%BC%80%E6%BA%90%E7%B3%BB%E7%BB%9F%E5%AF%B9%E6%AF%94/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


