初探文本表示学习
原文出自 : 丁香园大数据 NLP
两段式,可以大致认为 Deepwalk 就是「 如何将带结构信息的数据喂给 word2vec」。我们知道 word2vec 的训练方式(原文采用 SkipGram)是通过中心词(target)预测窗口内的词(context),所以 Deepwalk 的采样过程可以看作「 如何定义和获取图上节点的 context」。这里 Deepwalk 给出最基本的方法,就是定义任意中心节点到邻接节点的跳转概率,然后跳转一定次数作为该中心节点的 context,这样就组成了 word2vec 接受的输入样本:(target,context)

可以认为 Deepwalk 确立了一种通用的 Graph Embedding 求解框架,即:(1) 定义中心节点的邻域及采样方法;(2) 设计(target, neighbors)的 embedding 模型。后续的 Graph Embedding 模型及很多复杂的 GNN 模型其实也都是改进这两个框架的具体操作,例如下面的 LINE 和 Node2vec。
- LINE: Large-scale Information Network Embedding [2]
在 Deepwalk 之后较短的时段内(2014 年之后),多数工作直接延用了 word2vec 训练 embedding 向量的方式,并将重点放在如何改进中心节点邻域的采样方法上。LINE 的关键改进就在于对 context 的设定,作者提出了一阶和二阶两种邻域关系,如下图所示
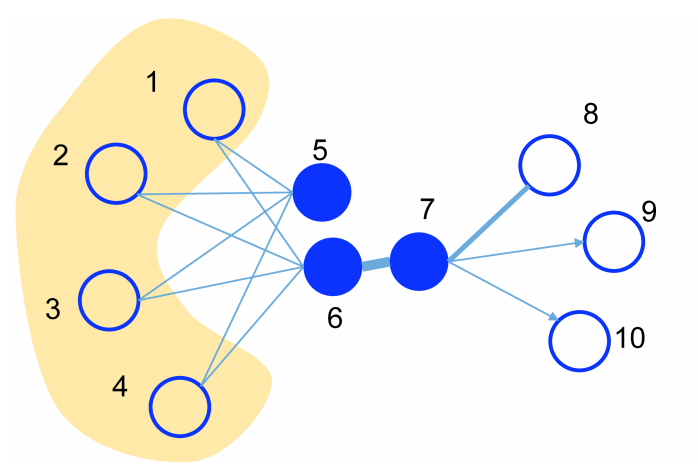
一阶相邻就是直接相连,二阶相邻则是取两个邻接节点邻居的重合部分;这样,一阶关系可以采样出(target, neighbor),二阶关系则会采样出(target, neighbors);对此,可以分别用 sigmoid 和 softmax 计算二元组的概率分布;在计算 loss 时,如果将两种采样方式合并计算,会得到一组 embedding,也可以考虑分开计算 loss,得到两组 embedding weights,再用 concat([first_order_embed, second_order_embed])合并。
- node2vec: Scalable Feature Learning for Networks [3]
Node2vec 也沿用了 word2vec 的训练方式,而在采样上比 LINE 更接近 Deepwalk 的思路。不过作者进一步思考了节点间的距离和节点本身的位置这些结构信息的意义。
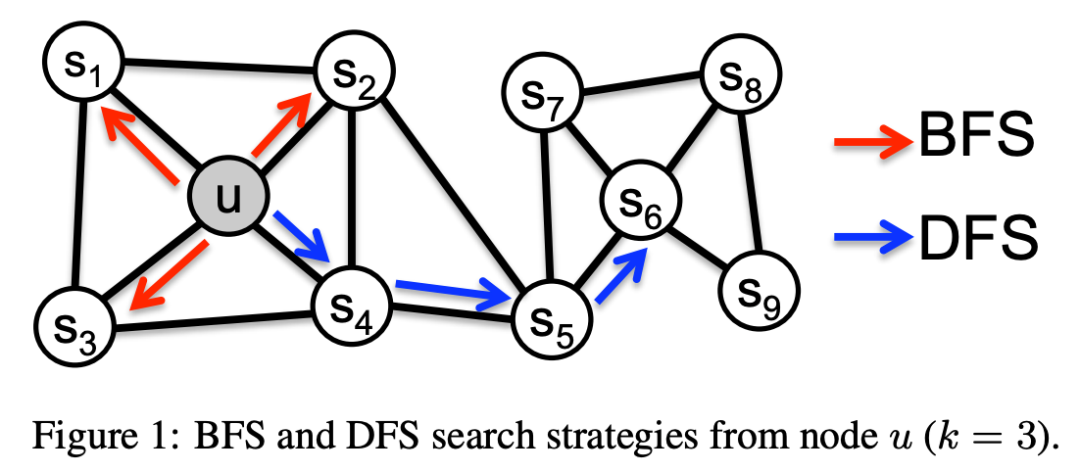
我们知道图的遍历有深度优先(DFS)和广度优先(BFS)两种,采用 DFS 会更容易采样到较远的点,而 BFS 倾向于发掘周围的点。对此,作者提出了两个概念来描述这种位置结构:(1): 同质性(homophily),指紧密围绕从而形成一个社群(community)的节点,比如图上的 u 和 s_2 ; (2): 结构性(structural equivalence),只虽然距离较远因而不能构成同一个社群,但彼此社群中都处于类似的位置,比如图上的 u 和 s_6 (注意,作者表示 DFS 更侧重同质性,BFS 倾向于结构性,和大家的理解一致么)
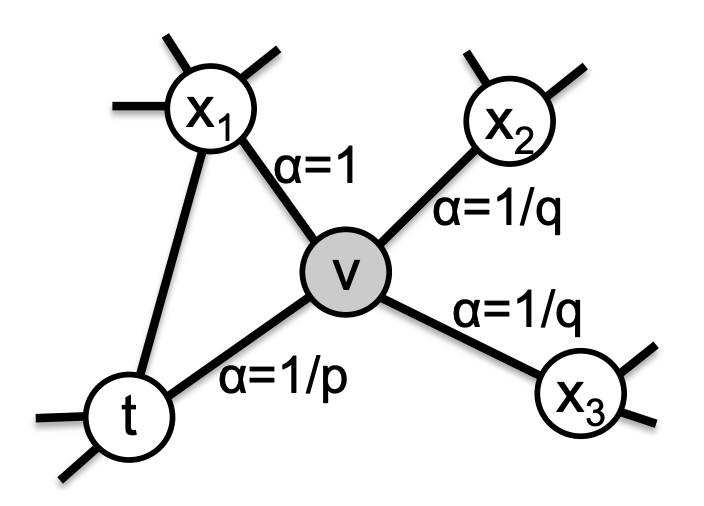
基于这两种结构性质,作者扩展了 Deepwalk 的采样方法,设定了两个概率参数 p 和 q ,分别是回退参数(p: return parameter)和进出参数(q: in-out parameter),如上图所示,当前节点从 t 到 v ,如果 p 降低,则退回到 t 的概率就越大,q 降低则驱使算法走向新节点;控制这两个参数就可以改变 context 的采样结果,影响最终 emebdding 结果。
还有诸如 SDNE,EGES 这类工作都属于 Graph Embeding 方法,操作简单实用性高,在图的节点数量很大时,下面的 GNN 方法不太容易训练应用,传统 Graph Embeding 方法依然有大量戏份。
Graph Neural Networks
GNN 的正式定义大约来源于 2009 年的这篇文章[4],随后经历了大约 6 年的沉寂直到 2014 年,受 word2vec 的启发,包括前文提到的一系列 Graph Embedding 算法相继出现;再之后,大概 2017 年起,各类结合了 Gated 机制,CNN,Attention 的 GNN 模型结构不断被提出;时至今日,基于 GNN 的研究已经深入诸多领域,新颖概念层出不穷;笔者初窥门径,以下仅选个别有代表性的工作简单介绍。
- GCN: SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS [5]
融入 CNN 形成的 GCN 框架可能是最流行的 GNN 之一,然而 CV 领域大放异彩的 CNN 并不能直接用在属于非欧空间的图结构上,直观的说法是" 图结构中邻居节点的个数不固定,卷积核无法计算",因此需要某种转换操作, 要么固定邻居节点个数,要么将非欧空间的图转换到欧式空间,本节文章中的 GCN 就属于后者,这就引出了 GCN 的核心之一的 Laplacian 算子;下面我们先解释图的空间变换。
描述 Laplacian 算子 不得不提 Fourier 变换,我们知道 Fourier 变换可以将时域函数转换到频域的"线性变换",公式大概长这样:
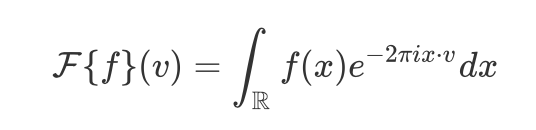
需要关注的是 e^{-2 piixv} 这个"基向量",就是它将时域函数 f(x)映射到以它为基的频域空间;那么对于 GCN,关键就在于找到这个"基向量",通过"图 Fourier 变换"完成非欧空间到欧式空间的映射,这才引出 Laplacian 算子;参照 wiki 上的中文定义[6]:拉普拉斯算子或是拉普拉斯算符(Laplace operator, Laplacian)是由欧几里得空间中的一个函数的梯度的散度给出的微分算子;先做梯度运算,再做散度运算,简单说就是二阶导数,它描述了二维空间中某种量的传播状态;最终,研究者们找到了拉普拉斯矩阵 L 作为 Laplacian 算子,并用 L 的特征向量作为基向量执行"图 Fourier 变换",L 就是图的度矩阵减去邻接矩阵,取 L 的特征向量组 U 为"图 Fourier 变换"的基向量(这里仅简单描述 Laplacian 算子的作用意义,有关 Laplacian 算子和 Fourier 变换的公式推导有很多精彩的文章珠玉在前,这里便不做赘述)。
Laplacian 算子和图 Fourier 变换是 GCN 的基石,不过 GCN 的内容远不止如此,图卷积网络的框架是多篇文章不断改进的结果,这里引用的工作算是博采众长,早在 2014 年[7]就有研究提出了用拉普拉斯矩阵的特征分解实现卷积,但计算中包含的特征分解计算复杂度高,因此另一个让 GCN 应用广泛的贡献是通过**切比雪夫多项式(Chebyshev)**近似图卷积计算,引文第二段集中介绍了该近似过程,综合改进后的 GCN 如引文中的公式 2 所示,其中 HW 就如同 CNN 运算一般,前面矩阵 A 和 D 的运算就是图卷积的近似。
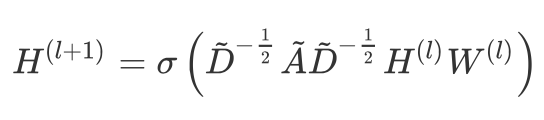
最后,这类对整张图做特征提取的方法被称为 Transductive approaches,下面要介绍另一类 Inductive approaches 中有代表性的 GraphSAGE。
- GraphSAGE: Inductive Representation Learning on Large Graphs [8]
Transductive approaches 都有一个问题,就是必须要对全图操作,这样一方面内存会限制图的规模,另一方面想更新图结构就不得不重新处理整张图;GraphSAGE 的一个好处就是"以偏概全",不再对整张图做变换和卷积,而是 采样固定个数邻居 并基于这种 target-neighbors 的子图结构训练 聚合函数(AGGREGATE),这样一方面可以根据需求,通过控制邻居个数来增减图的规模,另一方面对于新加入的节点,完全可以用训练好的聚合函数获得 embedding 表示或其他下有任务结果。

其实看算法流程很容易想象整个流程,基本也符合 deepwalk 的两段式,值得注意的就是其中的 AGGREGATE,文中对比了四种聚合函数:lstm,gcn,mean,pool(max);大家可以参照文中的对比实验选择合适自己任务的方法。此外,作者在文中也给出了针对无监督和有监督的不同 loss 设定,无监督继续采用类似 word2vec 的方式,有监督任务则替换成适合特定目标的损失即可,另外本文发表于 2017 年,Transformer 也是同年发表,而今结合 self-attention 做聚合函数的工作已经非常多了,框架上基本也和 GraphSAGE 一致,很容易替换扩展。
总体来说,本文无论是思路,结构还是源码都比较简单,对应到工程落地,可以参考同一团队在 KDD2018 发表的,基于 Pinterest 公司推荐系统的实践工作[9];不过,我们尝试用 GraphSAGE 直接学习文本知识的 embedding 时,感觉并不十分理想,首先是当图的规模非常大时训练比较慢,收敛情况与子图采样密切相关,找采样参数需要大量实验;另外需要注意,源码中构造图结构用的是 Python 的 networkx 库,这个库是基于 dict 存储的,比较费内存;最后,我们的文本知识包含大约 150w 节点,1 亿条边,无监督训练的结果不够理想,当然很可能是数据量不足以及还没找到合适的采样参数,不过,这种规模的图对我们来说已经很大了,用稀疏矩阵存储会更省资源,不过得用 sparse 的 API 重写整个结构,所以如果有办法可以直接对稀疏矩阵做计算得到 embedding 岂不省事许多,下一节的 ProNE。
- ProNE: Fast and Scalable Network Representation Learning [10]
本文大概应该归为 Graph Embedding 一类,因为并没有 GCN 和 GraphSAGE 这些框架中的多层网络结构,不过本文第二部分的 embedding 过程应用了 GCN 中 spectual 方法的思路,在 GCN 之后介绍也更合适。本文将图表示学习的模型分为三类,GNN 归为一类,前文的 Deepwalk、LINE、node2vec 属于 skip-gram 类,ProNE 则属于矩阵分解类模型。
ProNE 整体可分为两部分, 第一部分对无向图结构的邻接矩阵做稀疏矩阵分解。作者定义了如下损失函数最大化节点 r 和邻居 c 的共现频率 p,同时最小化负采样邻居概率:
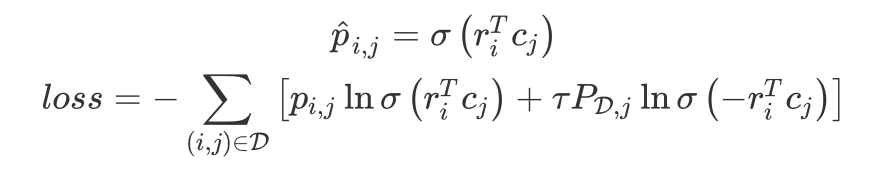
最小化 loss 的充分条件是 loss 对 r*{i}^{T} c*{j} 的偏导数为 0,可得节点 r 和邻居 c 的的距离公式并构造距离矩阵
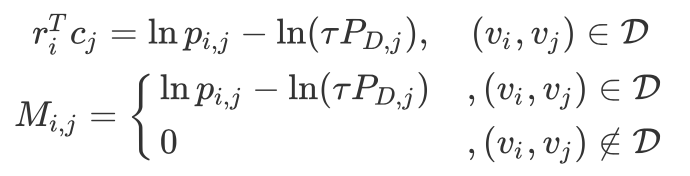
对距离矩阵 M 做 tSVD(truncated Singular Value Decomposition)并取最后 top-d 的奇异值和对应向量作为这一部分的节点 embedding 表示,为了效率,作者用 randomized tSVD 加速运算。
第二部分利用高阶 Cheeger 不等式(higher-order Cheeger’s inequality),上一步仅利用了每个节点的局部邻居,这里借鉴 GCN 中 spectrum 方法的思路设计了传播策略(propagation strategy),目的是获取图结构中的局部平滑(localized smoothing)信息和全局聚类(global clustering)信息,而 Cheeger 不等式为我们解释了图结构谱方法的特征值与局部平滑(localized smoothing)信息和全局聚类(global clustering)信息之间的关系。
首先,GCN 部分的引文中其实介绍了,图 Fourier 变换实际上是一次图 Fourier 变换加一次逆变换,这个过程可以理解为:先由拉普拉斯矩阵的特征向量组 U 将 X 映射到对应向量空间,用特征值 lambda_k 缩放 X ,再被逆变换处理;然后,在图分割理论(graph partition)中有一个 k-way Cheeger 常量 \rho_{G}(k) ,这个常量越小表示图的划分越好,直观的表述大概是"子图聚合程度越高,该常量对应越小,相对的划分就越好";最后我们通过高阶 Cheeger 不等式将拉普拉斯矩阵的特征值和这个常量联系起来
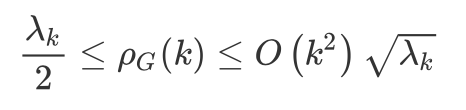
上式表明 Cheeger 常量对应着特征值的上下界,更小的常量对应更小的特征值,也对应着更内聚(clustering)的子图,反之对应更大的特征值,此时图结构中的子图更为平滑(smoothing);因此,在这部分里,作者设计了一个函数 g 用于控制特征值的取值范围,此时的图 Fourier 变换为
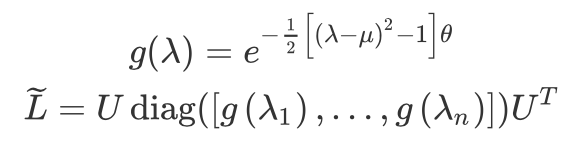
最后,再参照 GCN 中利用切比雪夫多项式近似计算 \widetilde{L} 即可,整个过程可以看作 限制特征值范围的 GCN,注意最后为保证正交性,还需要对 Embedding 结果做一次 SVD。
我们知道通常对于大规模图结构,Graph Embedding 在效率上的价值更为明显,ProNE 在效率方面比 Deepwalk、LINE、node2vec 都要出色,文中的时间对比表明,在 5 个常见的 GNN 数据集上(PPI、Wiki、BlogCatalog、DBLP、Youtube),ProNE 比效率最好的 LINE 快大概 9-50 倍;我们用 150w 节点,1 亿条边的稀疏矩阵做文本知识学习,默认参数(128 维向量,迭代 10 次)耗时大概 1 小时以内;具体来说,我们试图识别出每个文本知识词汇中包含的特定类别词,例如下面的"口腔咽喉黏膜充血"中的"口腔、咽喉、黏膜"均为身体部位;“卵巢雄激素肿瘤"中包含的"卵巢"属于身体部位类词汇,“肿瘤"属于常见病症词的词根,按照包含词以及类别构建邻接图,应用 ProNE 方法,并按 cosine 计算相关词汇,结果看起来还不错:


出色的 efficient 兼顾不错的 effective,源码的 Python 版是用 networkx 加载图结构,这部分完全可以用 scipy.sparse 的 API 替换,只有一点美中不足,和 GCN 一样不能直接应用于有向图,所以下面为大家介绍一篇有关文本有向图 Embedding 的工作 SynGCN。
- Incorporating Syntactic and Semantic Information in Word Embeddings using Graph Convolutional Networks [11]
本文将 GNN 应用于 Word Embedding 任务,框架上基本采用 GraphSAGE 的邻居采样 + 编码函数聚合信息的模式,训练上也与 word2vec 类似,值得关注的是其融合有向图的 SemGCN 结构
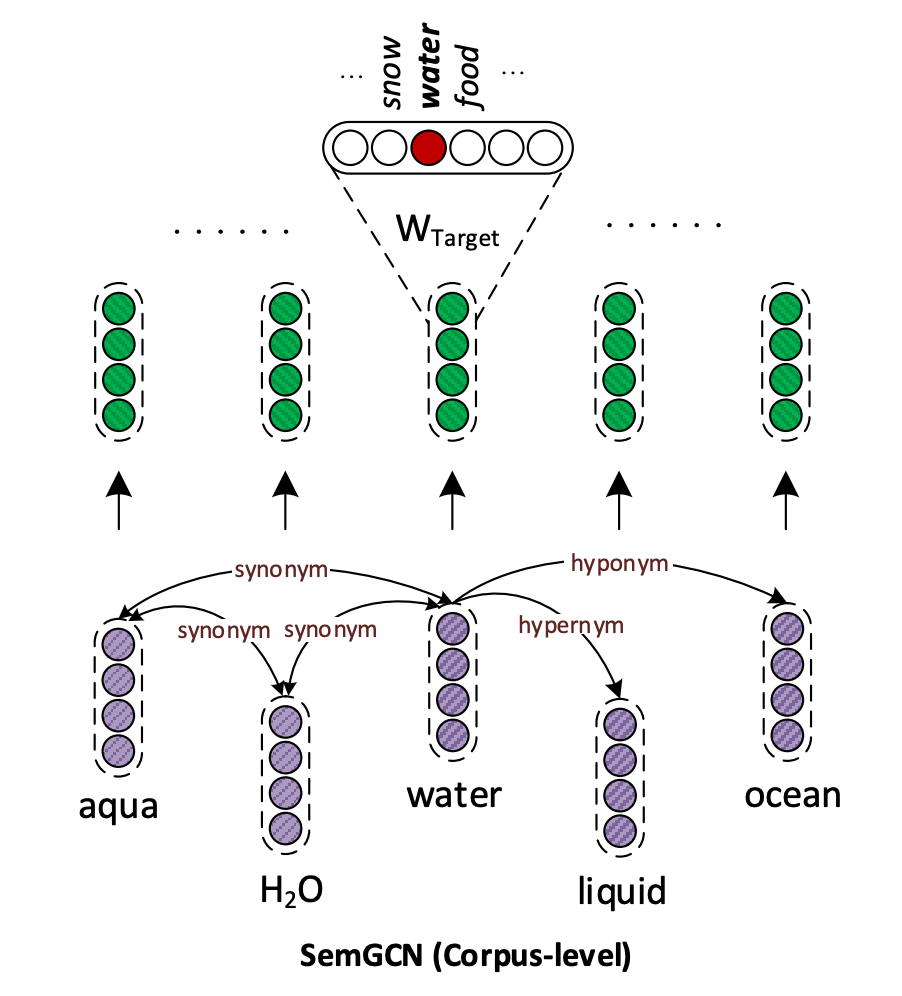
具体而言,word2vec 的 context 在这里由 target 词的知识组成,在编码过程中我们希望对有向边做特别处理,其实这里有向图就起到了一个线性组合的作用,对有向图的融合非常简单,就是构造一个有向图的邻接矩阵,对原有的特征 embedding 矩阵 M 做线性变换,与 M 叠加后再过下一个编码层。这种线性组合的方式很容易上手,而且至少对个别节点做微调效果立竿见影,不过大规模应用是否普遍有效还需要进一步检验,我们还没做进一步试验,这里仅作为一种思路介绍。
总结
本文仅简要列举了几项图结构表示学习发展中有代表性的工作供大家参考;GCN 和 GraphSAGE 代表了图结构转换两种处理角度,就表示学习而言,或许是受图规模和计算资源的限制,后续工作中倾向于后者的采样方法的占比较高,但"图 Fourier 变换"的思路非常精彩不容忽视,而且在流形学习等领域也有诸多应用;基于子图训练聚合函数的方向上,除了尝试更有效的编码结构外,如何扩展和结合更丰富的图结构信息应该是更关键的方向,除了上文提到的有向图外,在推荐系统中已经出现了很多基于**异构信息网络(heterogeneous information network[12])**的工作,用于结合节点和边对应的不同类别或语义;当然回归工程实践,我们不该忽略 Graph Embedding 类的方法,也不该将其与 GNN 割裂开,上文提到的 ProNE 中的传播策略完全可以用于其他方法的 Embedding 向量上,基于此类方法再训练 GraphSAGE 有可能更容易收敛,简单的有向图线性组合也具有指导意义。下一步我们也希望在 ProNE 的基础上尝试更多深层结构,并基于有向图线性组合的思路,调整图结构来贴合不同应用任务。
参考文献
[1] [http
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%88%9D%E6%8E%A2%E6%96%87%E6%9C%AC%E8%A1%A8%E7%A4%BA%E5%AD%A6%E4%B9%A0/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


