及核心原理及实践
Spark 已经成为广告、报表以及推荐系统等大数据计算场景中首选系统,因效率高,易用以及通用性越来越得到大家的青睐,我自己最近半年在接触 spark 以及 spark streaming 之后,对 spark 技术的使用有一些自己的经验积累以及心得体会,在此分享给大家。本文依次从 spark 生态,原理,基本概念,spark streaming 原理及实践,还有 spark 调优以及环境搭建等方面进行介绍,希望对大家有所帮助。
spark 生态及运行原理
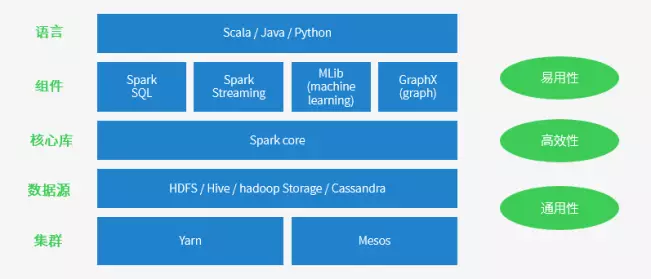
Spark 特点
运行速度快 => Spark 拥有 DAG 执行引擎,支持在内存中对数据进行迭代计算。官方提供的数据表明,如果数据由磁盘读取,速度是 hadoop MapReduce 的 10 倍以上,如果数据从内存中读取,速度可以高达 100 多倍。
适用场景广泛 => 大数据分析统计,实时数据处理,图计算及机器学习
易用性 => 编写简单,支持 80 种以上的高级算子,支持多种语言,数据源丰富,可部署在多种集群中
容错性高。Spark 引进了弹性分布式数据集 RDD (Resilient Distributed Dataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据 “血统”(即充许基于数据衍生过程) 对它们进行重建。另外在 RDD 计算时可以通过 CheckPoint 来实现容错,而 CheckPoint 有两种方式:CheckPoint Data,和 Logging The Updates,用户可以控制采用哪种方式来实现容错。
Spark 的适用场景
目前大数据处理场景有以下几个类型:
复杂的批量处理 (Batch Data Processing),偏重点在于处理海量数据的能力,至于处理速度可忍受,通常的时间可能是在数十分钟到数小时;
基于历史数据的交互式查询 (Interactive Query),通常的时间在数十秒到数十分钟之间
基于实时数据流的数据处理 (Streaming Data Processing),通常在数百毫秒到数秒之间
Spark 成功案例 目前大数据在互联网公司主要应用在广告、报表、推荐系统等业务上。在广告业务方面需要大数据做应用分析、效果分析、定向优化等,在推荐系统方面则需要大数据优化相关排名、个性化推荐以及热点点击分析等。这些应用场景的普遍特点是计算量大、效率要求高。腾讯 / yahoo / 淘宝 / 优酷土豆
spark 运行架构
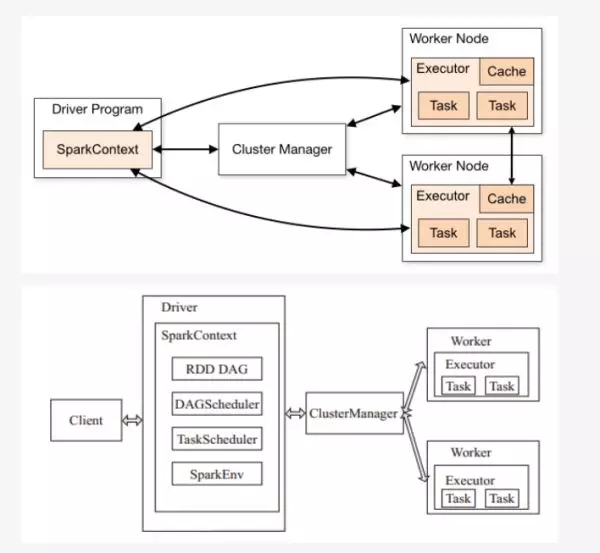
spark 基础运行架构如下所示:
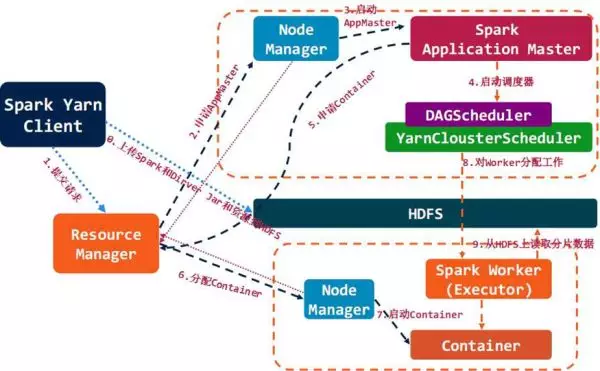
spark 结合 yarn 集群背后的运行流程如下所示:
spark 运行流程:
Spark 架构采用了分布式计算中的 Master-Slave 模型。Master 是对应集群中的含有 Master 进程的节点,Slave 是集群中含有 Worker 进程的节点。Master 作为整个集群的控制器,负责整个集群的正常运行; Worker 相当于计算节点,接收主节点命令与进行状态汇报; Executor 负责任务的执行; Client 作为用户的客户端负责提交应用,Driver 负责控制一个应用的执行。
Spark 集群部署后,需要在主节点和从节点分别启动 Master 进程和 Worker 进程,对整个集群进行控制。在一个 Spark 应用的执行过程中,Driver 和 Worker 是两个重要角色。Driver 程序是应用逻辑执行的起点,负责作业的调度,即 Task 任务的分发,而多个 Worker 用来管理计算节点和创建 Executor 并行处理任务。在执行阶段,Driver 会将 Task 和 Task 所依赖的 file 和 jar 序列化后传递给对应的 Worker 机器,同时 Executor 对相应数据分区的任务进行处理。
Excecutor /Task 每个程序自有,不同程序互相隔离,task 多线程并行,
集群对 Spark 透明,Spark 只要能获取相关节点和进程
Driver 与 Executor 保持通信,协作处理
三种集群模式:
Standalone 独立集群
Mesos, apache mesos
Yarn, hadoop yarn
基本概念:
Application =>Spark 的应用程序,包含一个 Driver program 和若干 Executor
SparkContext => Spark 应用程序的入口,负责调度各个运算资源,协调各个 Worker Node 上的 Executor
Driver Program => 运行 Application 的 main() 函数并且创建 SparkContext
Executor => 是为 Application 运行在 Worker node 上的一个进程,该进程负责运行 Task,并且负责将数据存在内存或者磁盘上。每个 Application 都会申请各自的 Executor 来处理任务
Cluster Manager => 在集群上获取资源的外部服务 (例如:Standalone、Mesos、Yarn)
Worker Node => 集群中任何可以运行 Application 代码的节点,运行一个或多个 Executor 进程
Task => 运行在 Executor 上的工作单元
Job => SparkContext 提交的具体 Action 操作,常和 Action 对应
Stage => 每个 Job 会被拆分很多组 task,每组任务被称为 Stage,也称 TaskSet
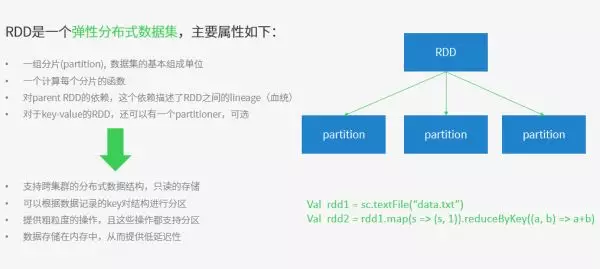
RDD => 是 Resilient distributed datasets 的简称,中文为弹性分布式数据集; 是 Spark 最核心的模块和类
DAGScheduler => 根据 Job 构建基于 Stage 的 DAG,并提交 Stage 给 TaskScheduler
TaskScheduler => 将 Taskset 提交给 Worker node 集群运行并返回结果
Transformations => 是 Spark API 的一种类型,Transformation 返回值还是一个 RDD,所有的 Transformation 采用的都是懒策略,如果只是将 Transformation 提交是不会执行计算的
Action => 是 Spark API 的一种类型,Action 返回值不是一个 RDD,而是一个 scala 集合; 计算只有在 Action 被提交的时候计算才被触发。
Spark 核心概念之 RDD
Spark 核心概念之 Transformations / Actions
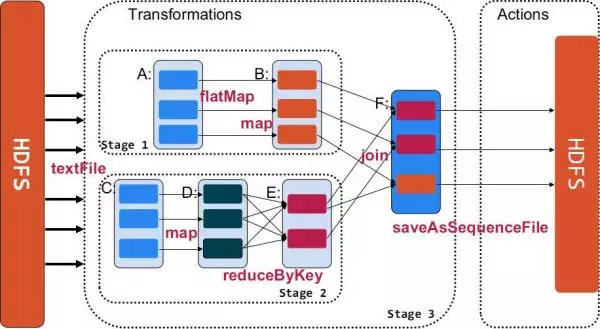
Transformation 返回值还是一个 RDD。它使用了链式调用的设计模式,对一个 RDD 进行计算后,变换成另外一个 RDD,然后这个 RDD 又可以进行另外一次转换。这个过程是分布式的。 Action 返回值不是一个 RDD。它要么是一个 Scala 的普通集合,要么是一个值,要么是空,最终或返回到 Driver 程序,或把 RDD 写入到文件系统中。
Action 是返回值返回给 driver 或者存储到文件,是 RDD 到 result 的变换,Transformation 是 RDD 到 RDD 的变换。
只有 action 执行时,rdd 才会被计算生成,这是 rdd 懒惰执行的根本所在。
Spark 核心概念之 Jobs / Stage
Job => 包含多个 task 的并行计算,一个 action 触发一个 job
stage => 一个 job 会被拆为多组 task,每组任务称为一个 stage,以 shuffle 进行划分
Spark 核心概念之 Shuffle
以 reduceByKey 为例解释 shuffle 过程。
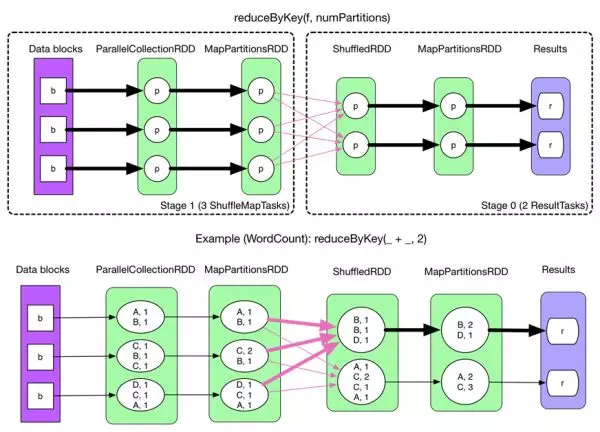
在没有 task 的文件分片合并下的 shuffle 过程如下:(spark.shuffle.consolidateFiles=false)
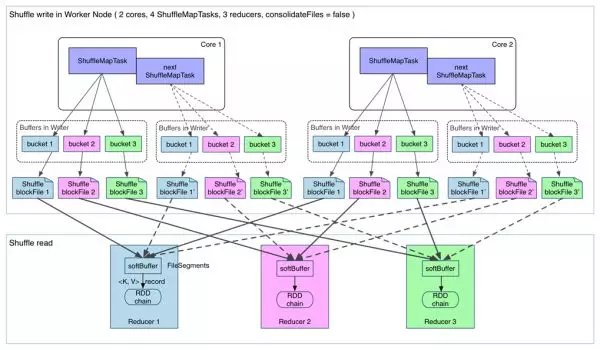
fetch 来的数据存放到哪里?
刚 fetch 来的 FileSegment 存放在 softBuffer 缓冲区,经过处理后的数据放在内存 + 磁盘上。这里我们主要讨论处理后的数据,可以灵活设置这些数据是 “只用内存” 还是 “内存 + 磁盘”。如果 spark.shuffle.spill = false 就只用内存。由于不要求数据有序,shuffle write 的任务很简单:将数据 partition 好,并持久化。之所以要持久化,一方面是要减少内存存储空间压力,另一方面也是为了 fault-tolerance。
shuffle 之所以需要把中间结果放到磁盘文件中,是因为虽然上一批 task 结束了,下一批 task 还需要使用内存。如果全部放在内存中,内存会不够。另外一方面为了容错,防止任务挂掉。
存在问题如下:
产生的 FileSegment 过多。每个 ShuffleMapTask 产生 R(reducer 个数) 个 FileSegment,M 个 ShuffleMapTask 就会产生 M * R 个文件。一般 Spark job 的 M 和 R 都很大,因此磁盘上会存在大量的数据文件。
缓冲区占用内存空间大。每个 ShuffleMapTask 需要开 R 个 bucket,M 个 ShuffleMapTask 就会产生 MR 个 bucket。虽然一个 ShuffleMapTask 结束后,对应的缓冲区可以被回收,但一个 worker node 上同时存在的 bucket 个数可以达到 cores R 个 (一般 worker 同时可以运行 cores 个 ShuffleMapTask),占用的内存空间也就达到了 cores R 32 KB。对于 8 核 1000 个 reducer 来说,占用内存就是 256MB。
为了解决上述问题,我们可以使用文件合并的功能。
在进行 task 的文件分片合并下的 shuffle 过程如下:(spark.shuffle.consolidateFiles=true)
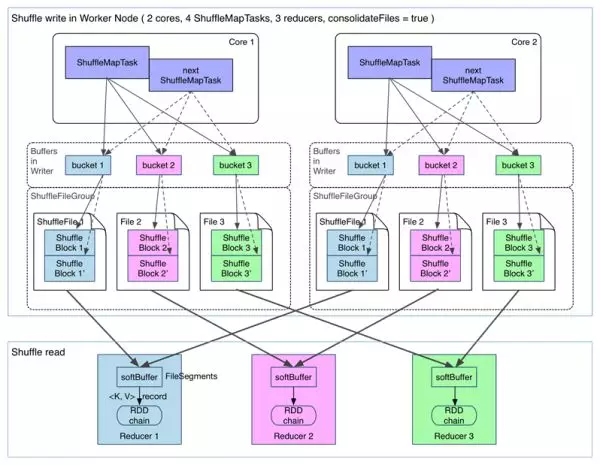
可以明显看出,在一个 core 上连续执行的 ShuffleMapTasks 可以共用一个输出文件 ShuffleFile。先执行完的 ShuffleMapTask 形成 ShuffleBlock i,后执行的 ShuffleMapTask 可以将输出数据直接追加到 ShuffleBlock i 后面,形成 ShuffleBlock i’,每个 ShuffleBlock 被称为 FileSegment。下一个 stage 的 reducer 只需要 fetch 整个 ShuffleFile 就行了。这样,每个 worker 持有的文件数降为 cores * R。FileConsolidation 功能可以通过 spark.shuffle.consolidateFiles=true 来开启。
Spark 核心概念之 Cache
val rdd1 = … // 读取 hdfs 数据,加载成 RDD
rdd1.cache
val rdd2 = rdd1.map(…)
val rdd3 = rdd1.filter(…)
rdd2.take(10).foreach(println)
rdd3.take(10).foreach(println)
rdd1.unpersist
cache 和 unpersisit 两个操作比较特殊,他们既不是 action 也不是 transformation。cache 会将标记需要缓存的 rdd,真正缓存是在第一次被相关 action 调用后才缓存; unpersisit 是抹掉该标记,并且立刻释放内存。只有 action 执行时,rdd1 才会开始创建并进行后续的 rdd 变换计算。
cache 其实也是调用的 persist 持久化函数,只是选择的持久化级别为 MEMORY_ONLY。
persist 支持的 RDD 持久化级别如下:

需要注意的问题: Cache 或 shuffle 场景序列化时, spark 序列化不支持 protobuf message,需要 java 可以 serializable 的对象。一旦在序列化用到不支持 java serializable 的对象就会出现上述错误。 Spark 只要写磁盘,就会用到序列化。除了 shuffle 阶段和 persist 会序列化,其他时候 RDD 处理都在内存中,不会用到序列化。
Spark Streaming 运行原理
spark 程序是使用一个 spark 应用实例一次性对一批历史数据进行处理,spark streaming 是将持续不断输入的数据流转换成多个 batch 分片,使用一批 spark 应用实例进行处理。
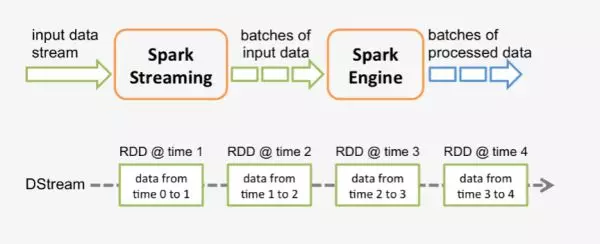
从原理上看,把传统的 spark 批处理程序变成 streaming 程序,spark 需要构建什么?
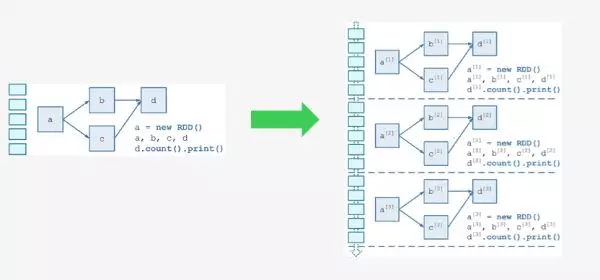
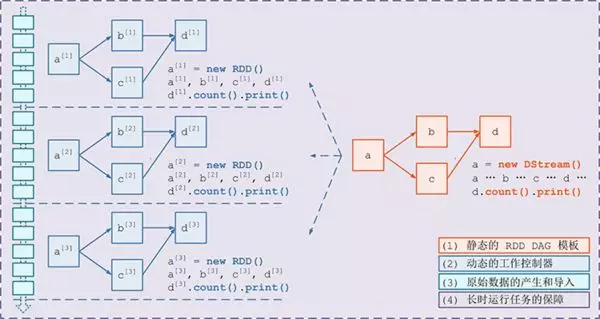
需要构建 4 个东西:
一个静态的 RDD DAG 的模板,来表示处理逻辑;
一个动态的工作控制器,将连续的 streaming data 切分数据片段,并按照模板复制出新的 RDD 3. DAG 的实例,对数据片段进行处理;
Receiver 进行原始数据的产生和导入; Receiver 将接收到的数据合并为数据块并存到内存或硬盘中,供后续 batch RDD 进行消费
对长时运行任务的保障,包括输入数据的�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%8F%8A%E6%A0%B8%E5%BF%83%E5%8E%9F%E7%90%86%E5%8F%8A%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


