同城向量检索平台架构实践
陈泽龙,58同城AI Lab后端工程师
导读: 向量检索在很多AI场景都会应用到,例如:在推荐系统中,召回环节基于用户向量计算其最相似的N个物品向量;在问答系统中,基于问题向量匹配相似的N个问题;在视频或图像检索中,通过对视频截图提取向量,然后搜索相似图像及图像对应的视频。
背景
为了满足业务上对向量检索的需求,降低学习成本,提高开发效率,我们开发并上线了向量检索平台。我们支持了Faiss算法库,实现了几种常用索引的全量索引构建、实时增量索引、实时在线检索,旨在帮助用户更快更好的使用海量高维向量相似性检索功能。
整体架构
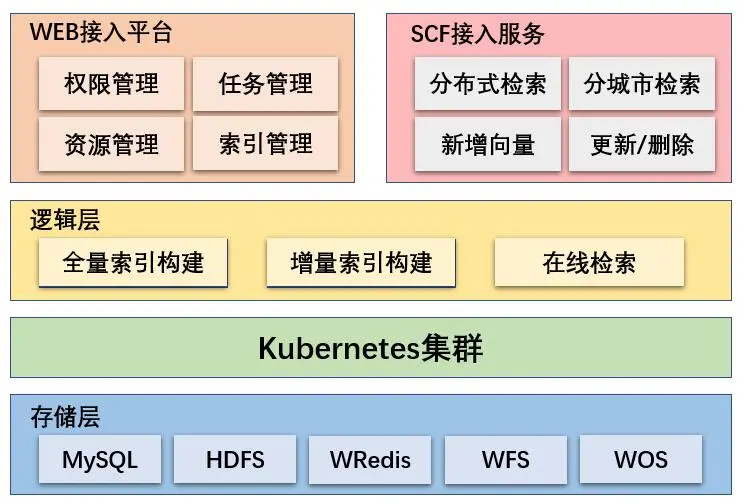
WEB接入平台: 向量检索平台提供统一的web可视化操作界面,可以进行权限管理、任务管理、资源管理、索引管理等。
SCF接入服务: 提供给业务方的SCF线上服务服务,包括分布式索引检索、分城市索引检索、线上索引的增量服务,以及更新删除向量接口。SCF( Service Communication Framework)是58自主研发的RPC框架,致力于在分布式环境下提供高性能、高可靠和透明化的RPC远程调用方案。
逻辑层: 向量检索平台的核心功能模块,提供向量数据的全量索引构建、增量索引构建功能,以及SCF服务接口的底层逻辑实现。全量索引构建模块实现对全部向量数据构建为指定类型索引文件;增量索引构建模块实现对线上索引中向量数据的新增、更新、删除;在线检索模块提供多类型索引的向量相似性检索功能的底层逻辑实现。
存储层: 提供向量原始文件、索引文件、任务信息、资源配置等数据的存储功能。其中MySQL负责存储任务信息和资源配置,HDFS和WFS负责存储原始数据文件,WOS和WFS负责存储索引文件,Redis负责存储需要增量、更新、删除的向量数据信息。其中WFS是58自研的多用户共享高性能分布式文件系统,WOS是58自研的对象存储系统,提供高性能、高可用的云端存储服务。
索引构建
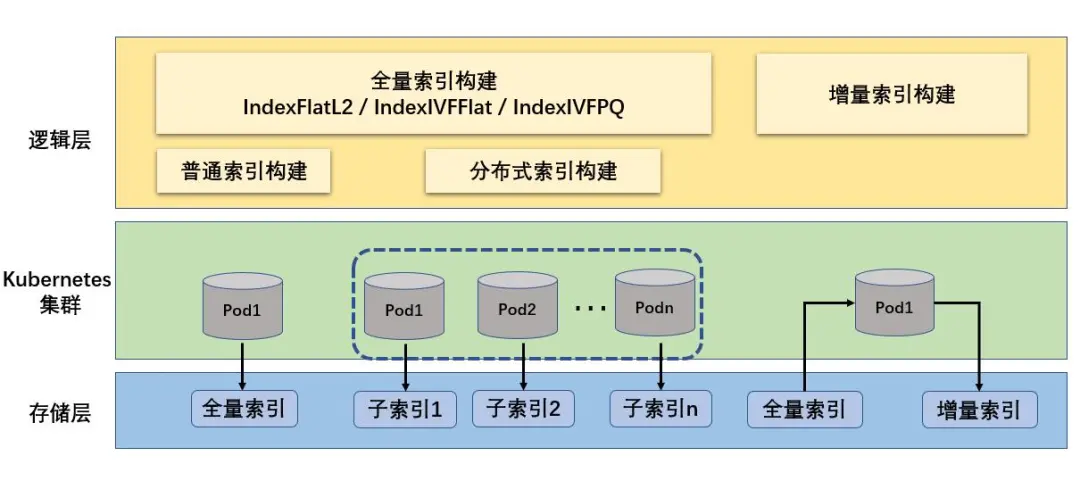
平台基于Facebook的Faiss进行向量索引的构建,目前支持三种比较具有代表性的索引全量构建,分别是IndexFlatL2(基于欧氏距离的暴力索引)、IndexIVFFlat(加聚类的倒排索引,支持欧式距离和向量内积两种距离算法)、IndexIVFPQ(加聚类、加量化的倒排索引),并且支持分布式索引(支持大规模数据的分布式索引构建)。
使用方在WEB接入平台配置数据文件的路径信息。平台下载对应路径下的数据文件到本地(HDFS路径)或直接读取数据文件(WFS路径),随机从中取出若干样本数据组成样本数据集,进行索引训练。训练成功后,将所有向量数据通过Faiss提供的新增API添加到索引中,最后将索引保存为文件,集中管理。
增量索引构建
在实际业务中,在接收到新的实体时,需要将新实体的向量增加到已构建好的全量索引中。
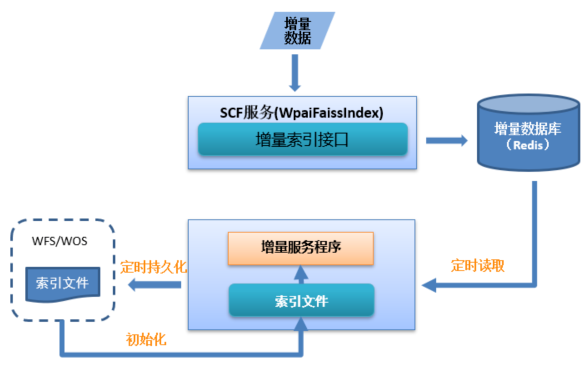
用户通过调用增量接口,实时的添加新增向量。当新增请求到来时,平台会将新增数据的相关信息存入Redis中。平台部署增量节点,增量服务程序加载构建好的全量索引,定时监测并读取Redis中对应任务的新增数据,将数据添加到全量索引中,并定时持久化到WFS和WOS中,供在线检索服务使用。
分布式索引构建
Faiss本身只是一个能够单机运行的向量检索基础算法库,不支持分布式。在海量数据的场景下,向量数据集达到百亿级及以上时,单机构建索引会产生如下问题:
- 单机处理数据量,构建索引耗时较长
- 构建的索引,可能达到百GB以上甚至达到TB级别,会超过单机物理节点的内存资源上限
针对以上问题,向量检索平台支持了分布式索引的构建,具体实现如下图所示:
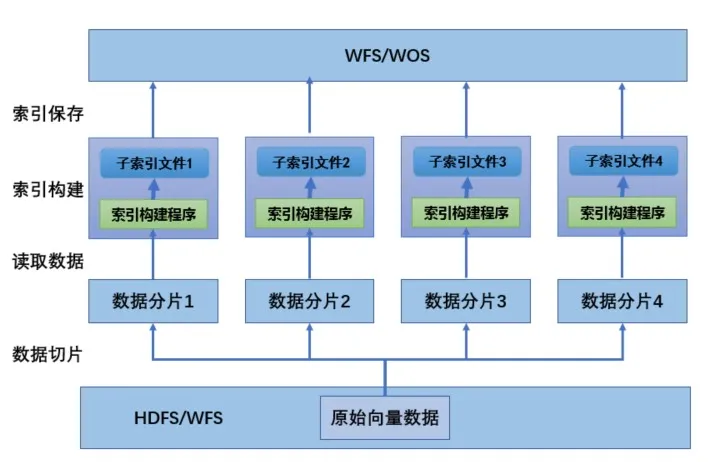
通过一致性Hash,将原始向量数据分割为多个数据分片,每个分片包含一部分的向量数据且不相交,平台为每个数据分片单独创建一个构建环境,独立的进行索引构建,并且各数据分片分别生成一份索引文件,保存到WFS和WOS系统中。通过将数据量较大的原始数据分割为多个较小的分片,实现了降低单个索引大小,提高构建效率的目的。
在线检索
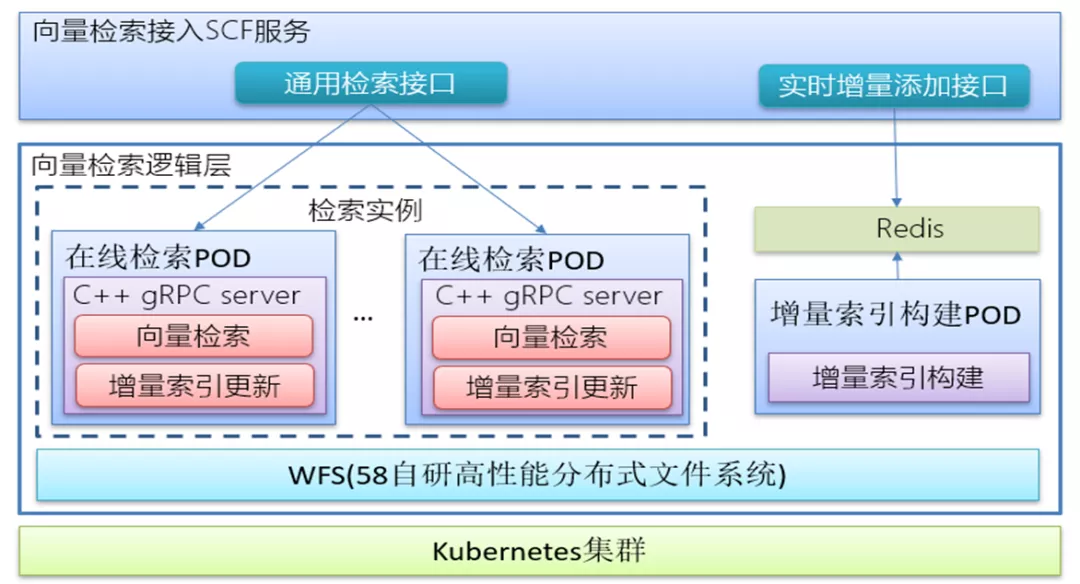
向量检索平台在线检索模块主要包括向量检索接入SCF服务和向量检索逻辑层两大部分。
向量检索接入SCF服务主要实现了请求转发和负载均衡两大功能,请求转发主要通过RPC调用,将用户发送的SCF服务请求,重新封装为检索节点的gRPC请求,实现向量检索请求和实时向量添加请求的转发。
负载均衡主要是基于动态加权轮询算法实现多个检索节点的负载均衡,根据每次gRPC请求的结果,动态调整节点权重,节点正常响应,则提升节点权重,节点请求异常(宕机或阻塞),则降低节点权重。有效提升了正常节点的流量,降低了异常节点的流量,实现了节点间的负载均衡。
向量检索逻辑层负责线上向量的检索逻辑,基于gRPC实现,将Faiss各种检索调用及增量调用封装为gRPC服务,服务采用统一的输入输出格式,通过容器的方式进行部署,由Kubernetes集群统一进行管理。
同时为了不影响检索服务的性能,平台通过读写分离实现增量索引的在线检索功能。增量数据通过向量检索接入SCF服务的实时增量添加接口缓存在WRedis中,增量索引构建POD读取WRedis的增量数据并构建到全量索引中并定时持久化保存到WFS中,在线检索POD增量索引更新定时进行索引文件检查,当发现有更新时从WFS上拉取最新索引文件加载到内存,加载完毕切换到线上进行访问,避免了索引更新可能造成的短暂服务失效。
分布式检索
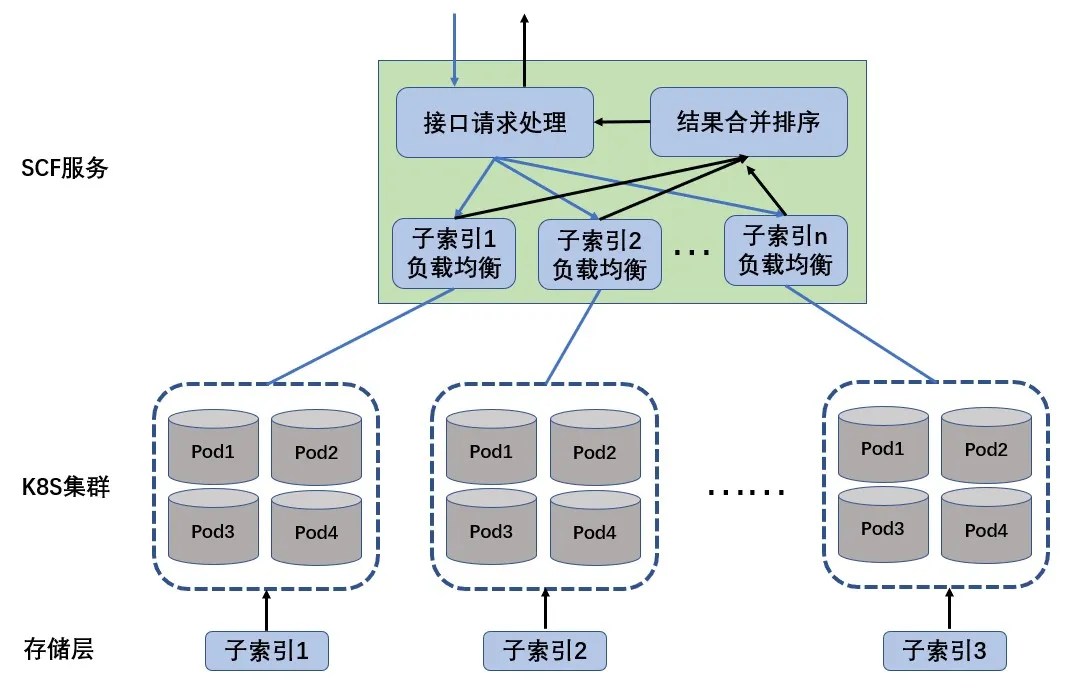
分布式在线检索采用了分片查询-汇总模式以提升检索效率,并对外提供统一的向量检索接口屏蔽底层部署实现。
服务部署时,子索引分节点部署,每个子索引分别部署多个副本节点,每个节点对外通过gRPC提供服务。SCF服务进行请求转发时,会从每个子索引的节点集合中挑选一个节点进行请求转发,并将请求结果进行合并、重排、筛选后进行返回。因此我们为每个子索引的节点集合分别部署一个负载均衡,实现子索引多个检索节点的负载均衡。
分城市检索
部分场景下,需要根据数据所属的区域对数据进行分区域检索,如在很多业务中,需要根据所在城市进行信息推荐。如果对于每个城市都创建对应的检索任务,会出现以下问题:
- 城市数量过多,每个城市分别进行部署,物理资源消耗呈指数上涨
- 对于用户,管理多个任务,运维成本较高
针对以上问题,向量检索平台支持了分城市索引检索,具体实现如下图所示:
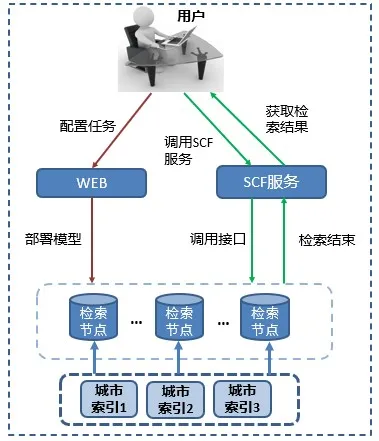
构建分城市索引时,通过数据中的城市ID将数据分别添加到对应ID的城市索引中,在同一个构建节点中创建所有城市的索引,每个城市分别对应一个索引,索引文件名定义包含了对应的城市ID,最后将索引文件打包保存。
在
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%90%8C%E5%9F%8E%E5%90%91%E9%87%8F%E6%A3%80%E7%B4%A2%E5%B9%B3%E5%8F%B0%E6%9E%B6%E6%9E%84%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


