同城槽位识别与纠错在智能语音机器人中的实践
作者: 宋玉美
导读
在语音机器人中,经常需要槽位识别来提取用户回答中的关键信息,以便用于控制对话逻辑跳转和标识对话关键词等,我们通过命名实体识别(Named Entity Recognition,NER)技术来提取对话中的实体词(关键词),即语音机器人中的槽位词。
背景
由于语音识别(Automatic Speech Recognition,ASR)技术采用的是第三方通用的语音识别,而在不同的业务中往往涉及到很多专有的名词,因此经过ASR后的文本很容易发生拼音正确但词识别错误的情况,或因用户口音、噪音、通话质量等问题导致ASR后的文本容易存在拼音相似但词不正确的问题。
为了提升对话流畅度,需要对识别出的槽位词进行纠错。例如在新车外呼场景中,用户回复文本 “我想买那个别克7268”,NER识别出车品牌“别克”,车系“7268”,但其实用户想表达的是“别克GL8”,通过槽位纠错可以将车系“7268”纠正成“GL8”,可以更好识别用户意图, 通过纠错后线上车品牌车系两种槽位的准确率提升14.43%,召回率提升8.29%。后续本文将分别从槽位识别与纠错进行详细介绍。
槽位识别流程
语音机器人中很多话术需要提取用户回答中的关键信息,比如新车的话术,系统对咨询过二手车的用户进行回访,并从中了解用户是否想购买新车及具体想购买什么车,需要识别出槽位:车品牌、车系、车型、新车/二手车,便于对用户进一步的跟进。
槽位识别是一种序列标注问题,序列标注就是对给定文本的每一个字符打上标签,然后提取出我们关心的关键词,通常采用实体识别[1,2]方式实现。标签的格式通常使用两种标准:IOB2和IOBES,标签含义如下 :
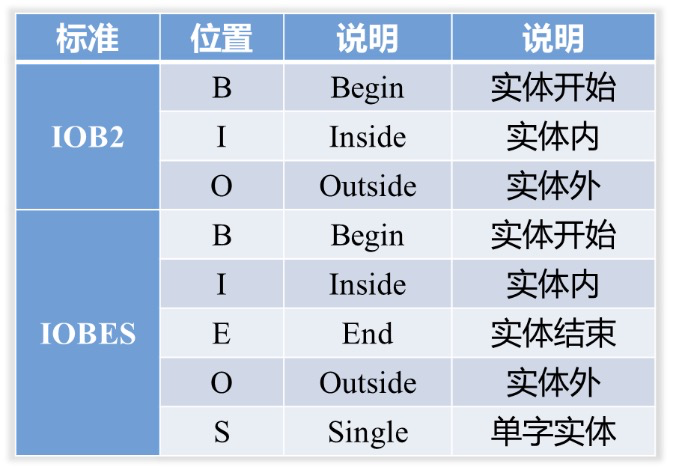
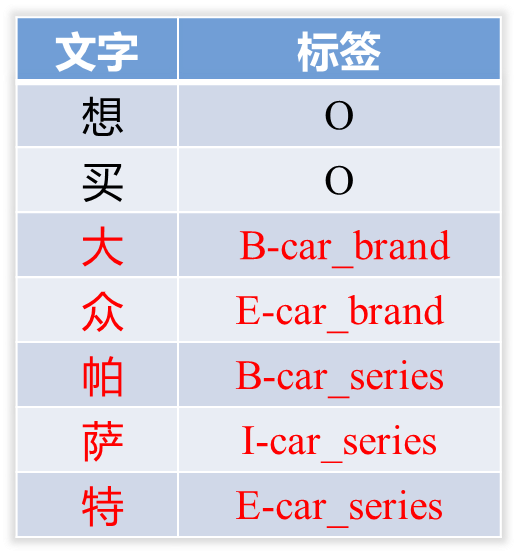
识别结果如下图所示,标签包含实体类型和位置两个部分,图中“大众”和“帕萨特”即为实体。
槽位识别的开发主要分两步:数据标注和模型训练。数据标注又分为如下几步:1)定义本体库,即定义需要识别的实体类型,比如car_brand(车品牌);
- 通过爬虫爬取带有实体词的文本数据作为候选标注数据;
- 根据积累的实体关键词,利用trie树对文本中的实体词进行初始化;
- 数据部署到rasa-nlu(一款开源的NLP工具)进行标注,对初始化的实体词进行微调。
数据标注完成后,训练实体识别模型。我们采用IDCNN+CRF [3]和BiLSTM+CRF [4~6]两种模型进行实验。IDCNN通过空洞卷积增大模型的感受野,通常以多个卷积核为一个网络单元,再重复多次以学习上下文的特征;BiLSTM通过双向的LSTM学习到输入文本序列之间的依存关系;两种模型都是对输入文本进行特征提取,得到标签数量维度的特征向量,再作为CRF的特征,从而将标签之间的依存关系也学习到,最终得到每个字对应的实体标签, 合并操作后得到槽位词。
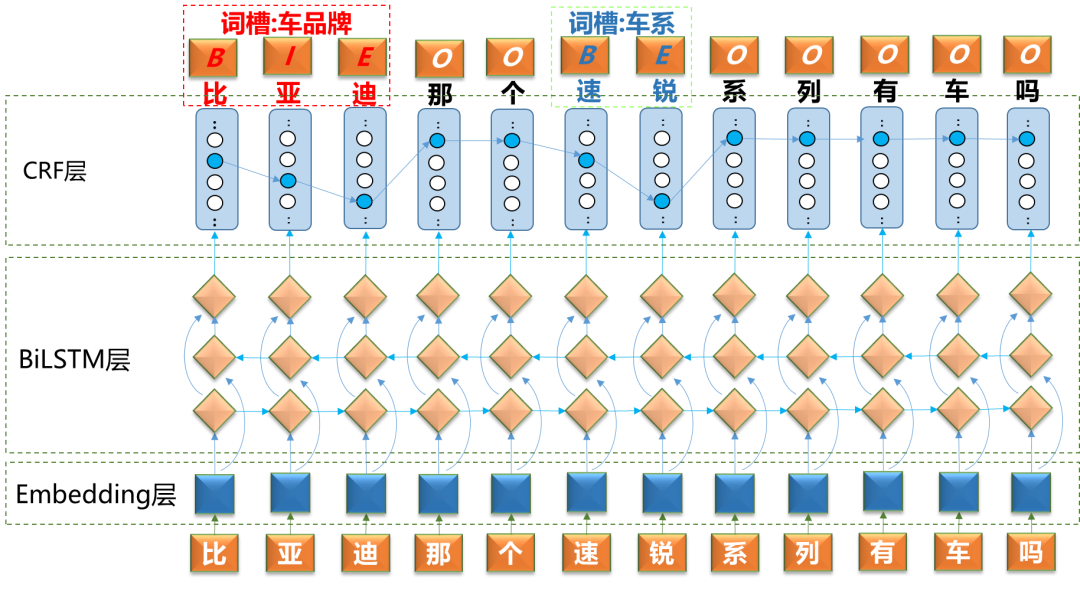
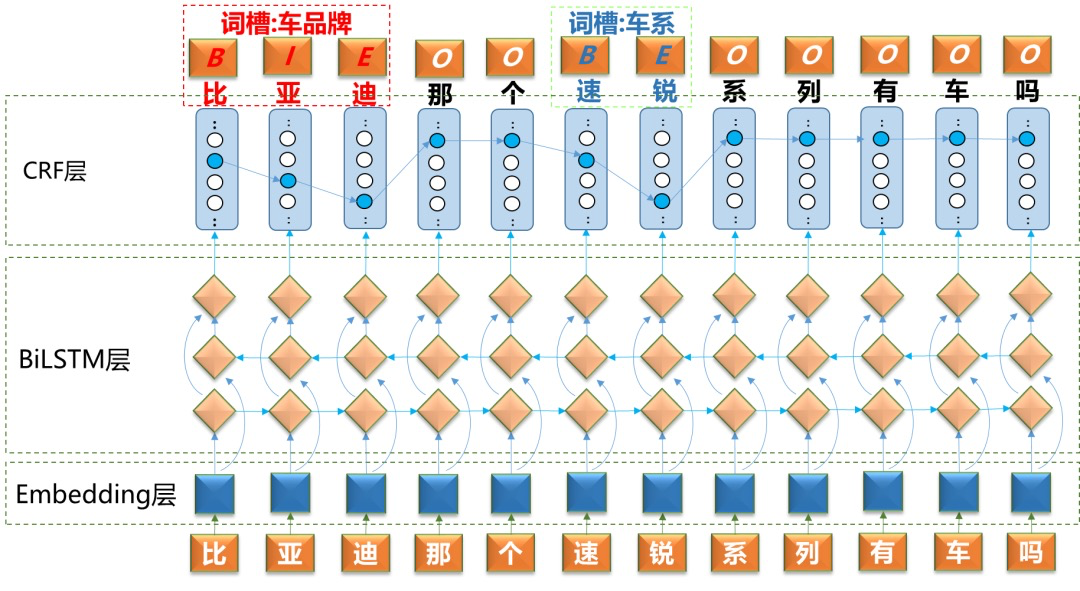
在12000条评测数据上,采用BiLSTM+CRF模型,相比IDCNN+CRF模型车品牌槽位的准确率和召回率分别提升5.22%、2.86%,车系槽位的准确率和召回率分别提升3.6%、3.39%,整体来看,采用BiLSTM+CRF槽位识别效果更好。以下结合几个例子具体分析。
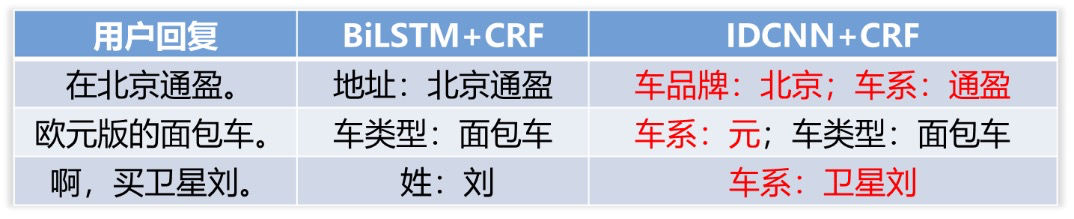
BiLSTM对句子整体和当前位置的特征比较敏感,IDCNN对周边局部比较敏感。比如,句子“在北京通盈。”, 关键词“北京”是地址也是车品牌,在本句话中表达的应该是一个地址,BiLSTM会考虑“北京”的上下文特征,倾向于识别成地址槽位,而IDCNN更多地考虑局部特征,会将“北京”识别成车品牌,在车品牌“北京”后面的“通盈”识别成车系。
且在该场景下,通常用户回复较短,很容易语音识别错误严重,IDCNN可能会抓住错误的局部特征导致槽位识别错误,比如,“欧元版的面包车”(用户真实表达是“货运版的面包车”),语音识别错误的词“元”本身是比亚迪的一个车系,IDCNN对局部特征较敏感识别出车系“元”。
比如,用户回复“啊,买卫星刘。”(用户真实表达是“免贵姓刘”),IDCNN根据局部的“买”认为“卫星刘”是一个车系,而BiLSTM则会根据当前位置和句子整体特征将“刘”识别成一个姓。在ASR错误严重的句子,BiLSTM不仅根据当前词还会根据句子整体特征来识别是哪种槽位,效果会略好。
槽位纠错流程
在语音机器人的话术中,识别出来的槽位用于话术流转,对于有些话术,识别出的槽位也会作为最后标签的一部分返回。
比如在车话术中,机器人对有购车意向的用户进行回访,需要识别出槽位:新车/二手车、车品牌、车系、姓氏等。机器人首先询问用户要买新车还是二手车,此时需要提取出新车/二手车的槽位用作话术跳转,如果识别到该槽位话术跳转到肯定分支继续询问用户意向车型,此时需要识别出车品牌、车系槽位,便于对用户进一步跟进。
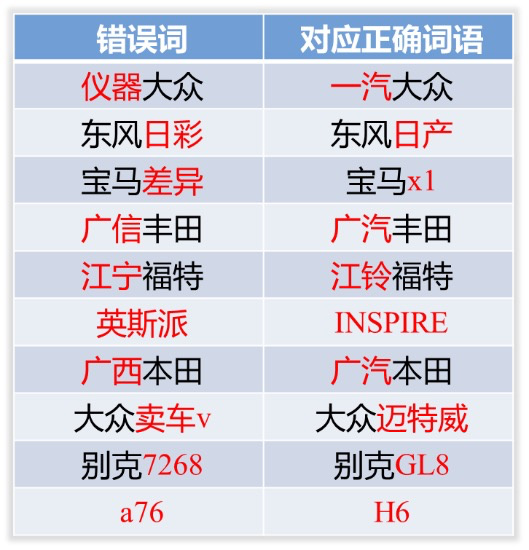
由于采用第三方通用的ASR服务,针对很多特定场景中的专业名词识别,容易出现谐音词错误(同音不同字,仪器大众与一汽大众)和混淆音词错误(拼音相似词不正确,江宁福特与江铃福特)的问题。
比如用户回复文本:“我想买那个别克7268”,槽位模型识别出车系:7268,直接将此错误车系回传给业务方无法入库,识别出的车系没有价值,因此我们需要对识别出的槽位实体词进行纠错,得到正确的槽位词(GL8)才能入库。如下表列出部分错误类型。
基于我们已有的领域知识(车品牌库、车系库及车品牌与车系的映射关系),首先对领域知识中的词进行预处理(去空格、去特殊符号、车系需要去掉车品牌前缀、大小写统一等),并将预处理后的词与原始领域词进行映射(chr海外–>丰田C-HR(海外)),后续所有与领域知识词进行比较,都采用预处理后的领域知识词,最终再映射到原始的领域知识词输出。
例如,如果识别出的槽位词与相应领域知识中预处理过的词完全匹配,则返回映射的原始领域词,如果不匹配,那么认为槽位词错误,需要纠正,如何纠正呢?
上述提到错误主要是由谐音或混淆音导致的,基于我们已有的车品牌、车系库,可以通过拼音相似度算法进行匹配,得到相似度最大的实体词,即认为是正确的实体词(会通过阈值来控制)。
拼音相似度算法采用编辑距离,将待纠错词与车品牌、车系库中的所有词都转成拼音,待纠错词与库中的词计算编辑距离(基于拼音的每个字母计算编辑距离),即待纠错的拼音字符串需要改动多少次才能变成目标拼音字符串,同时考虑到字符串长度的影响,再除以两个字符串拼音的长度,编辑距离越小,匹配程度越高,最终通过阈值来控制是否采纳纠错结果。
具体地,在语音机器人新车相关话术中,对于用户回复买车的文本,首先会提取出本句话所有识别出的车品牌,对错误的车品牌进行纠正,这里车品牌纠错设置的阈值比较大,尽可能使纠正后的车品牌正确,这样才能基于正确的车品牌进行车系的纠错。
车品牌纠错后�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%90%8C%E5%9F%8E%E6%A7%BD%E4%BD%8D%E8%AF%86%E5%88%AB%E4%B8%8E%E7%BA%A0%E9%94%99%E5%9C%A8%E6%99%BA%E8%83%BD%E8%AF%AD%E9%9F%B3%E6%9C%BA%E5%99%A8%E4%BA%BA%E4%B8%AD%E7%9A%84%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


