回顾在贝壳找房的实践经验
本文转发于 DataFunTalk 公众号

本文根据贝壳找房邓钫元老师在中国HBase技术社区第二届MeetUp:“HBase技术解析及应用实践”中分享的《HBase在贝壳找房的实践经验》编辑整理而成,在未改变原意的基础上稍做整理。

钫元老师

首先给大家介绍一下贝壳,贝壳是链家一个房地产品牌,链家的愿景是把贝壳打造为一个大的互联网房地产入口品牌,也允许第三方品牌接入我们的贝壳平台。类似于京东商城与京东自营的关系。我们的愿景是把链家的数据与行业的品牌结合起来,更好的服务整个行业的消费者。
本次分享从以下四个部分介绍:

第一部分 HBase简介

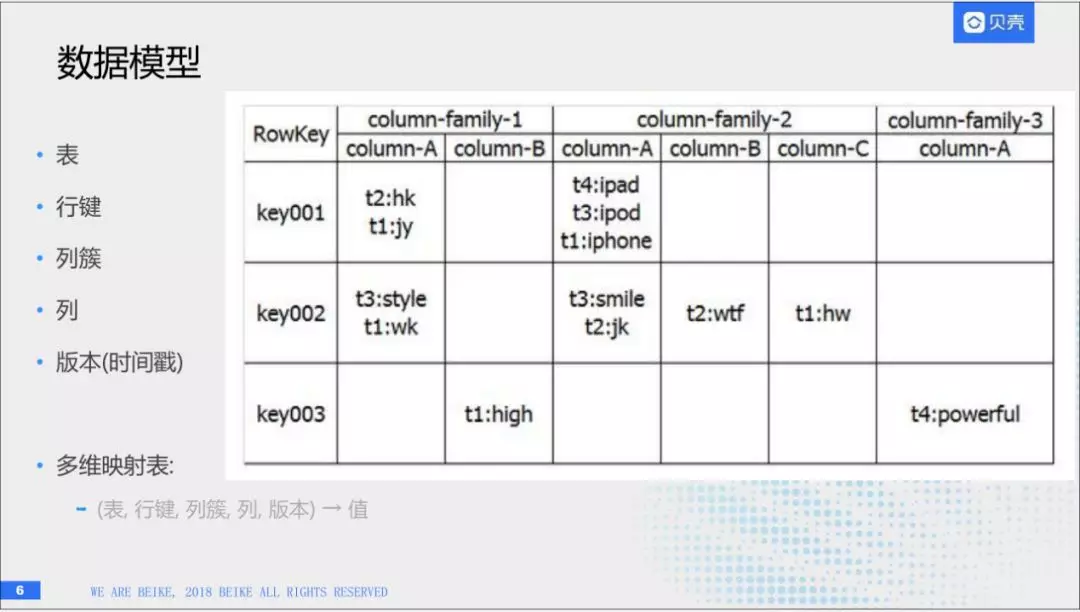
(1)数据模型
它的几个程式是一张表,有一个行键,叫做rowkey,它用来确定每一行,然后每一行里面会分为很多个列族,每一个列族下面有不限量的列。每一个列上可以存储数据,每一个数据都是有版本的,可以通过时间戳来区别。所以我们在一张表中,知道行键,列族,列,版本时间戳可以确定一个唯一的值。
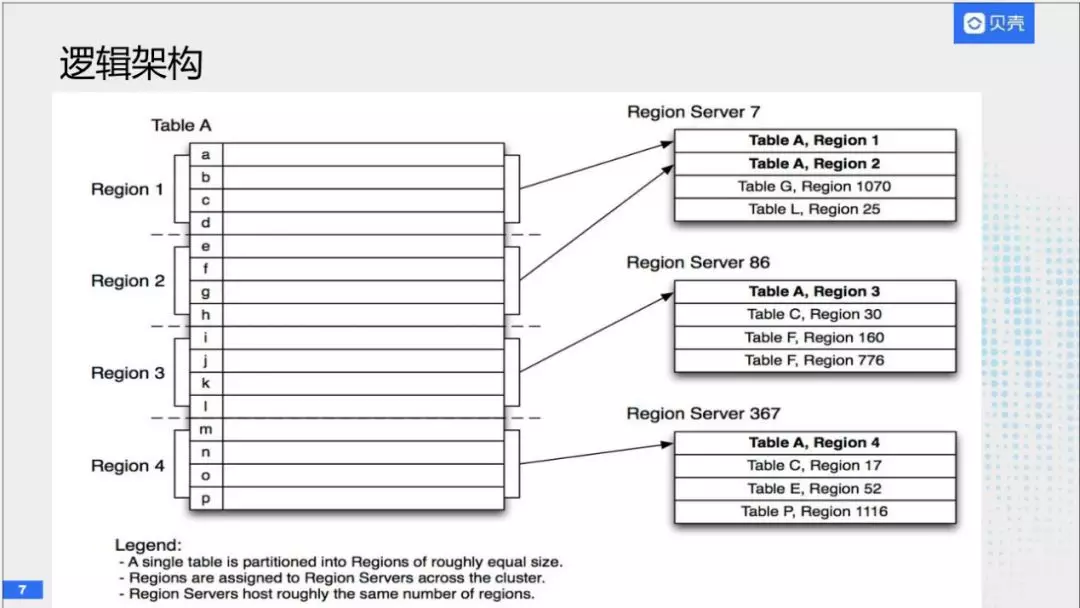
(2)逻辑架构
任何一张表,他的rowkey是全局有序的,由于对物理存储上的考虑,我们把它放在多个机器上,我们按照大小或者其他策略,分为多个region。每一个region负责表示一份数据,region会在物理机器上,保证是一个均衡的状态。
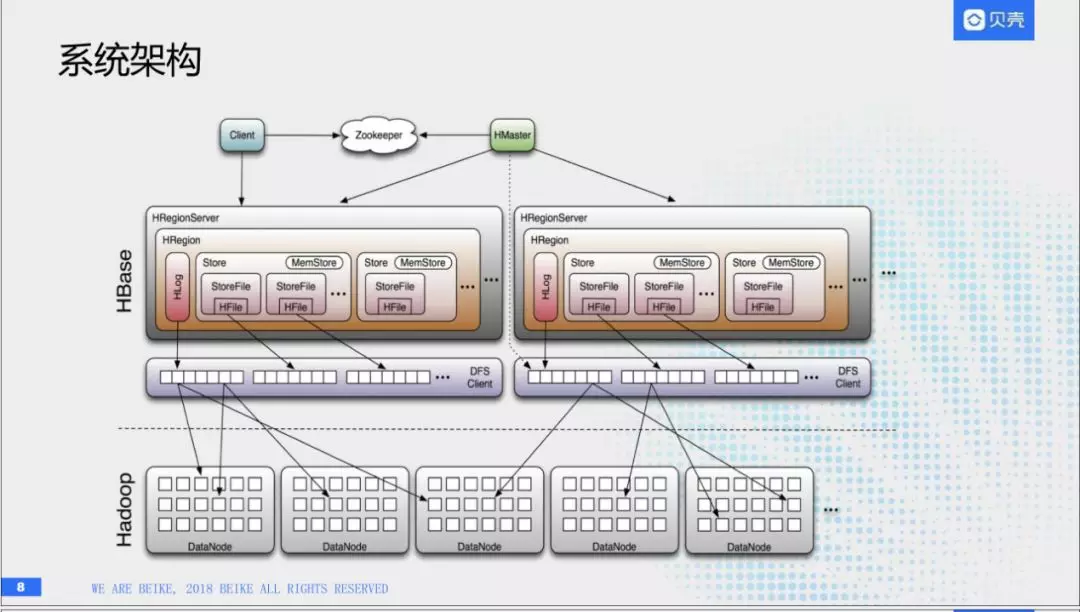
(3)系统架构
首先它也是一套标准的存储架构。他的Hmaster主要负责简单的协调服务,比如region的转移,均衡,以及错误的恢复,实际上他并不参与查询,真正的查询是发生在region server。region server事负责存储的,刚才我们说过,每一个表会分为几个region。然后存储在region server。这里最重要的部分是hlog。为了保证数据一致性,首先会写一份日志文件,这是数据库系统里面以来的一种特性,创建了日志以后,我们才能写入成功。我们刚才提到HBase里面有很多column-family列族,没个列族在一个region里对应一个store,store分别包含storefile和menstore。为了后续对HBase可以优化,我们首先考虑把文件写入menstore里面,随着menstore里面的数据满了之后,会把数据分发到磁盘里,然后storefile和memstore整体的话,依赖一个数据模型,叫做lmstree。然后,数据是采用append方式写入的,无论是插入,修改,删除。实际上都是不断的append的。比如说你的更新,删除的操作方式,都是以打标记方式写入,所以它避免了磁盘的随机io,提高了写入性能,当然的话,它的底层的话是建立在hdfs之上。
第二部分 HBase在贝壳中的使用经验

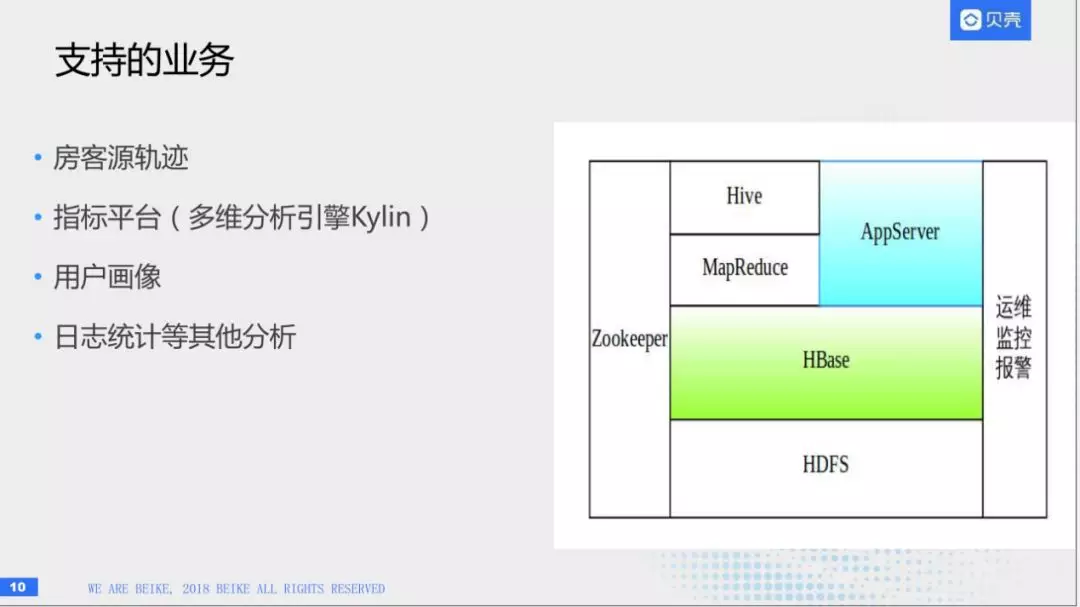
(1)总体介绍
我们贝壳使用HBase是非常多的。这边也搭建了一套系统,部署在我们机器上,目前我们应用在房客源轨迹跟踪,我们制订了一个指标平台,这个平台依赖于另外一个引擎—kylin。借助HBase实现一套多维分析,比如用户的画像,还有日志统计分析等这几个方面。
(2)房客源轨迹产品介绍
这就是我们房客源轨迹的一个产品,其实这个产品主要使用者是经纪人,这个产品可以根据客户的一套房子去跟踪它的所有信息,包括它挂牌成交后的电话以及房源状态的跟新。实际上这个状态量是非常大。我们使用HBase来存储这些数据。
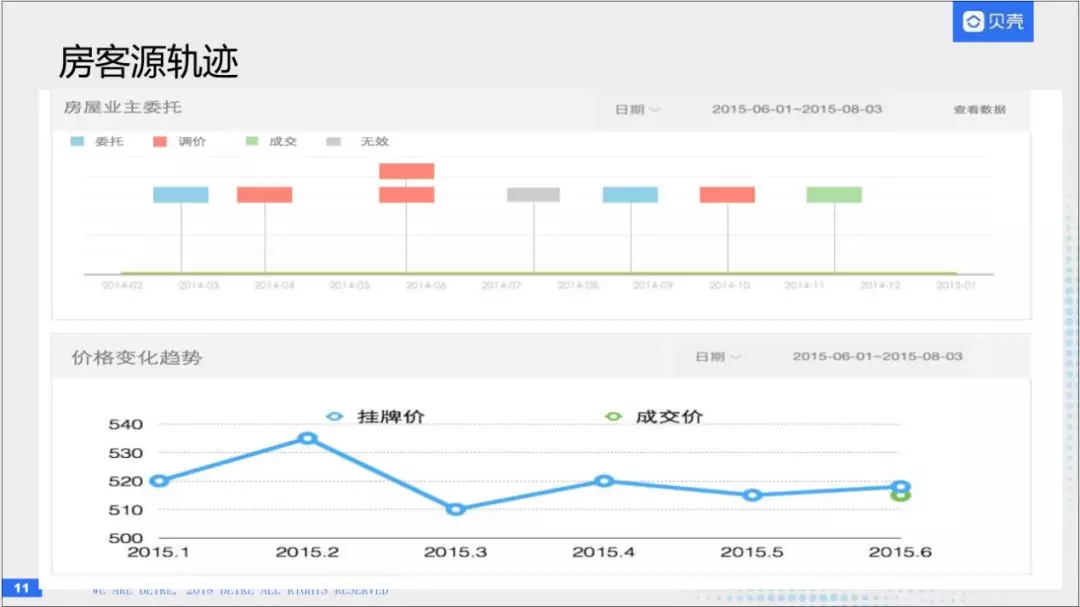
其实这个模型是非常适合HBase存储的模型,比如说,对于房源轨迹的存储我们做了如下设计,因为它就依赖于房价来做索引,我们把它的row-key设计成房源Id+时间+操作类型。value的话,就是具体操作的值。为了保证HBase序列的均衡性,我们对Id加一个md5,做一个哈希,这样可以保证数据的分配均衡。这是一个非常典型的使用场景。

(3)指标平台
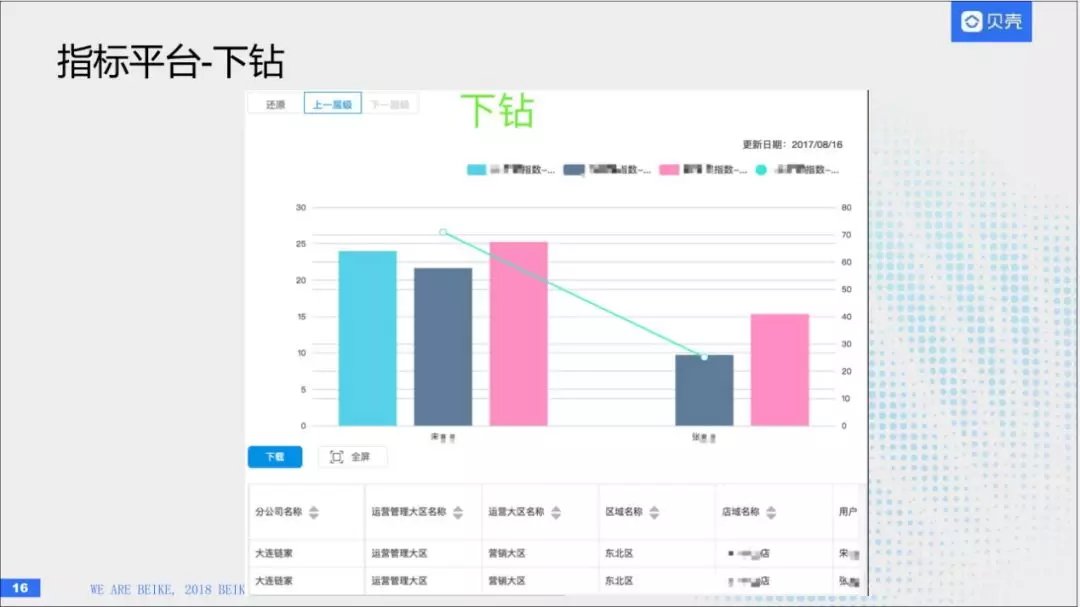
第二个场景叫做指标平台,首先给大家展示一下平台。这是一个可视化的分析平台,在这上面可以选择我们在HBase存储好的数据,可以选择哪些维度,去查询哪些指标。比如这个成交数据,可以选择时间,城市。就会形成一张图,进而创建一张报表。然后这张报表可以分享给其他人使用。
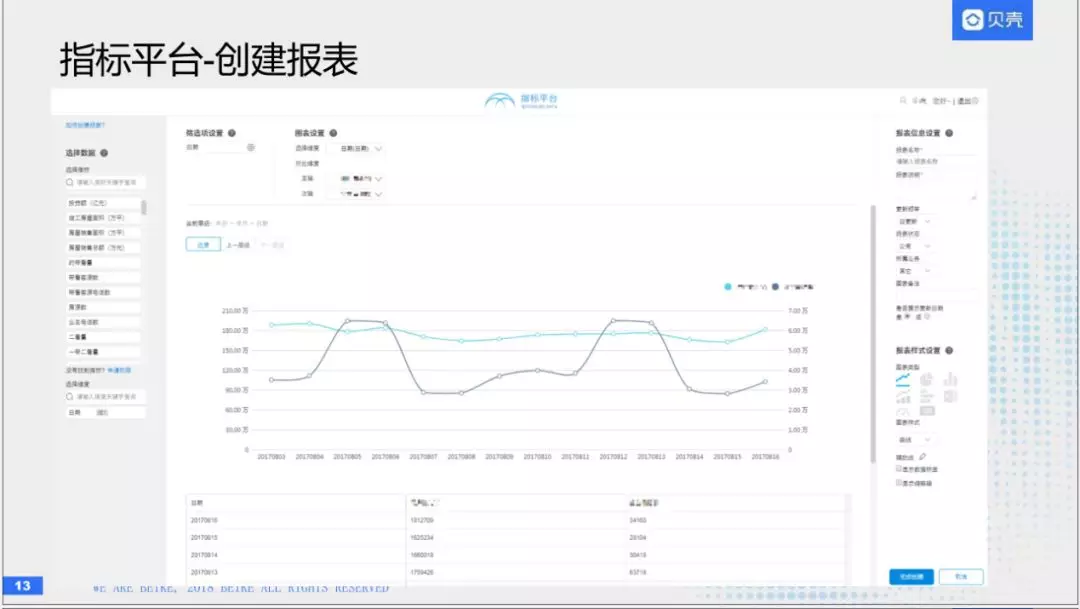
这张表,应该从时间和组织架构这两个维度,我们现在看到的是一个大区的情况,这是每个大区的成交量。
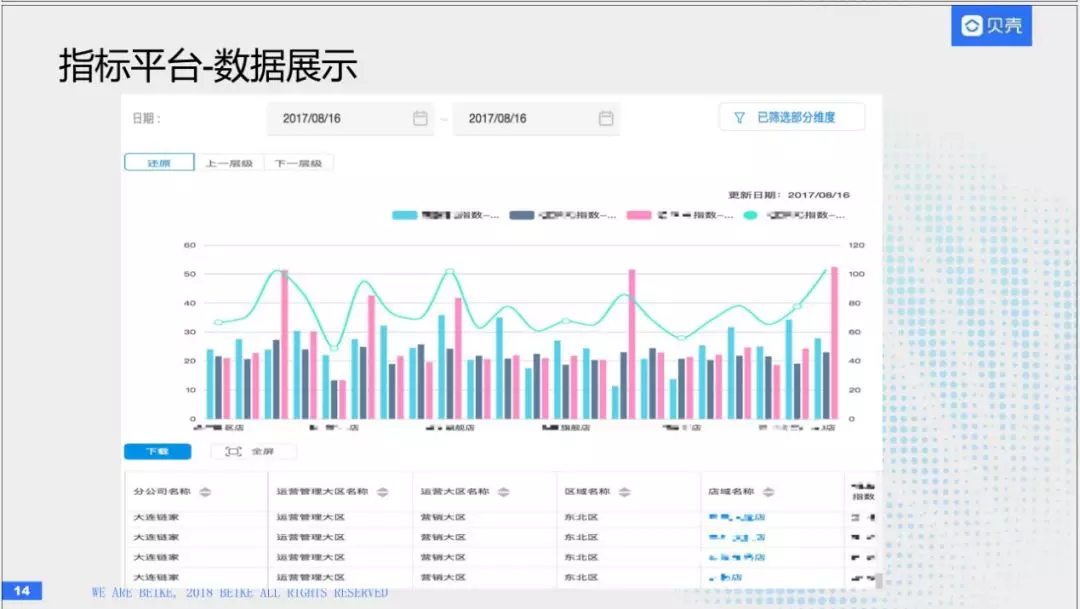
多维分析的话,包括上卷和下钻。刚才我么刚到大区的情况,我想往上一层,看全国的区域,比如说东北区域或者华南区域的情况。
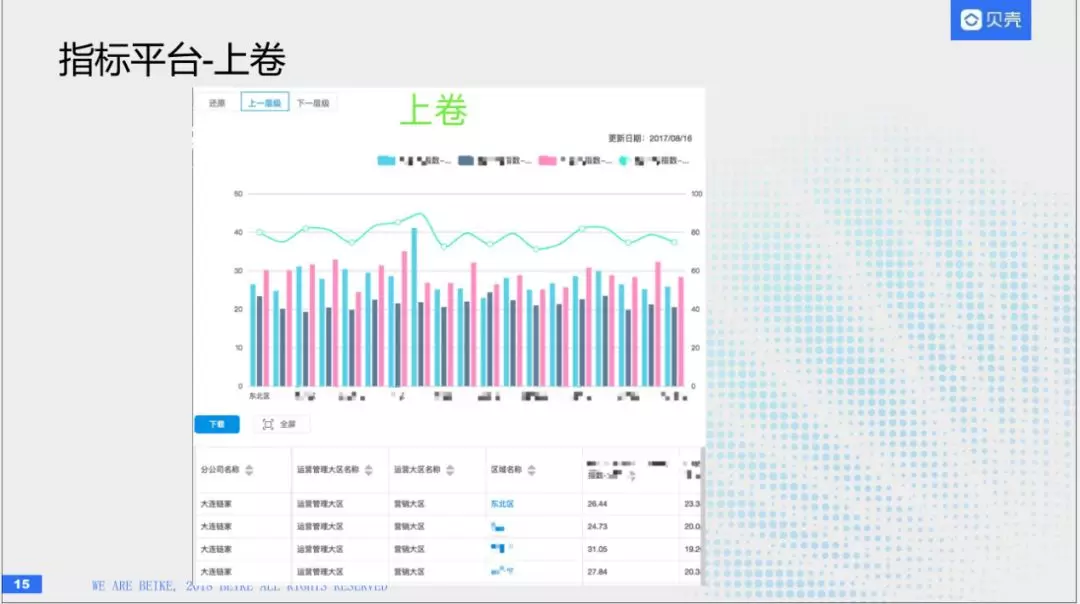
第二个是下钻,这就是看某个区域的情况,比如说我们想看某个区域作业的经纪人或者作业的店,可以往下查询,分析到每一个人。
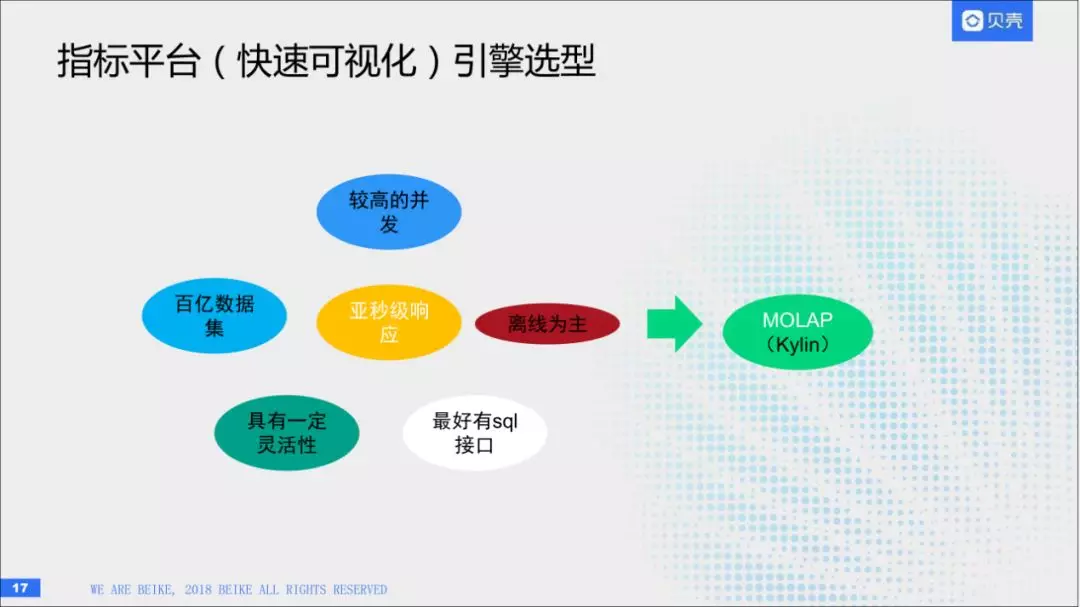
(4)引擎选型
指标平台的话,前面是从一个产品方面展示。他后台依赖的一个引擎是Kylin。为什么会选择Kylin呢,因为Kylin是一个molap引擎,他是一个运算模型,他满足我们的需求,对页面的相应的话,需要亚秒级的响应。第二,他对并发有一定的要求,原始的数据达到了百亿的规模。另外需要具有一定的灵活性,最好有sql接口,以离线为主。综合考虑,我们使用的是Kylin。
(5)Kylin简介
Kylin给他家简单介绍一下,Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc.开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。他的原理比较简单,基于一个并运算模型,我预先知道,我要从那几个维度去查询某个指标。在预定好的指标和维度的情况下去把所有的情况遍历一遍。利用molap把所有的结果都算出来,在存储到HBase中。然后根据sql查询的维度和指标直接到HBase中扫描就行了。为什么能够实现亚秒级的查询,这就依赖于HBase的计算。

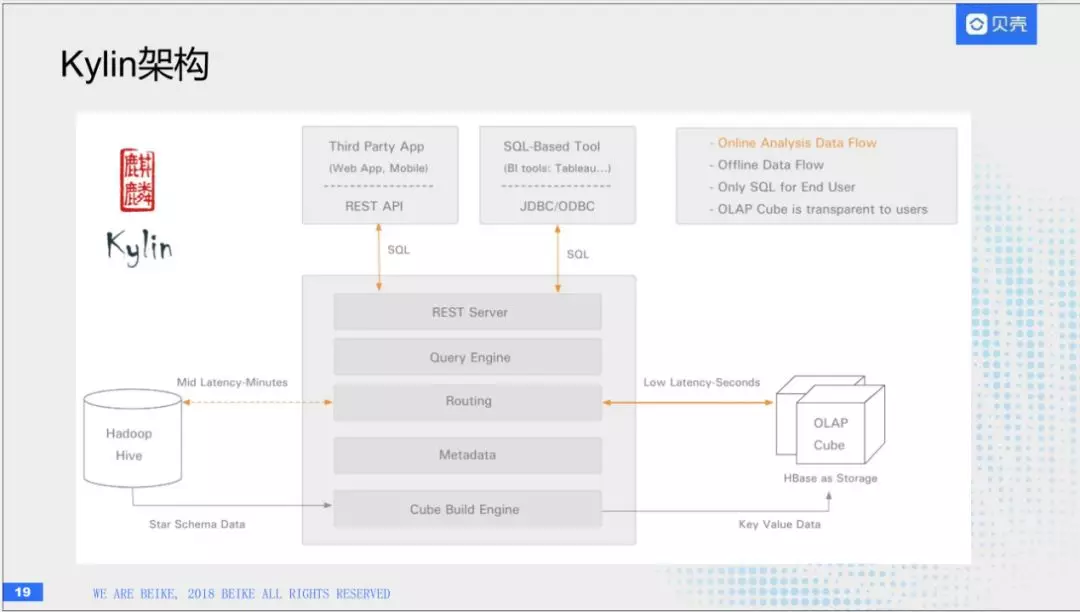
(6)kylin架构
和刚才讲的逻辑是一致的,左边是数据仓库。所有的数据都在数据仓库中存储。中间是计算引擎,把每天的调度做好,转化为HBase的KY结构存储在HBase中,对外提供sql接口,提供路由功能,解析sql语句,转化为具体的HBase命令。
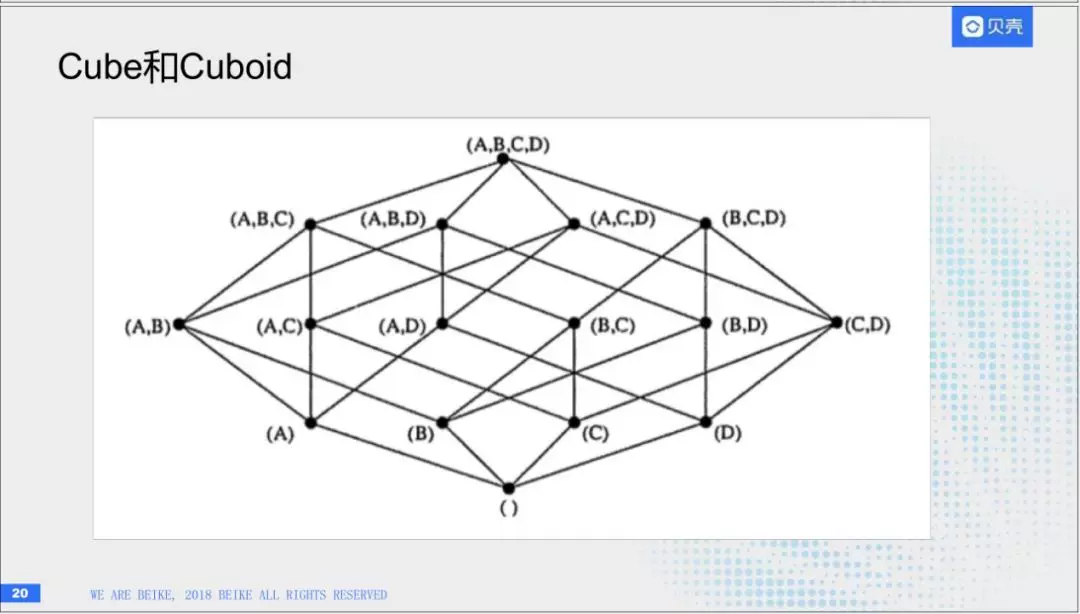
Kylin中有一个概念叫Cube和Cubold,其实这个逻辑也非常简单,比如已经知道查询的维度有A,b,c,d四个。那abcd查询的时候,可以取也可以不取。一共有16种组合,整体叫做,cube。其中每一种组合叫做Cuboid。
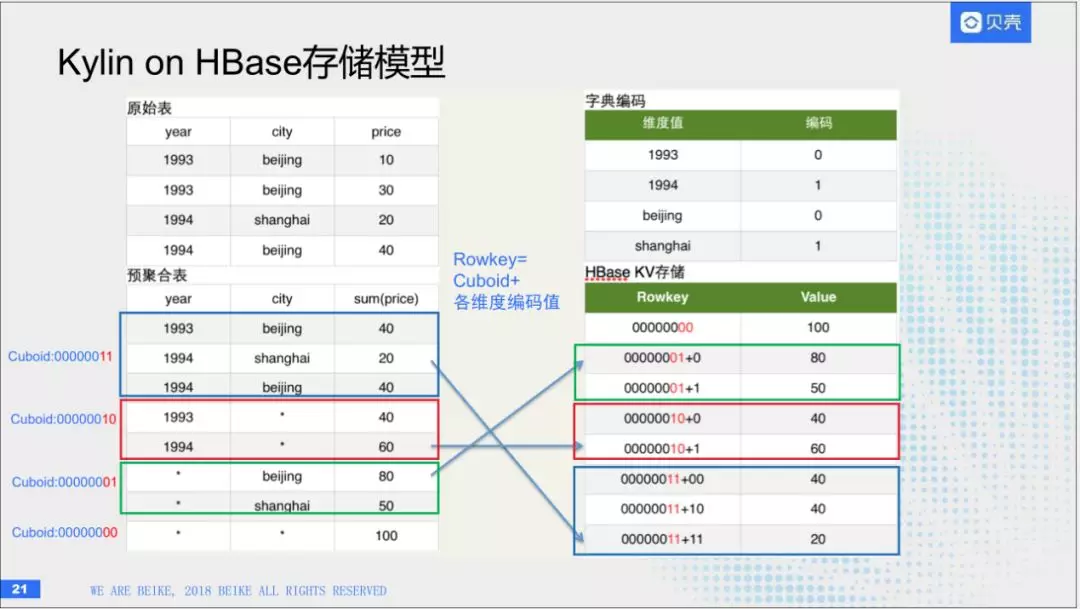
(7)Kylin如何在Hbase中进行物理存储的
首先定义一张原始表,有两个维度,year和city。在定义一个指标,比如总价。下面是所有的组合,刚才说到Kylin里面有很多cuboid组合,比如说前面三行有一个cuboid:00000011组合,他们在HBase中的RowKey就是cuboid加上各维度的取值。这里面会做一点小技巧,对维度的值做一些编码,如果把程式的原始值放到Rowkey里,会比较长。Rowkey也会存在一个sell里任何一个版本的值都会存在里面。如果rowkey变的非常长,对HBase的压力会非常大,所有通过一个字典编码去减少长度,通过这种方法,就可以把kylin中的计算数据存储到HBase中。
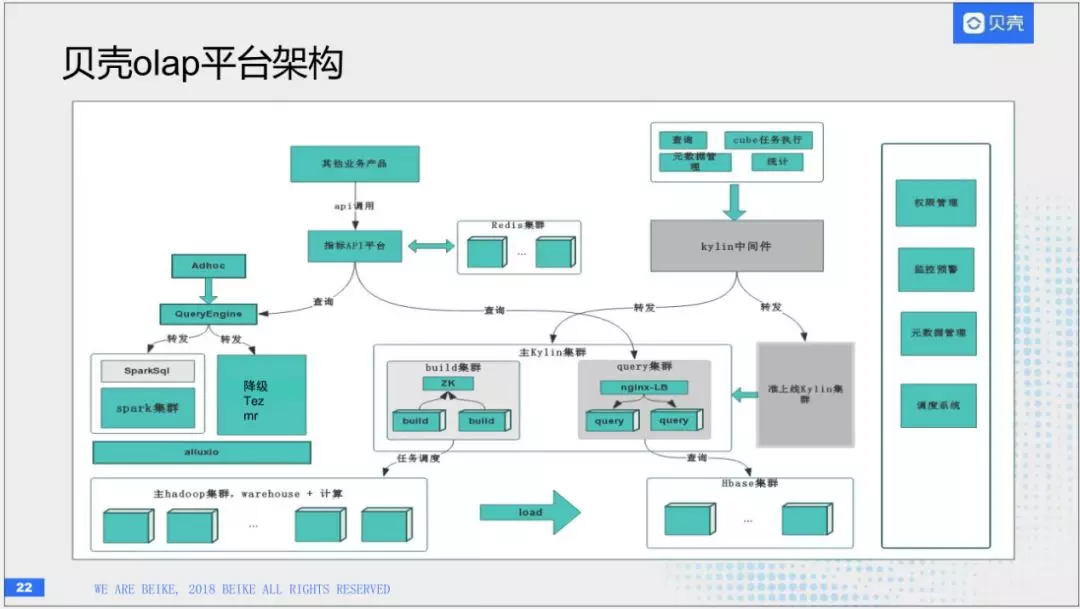
(7)平台架构
这就是我们链家多维分析的平台架构,左边是一套主集群,数据仓库和离线计算在上面,右边是Kylin的系统,分为查询和构件两部分,通过一个调度系统,定时去调度计算任务,把数据导入独立的HBase中,这套独立的HBase是为了保证线上查询不会受影响。最右边,我们做了一套Kylin中间件,因为Kylin本身会有很多问题,比如任务数有限制,任务之间没有优先级,错误重试等问题,通过自研了一套中间件来解决这些问题。最右边是使用这些系统和集群的平台。它底层就依赖于kylin的数据查询服务,同时也会做一些数据缓存。使用系统中的通用模块,比如权限管理,监控管理,元数据管理,调度系统。
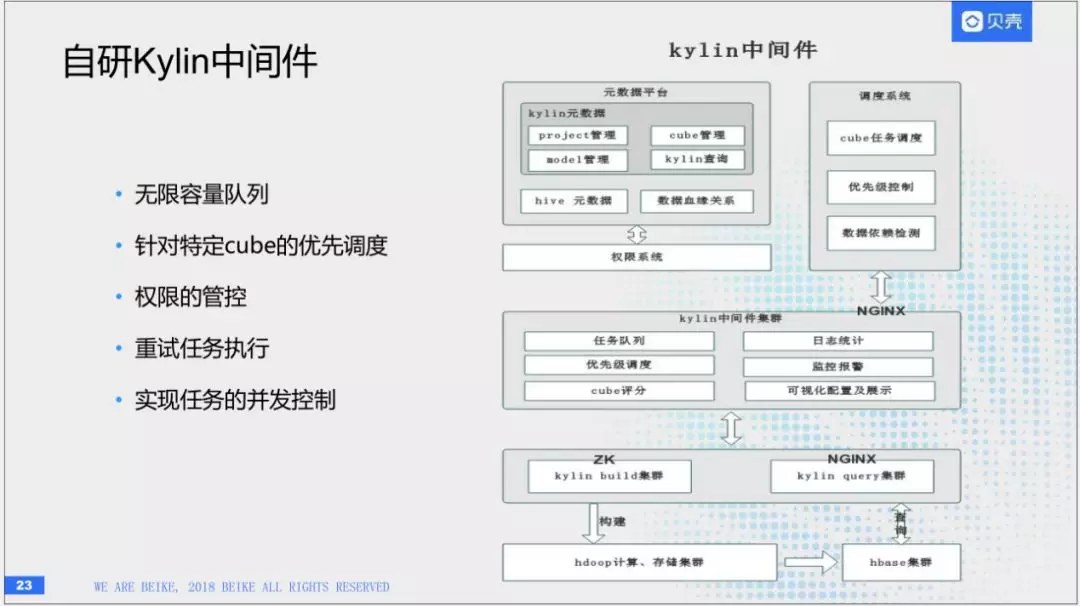
(8)Kylin自研中间件
这就是我们自研的Kylin中间件,原生的话,本身有很多问题,我们做的工作支持如下功能:无限容量队列,针对特定cube的优先调度,权限的管理, 重试任务执行,实现任务的并发控制。
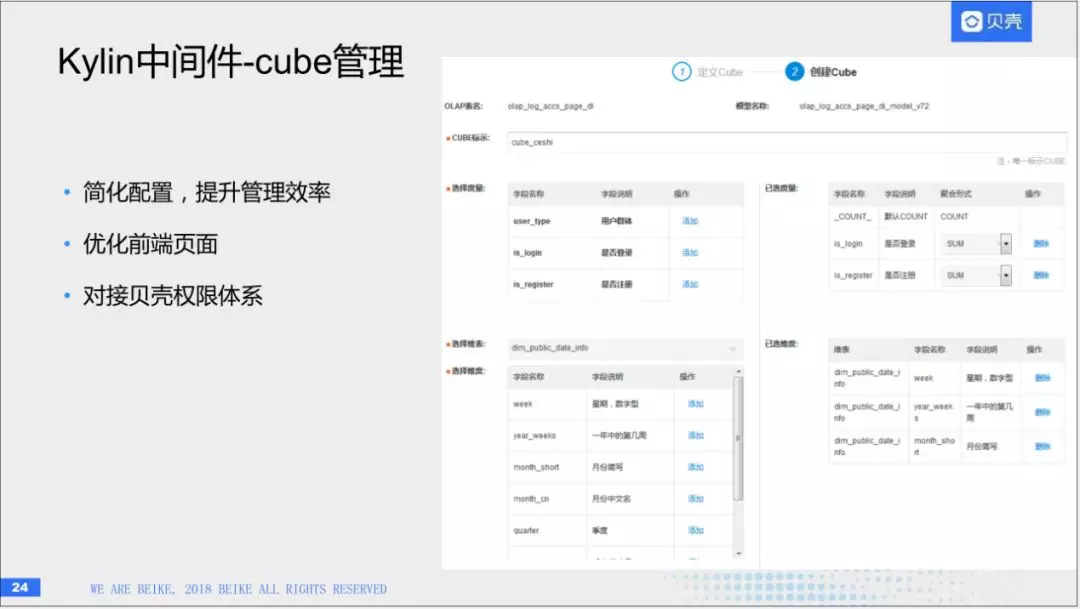
这是中间件的另一个功能:cube管理,Kylin原生也有一套cube管理,但是会有很多问题,比如说性能问题,cube会很卡,另外一个是权限问题,我们希望可以对接到链家的权限,优化前端页面,简化配置,提升管理效率。右边是我们自主创建cube的过程。
这里是我们Kylin使用的情况。

这里是我们链家对Kylin的定制改造。

第三部分 HBase的优化经验

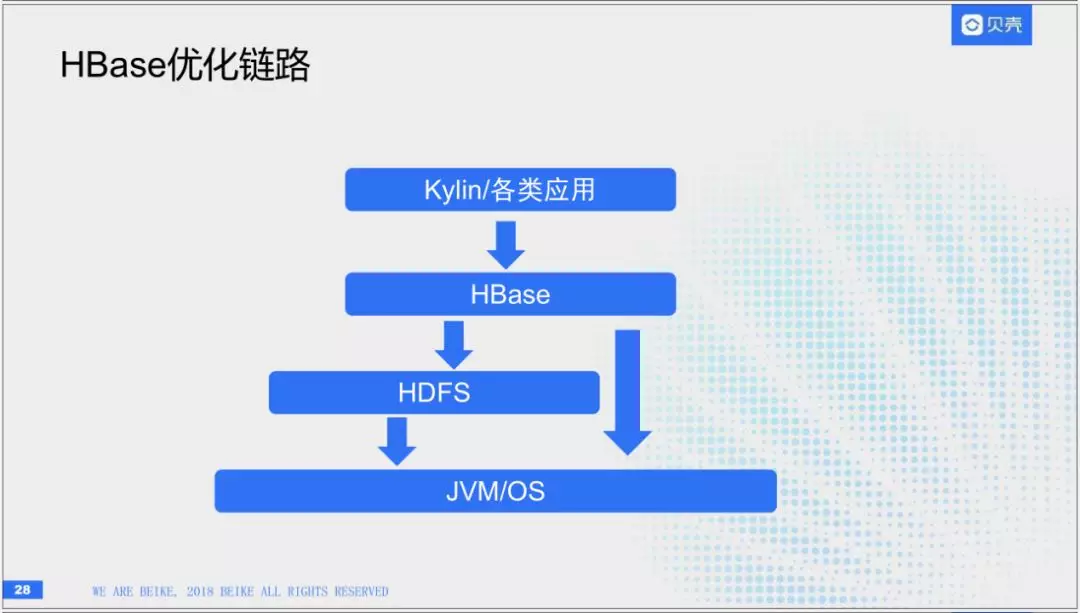
(1)HBase部署上的链路
我们优化也是针对这个链路做优化,第一步:Kylin及各类应用,由HBase调用,HBase数据又存储在HDFS上。同时HBase和HDFS又运行在操作系统上。我们会从这几层做优化。
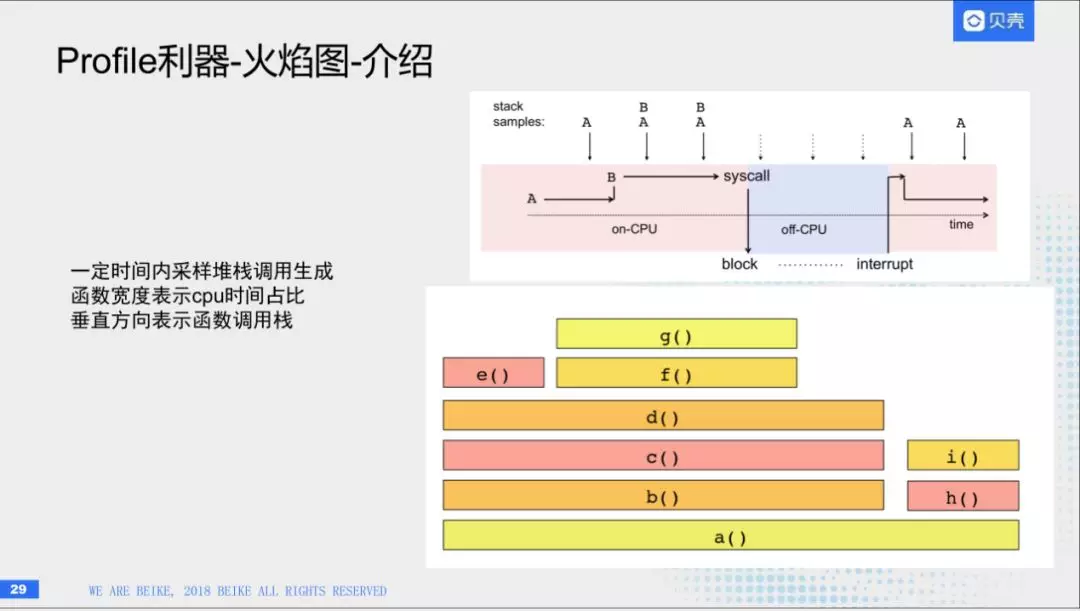
(2)性能优化工具
首先给大家介绍一个性能优化的工具,是Profile利器-火焰图。首先看右边的图,表示的是代码在我们CPU上运行的逻辑。AB就是两个函数,A会调用B,然后时序会从左到右。上面的每个箭头,是每个堆栈的切片,on-CPU表示你的代码正在运行,off-cpu表示你的代码调用其他读写功能,让出线程。把这些切片信息累加起来,就可以得到在右下角的一张图,叫做火焰图。
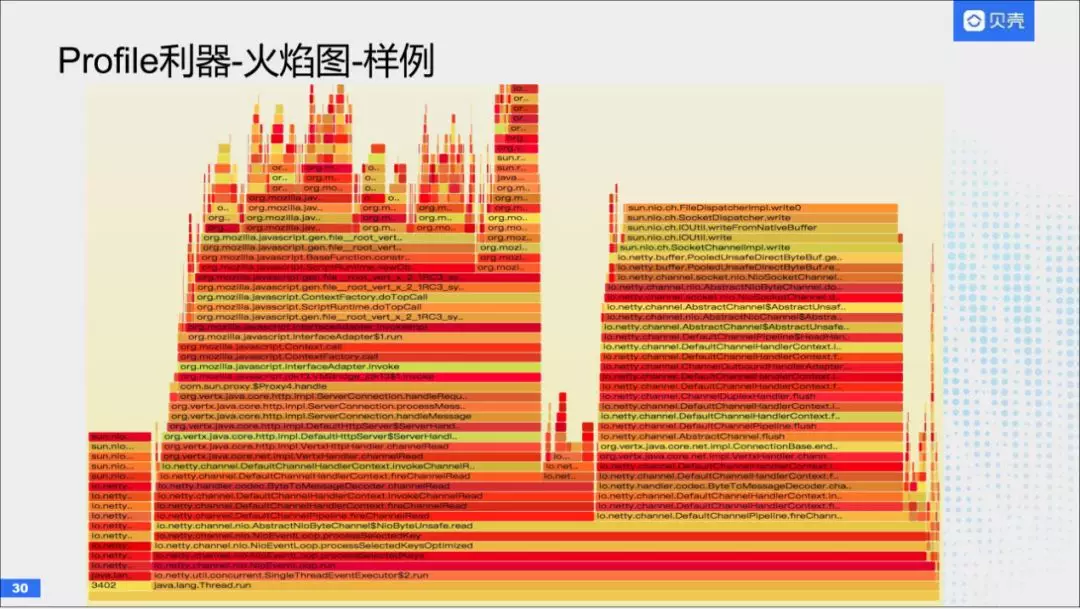
这是一张火焰图的样例,这张图是对Firefox进行采样的,一般分析火焰图,是从下往上的。我们可以看到非常多的“山峰”。一般我们关注的是,“山峰”从下往上一直没有缩减。
(3)优化实例
这里讲一个优化实例,之前某一个查询服务,当时发现,并发的时候CPU满载,用火焰图做一个采样分析,左上角是一个认证模块加密算法,他消耗百分之七八十的CPU资源,下面的弹窗显示的是具体处理过程,也是占用百分之八九十的CPU资源,他为了实现长加密,使用了一套Base的加密算法,这套算法对CPU的消费非常高,实际上在内网环境上,对安全的要求没有那么高,所以换成了MD5加密算法,大家可以看到,优化之后,处理的时间大大降低了。通过对比,提升了四五倍的qps。右边是火焰图的创造者。

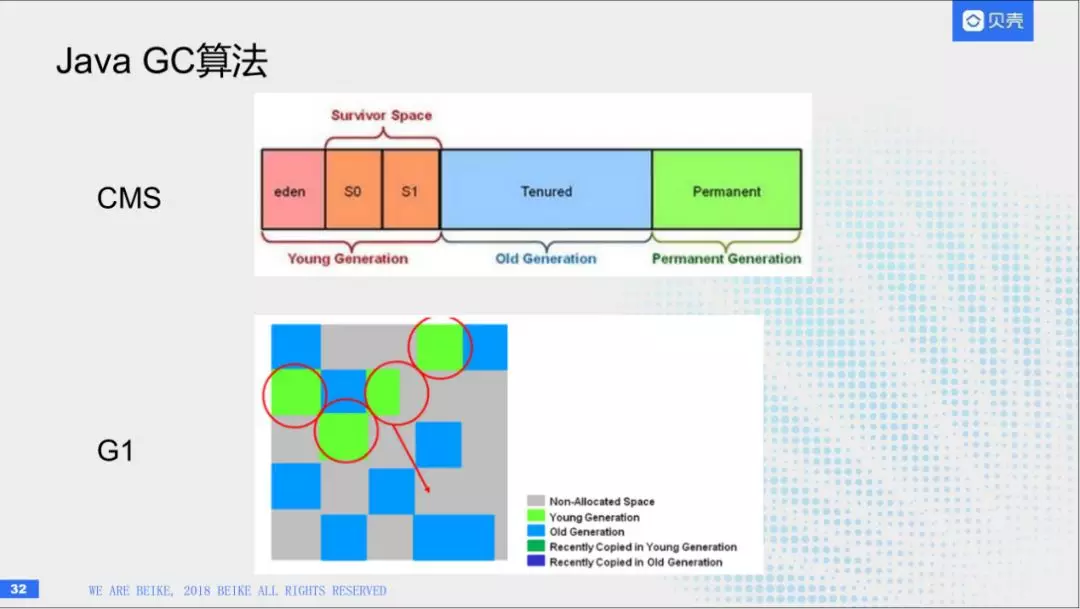
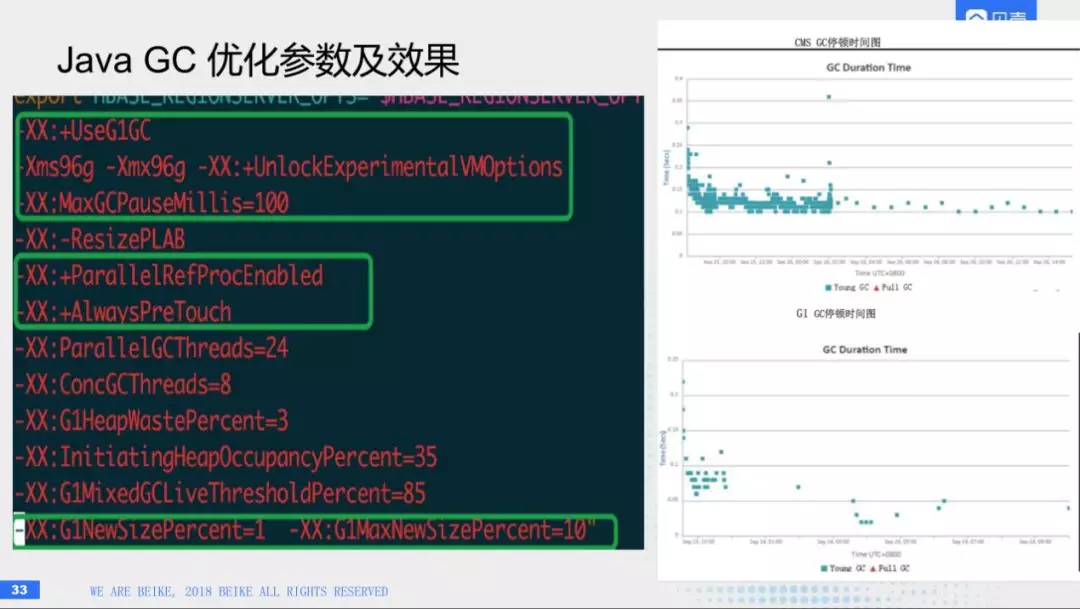
(4)GC算法
HBase是内存消耗的大户,它分为两部分,一个是写入的时候,里那个一个是cache。他们对内存的消耗是非常大,我们这边对Java的堆开到了将近100g左右,如果使用CMS算法的话,对其进行调优。都会出现暂停时间比较长的情况,满足线上的重调业务,后期的话,我们改成了G1,G1就是把内存的堆分成region,然后每一个region有各自的功能,G1有预测算法,比如,我指定一个暂停时间100ms,他能够通过预测算法,能够预算到在这100ms内能够搜集多少垃圾,然后他会收集指定的region,这样就可以做到时间可控。
这是我们线上使用java的执行参数。第一个框我们指定暂停时间100ms,有几个重要的参数,比如有几个并行数,另外alwayspretouch这个参数比较有意思,当我们启动java程序的时候,他向操作系统申请96M的空间,实际上这个空间是虚拟内存,当你有反馈的时候,操作系统才会把虚拟内存映射到物理内存上,这样一个操作叫做区域中断,这一个负载比较高的系统中,会对你的处理有一些延迟,你开启这个参数,就会把所有的清零。因为每次写入新数据,会产生一个回升带,回升带设置比较大的话,造成暂停的时间比较长,所以建议设置一个比较小的数,百分之1就可以。右边是一个优化的图,上边是使用GMS的时间,下面是G1算法的。可以看到得到了很好的缩短。
(5)HBase在IO上优化
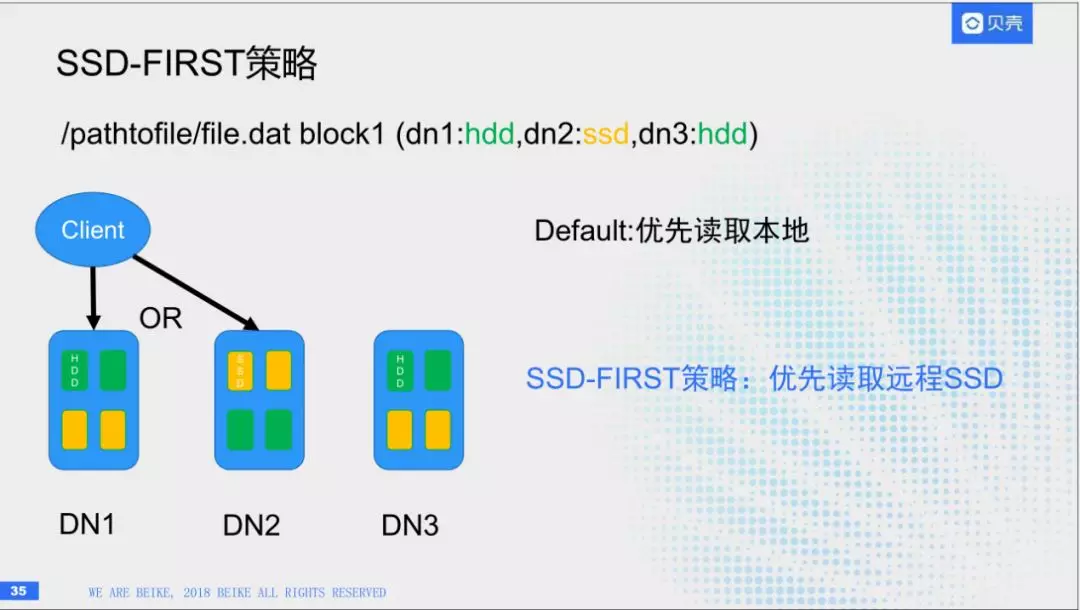
我们也了解到HBase在IO上可以做很多优化,但是对IO最好的优化,还是基于硬件。左边的话,最上方主要依赖Hbase对多存储的支持,叫做异构存储,可以标记存储页,同时,HBase上也会有有一些策略,比如ALL_SSD,(F副本全部放在SSD上)ONE_SSD(一个副本放在SSD上)。目前,我们把HBase核心业务和预写日志用ALL_SSD这种策略上,一些重要业务会使用ONE_SSD,普通的话,使用村纯硬盘就可以了。

下面说一下,在ONE_SSD测策略下,会有一些性能会出现问题,比如第一个文件块,会有三个副本,其中某一块SSD,当我发起读取的请求时,根据原生hadoop的策略,会优先去读本地,但实际上,在目前的架构下,远程去读SSD的性能是远超读取本地硬盘的。所以在架构上增加了SSD-FIRST策略,优先读取远程SSD。
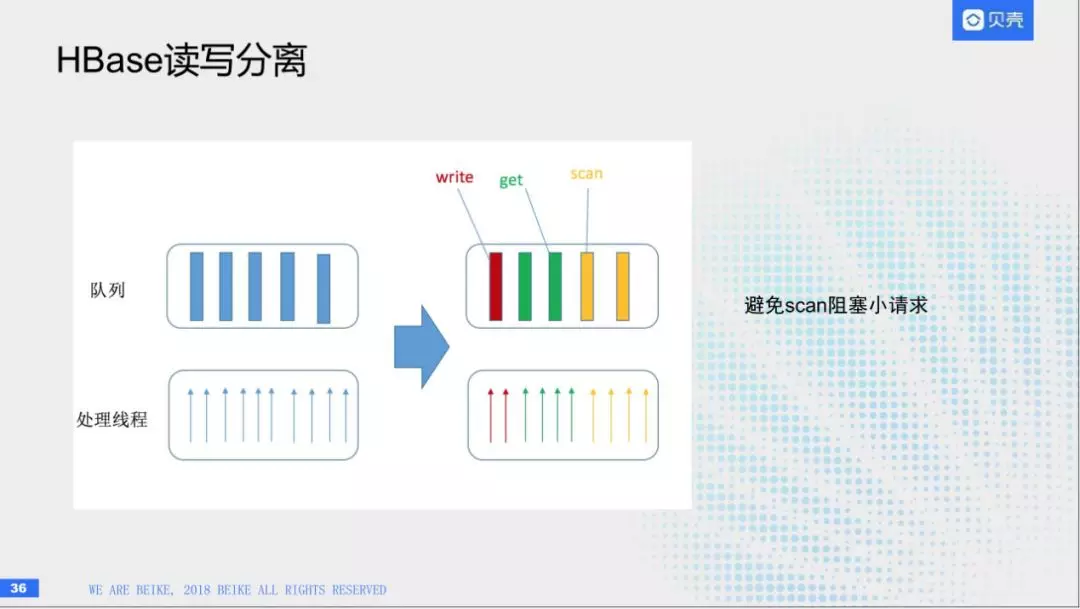
另外就是HBase的读写分离,原生HBase可以生成队列树和线程树,想很多读写请求和scan请求都会统一并发,这样的话会出现一个问题,当我有一个scan请求,会扫面很多行,把队列都堵住了,后续的请求可能会无法响应,上边是1.2里的功能,我可以把队列和线程分组,比如80%负责读,15%负责写,5%负责scan。
这是HBase基于wasd的性能测试,左边是测试的设备和配置。可以看硬盘与SSD的IO差别很大,绿色的这条线,代表的是qps这条线。大家可以看到,最开始全部使用硬盘的时候,qps大概在一万左右,�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%9B%9E%E9%A1%BE%E5%9C%A8%E8%B4%9D%E5%A3%B3%E6%89%BE%E6%88%BF%E7%9A%84%E5%AE%9E%E8%B7%B5%E7%BB%8F%E9%AA%8C/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


