在有赞实时计算的实践
转载自: 有赞技术团队博客
一、前言
这篇主要由五个部分来组成:
首先是有赞的实时平台架构。
其次是在调研阶段我们为什么选择了 Flink。在这个部分,主要是 Flink 与 Spark 的 structured streaming 的一些对比和选择 Flink 的原因。
第三个就是比较重点的内容,Flink 在有赞的实践。这其中包括了我们在使用 Flink 的过程中碰到的一些坑,也有一些具体的经验。
第四部分是将实时计算 SQL 化,界面化的一些实践。
最后的话就是对 Flink 未来的一些展望。这块可以分为两个部分,一部分是我们公司接下来会怎么去更深入的使用 Flink,另一部分就是 Flink 以后可能会有的的一些新的特性。
二、有赞实时平台架构
有赞的实时平台架构呢有几个主要的组成部分。
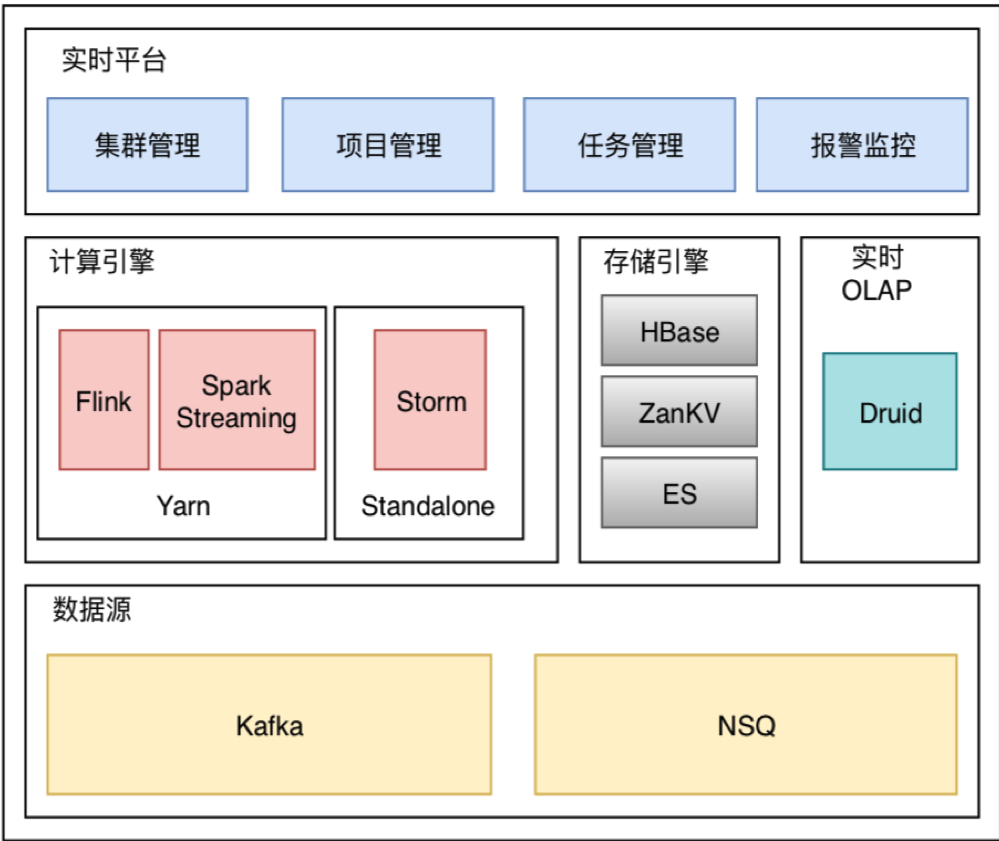 首先,对于实时数据来说,一个消息中间件肯定是必不可少的。在有赞呢,除了业界常用的 Kafka 以外,还有 NSQ。与 Kafka 有别的是,NSQ 是使用 Go 开发的,所以公司封了一层 Java 的客户端是通过 push 和 ack 的模式去保证消息至少投递一次,所以 Connector 也会有比较大的差距,尤其是实现容错的部分。在实现的过程中呢,参考了 Flink 官方提供的 Rabbit MQ 的连接器,结合 NSQ client 的特性做了一些改造。
首先,对于实时数据来说,一个消息中间件肯定是必不可少的。在有赞呢,除了业界常用的 Kafka 以外,还有 NSQ。与 Kafka 有别的是,NSQ 是使用 Go 开发的,所以公司封了一层 Java 的客户端是通过 push 和 ack 的模式去保证消息至少投递一次,所以 Connector 也会有比较大的差距,尤其是实现容错的部分。在实现的过程中呢,参考了 Flink 官方提供的 Rabbit MQ 的连接器,结合 NSQ client 的特性做了一些改造。
接下来就是计算引擎了,最古老的就是 Storm 了,现在依然还有一些任务在 Storm 上面跑,至于新的任务基本已经不会基于它来开发了,因为除了开发成本高以外,语义的支持,SQL 的支持包括状态管理的支持都做得不太好,吞吐量还比较低,将 Storm 的任务迁移到 Flink 上也是我们接下来的任务之一。还有呢就是 Spark Streaming 了,相对来说 Spark 有一个比较好的生态,但是 Spark Streaming 是微批处理的,这给它带来了很多限制,除了延迟高以外还会比较依赖外部存储来保存中间状态。 Flink 在有赞是比较新的引擎,为什么在有了 Spark 和 Storm 的情况下我们还要引入 Flink 呢,下一个部分我会提到。
存储引擎,除了传统的 MySQL 以外,我们还使用 HBase ,ES 和 ZanKV。ZanKV 是我们公司开发的一个兼容 Redis 协议的分布式 KV 数据库,所以姑且就把它当成 Redis 来理解好了。
实时 OLAP 引擎的话基于 Druid,在多维的统计上面有非常好的应用。
最后是我们的实时平台。实时平台提供了集群管理,项目管理,任务管理和报警监控的功能。。
关于实时平台的架构就简单介绍到这里,接下来是 Flink 在有赞的探索阶段。在这个部分,我主要会对比的 Spark Structured Streaming。
三、为什么选择引入 Flink
至于为什么和 Spark Structured Streaming(SSS) 进行对比呢?因为这是实时SQL化这个大背景下比较有代表性的两个引擎。
首先是性能上,从几个角度来比较一下。首先是延迟,毫无疑问,Flink 作为一个流式引擎是优于 SSS 的微批引擎的。虽然说 Spark 也引入了一个连续的计算引擎,但是不管从语义的保证上,还是从成熟度上,都是不如 Flink 的。据我所知,他们是通过将 rdd 长期分配到一个结点上来实现的。
其次比较直观的指标就是吞吐了,这一点在某些场景下 Flink 略逊于 Spark 。但是当涉及到中间状态比较大的任务呢,Flink 基于 RocksDB 的状态管理就显示出了它的优势。 Flink 在中间状态的管理上可以使用纯内存,也可以使用 RocksDB 。至于 RocksDB ,简单点理解的话就是一个带缓存的嵌入式数据库。借助持久化到磁盘的能力,Flink 相比 SSS 来说可以保存的状态量大得多,并且不容易OOM。并且在做 checkpoint 中选用了增量模式,应该是只需要备份与上一次 checkpoint 时不同的 sst 文件。使用过程中,发现 RocksDB 作为状态管理性能也是可以满足我们需求的。
聊完性能,接下来就说一说 SQL 化,这也是现在的一个大方向吧。我在开始尝试 SSS 的时候,尝试了一个 SQL 语句中有多个聚合操作,但是却抛了异常。 后面仔细看了文档,发现确实这在 SSS 中是不支持的。第二个是 distinct 也是不支持的。这两点 Flink 是远优于 SSS 的。所以从实时 SQL 的角度,Flink 又为自己赢得了一票。除此之外,Flink 有更灵活的窗口。还有输出的话,同样参考的是 DataFlow 模型,Flink 实现支持删除并更新的操作,SSS 仅支持更新的操作。(这边 SSS 是基于 Spark 的 2.3版本)
API 的灵活性。在 SSS 中,诚然 table 带来了比较大的方便,但是对于有一些操作依然会想通过 DStream 或者 rdd 的形式来操作,但是 SSS 并没有提供这样的转换,只能编写一些 UDF。但是在 Flink 中,Table 和 DataStream 可以灵活地互相转换,以应对更复杂的场景。
四、Flink在有赞的实践
在真正开始使用 Flink 之前呢,第一个要考虑的就是部署的问题。因为现有的技术栈,所以选择了部署在 Yarn 上,并且使用的是 Single Job 的模式,虽然会有更多的 ApplicationMaster,但无疑是增加了隔离性的。
4.1 问题一: FLINK-9567
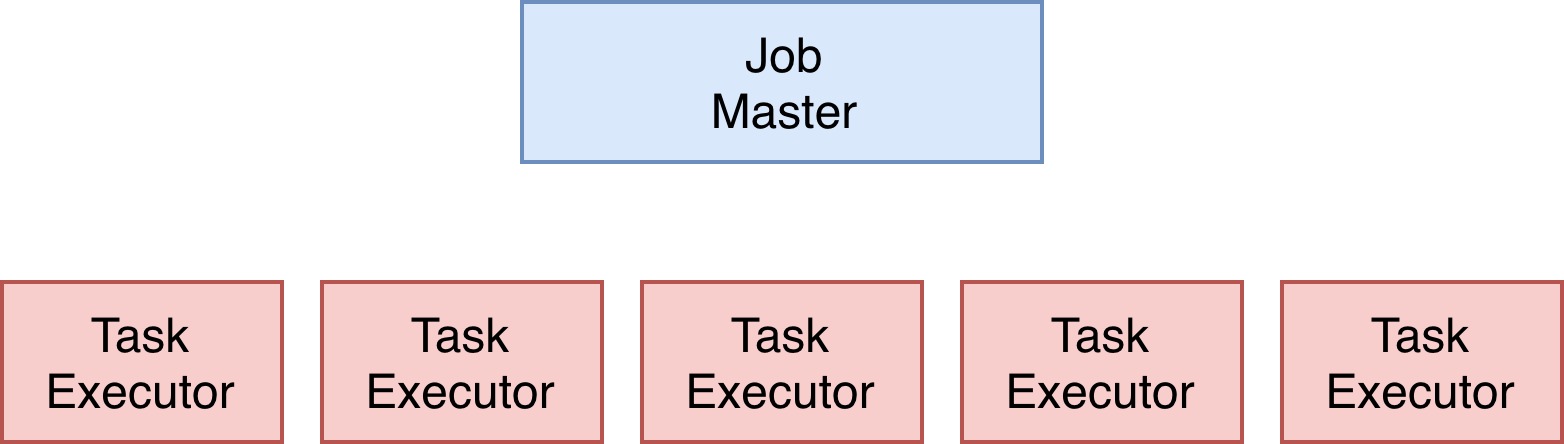
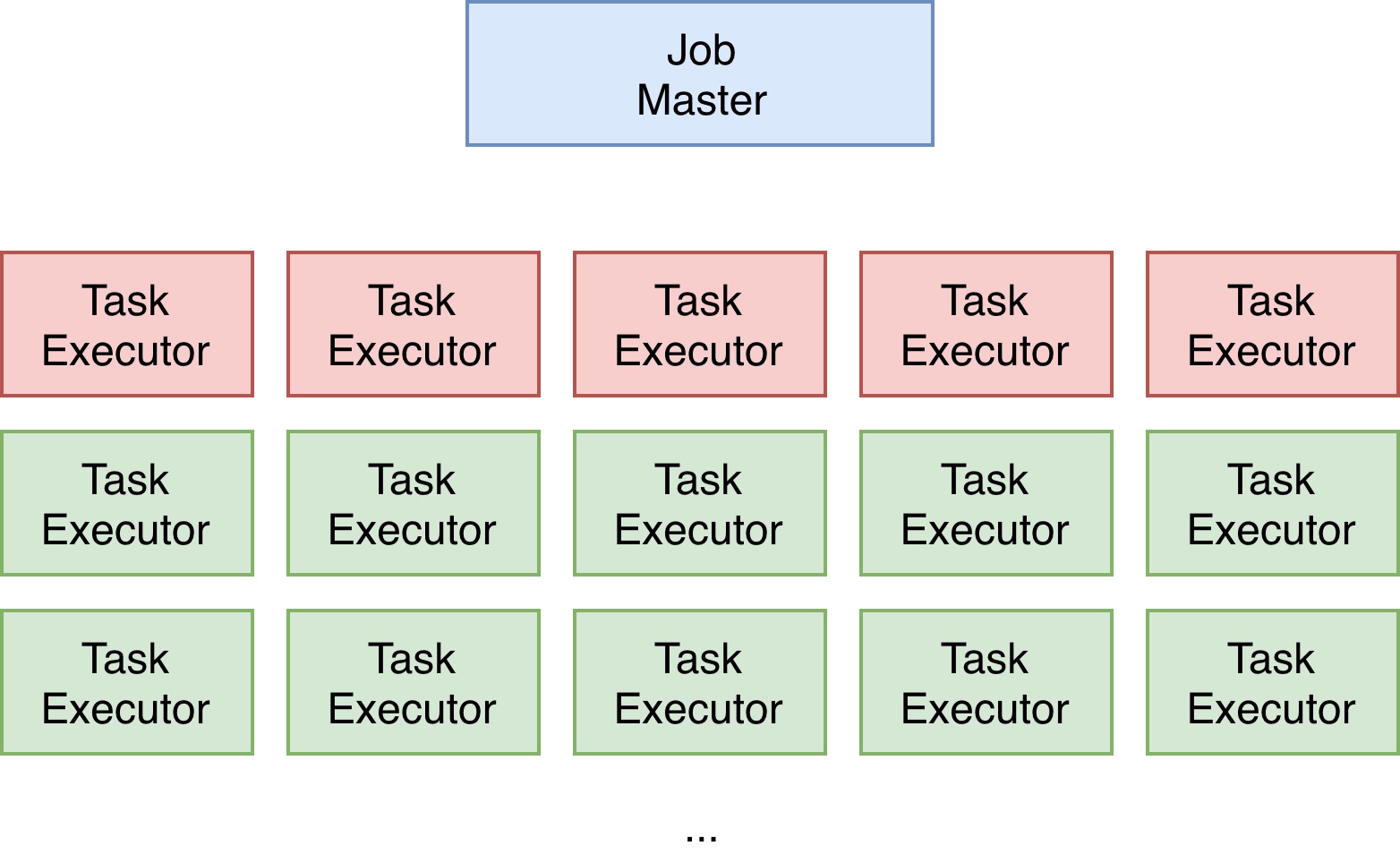
在开始部署的时候我遇到了一个比较奇怪的问题。先讲一下背景吧,因为还处于调研阶段,所以使用的是 Yarn 的默认队列,优先级比较低,在资源紧张的时候也容易被抢占。 有一个上午,我起了一个任务,申请了5个 Container 来运行 TaskExecutor ,一个比较简单地带状态的流式任务,想多跑一段时间看看稳定不稳定。这个 Flink 任务最后占了100多个 container,还在不停增加,但是只有五个 Container 在工作,其他的 container 都注册了 slot,并且 slot 都处于闲置的状态。以下两张图分别代表正常状态下的任务,和出问题的任务。
 出错后
出错后
在涉及到这个问题细节之前,我先介绍一下 Flink 是如何和 Yarn 整合到一块的。根据下图,我们从下往上一个一个介绍这些组件是做什么的。
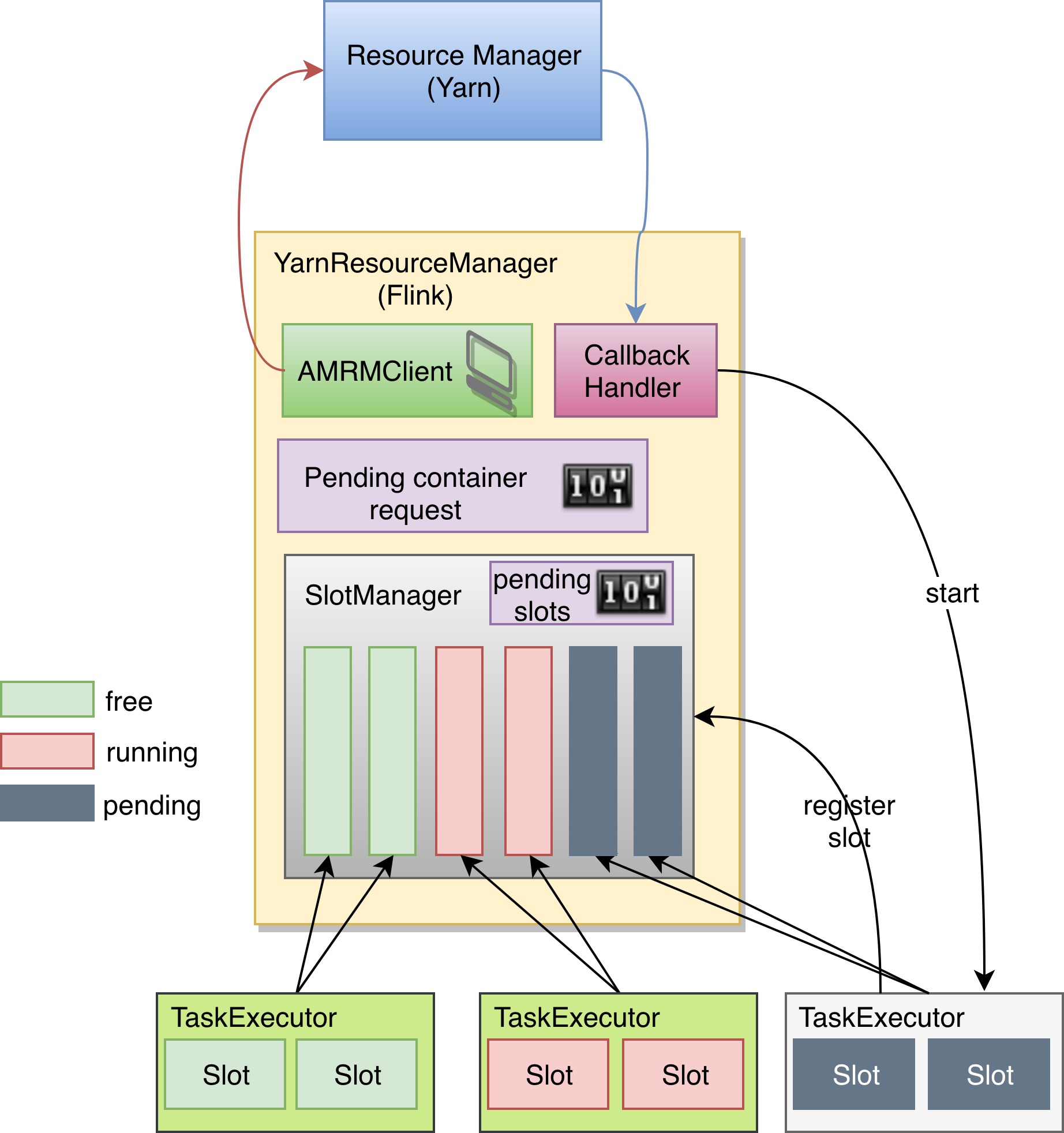
TaskExecutor 是实际任务的执行者,它可能有多个槽位,每个槽位执行一个具体的子任务。每个 TaskExecutor 会将自己的槽位注册到 SlotManager 上,并汇报自己的状态,是忙碌状态,还是处于一个闲置的状态。
SlotManager 既是 Slot 的管理者,也负责给正在运行的任务提供符合需求的槽位。还记录了当前积压的槽位申请。当槽位不够的时候向Flink的ResourceManager申请容器。
Pending slots 积压的 Slot 申请及计数器
Flink 的 ResourceManager 则负责了与 Yarn 的 ResourceManager 进行交互,进行一系列例如申请容器,启动容器,处理容器的退出等等操作。因为采用的是异步申请的方式,所以还需要记录当前积压的容器申请,防止接收过多容器。
Pending container request 积压容器的计数器
AMRMClient 是异步申请的执行者,CallbackHandler 则在接收到容器和容器退出的时候通知 Flink 的 ResourceManager。
Yarn 的 ResourceManager 则像是一个资源的分发器,负责接收容器请求,并为 Client 准备好容器。
这边一下子引入的概念有点多,下面我用一个简单地例子来描述一下这些组件在运行中起到的角色。
首先,我们的配置是3个 TaskManager,每个 TaskManager 有两个 Slot,也就是总共需要6个槽位。当前已经拥有了4个槽位,任务的调度器向 Slot 申请还需要两个槽位来运行子任务。
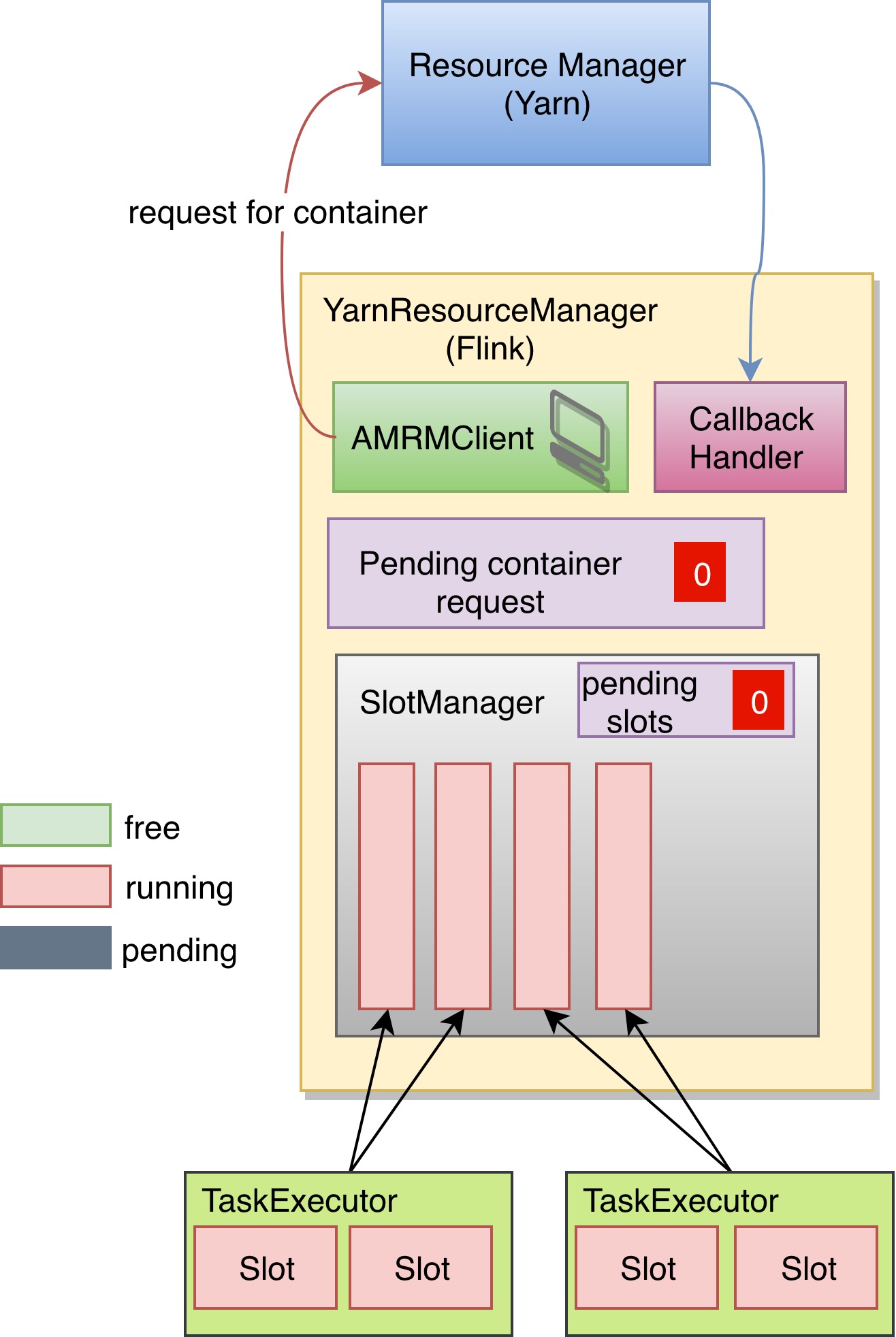
这时 SlotManager 发现所有的槽位都已经被占用了,所以它将这个 slot 的 request 放入了 pending slots 当中。所以可以看到 pending slots 的那个计数器从刚才的0跳转到了现在的2. 之后 SlotManager 就向 Flink 的 ResourceManager 申请一个新的 TaskExecutor,正好就可以满足这两个槽位的需求。于是 Flink 的 ResourceManager 将 pending container request 加1,并通过 AMRM Client 去向 Yarn 申请资源。
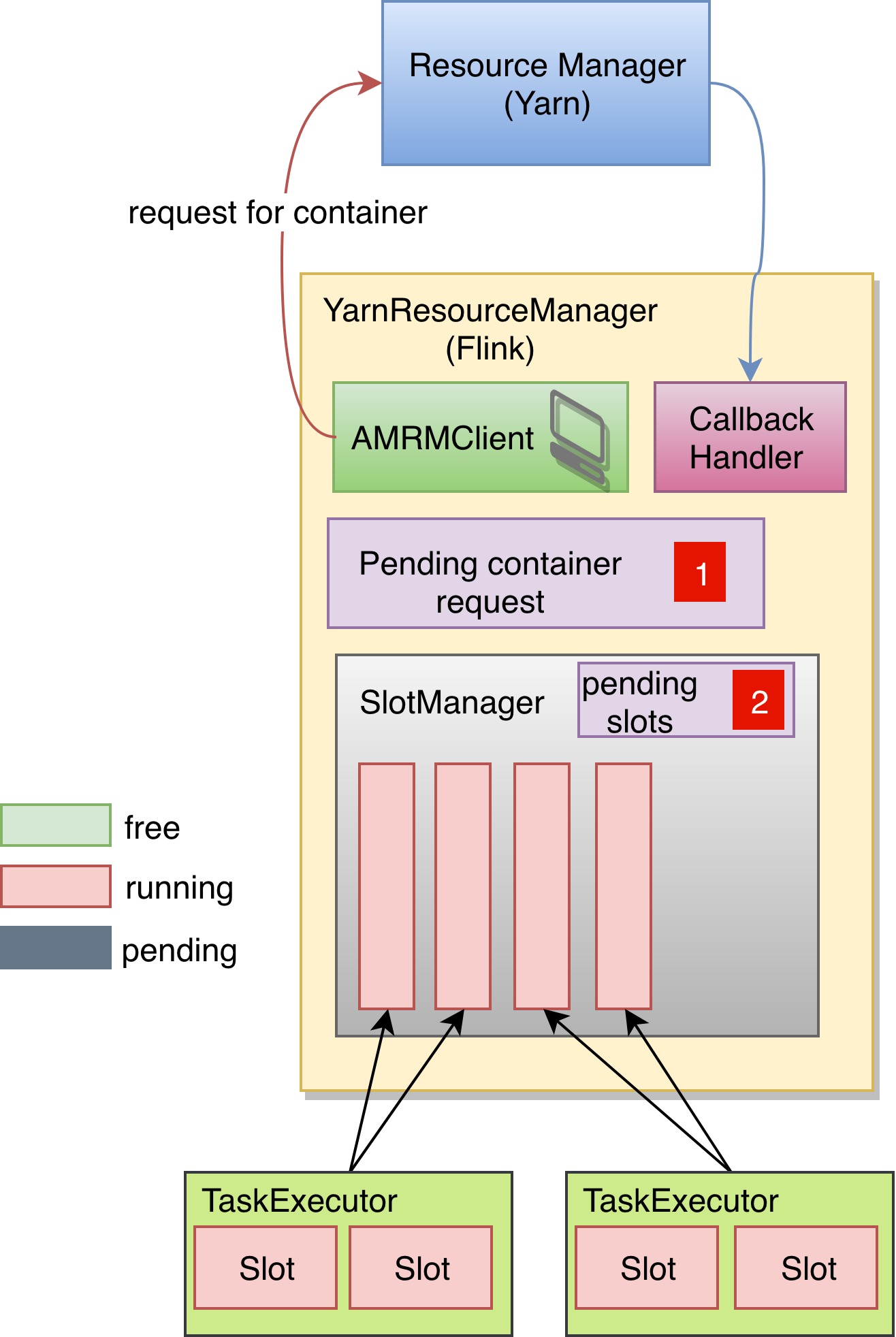
当 Yarn 将相应的 Container 准备好以后,通过 CallbackHandler 去通知 Flink 的 ResourceManager。Flink 就会根据在每一个收到的 container 中启动一个 TaskExecutor ,并且将 pending container request 减1,当 pending container request 变为0之后,即使收到新的 container 也会马上退回。
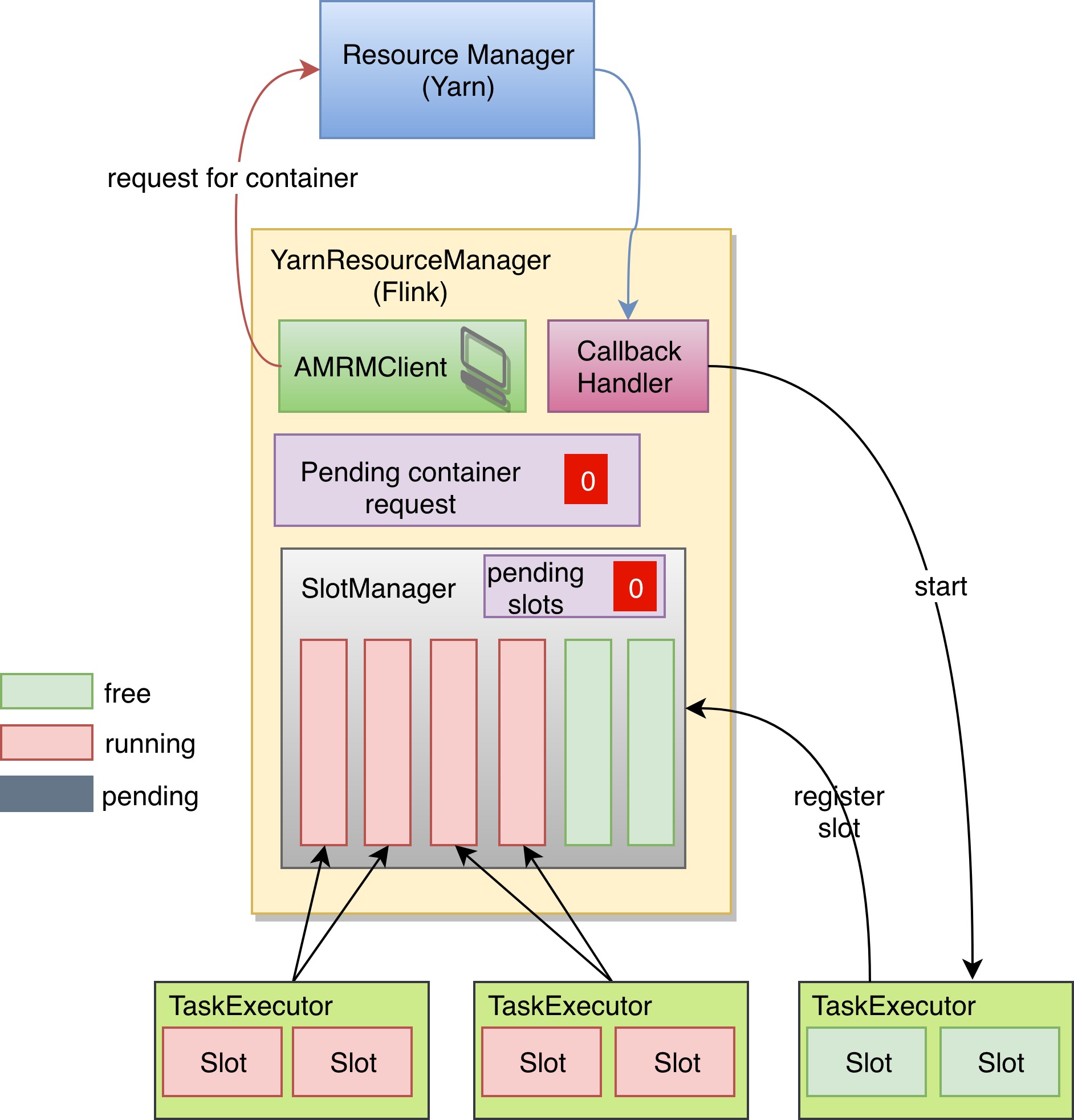
当 TaskExecutor 启动之后,会向 SlotManager 注册自己的两个 Slot 可用,SlotManager 便会将两个积压的 SlotRequest 完成,通知调度器这两个子任务可以到这个新的 TaskExecutor 上执行,并且 pending requests 也被置为0. 到这儿一切都符合预期。
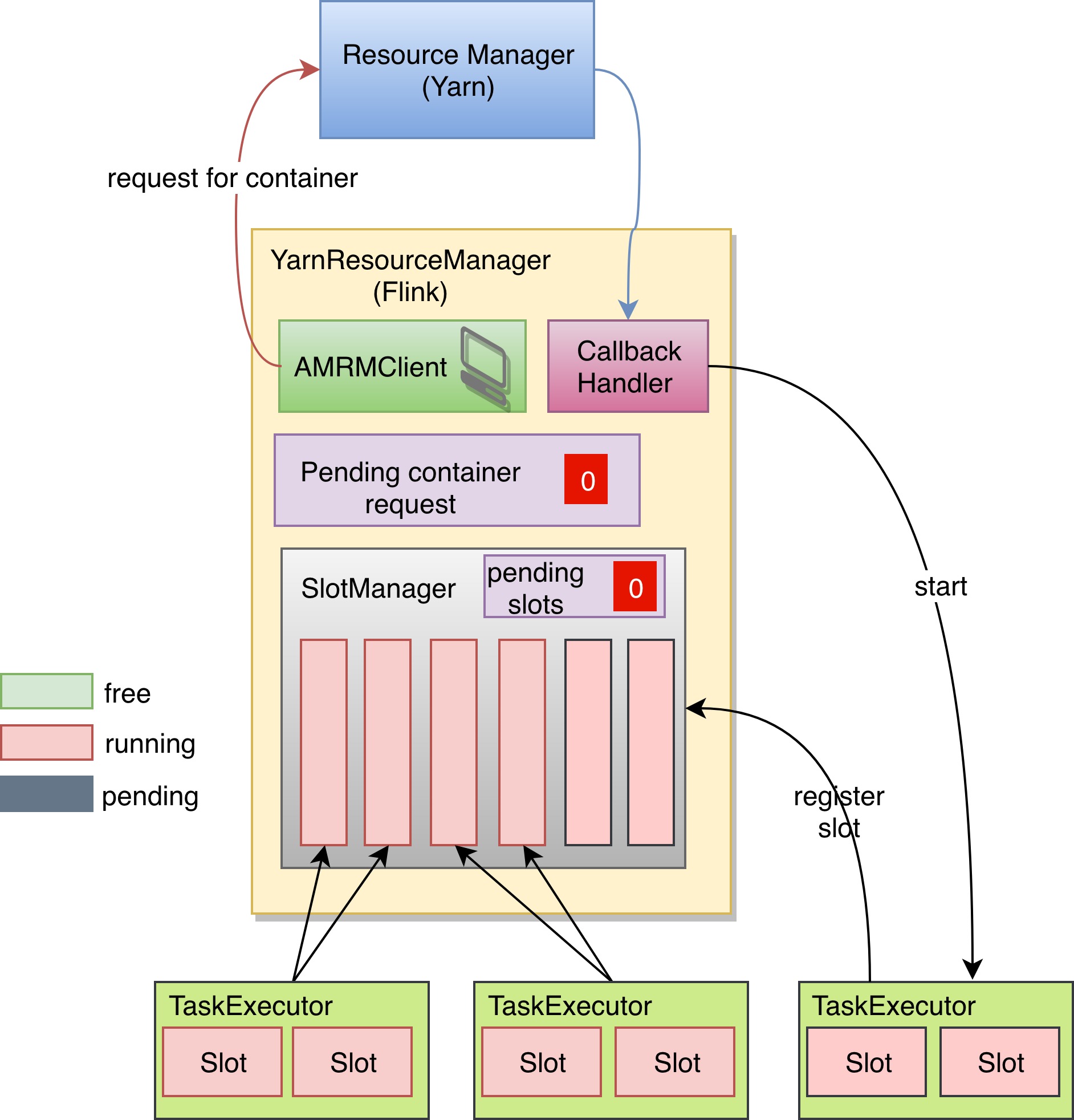
那这个超发的问题又是如何出现的呢?首先我们看一看这就是刚刚那个正常运行的任务。它占用了6个 Slot。
如果在这个时候,出现了一些原因导致了 TaskExecutor 非正常退出,比如说 Yarn 将资源给抢占了。这时 Yarn 就会通知 Flink 的 ResourceManager 这三个 Container 已经异常退出。所以 Flink 的 ResourceManager 会立即申请三个新的 container。在这儿会讨论的是一个 worst case,因为这个问题其实也不是稳定复现的。
CallbackHandler 两次接收到回调发现 Container 是异常退出,所以立即申请新的 Container,pending container requests 也被置为了3.
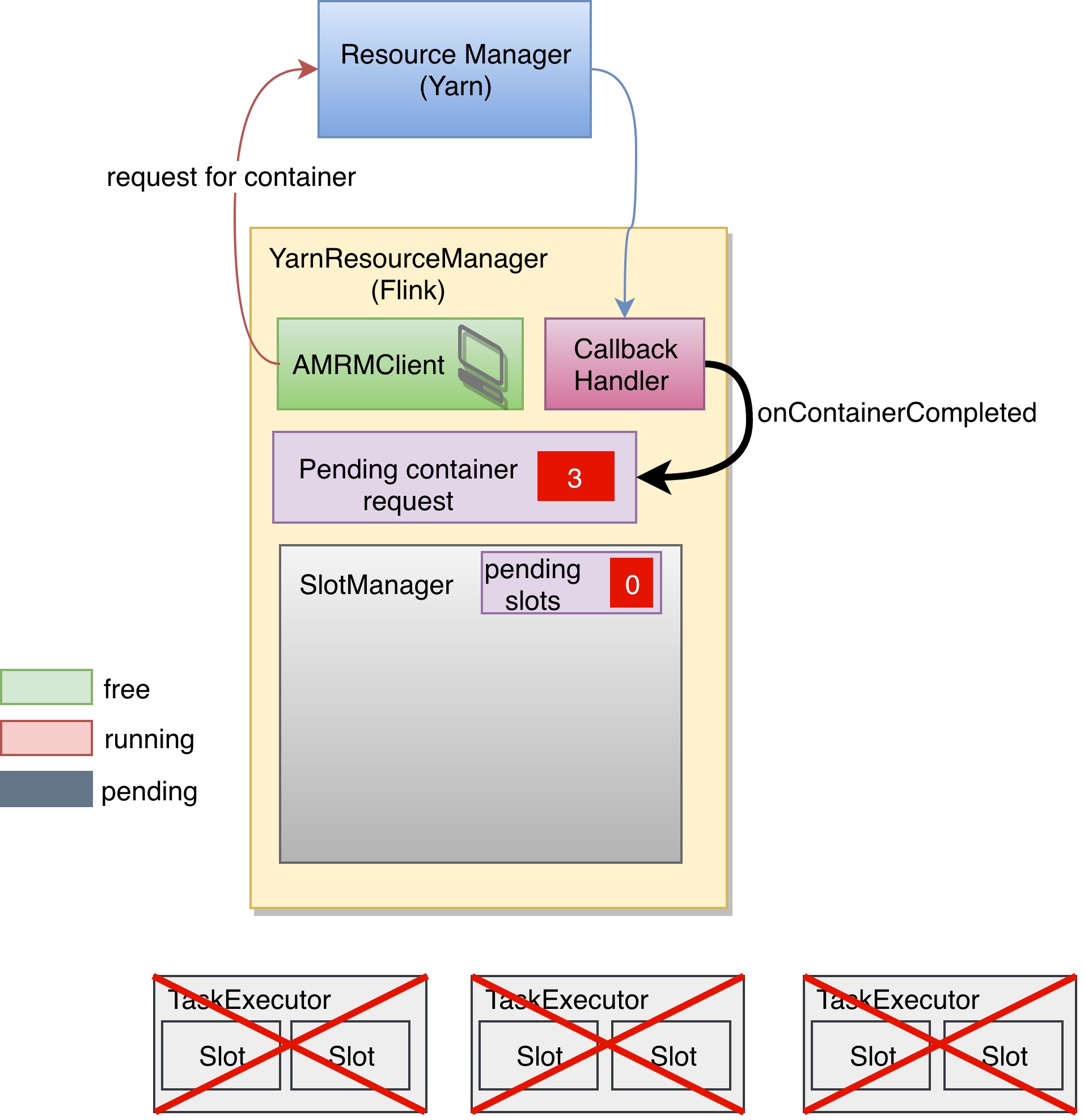
如果在这时,任务重启,调度器会向 SlotManager 申请6个 Slot,SlotManager 中也没有可用 Slot,就会向 Flink 的 ResourceManager 申请3个 Container,这时 pending container requests 变为了6.
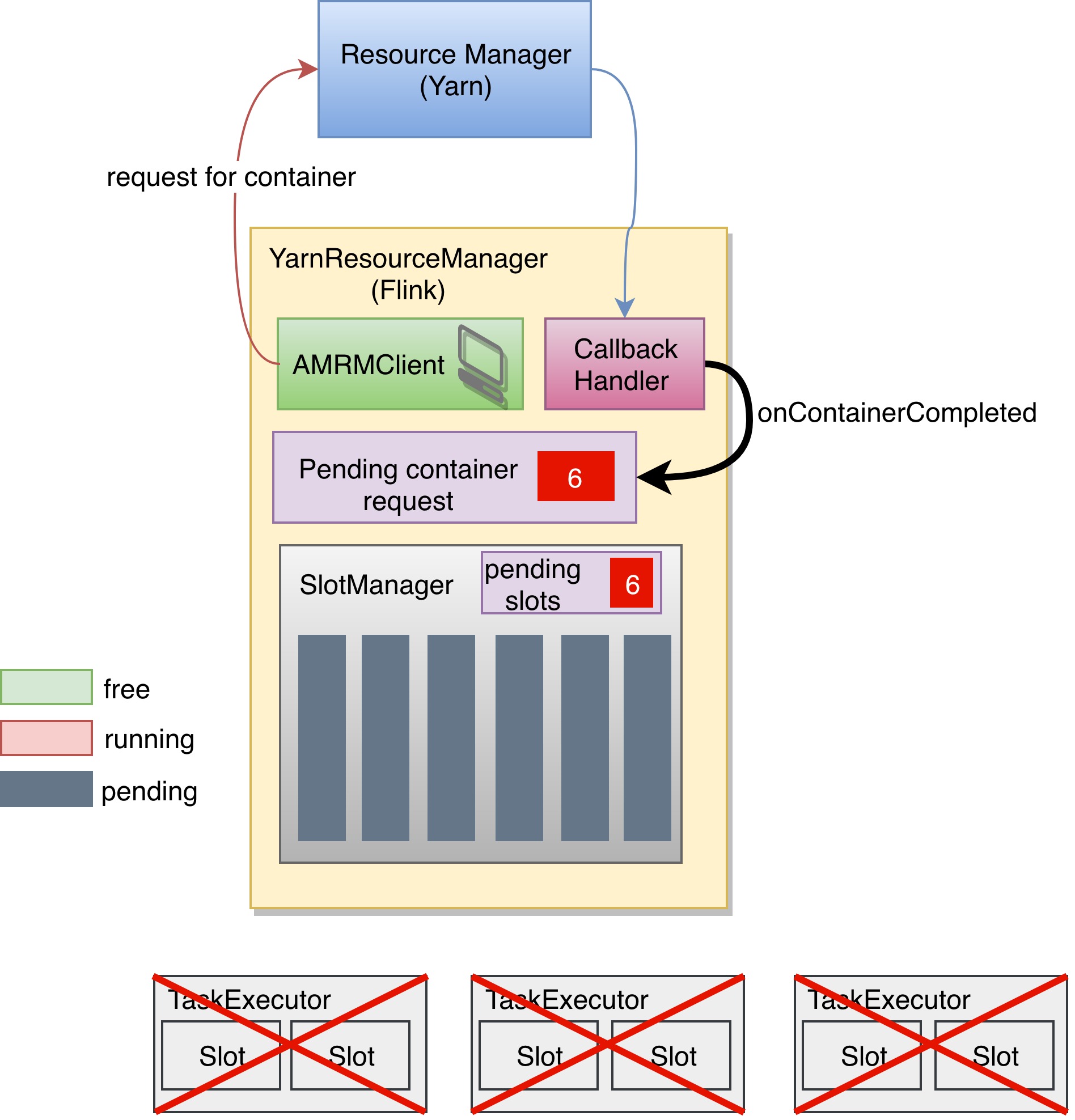
最后呢结果就如图所示,起了6个 TaskExecutor,总共12个 Slot,但是只有6个是被正常使用的,还有6个一直处于闲置的状态。
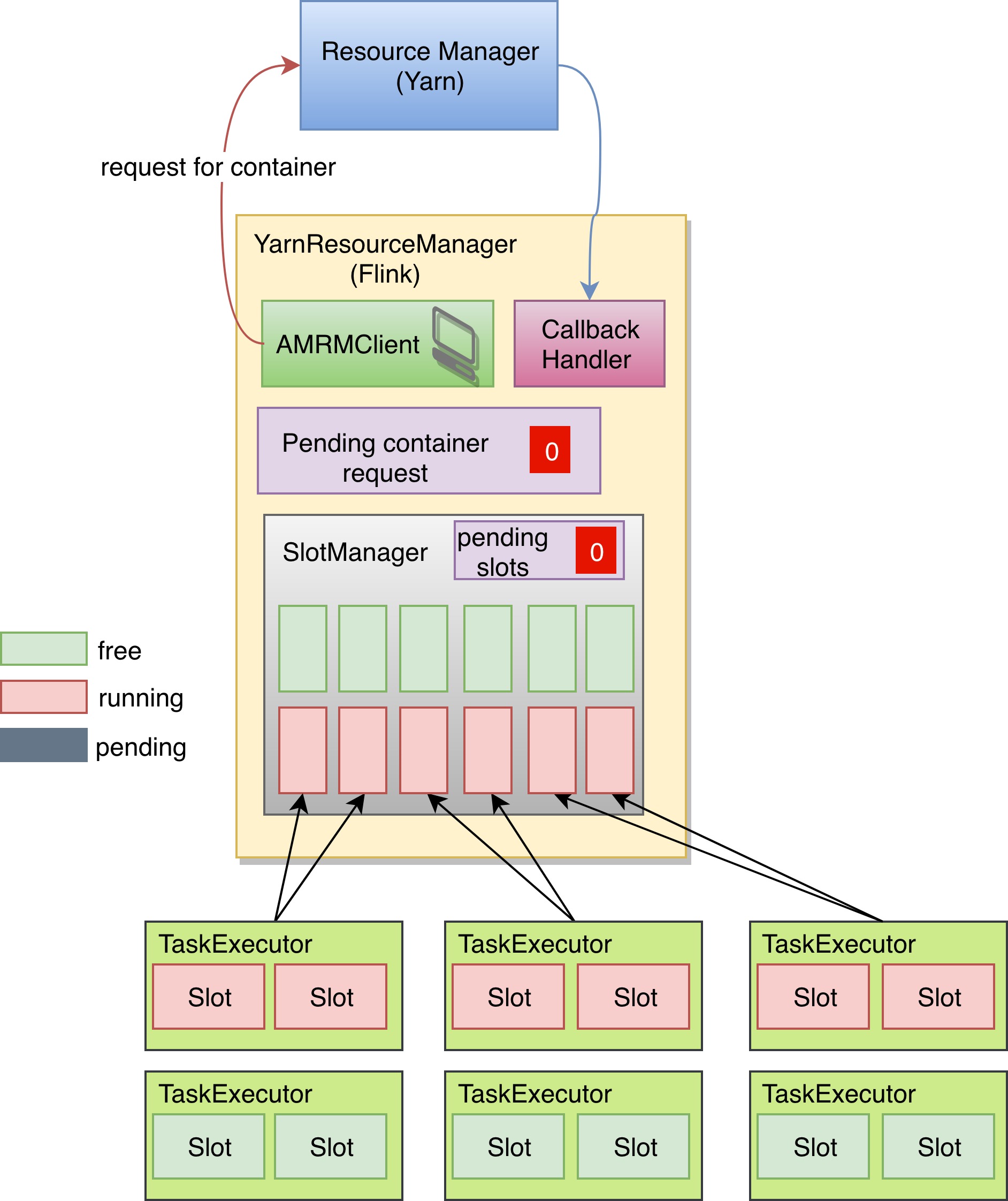
在修复这个问题的过程中,我有两次尝试。第一次尝试,在 Container 异常退出以后,我不去立即申请新的 container。但是问题在于,如果 Container 在启动 TaskExecutor 的过程中出错,那么失去了这种补偿的机制,有些 Slot Request 会被一直积压,因为 SlotManager 已经为它们申请了 Container。 第二次尝试是在 Flink 的 ResourceManager 申请新的 container 之前先去检查 pending slots,如果当前的积压 slots 已经可以被积压的 container 给满足,那就没有必要申请新的 container 了。
4.2 问题二: 监控
我们使用过程中踩到的第二个坑,其实是跟延迟监控相关的。例子是一个很简单的任务,两个 source,两个除了 source 之外的 operator,并行度都是2. 每个 source 和 operator 它都有两个子任务。
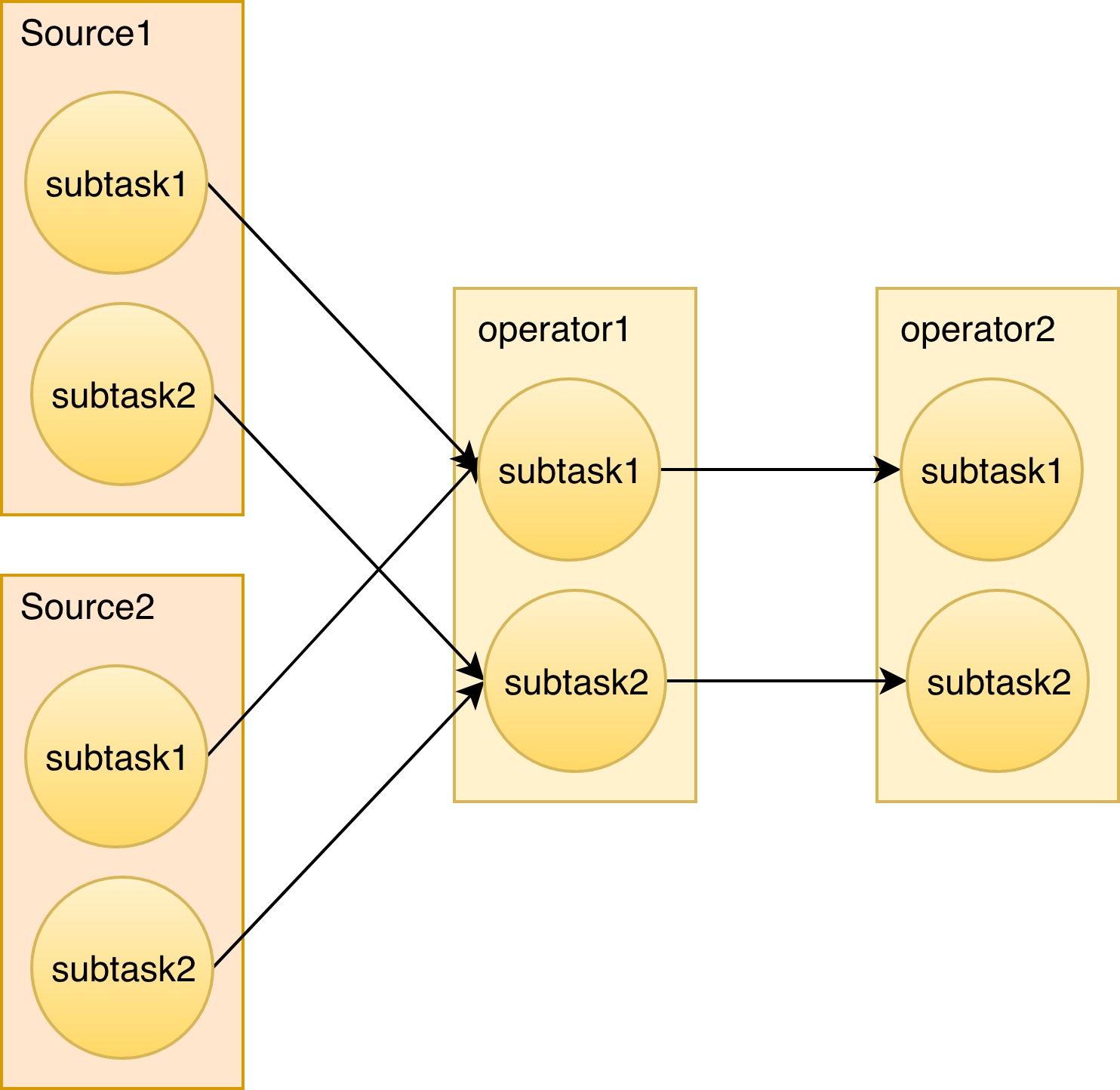
任务的逻辑是很简单,但是呢当我们打开延时监控。即使是这么简单的一个任务,它会记录每一个 source 的子任务到每一个算子的子任务的延迟数据。这个延迟数据里还包含了平均延迟,最大延迟,百分之99的延迟等等等等。那我们可以得出一个公式,延迟数据的数量是 source 的子任务数量乘以的 source 的数量乘以算子的并行度乘以算子的数量。N = n(subtasks per source) * n(sources) * n(subtasks per operator) * n(operator)
这边我做一个比较简单地假设,那就是 source 的子任务数量和算则的子任务数量都是 p - 并行度。从下面这个公式我们可以看出,监控的数量随着并行度的上升呈平方增长。N = p^2 * n(sources) * n(operator)
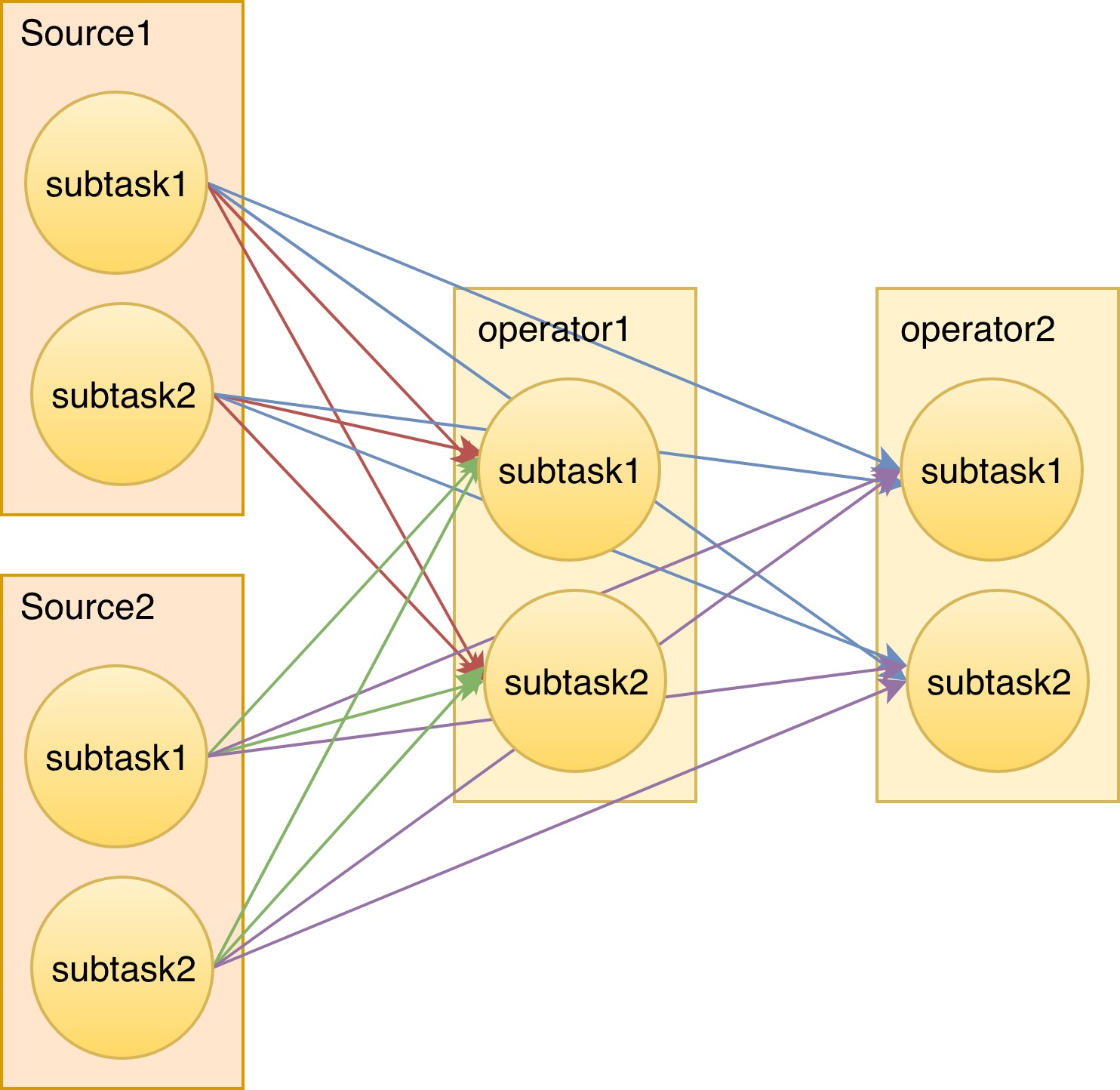
如果我们把上个任务提升到10个并行度,那么就会收到400份的延迟数据。这可能看起来还没有太大的问题,这貌似并不影响组件的正常运行。
但是,在 Flink 的 dev mailing list 当中,有一个用户反馈在开启了延迟监控之后,JobMaster 很快就会挂掉。他收到了24000+的监控数据,并且包含这些数据的 ConcurrentHashMap 在内存中占用了1.6 G 的内存。常规情况 Flink 的 JobMaster 时会给到多少内存,我一般会配1-2 g,最后会导致长期 FullGC 和 OOM 的情况。
那怎么去解决这个问题呢?当延迟监控已经开始影响到系统的正常工作的时候,最简单的办法就是把它给关掉。可是把延时监控关掉,一方面我们无法得知当前任务的延时,另一方面,又没有办法去针对延时做一些报警的功能。 所以另一个解决方案就如下。首先是 Flink-10243,它提供了更多的延迟监控粒度的选项,从源头上减少数量。比如说我们使用了 Single 模式去采集这些数据,那它只会记录每个 operator 的子任务的延迟,忽略是从哪个 source 或是 source 的子任务中来。这样就可以得出这样一个公式,也能将之前我们提到的十个并行度的任务产生的400个延时监控降低到了40个。这个功能发布在了1.7.0中,并且 backport 回了1.5.5和1.6.2. 此外,Flink-10246 提出了改进 MetricQueryService。它包含了几个子任务,前三个子任务为监控服务建立了一个专有的低优先级的 ActorSystem,在这里可以简单的理解为一个独立的线程池提供低优先级的线程去处理相关任务。它的目的也是为了防止监控任务影响到主要的组件。这个功能发布在了1.7.0中。 还有一个就是 Flink-10252,它还依旧处于 review 和改进当中,目的是为了控制监控消息的大小。
4.3 具体实践一
接下来会谈一下 Flink 在有赞的一些具体应用。 首先是 Flink 结合 Spring。为什么要将这两者做结合呢,首先在有赞有很多服务都只暴露了 Dubbo 的接口,而用户往往都是通过 Spring 去获取这个服务的 client,在实时计算的一些应用中也是如此。 另外,有不少数据应用的开发也是 Java 工程师,他们希望能在 Flink 中使用 Spring 以及生态中的一些组件去简化他们的开发。用户的需求肯定得得到满足。接下来我会讲一些错误的典型,以及最后是怎么去使用的。
第一个错误的典型就是在 Flink 的用户代码中启动一个 Spring 环境,然后在算子中取调用相关的 bean。但是事实上,最后这个 Spring Context 是启动在 client 端的,也就是提交任务的这一端,在图中有一个红色的方框中间写着 Spring Context 表示了它启动的位置。可是用户在实际调用时确实在 TaskManager 的 TaskSlot 中,它们都处在不同的 jvm,这明显是不合理的。所以呢我们又遇到了第二个错误。
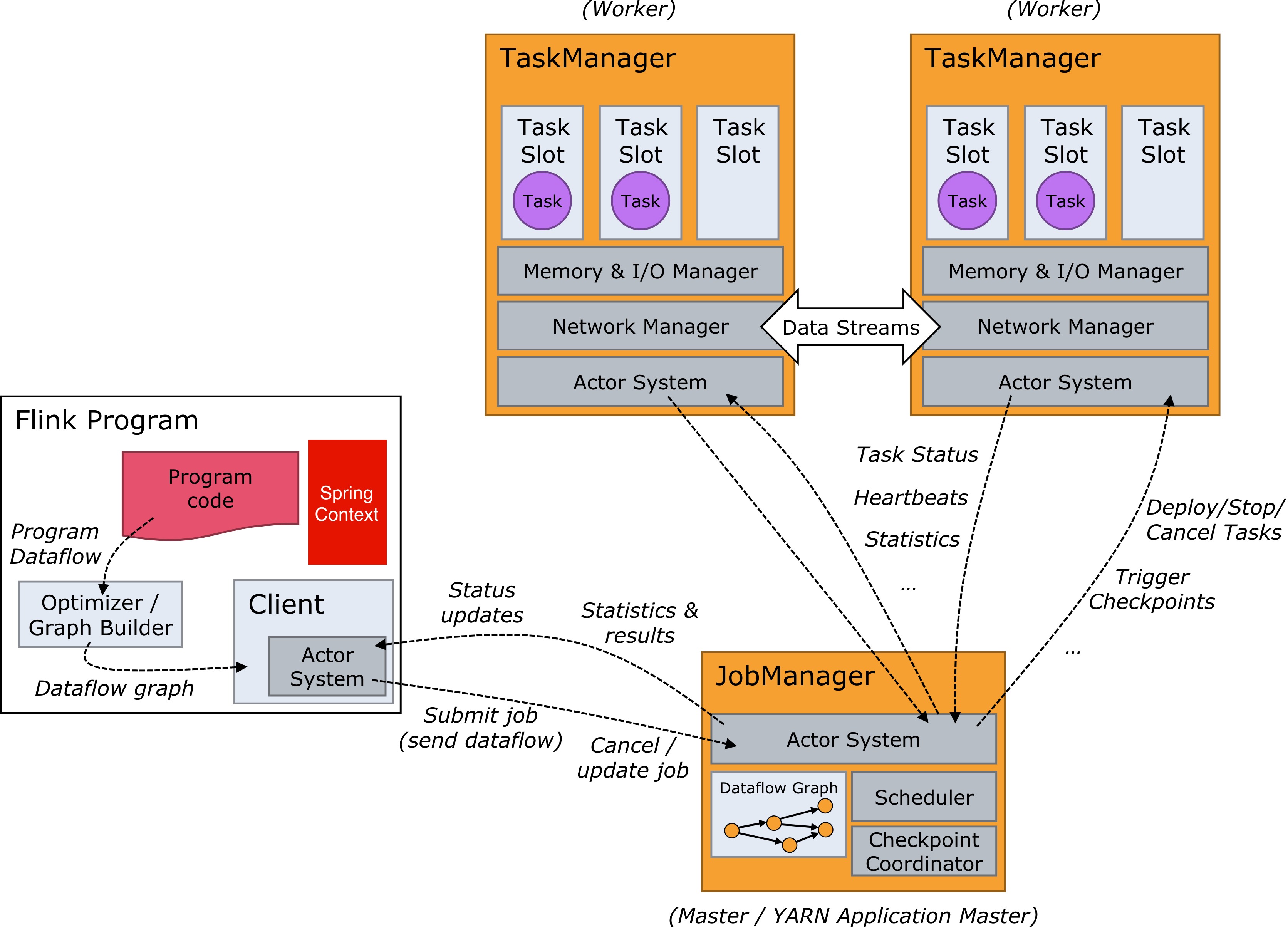
第二个错误比第一个错误看起来要好多了,我们在算子中使用了 RichFunction,并且在 open 方法中通过配置文件获取了一个 Spring Context。但是先不说一个 TaskManager 中启动几个 Spring Context 是不是浪费,一个 Jvm 中启动两个 Spring Context 就会出问题。可能有用户就觉得,那还不简单,把 TaskSlot 设为1不就行了。可是还有 OperatorChain 这个机制将几个窄依赖的算子绑定到一块运行在一个 TaskSlot 中。那我们关闭 OperatorChain 不就行了?还是不行,Flink可能会做基于 CoLocationGroup 的优化,将多个 subtask 放到一个 TaskSlot 中轮番执行。
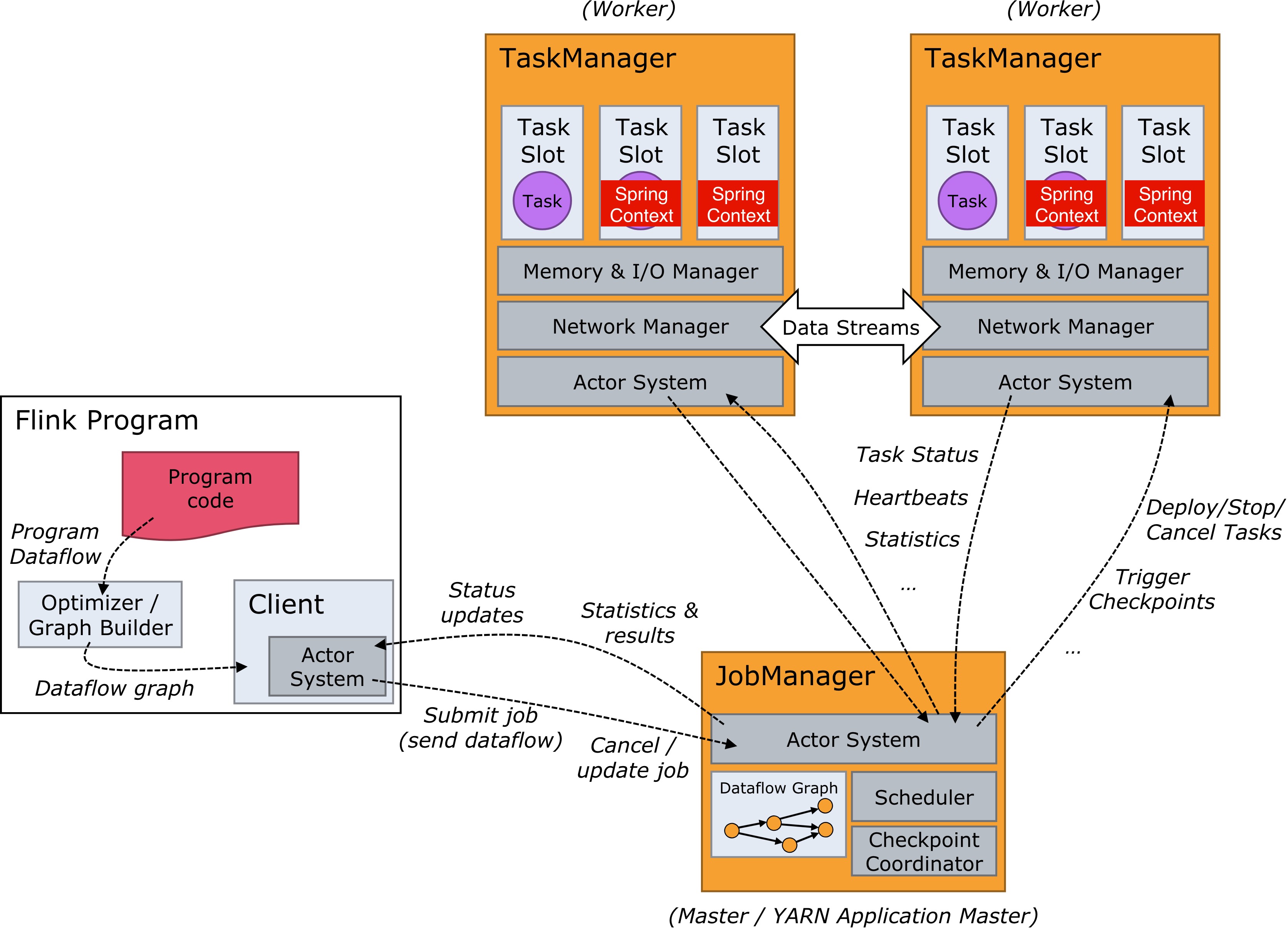
但其实最后的解决方案还是比较容易的,无非是使用单例模式来封装 SpringContext,确保每个jvm中只有一个,在算子函数的 open 方法中通过这个单例来获取相应的 Bean。
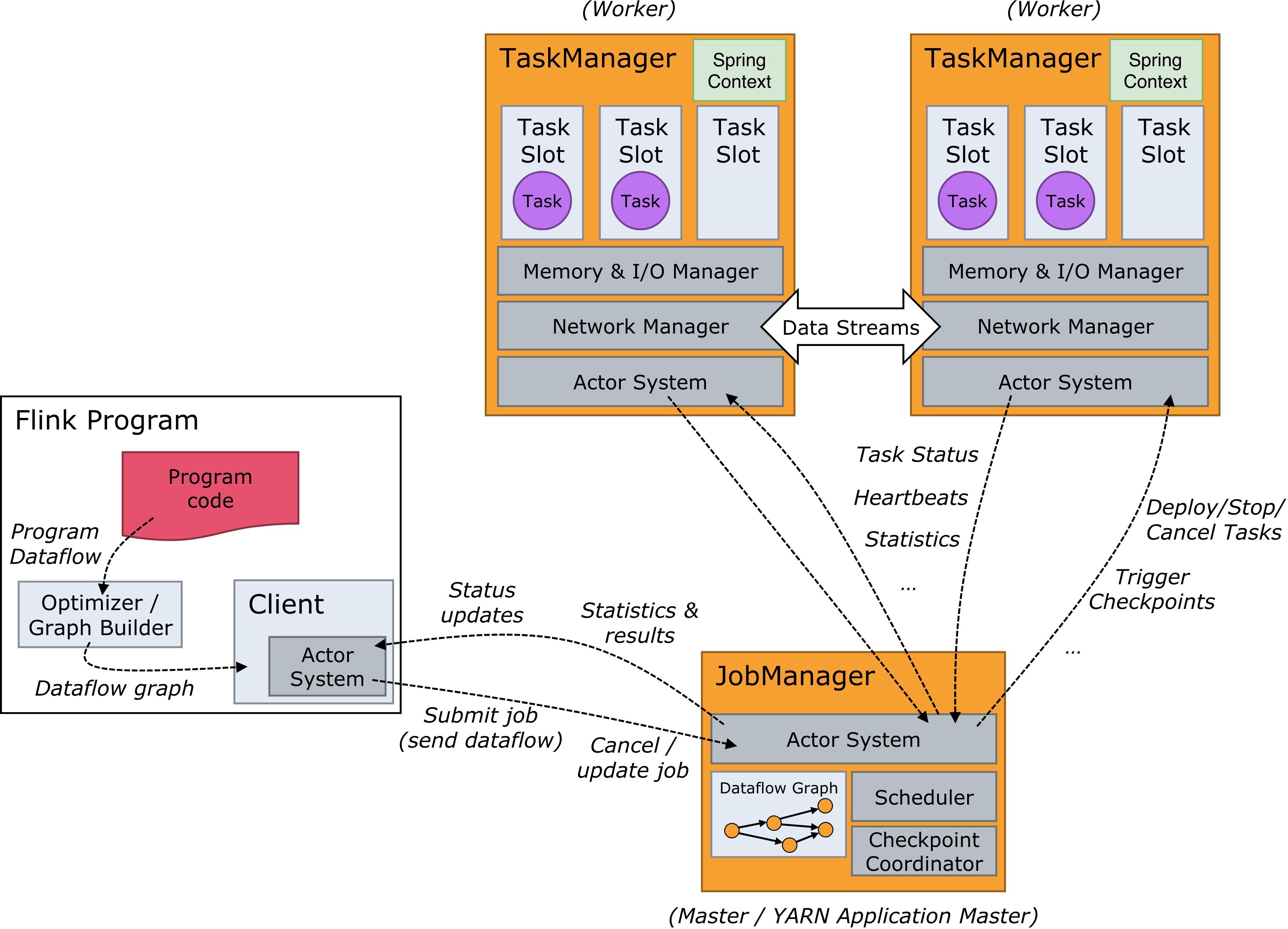
可是在调用 Dubbo 服务的时候,一次响应往往最少也要在10 ms 以上。一个 TaskSlot 最大的吞吐也就在一千,可以说对性能是大大的浪费。那么解决这个问题的话可以通过异步和缓存,对于多次返回同一个值的调用可以使用缓存,提升吞吐我们可以使用异步。
4.4 具体实践二
可是如果想同时使用异步和缓存呢?刚开始我觉得这是一个挺容易实现的功能,但在实际写 RichAsyncFunction 的时候我发现并没有办法使用 Flink 托管的 KeyedState。所以最初想到的方法就是做一个类似 LRU 的 Cache 去缓存数据。但是这完全不能借助到 Flink 的状态管理的优势。所以我研究了一下实现。
为什么不支持呢?
当一条记录进入算子的时候,Flink 会先将 key 提取出来并将 KeyedState 指向与这个 key 关联的存储空间,图上就指向了 key4 相关的存储空间。但是如果此时 key1 关联的异步操作完成了,希望把内容缓存起来,会将内容写入到 key4 绑定的存储空间。当下一次 key1 相关的记录进入算子时,回去 key1 关联的存储空间查找,可是根本找不到数据,只好再次请求。
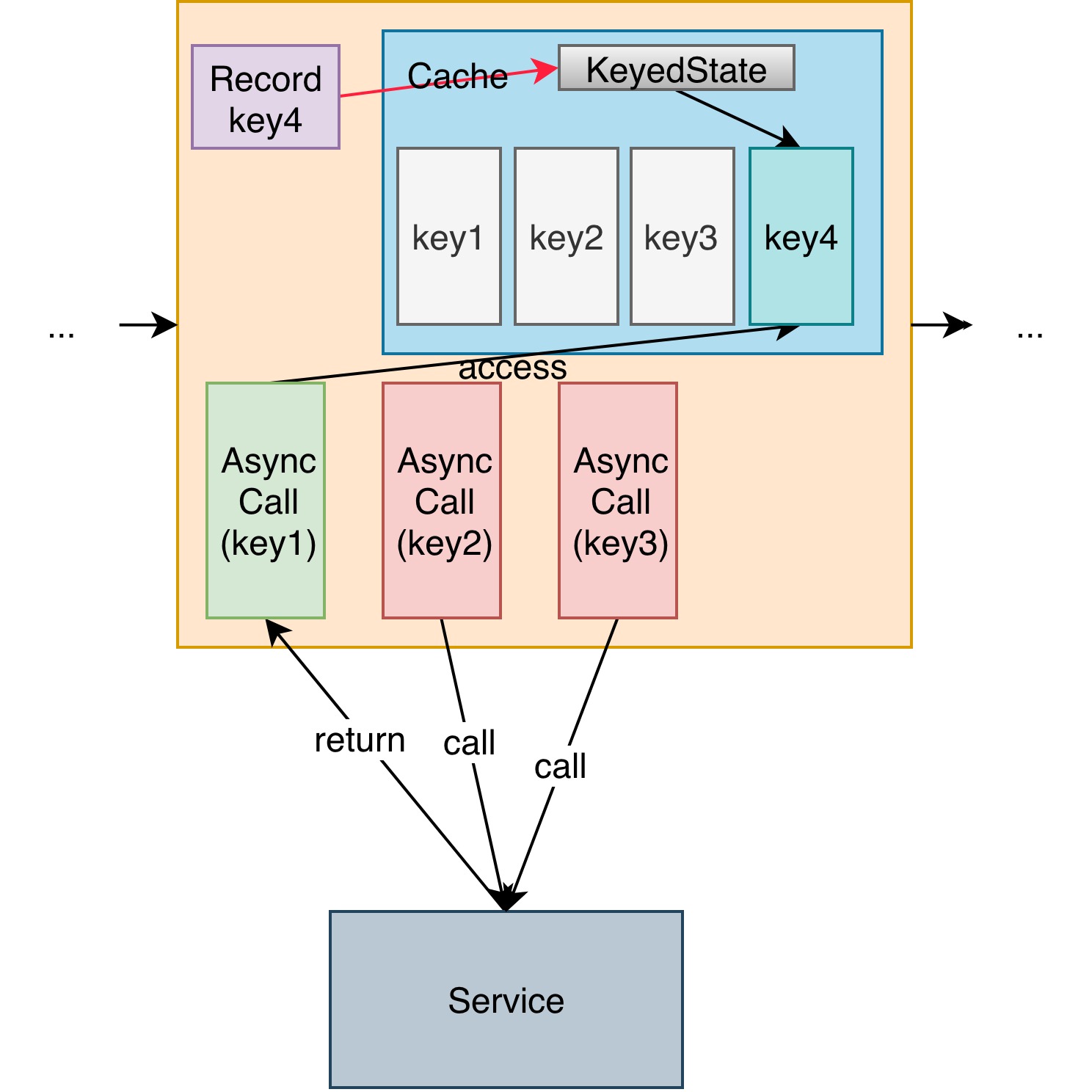
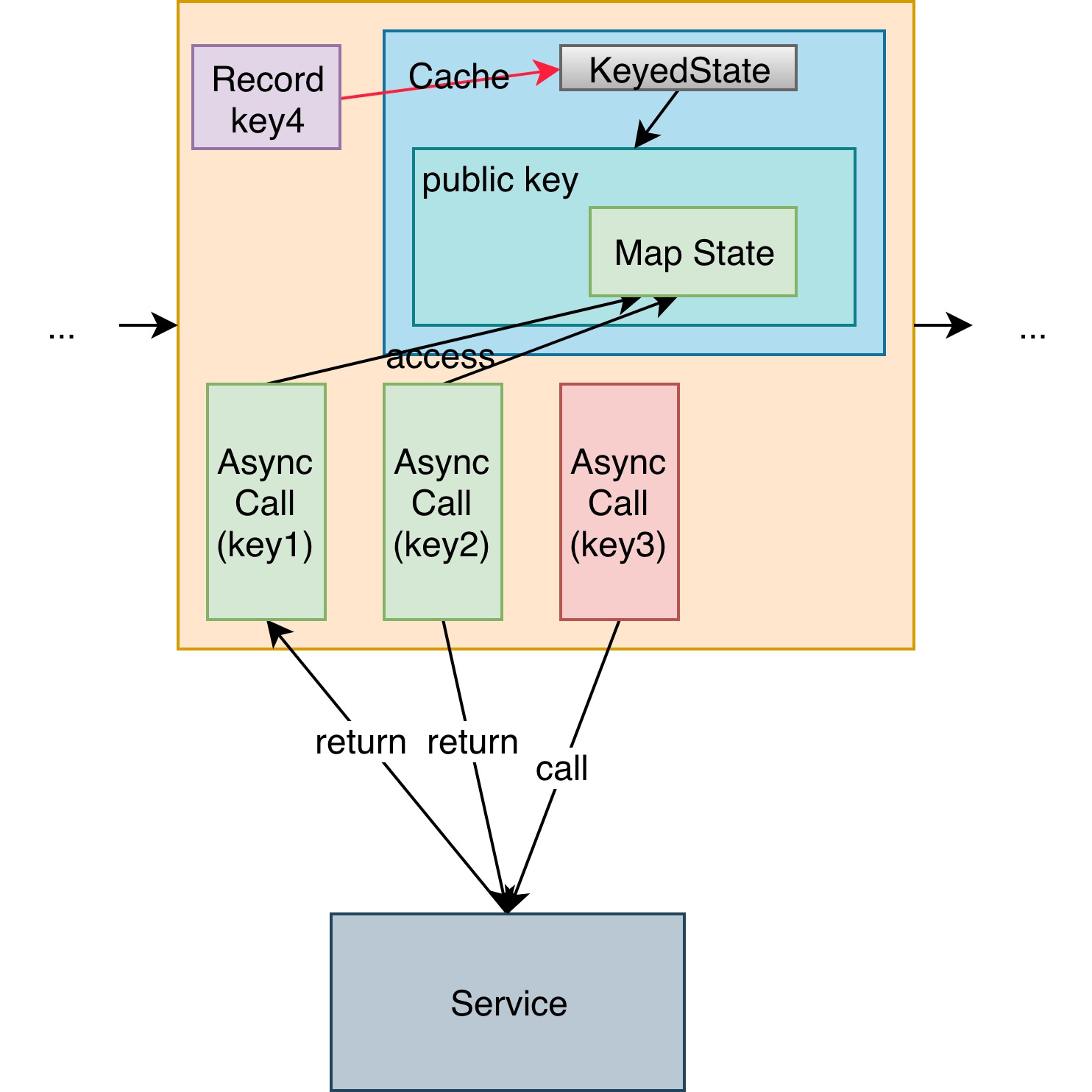
所以解决的方法是定制一个算子,每条记录进入系统,都让它指向同一个公用 key 的存储空间。在这个空间使用 MapState 来做缓存。最后算子运行的 function 继承 AbstractRichFunction 在 open 方法中来获取 KeyedState,实现 AsyncFunction 接口来做异步操作。
五、实时计算 SQL 化与界面化
最早我们使用 SDK 的方式来简化 SQL 实时任务的开发,但是这对用户来说也不算非常友好,所以现在讲 SQL 实时任务界面化,用 Flink 作为底层引擎去执行这些任务。
在做 SQL 实时任务时,首先是外部系统的抽象,将数据源和数据池抽象为流资源,用户将它们数据的 Schema 信息和元信息注册到平台中,平台根据用户所在的项目组管理读写的权限。在这里消息源的格式如果能做到统一能降低很多复杂度。比如在有赞,想要接入的用户必须保证是 Json 格式的消息,通过一条样例消息可以直接生成 Schema 信息。
接下来是根据用户选择的数据源和数据池,获取相应的 Schema 信息和元信息,在 Flink 任务中注册相应的外部系统 Table 连接器,再执行相应的 SQL 语句。
在 SQL 语义不支持的功能上尽量使用 UDF 的方式来拓展。
有数据源和数据池之间的元信息,还可以获取实时任务之间可能存在的依赖关系,并且能做到整个链路的监控
六、未来与展望
Flink 的批处理和 ML 模块的尝试,会跟 Spark 进行对比,分析优劣势。目前还处于调研阶段,目前比较关注的是 Flink 和 Hive的结合,对应 FLINK-10566 这个 issue。
从 Flink 的发展来讲呢,我比较关注并参与接下来对于调度和资源管理的优化。现在 Flink 的调度和任务执行图是耦合在一块的,使用比较简单地调度机制。通过将调度器隔离出来,做成可插拔式的,可以应用更多的调度机制。此外,基于新的调度器,还可以去做更灵活的资源补充和减少机制,实现 Auto Scaling。这可能在接下来的版本中会是一个重要的特性。对应 FLINK-10404 和 FLINK-10429 这两个 issue。
最后打个小广告,有赞大数据团队基础设
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%9C%A8%E6%9C%89%E8%B5%9E%E5%AE%9E%E6%97%B6%E8%AE%A1%E7%AE%97%E7%9A%84%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


