复杂语境下的实体关系抽取

嘉宾:曾道建 湖南师范大学 助理教授
整理:盛泳潘 重庆大学 助理研究员
出品:DataFunTalk
导读: 实体关系抽取是知识图谱构建过程中的一个重要环节,同时也是信息抽取中的一个主要任务。近年来,该课题受到了学术界与工业界研究者们的广泛关注,其主要包含多个子任务,如关系分类、远程监督关系抽取等。今天的分享主要为实体关系联合抽取与文档级关系抽取,可将它们归结为复杂语境下的实体关系抽取。
01 实体关系抽取任务介绍

一般情况下,我们将关系定义为两个或多个实体间的某种联系,而实体关系抽取旨在自动发现实体间存在的某种语义关系。在上图中,我们可以判别出“乔布斯(人)”和“苹果(公司)”之间有一种创始人关系。
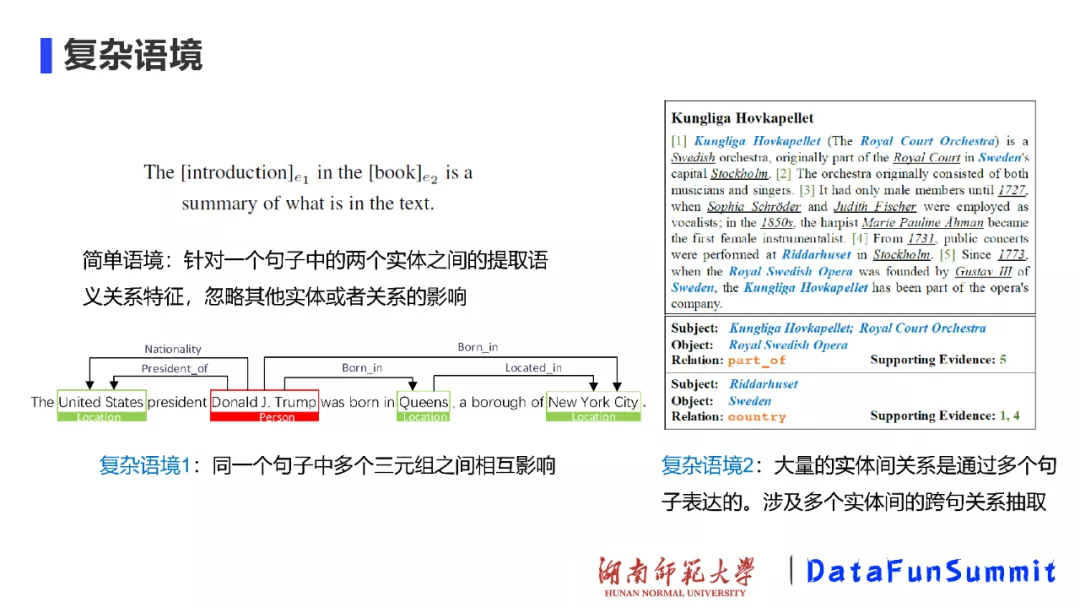
传统的实体关系抽取我们称之为简单语境,其主要针对一个句子中的两个实体之间的语义关系特征,在这种语境下会忽略其他实体或者关系的影响。而复杂语境通常包括两种,如上图中所列出的:(1)同一个句子中多个三元组之间相互影响;如上图(左),Donald J. Trump和Queens之间有Born_in关系,Queens和New York City之间有Located_in关系,那么也可以推断出Donald J. Trump和New York City之间有Located_in关系;(2)大量的实体间关系是通过多个句子表达的,其主要涉及多个实体间的跨句关系抽取。上图(右)为从清华大学刘知远老师团队发布的DocRED数据集上所获得的截图,在发布该数据集时有进行简单的统计,统计结果表明:在维基百科数据集人工标注的结果中,至少有40%实体关系相关的事实只能从多个句子中进行联合抽取。
02 实体关系联合抽取

对于实体关系联合抽取任务,目前有较多的框架/方法类别,如基于序列标注的方法,基于表填充的方法,序列到序列的方法,多任务学习的方法等,以下我们将就三类方法进行展开介绍。
1. 基于序列标注的方法
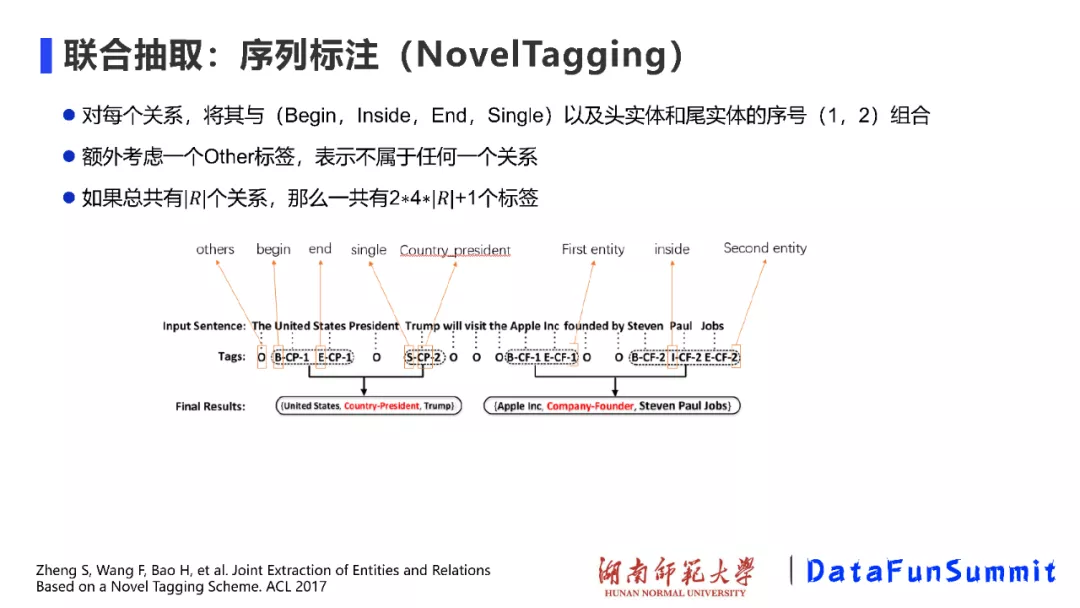
对于序列标注的方法,不得不提2017年在ACL上发表的一篇文章《Joint Extraction of Entities and Relations Based on Novel Tagging Scheme》,(当时这篇文章也获得了Outstanding paper)。在上述NovelTagging方法中,作者提出了一种新的关系标注模式(Relation tagging schema),对于每种关系,将其与(Begin, Inside,End,Single)以及头实体和尾实体的序号(1,2)组会起来进行关系抽取,并根据最后的标注结果进行解码,进而得到关系三元组。再者,该方法额外考虑了一个Other标签,主要表示不属于任何一种关系。如果总共有|R|种关系,那么一共就有2 4 |R|+1个标签。
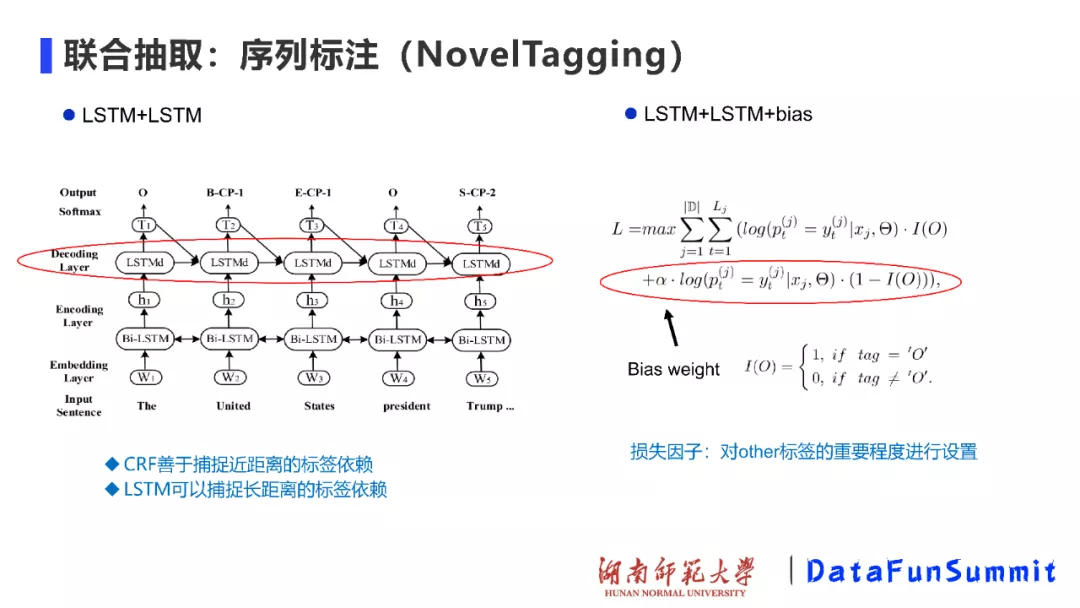
在上述方法中,作者也尝试了一系列经典的序列标注框架,如LSTM+CRF,其中CRF善于捕捉近距离的标签依赖,而LSTM可以捕捉长距离的标签依赖。在此基础上,由于LSTM可以堆叠之前所有时刻的隐状态,所以我们在Encoding-Decoding框架的Decoding层同样采用LSTM结构,如上图(左);再者,考虑到other标签也占据较大的比例,所以作者加入损失因子(即Bias weight)以对other标签的重要程度进行设置。
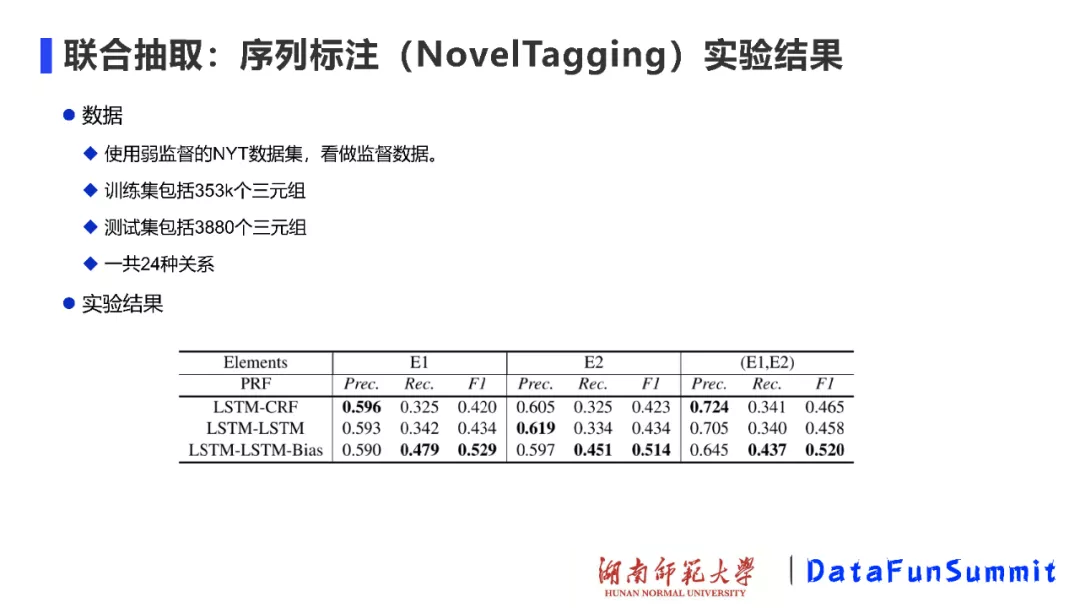
在实验中,作者选择NYT数据集,并将其看作是监督数据(即已标注的数据),通过在24种关系上进行尝试,实验结果表明:该方法的F1值并不是特别高,但是验证了该方法在处理关系抽取问题上的可行性,同时也为基于该方法的改进模型留下了空间。
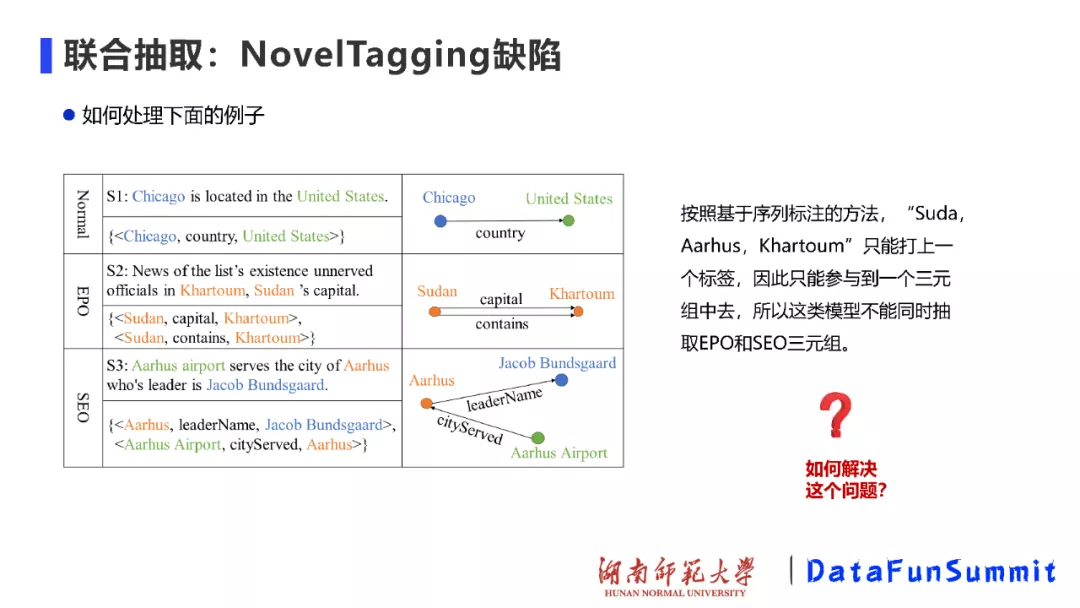
在做实体关系抽取任务时,我们可以将关系三元组划分为Normal、EPO和SEO三种类型(也被称为关系重叠三元组)。EPO(Entity pair overlap)指的是两个实体之间存在不止一种关系类型;SEO(Single entity overlap)指的是一个实体同时参与了两个关系三元组。NovelTagging模型能够较好地处理Normal三元组,然而却无法有效适应EPO和SEO的三元组情况。这是因为基于序列标注的方法只能为每个文本单词打上一个标签(即N输入N输出),所以这类模型不能同时处理EPO和SEO三元组。
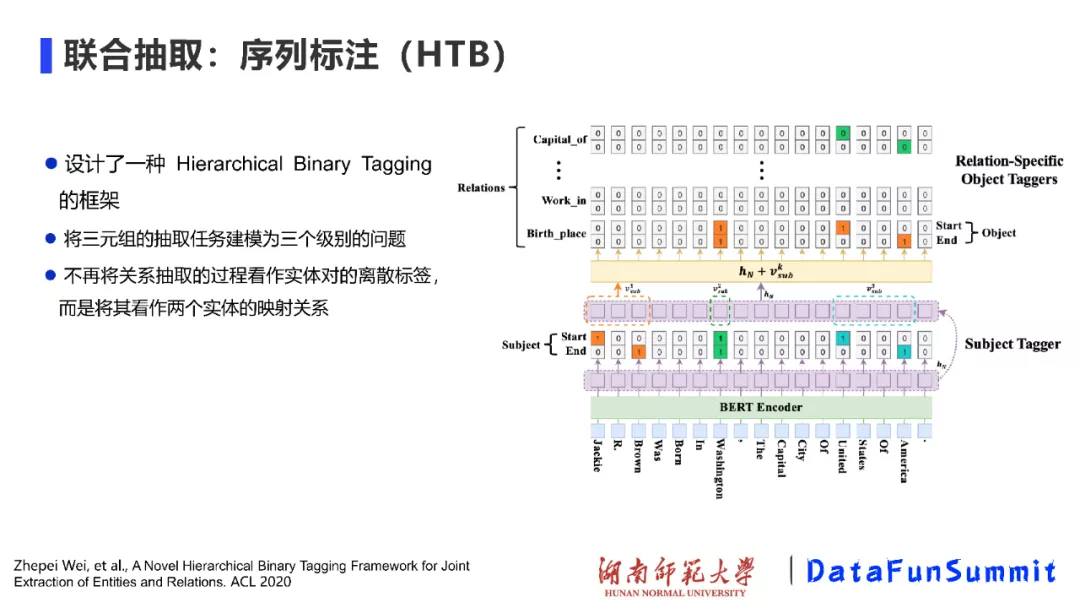
基于NovelTagging模型,Wei等人设计了一种名为Hierarchical Binary Tagging的模型,将关系三元组的抽取任务建模为三个级别的问题,从而能够更好解决三元组重叠问题。该方法不再将关系抽取的过程看作是对实体对离散标签的预测过程,而是将其看作是两个实体的映射过程。
2. 基于表填充的方法
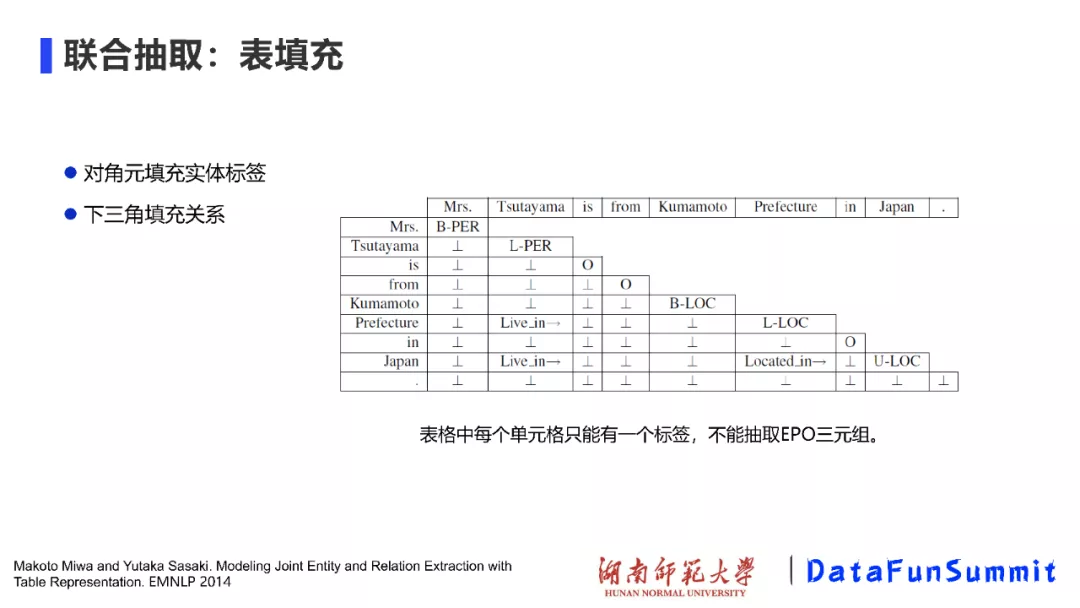
第二类实体关系联合抽取的方法是基于表填充的方法,该类方法最早于2014年提出(请见EMNLP’2014上的《Modeling Joint Entity and Relation Extraction with Table Representation》)。在上图中,对角线元素用于填充实体标签(即通过命名实体识别后的结果),下三角元素用于填充关系(可被视为一个softmax的分类)。我们发现该方法存在一个明显的问题,即表格中每个单元格只能有一个标签,不能抽取EPO三元组。
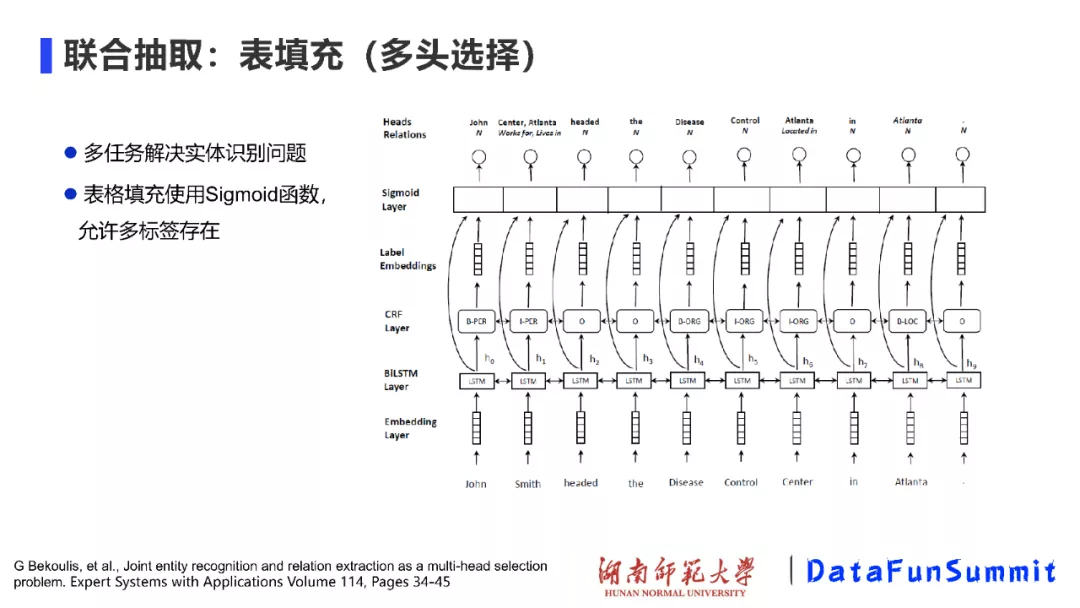
基于表填充工作的一项较好的改进为多头选择工作(请见《Joint recognition and relation extraction as a multi-head selection problem》)。如上图所示,这个模型的框架看上去好像和表格填充没有太大的关系,实际上,这是一种多任务的框架。具体而言,该模型首先在BiLSTM的基础上使用CRF进行序列标注,找到实体。然后,将句子中的词进行排列组合;最后结合LSTM学习到的特征,标签的特征,将它们送到sigmoid分类器中,进而判断实体之间的关系。之所以将这项工作归结为表填充的类别,是因为该模型在进行两两词的组合过程中,就像表格中将一个词作为横纵坐标上的索引,进而填充该索引位置中的类别标签这一情形一样。值得一提的,为了使该模型能够支持上述提到的EPO和SEO情况,在进行关系分类(即表格填充)时,使用的是Sigmoid函数,允许两个词之间的多关系标签存在,因此可以解决关系重叠的问题。
3. 序列到序列的方法
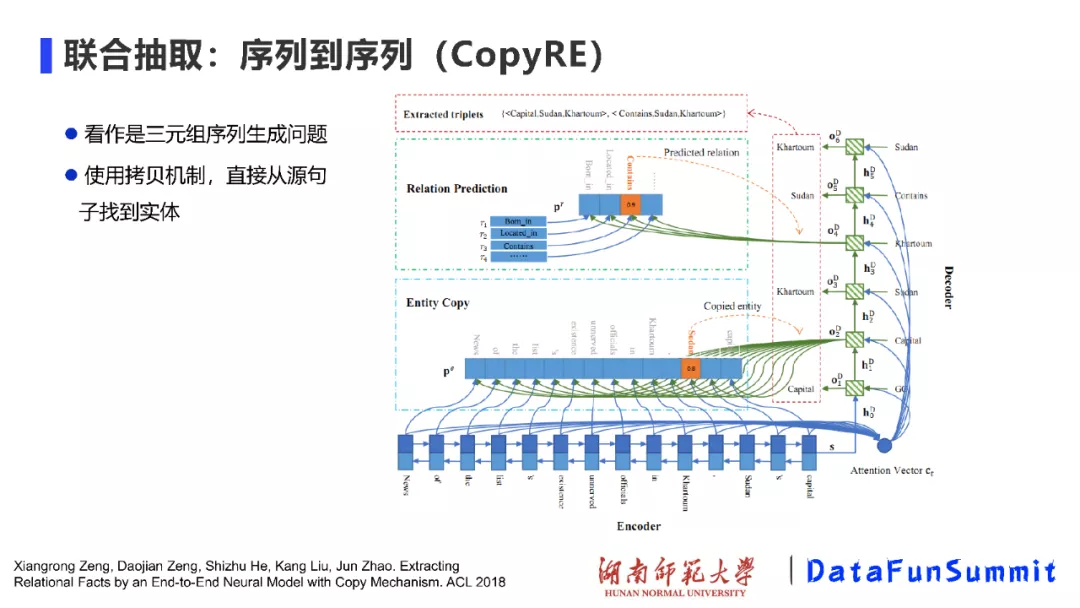
然后介绍我们的工作CopyRE,在该工作中,我们将关系三元组的抽取问题看成是序列到序列的生成问题,即根据输入的句子,借助于机器翻译的想法,将三元组看成是一个翻译的序列。在使用Encoder-Decoder框架时,在输出结果中可能会有部分实体不在输入的句子中,这是因为我们是立足于整个语料库来构建的词表,并将其作为Decoder的预测对象。因此,我们借助于拷贝机制,直接从源句中找到实体对象。与NovelTagging模型相比,我们的模型取得了性能的提升。
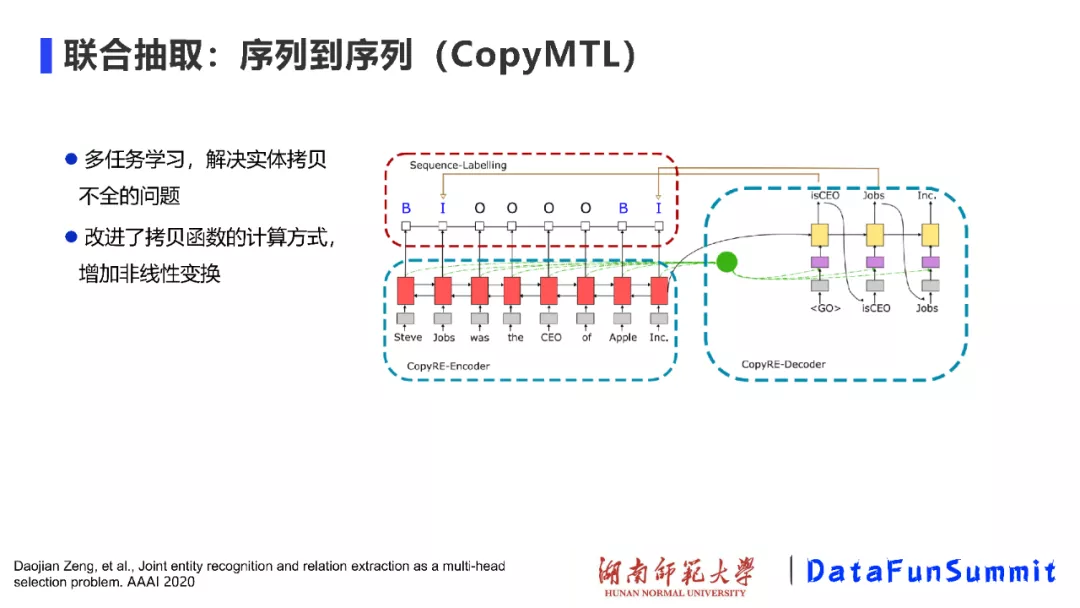
在CopyRE模型中,我们发现在进行拷贝时,主要是在控制实体的最后一个词(token),当头实体和尾实体是由多个token构成时,得到的关系三元组结果是不完整的。为了解决上述问题,我们提出了CopyMTL模型,该模型通过序列标注方法(Sequence-Labelling)来识别由多个词构成的实体,并增加非线性变换,改进了拷贝函数的计算方式,进而解决了实体拷贝不全的问题。
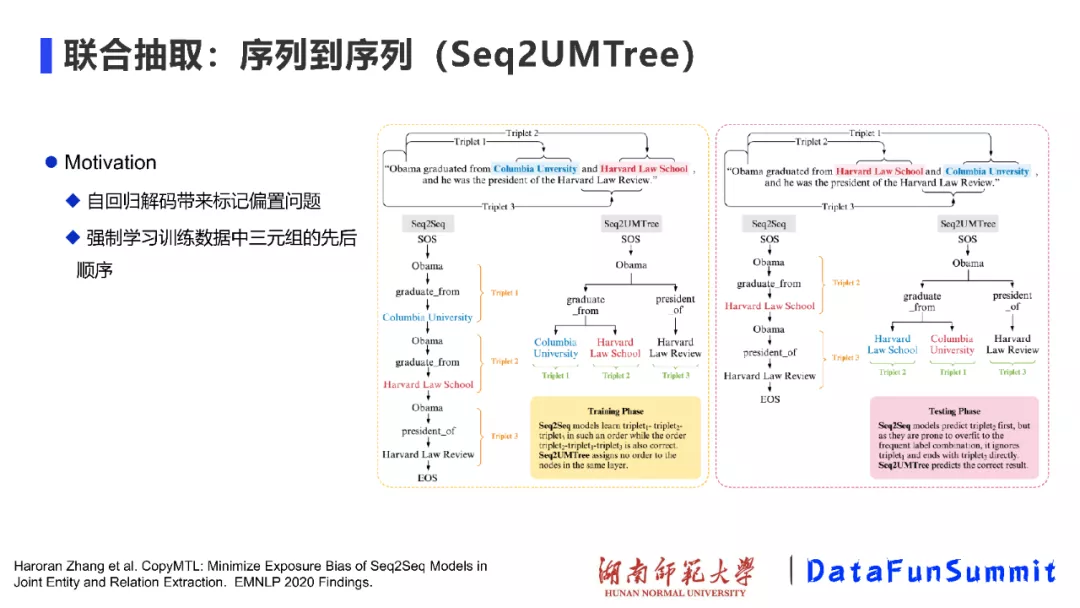
上述也是我们自己的工作,该工作的出发点在于:(1)在序列到序列的标注方法(Seq2seq)中,一个固有的问题是:由自回归解码而导致的标记偏置问题,即在解码第一实体时,依赖于start标记;解码第二个实体时,依赖于第一个实体是什么,以此类推。如果解码过程中的某一步出现了错误,就会导致后续的解码过程不准确;因为在训练时,我们有正确的标签(ground truth),而测试时就没有了正确标签的指导,生成的标签不可避免的会出现一定的错误。因此,标记偏置是一类比较严重的问题;(2)模型强制学习训练数据中三元组的先后顺序。如上图,例如,当模型在抽取得到“graduate_from”关系后,发现其与另外一种关系共现,进而就会再抽取这种关系,而将“graduate_from”关系遗忘。
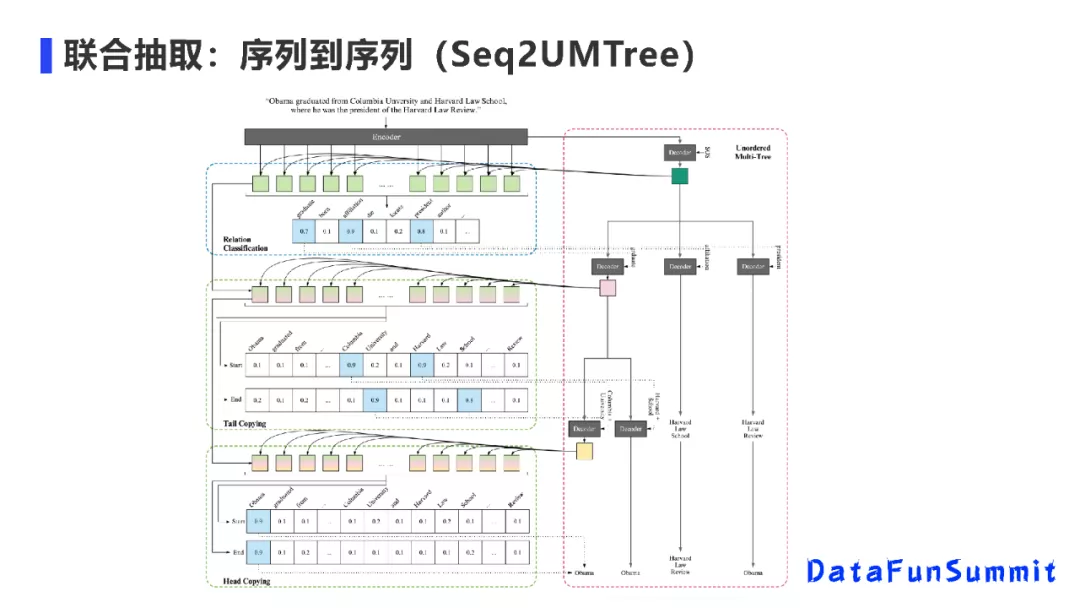
为解决上述两方面的问题:我们提出了Seq2UMTree模型。该模型的逻辑框架如上图所示,其建模动机在于:(1)我们考虑是否能通过缩短解码长度来解决标记偏置问题;(2)我们在解码时,不考虑三元组之间的关系,而是采用树状结构的解码方式。在树状结构的第一层中,我们先预测有哪几种类型的关系;在第二层中,找到头实体开始(start)与结束(end)的位置;在第三层中,再找到尾实体开始(start)与结束(end)的位置。该方法取得了比较好的性能效果。在这个工作中,无论句子中有多少个三元组,我们的解码器最多只有三层(即最多可为3个时间步长(time step)进行解码),这样可以避免:如果解码的time step越多,标记偏置的问题可能会越严重。
03 文档级关系抽取

下面给大家介绍本报告中第二个系列的工作,即文档级关系抽取。上图为DocRED数据集中的一个例子。

文档级关系抽取的关键在于:(1)如何有效的建模实体的多粒度信息,其主要包括2点:(a)如上图中,同一个实体可能在多个句子中出现(即实体在多个句子中的提及);(b)在文本写作中,自然出现的实体指代问题;(2)如何建模文档内的复杂语义信息,其主要涉及多个方面的推理,如逻辑推理、指代推理和常识知识推理等。

早期的文档级关系抽取主要是基于句子级别的抽取,再进行聚合操作。这里,我主要介绍基于图神经网络来完成上述任务的若干工作,第一个工作发表在ACL 2019上(请见《Inter-sentence Relation Extraction with Document-level Graph Convolutional Neural Network》),作者提出的模型被称为GCNN,主要的建模过程包括:
① 使用图神经网络来建模文档:在构建文档时,将输入文档中的每个词作为图中的一个节点,通过不同类型的边对整个文档的结构进行表示。如上图所示,作者用句法依赖标签建立句子中单词之间的远距离依赖;用指代消解工具将具有指代关系的词进行连接;将句子中相邻的两个词也连接起来;将句子中当前词的前后节点连接起来;最后将词本身进行连接。连接完成后,便构建出了一个图结构。
② 在下一步中,基于构建好的文档图,使用GCNN来学习节点之间的信息交互/传递,计算得到每个节点的表示。这样,不同句子中的不同提及都会得到表示。
③ 最后,通过多示例学习的方式聚合目标实体的所有提及并进行关系分类。
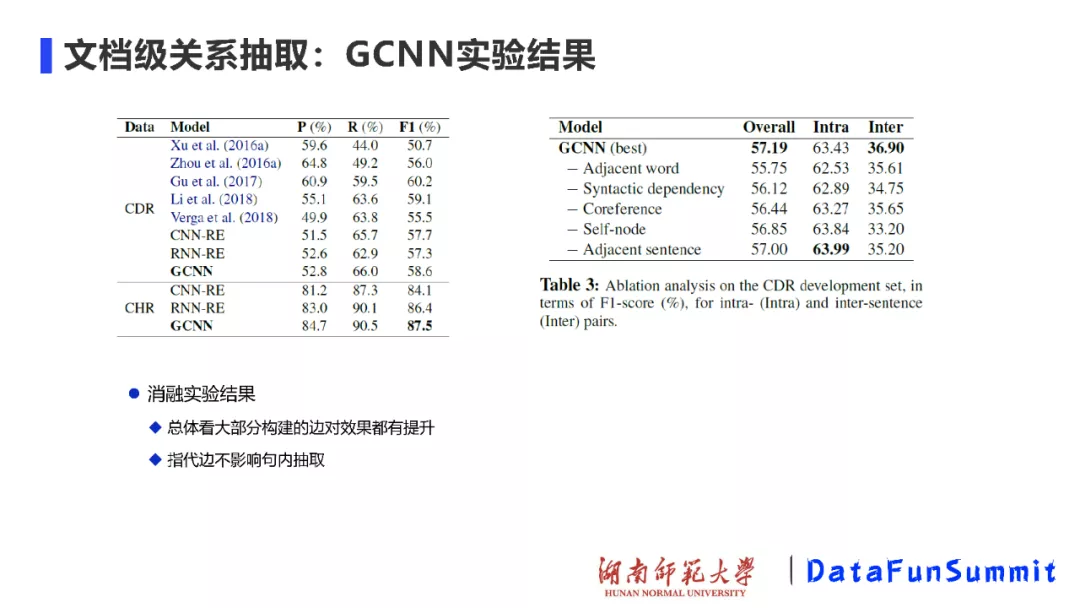
实验在CDR和CHR数据集上完成,并取得了较好的效果。特别要指出的是消融实验的结果,如上表所示。实验结果表明:大部分构建的边对模型效果能起到提升的作用,而指代的边并不影响句子内抽取,对于跨句子间的抽取确能起到重要的作用。
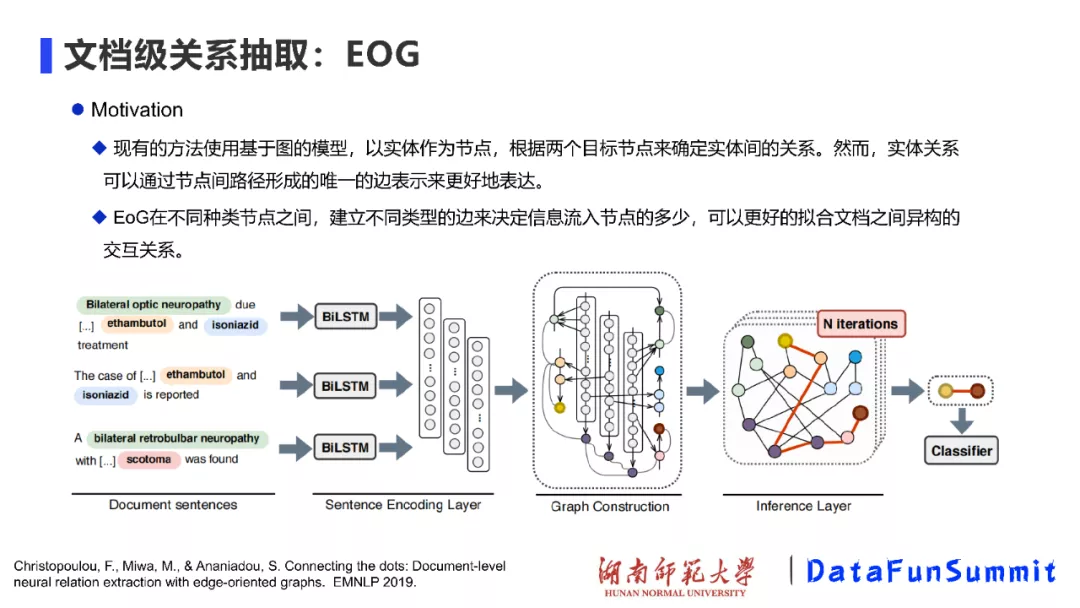
第二个工作也是同一批作者完成的,所提出的模型叫做EOG(请见EMNLP’2019《Connecting the dots: Document-level neural relation extraction with edge-oriented graphs》)。现有的方法主要使用基于图的模型,以实体作为节点,根据两个目标节点来确定实体间的关系。然而,关系是两个节点之间的核心,实体关系可以通过节点间路径形成的唯一的边表示来更好地表达。EoG通过在不同类型的节点之间建立不同类型的边来决定信息流入节点的多少,如此可以更好地拟合文档之间异构的交互关系。
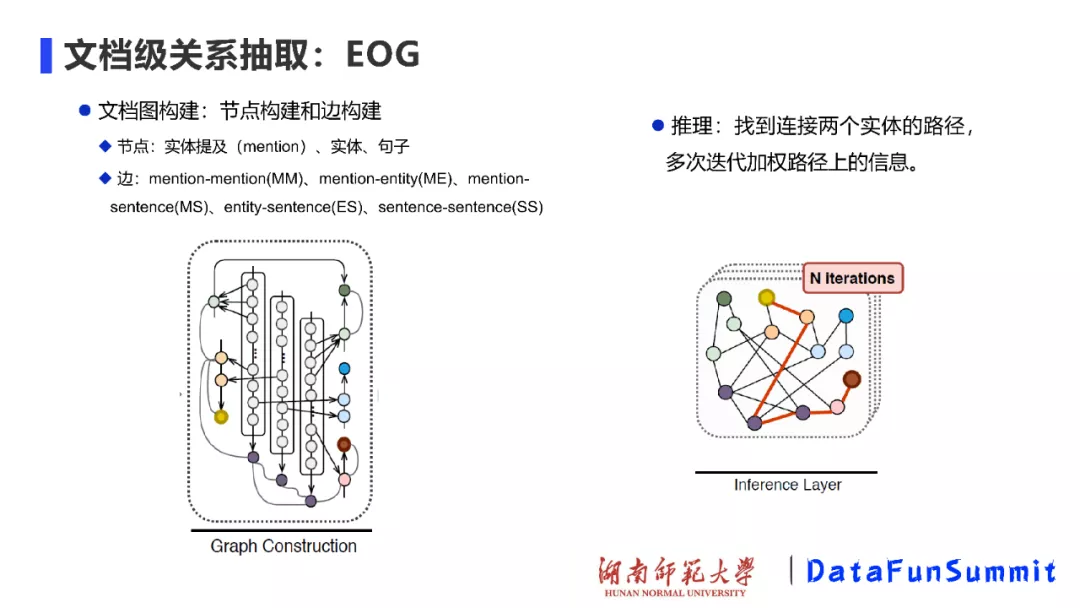
在EOG中,作者主要采用启发式的方法来构建图结构,图中的节点有实体提及、实体和句子,边主要包括:提及到提及(mention-mention, MM)、提及到实体(mention-entity, ME)、提及到句子(mention-sentence,MS)、实体到句子(entity-sentence,ES)和句子到句子(sentence-sentence,SS)之间的关系。构建好图之后,下一步就是推理处理。与使用GCN来进行推理不同,这里主要是训练连接两个实体之间的路径,多次迭代加权该路径上的信息,如上图(右)所示,从而将路径上的信息进行传递,起到推理的效果。
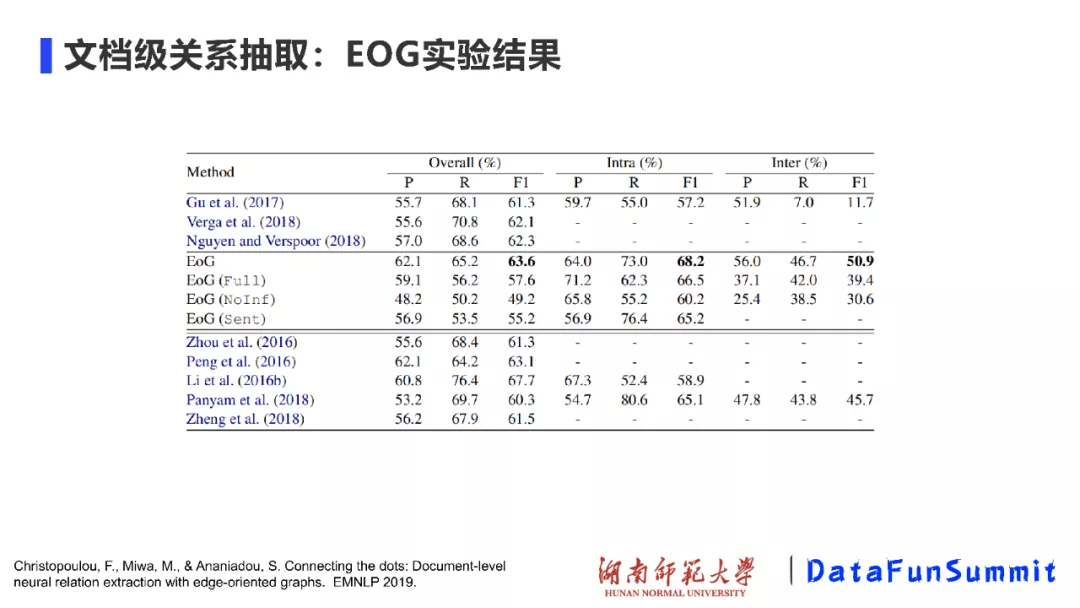
从实验效果上来看,与对比方法相比,EoG模型取得了最好的效果。值得一提的是,EoG(full)表示的是一种全连接的图,EoG(NoInf)表示不采用在图中游走的策略,EoG(Sent)表示以句子级别来构建的图。实验结果表明,在构建文档级别的图结构时,跨句推理非常关键。另外,图的结构也非常重要,构建全连接图的方法与使用启发式的规则、有目的地构建图的方法(即EoG方法)的差距也很大。
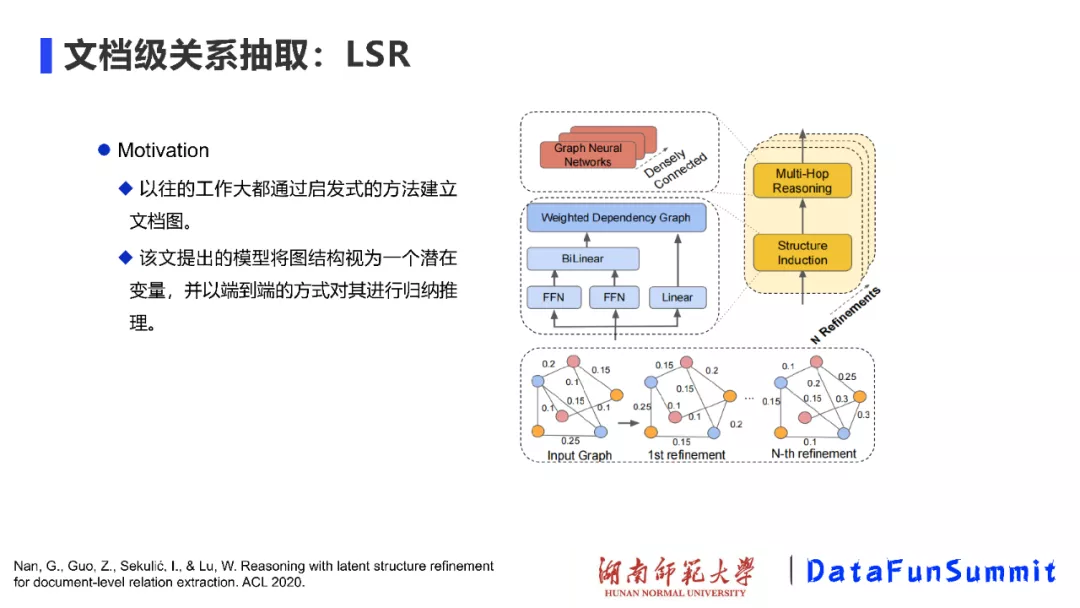
基于上述工作,我们发现图的结构非常重要。这里介绍ACL 2020年的一项工作,即LSR模型(请见《Reasoning with latent structure refinement for document-level relation extraction》),这个工作的动机主要是:图的结构是否也可以从大量文本中进行学习?作者据此提出:将图结构视为一个潜在的变量,并且以端到端的方式对其进行归纳推理。即在初始建图时,可以采用随机初始化或其它方式来完成;后续每一步迭代都将该图进行修正,进而得到最终的结果。
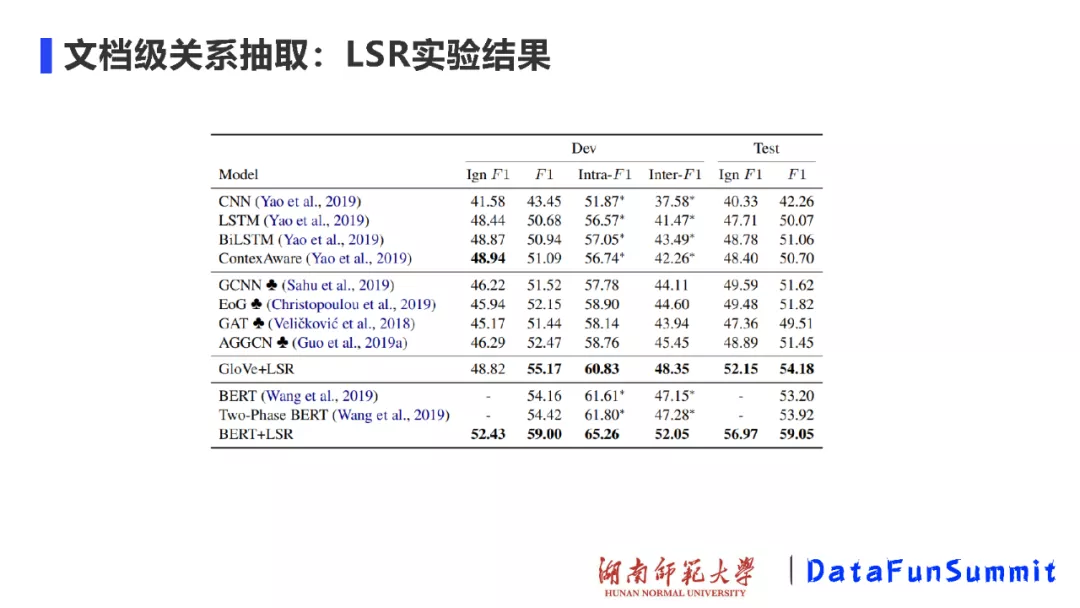
从实验效果来看,通过与GCNN、GAT、AGGCN等方法进行对比,在LSR模型中,通过自动学习图结构的方式也取得了非常好的效果。
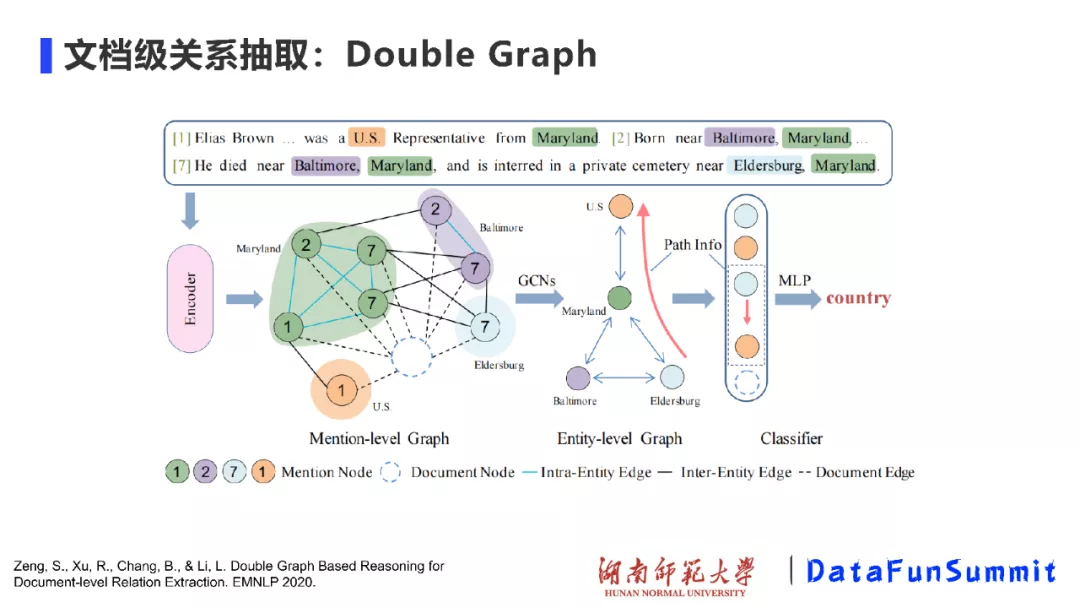
我认为,在文档级关系抽取中一项有意思的工作来源于北京大学(请见EMNLP’ 2020《Double Graph Based Reasoning for Document-level Relation Extraction》),被称为Double Graph。我们一直在讲,文档级关系抽取中最重要的包括:如何对文档进行建模以及如何进行关系推理。在Double Graph中,作者将以上两个部分分隔开,第一个部分是在提及级别的图(mention-level graph)上进行GCN或随机游走,进而完成图中的信息传递与推
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%A4%8D%E6%9D%82%E8%AF%AD%E5%A2%83%E4%B8%8B%E7%9A%84%E5%AE%9E%E4%BD%93%E5%85%B3%E7%B3%BB%E6%8A%BD%E5%8F%96/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


