如何破解组合使用遇到的难题

一.背景介绍
HBase与ElasticSearch是现代应用在处理海量数据的技术架构会经常被使用的两款产品,其中HBase是一个分布式KV系统,具有灵活Schema、水平扩展、低成本、高并发的优势,但在复杂查询、分析能力方面相对比较弱,特别适合海量半结构化、结构化数据的低成本存储和在线高并发查询。而ElasticSearch是一个分布式搜索引擎,具有灵活Schema、水平扩展、检索快的优势,但在成本、查询并发、一致性方面相对不足,特别适合海量半结构化、结构化数据的复杂查询和全文检索。
HBase与ElasticSearch两者有类似的灵活数据结构和分布式扩展性,又有各自鲜明的特点,一个擅长存,一个擅长取,为了取长补短,所以业界会经常将两者结合使用,把Elasticsearch作为HBase中部分字段的索引存储,从而同时实现低成本存储+高并发吞吐+高效检索的效果,典型场景如日志、监控、账单、用户画像等。
二.HBase与ES的组合使用
当应用决定组合使用HBase+ES的时候,核心要解决数据写入、数据查询这两个问题,即数据如何准确写入到两个系统,数据又如何从两个系统查询合并,目前常见的方案有三种:
1)应用双写双读:应用需要同时与HBase、ElasticSearch独立交互,其优点是不需要引入额外依赖,应用可以根据自身需求,定制或简化写入分发和查询合并的逻辑,但缺点也比较多,包括开发成本高、维护复杂、写入Latency增大、可用性下降、一致性解决困难等。
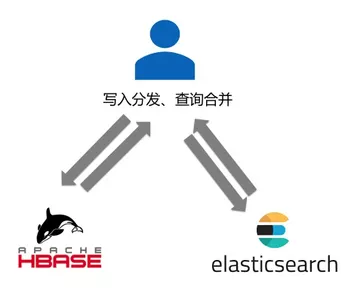
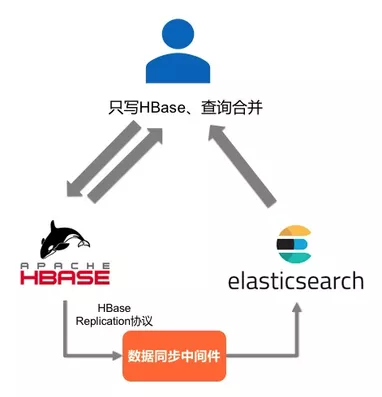
2)数据自动复制,应用双读:应用在写入链路只与HBase交互,在查询链路仍与两个系统交互,其优点是写入过程对应用保持透明,较容易保证最终一致性,ES系统异常后也不会影响写入,但缺点是需要额外开发维护一套数据同步服务,应用查询数据的复杂性仍然较高
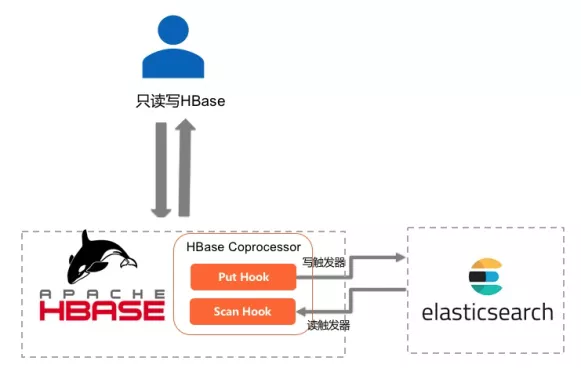
3)利用触发器,应用只读写HBase:应用在读写链路只与HBase交互,利用HBase Coprocessor功能,在HBase表上挂载读写触发器,其中写触发器负责数据写入HBase的同时自动往ElasticSearch写入,读触发器负责解析Scan语句中的查询表达,自动根据存储在ElasticSearch的索引字段进行加速,并与HBase中查询到的整行数据进行合并后,返回给客户端。所以,总的来说,这套方案的优点是应用的读写逻辑比较简单,只需要和HBase交互,但其缺点是其开发非常复杂,需要对HBase及其Coprocessor功能有深入理解,开发足够健壮的读写触发器,并将复杂多条件查询和数据检索的需求嵌入到HBase的查询框架中。同时,一致性、可用性、写入Latency这几个问题也依然存在。
通过上述三个方案的介绍,我们可以发现HBase+Elasticsearch的组合使用过程中会碰到以下几个痛点:
- 开发维护成本巨大,需要开发和维护数据实时同步、数据查询合并、索引字段增删管理、历史数据索引构建等多个能力,这依赖于开发者对HBase和ES系统的深入掌握,否则很容易造成数据错误。
- 数据一致性弱,由于数据写入ES后无法立即可见,并且HBase到ES之间的异步数据复制,所以会造成应用侧的数据不一致性,导致出现数据从HBase可以查到,但从ES查不到的现象。
- 部署成本高昂,HBase与Elasticsearch都是分布式架构,但前者使用存储计算分离架构,后者使用存储计算耦合架构,使得两个系统间的资源无法共享复用,碎片化浪费加大。
- 可用性和吞吐下降,由于HBase的并发吞吐能力远大于Elasticsearch,对于数据串行写HBase、Elasticsearch两个系统的方案,会导致写入延迟上升,吞吐下降到ES水平,并且可用性也随之下降。
- 部分功能失效或衰退,数据生命管理周期(TTL)是一个HBase与ES都具备的常用功能,但两者对其执行有一定的差异化,会导致部分数据在一个系统中已经过期淘汰,但在另一个系统还保留着的间歇性现象。多版本是HBase中的常用功能,可以还原乱序写入数据的顺序性,但Elasticsearch并不支持,所以两者组合后就无法继续使用该功能,否则会出现不可预测的奇怪现象。
- 非Java开发者使用困难,两个系统的服务端都是使用Java开发,上述方案二和方案三中的数据同步组件和触发器,都需要Java开发,对非Java开发者并不友好。
三.Lindorm Searchindex介绍
除了HBase+Elasticsearch的组合,Elasticsearch与MySQL、MongoDB、Cassandra等系统的组合也经常被用在各个业务场景中,这种数据库+搜索引擎的多套系统组合方案普遍具有类似的开发维护复杂、成本高昂、一致性弱等痛点。基于此情况,阿里云数据库Lindorm着力打造了企业级特性Searchindex,帮助用户更加简单、高效、低成本地应对海量数据的存储检索需求。
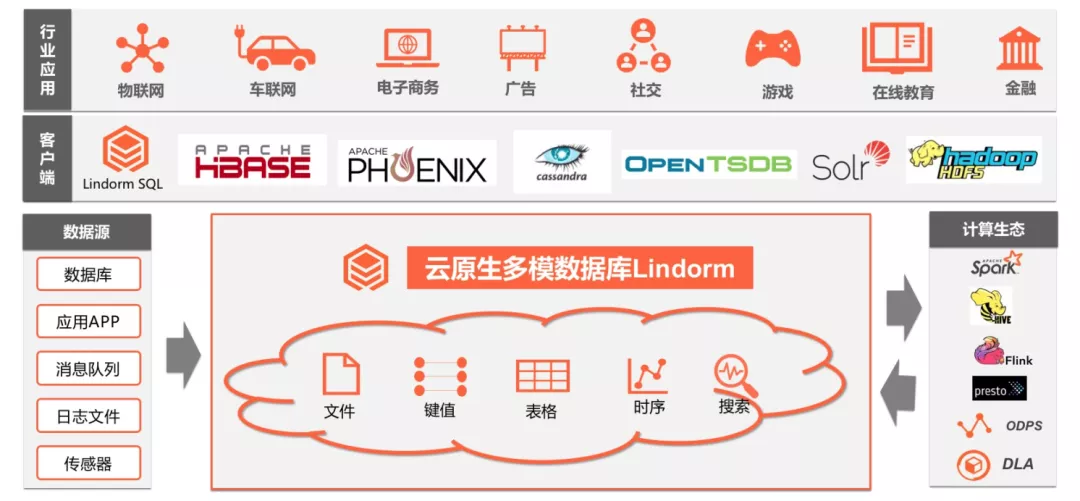
云原生多模数据库 Lindorm 是一个适用于任何规模、多种模型的数据库服务平台,支持海量多样化数据的低成本、实时在线的存储检索分析,提供宽表、时序、搜索、文件等多种数据模型,兼容HBase/Cassandra、OpenTSDB、Solr、SQL、HDFS等多种开源接口,是互联网、IoT、车联网、广告、社交、监控、游戏、风控等场景首选数据库,也是为阿里巴巴核心业务提供支撑的数据库之一。
Searchindex是Lindorm宽表提供的一种新型索引,用户只需简单的SQL语句即可管理索引的增删和构建,数据读写也可以使用统一的SQL访问,在使用体验上与传统数据库的二级索引一致,但其具备强大的全文索引和复杂条件查询能力,这背后是因为相关索引数据由基于Lucene的分布式搜索引擎LindormSearch管理,通过倒排索引、BKD-Tree、Bitmap等数据结构大幅提升海量数据的筛选速度。
让我们看一个具体的使用例子:
- 原始表
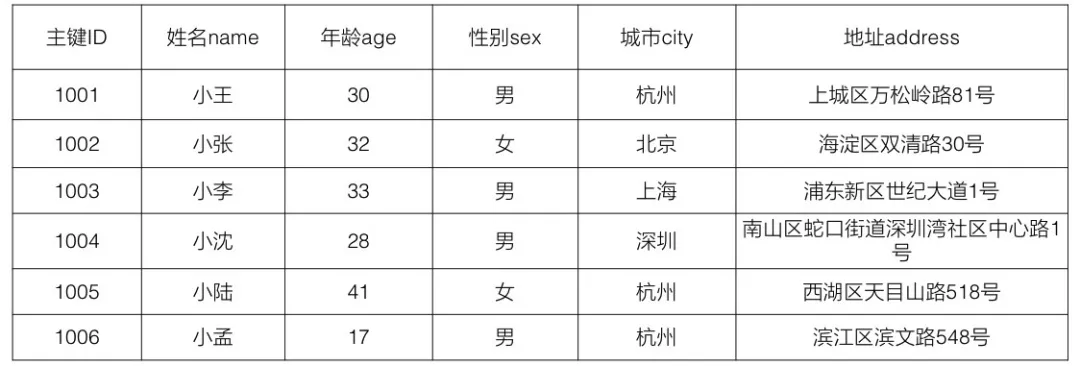
CREATE TABLE myTable (
id bigint,
name text,
age int,
sex text,
city text,
address text,
PRIMARY KEY (id)
) ;
- 需求对 姓名(name)、年龄(age)、性别(sex)、城市(city)、地址(address) 建立全文索引
CREATE SEARCH INDEX myIndex ON myTable WITH COLUMNS (name, age, sex, city, address);注意:索引列的先后顺序不影响,即索引列(c3, c2, c1)与索引列(c1, c2, c3)最终的效果是一致的。
- 查询
1)标准查询语句
模糊查询:SELECT * FROM myTable WHERE name LIKE '小%'
多维查询排序:SELECT * FROM myTable WHERE city='杭州' AND age>=18 ORDER BY age ASC多维查询翻页:SELECT * FROM myTable WHERE name='小刘' AND sex=false OFFSET 100 LIMIT 10 ORDER BY age DESC
2)高级查询语句
多维查询排序:SELECT * FROM myTable WHERE search_query='+city:杭州 +age:[18 TO *] ORDER BY age ASC'
文本检索:SELECT * FROM myTable WHERE search_query='address:西湖区'
从上面的例子可以看到,用户只要了解基本SQL,无需开发,即可使用Lindorm Searchindex。通过该特性,可以完全解决HBase+Elasticsearch组合使用遇到的难题,具体来说,有如下优势:
- 简单易用,作为一个数据库特性,开箱即用,索引增删、索引构建、存储优化等全部通过SQL命令控制,无需额�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%A6%82%E4%BD%95%E7%A0%B4%E8%A7%A3%E7%BB%84%E5%90%88%E4%BD%BF%E7%94%A8%E9%81%87%E5%88%B0%E7%9A%84%E9%9A%BE%E9%A2%98/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


