年月底字节推荐算法面试题道
文末彩蛋:七月在线干货组最新升级的《2021大厂最新AI面试题 [含答案和解析, 更新到前121题]》免费送!
1、分词方法BPE和WordPiece的区别
BPE与Wordpiece都是首先初始化一个小词表,再根据一定准则将不同的子词合并。词表由小变大
BPE与Wordpiece的最大区别在于,如何选择两个子词进行合并:BPE选择频数最高的相邻子词合并,而WordPiece选择能够提升语言模型概率最大的相邻子词加入词表。
2、残差网络有哪些作用?除了解决梯度消失?
解决梯度消失和网络退化问题。
残差网络为什么能解决梯度消失?
残差模块能让训练变得更加简单,如果输入值和输出值的差值过小,那么可能梯度会过小,导致出现梯度小时的情况,残差网络的好处在于当残差为0时,改成神经元只是对前层进行一次线性堆叠,使得网络梯度不容易消失,性能不会下降。
什么是网络退化?
随着网络层数的增加,网络会发生退化现象:随着网络层数的增加训练集loss逐渐下降,然后趋于饱和,如果再增加网络深度的话,训练集loss反而会增大,注意这并不是过拟合,因为在过拟合中训练loss是一直减小的。
残差网络为什么能解决网络退化?
在前向传播时,输入信号可以从任意低层直接传播到高层。由于包含了一个天然的恒等映射,一定程度上可以解决网络退化问题。
3、交叉熵损失,二分类交叉熵损失和极大似然什么关系?

不难看出,这其实就是对伯努利分布求极大似然中的对数似然函数(log-likelihood)。
也就是说,在伯努利分布下,极大似然估计与最小化交叉熵损失其实是同一回事。
可参考:
https://zhuanlan.zhihu.com/p/51099880
4、二叉树最大路径和(路径上的所有节点的价值和最大)
参考答案
方法一:递归
首先,考虑实现一个简化的函数 maxGain(node),该函数计算二叉树中的一个节点的最大贡献值,具体而言,就是在以该节点为根节点的子树中寻找以该节点为起点的一条路径,使得该路径上的节点值之和最大。
具体而言,该函数的计算如下。
空节点的最大贡献值等于 00。
非空节点的最大贡献值等于节点值与其子节点中的最大贡献值之和(对于叶节点而言,最大贡献值等于节点值)。
例如,考虑如下二叉树。
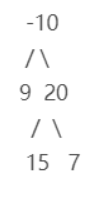
叶节点 99、1515、77 的最大贡献值分别为 99、1515、77。
得到叶节点的最大贡献值之后,再计算非叶节点的最大贡献值。节点 2020 的最大贡献值等于 20+max(15,7)=35,节点 -10 的最大贡献值等于 -10+max(9,35)=25。
上述计算过程是递归的过程,因此,对根节点调用函数 maxGain,即可得到每个节点的最大贡献值。
根据函数 maxGain 得到每个节点的最大贡献值之后,如何得到二叉树的最大路径和?对于二叉树中的一个节点,该节点的最大路径和取决于该节点的值与该节点的左右子节点的最大贡献值,如果子节点的最大贡献值为正,则计入该节点的最大路径和,否则不计入该节点的最大路径和。维护一个全局变量 maxSum 存储最大路径和,在递归过程中更新 maxSum 的值,最后得到的 maxSum 的值即为二叉树中的最大路径和。

5、写题:找数组中第k大的数,复杂度
三种思路:一种是直接使用sorted函数进行排序
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%B9%B4%E6%9C%88%E5%BA%95%E5%AD%97%E8%8A%82%E6%8E%A8%E8%8D%90%E7%AE%97%E6%B3%95%E9%9D%A2%E8%AF%95%E9%A2%98%E9%81%93/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


