度小满金融大数据架构实践

分享嘉宾:赵辉 度小满金融 架构师
编辑整理:蒋雯娟 厦门大学嘉庚学院
出品平台:DataFunTalk
导读: 大数据架构在金融场景下面临着诸多挑战,从架构上而言,业务对数据加工、存储和使用的全链路服务提出了更细致的管控需求;从使用上而言,用户并不想理解大数据架构的具体实现和管控的细节,用户只想以更低的门槛、更快的方式来使用产品;从管理上而言,公司希望能够对数据加工、处理过程中的相关经验做到有效传承。

本文主要针对上述问题分享对应的解决方案,分别是:① 基于百度云产品的大数据架构——MMR,管控需求;② 度小满数据湖管理与分析平台——鸿鹄,降门槛;③ 度小满模型训练监控评估体系——易创,经验传承。
01 大数据云化架构——MMR
度小满大数据云化架构是建立在百度云大数据产品基础之上的,百度云标准的大数据产品解决方案与开源的大数据解决方案类似。首先是通过用户提交任务,进入到计算层,承接计算需求。再到存储层,承接数据的存储需求。为了满足更细致的管控需求,我们对架构进行了一次延展。
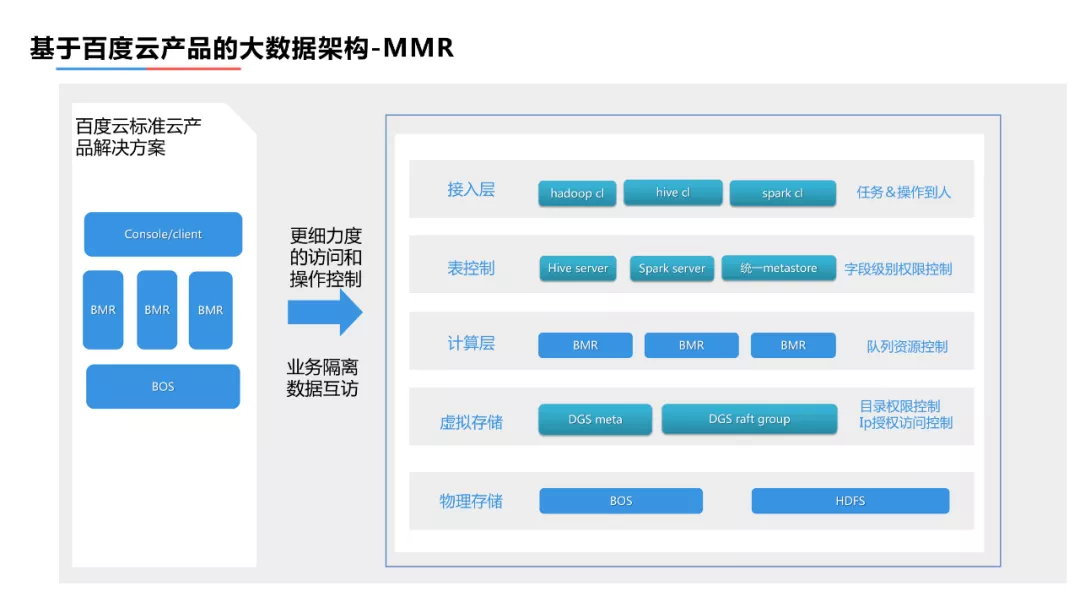
我们将架构分为以下几个部分:接入层、表控层、计算层、虚拟存储层、物理存储层。
1. 用户层
在用户层主要实现的是对从用户操作到人的管控。具体实现方式主要是:我们会在用户的大数据的入口进行改造,打通度小满的员工管理系统,大数据服务的用户在登陆作业机时会标注自己的身份,在提交操作和命令时,可以从架构上识别出个人的身份,这样一来,在提交命令或者是操作时是带着个人身份操作,所有任务和用户操作都可以定位到具体的责任人。
2. 表控制管理层
针对表控制管理层,满足了结构化数据部分共享的业务需求,即大数据存储数据是以Hive表为基础,Hive表里可能有一百、几百或上千个字段,不同的字段有不同的密级要求。例如,在100个字段里,只有20个字段是希望共享的,其余80个是不希望共享的,这种情况就需要对表进行字段级的权限控制。基于此,我们将在外层建立有针对性的权限控制中心,用户可以在平台上对表进行字段级别的密级标注以及共享和申请使用的权限设置。通过这种方式,用户提交任务到Hive Server或Spark Server时,服务层会有一段逻辑来校验用户提交的任务或者操作需要字段是否同时拥有该字段的权限,以此来决定是否放行实现字段级别的权限控制。
3. 计算层
在计算层主要是对资源的控制,主要是依赖百度云基础架构的能力。在计算层和存储层,度小满架设了虚拟管理层,虚拟管理层主要解决了非结构化数据的共享需求和隔离需求。一般而言,每个业务的细分方向具有私密性,但每个业务的数据加工团队,都有上游和下游,都会面临数据的部分分享和使用的需求。针对这类情况,我们对目录层面进行权限管控。在目录权限控制的基础上,同时约定使用方访问的IP、IP段可以做到更细微的管控。在保证业务隔离的基础上实现一定程度的数据共享,从而保障所有数据的操作、使用都是可控的,所有的过程都是可审计的。
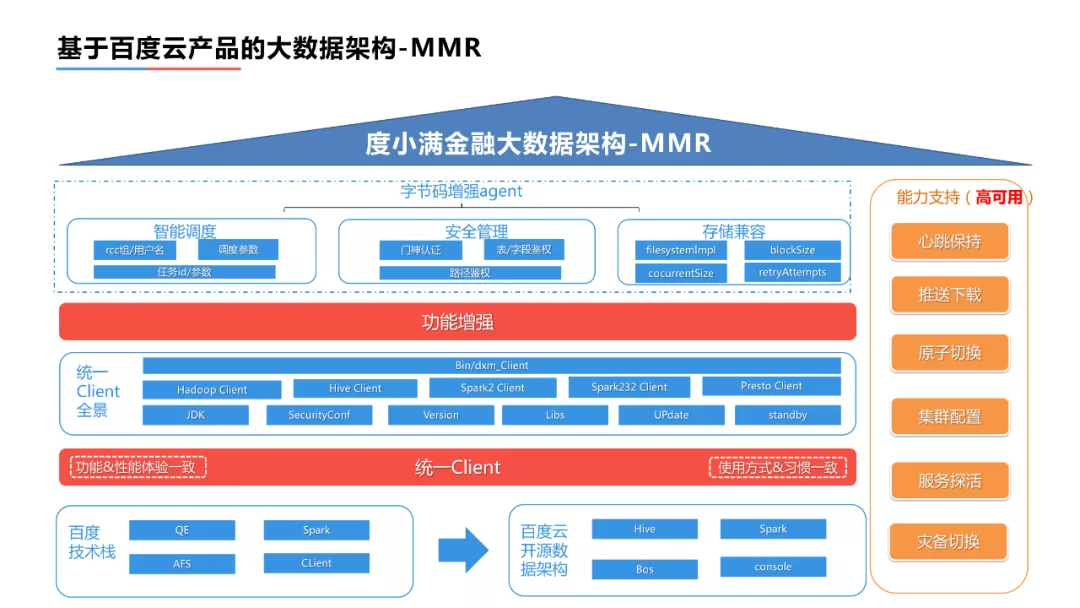
在此基础上,我们还面临着一个更大的问题——业务是从百度架构过度到当前的百度云开源的数据架构,类似于从闭源的大数据架构到开源的大数据架构。虽然计算逻辑或是计算方式上大致是相同的,但是在很多细节上比如入口设计、使用习惯和功能体验是不一致的。为了解决差异:
- 首先,要统一用户的使用习惯,把用户所有访问大数据服务使用的工具组装成统一的Client,在统一client对差异进行自动的抹平。用户在由百度架构到百度云架构到迁移的过程的工作主要是修改配置、验证结果,不会涉及到代码层面的修改。
- 其次,虚拟存储层的建设、实现存储层的兼容,以文件系统的使用方式和使用习惯去访问对象存储,在用户层面看来功能和体验是一致的。
智能调度&高可用,在百度资源池和资源的可用范围更大,在云上是用户申请多少就使用多少。因此,流量的高峰的拥堵情况比较严重,所以首先应对任务的参数进行调整,避免资源浪费,同时对所有任务实行窗口调度、动态调整任务的执行时间,以此来缓解整个流量高峰的拥堵情况。在调度、安全和兼容的基础上,也做了一些高可用层面的支持,主要是对所有用户使用的agent进行心跳的保持。通过这种方式,可以了解到用户的机器环境、提交任务使用的作业环境、集群的种类。当用户反馈一个任务失败时,可以非常快速的去定位和发现问题。
02 数据湖管理与分析平台——鸿鹄平台
1. 敏捷、智能的全域数据管理
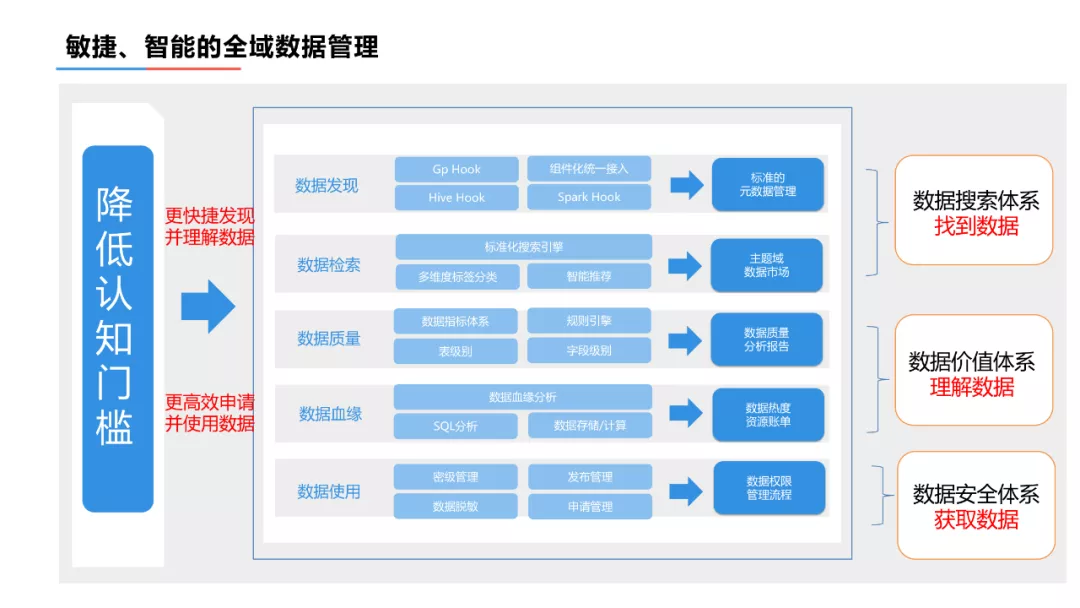
数据湖管理与分析平台目标用户是策略分析人员,策略分析人员对整个平台架构的需求简单明确:简单易用。
第一步降低用户的认知门槛,即任何人都可以非常快速的发现和理解数据,以及更高效的申请和使用数据。具体方案如下:
- 统一的元数据管理,归集不同存储系统的元数据信息,进行统一的平台展现,解决元数据孤岛,实现了元数据在用户感知层的统一。
- 主题域建设以及智能推荐,通过主题域的建设,对数据的标签分类,降低用户数据理解的成本。针对数据表膨胀的问题,建设了基于数据热度和数据质量的智能推荐体系,降低用户数据检索难度。
- 数据质量管控,对进入流通的数据进行严格的质量管控,产出数据质量报告,解决用户对数据可用性的疑虑。
- 数据价值分析,通过数据血缘、生产任务链,准确把控数据的价值,提升了用户对数据的。
- 权限管控,脱敏以及加密管理,确保的数据流通过程中的数据安全;发布与申请流程管控,确保了数据按照业务需求分享与使用。
2. 多引擎可视化拖拽式的批&流开发平台
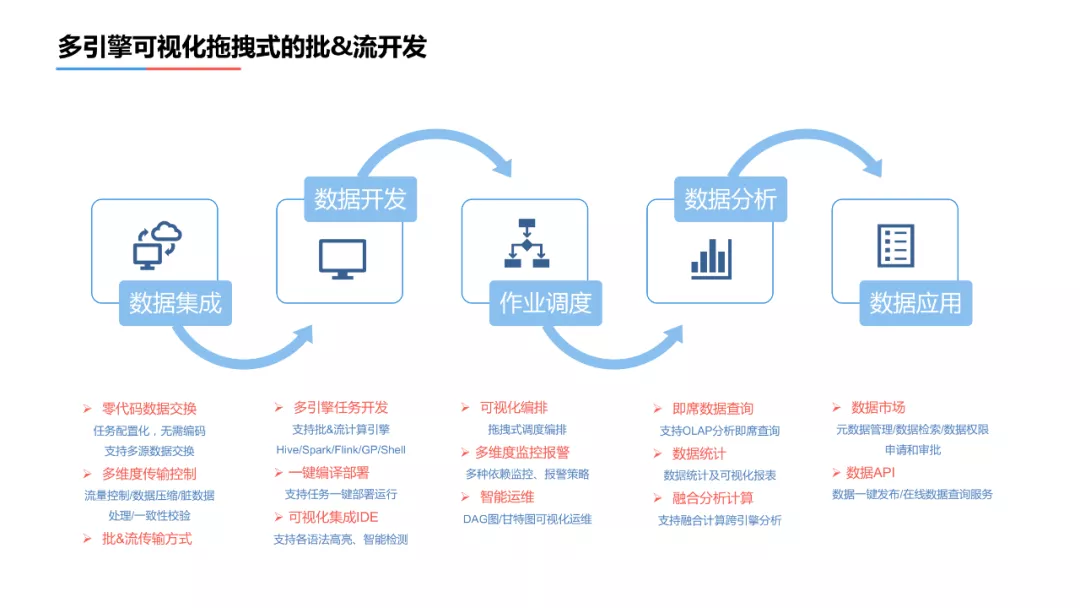
第二步降低用户的使用门槛,建立了多引擎可视化拖拽式的批&流开发平台。具体方案如下:
- 数据的集成,亦被称作数据交换、数据交换中心。我们建立了一个数据交换平台,用户只需要在数据交互平台上进行简单的任务配置,不需要编码就可以实现数据的获取。
- 可视化的集成IDE,支持语法检测、高亮的检测、格式的调整;支持任务的一键部署运行;支持Hive、Spark、Flink、GP、Shell等多种开发模式。
- 拖拽式的调度编排,直观有效的展示了任务之间的依赖关系;多维度的监控分析确保了任务的正确执行。
- 数据分析,平台展现的分析需求支持类似greenplum等OLTP类型的分析引擎。临时分析需求支持presto对Hive表或者gp中的数据进行联合分析。
- 数据API,支持数据完成分析和结果确认以后,一键生效到在线系统。
3. 全数据生命周期一站式的数据分析平台
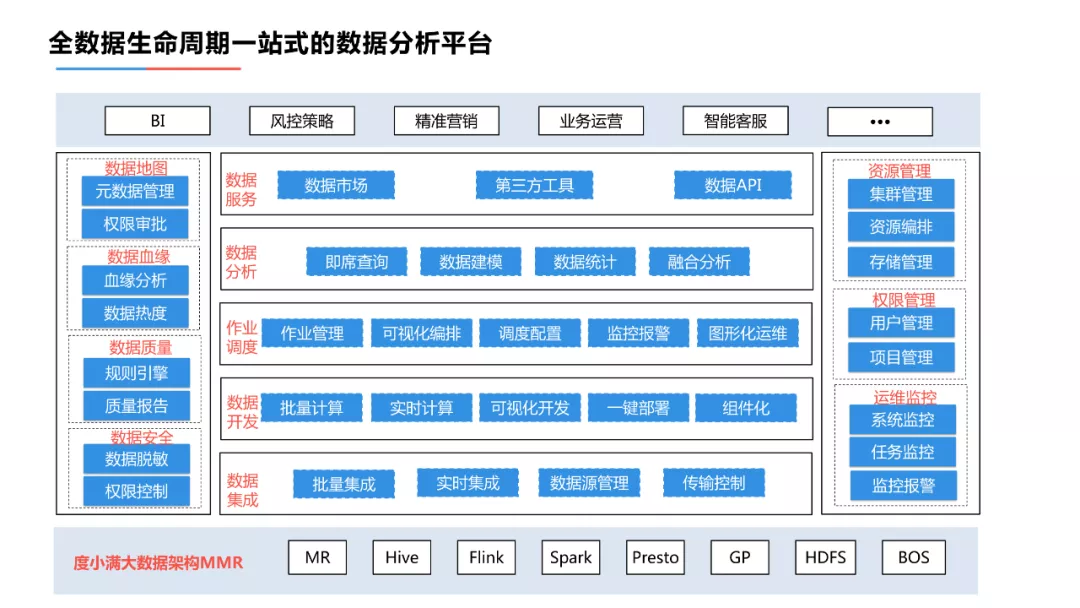
全数据生命�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%BA%A6%E5%B0%8F%E6%BB%A1%E9%87%91%E8%9E%8D%E5%A4%A7%E6%95%B0%E6%8D%AE%E6%9E%B6%E6%9E%84%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


