怎么理解基于机器学习四大支柱划分的学习排序方法

原文出自: 搜索与推荐 Wiki
Learning to rank(LTR,L2R)也叫排序学习,泛指机器学习中任何用户排序的技术,是指一类监督学习(Supervised Learning)排序算法。LTR 被应用在很多领域,比如信息检索(Information Retrieval)、推荐系统(Recommend System)、搜索引擎(Search Engine)。
LTR 框架
一般来讲,根据机器学习的“四大支柱”,LTR 分为三类方法:Pointwise Approach、Pairwise Approach、Listwise Approach。不同的方法通过不同的方式去训练模型,他们定义不同的输入、不同的输出、不同的假设、不同的损失函数。
什么是机器学习的四大支柱?看下图! null
LTR 框架对应的则是排序模型,一个通用的 LTR 框架如下:
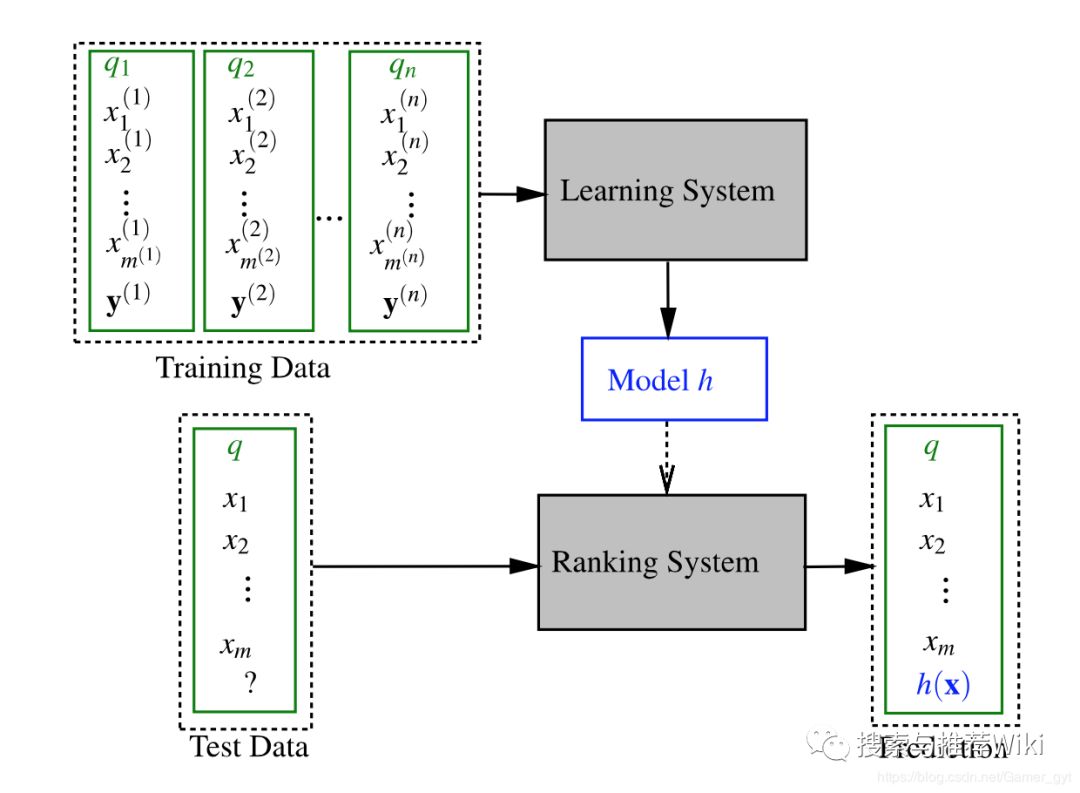
LTR 框架
通常来说,一个训练集由个 query 组成,每一个 query 都会有一系列与之相关的 documents(通常每个 documents 都有向量表示,向量内容可以是有意义的特征,也可以是 embedding 得出的向量),表示与相关的 documents 个数,代表 documents 的正确标签(可能是 0 或者 1,也能是相关度)。上图中对应的流程是:准备训练数据-> 特征提取-> 训练模型-数据预测-> 效果评估
Pointwise Approach
解释
Pointwise 是“逐样本”的训练方法,即仅考虑单个样本的得分与样本的真实得分的关系。
Pointwise 将问题转化为多分类或回归问题。如果归结为多分类问题,对于某个 Query,对文档与此 Query 的相关程度打标签,标签分为有限的类别,这样就将问题转为多分类问题;如果归结为回归问题,对于某个 Query,则对文档与此 Query 的相关程度计算相关度 Score,这样就将问题归结为回归问题。
例如,对于一组样本数据,用户一段时间内在几个商品类别下的浏览,收藏,分享,购买次数,然后 label 为喜好等级或是否喜欢,如下表所示(数据伪造只为了说明问题):
用户类别浏览收藏分享购买喜好等级是否喜欢userA数码产品43842高是userB生活用户24421中否userC办公用品12140低否userD衣服25511中是
如上表所示,用户在每个类别下的行为特征有四个,喜好等级分为:高、中、低三档。然后我们可以采用机器学习中的任意一种多分类方法计算用户对物品类别的喜好等级,当然我们也可以采用二分类的方法计算用户是否喜欢这个类别,这和推荐系统中基于 CTR 来做物品排序和 pointwise 中的二分类思路是一致的。
缺点
-
Pointwise 完全从单文档的分类角度计算,没有考虑文档之间的相对顺序。而且它假设相关度是查询无关的,只要 (query, y_i) 的相关度相同,那么他们就被划分到同一个级别中,属于同一类。比如在 CTR 场景中构建的训练集中,所有正样本之间的相关性,Pointwise 是不会考虑,同样所有的负样本之间的相关性 Pointwise 也是不会考虑的。
-
损失函数中没有捕获预测排序中的位置信息,因此,损失函数可能无意的过多强调那些不重要的结果,即那些排序在后面对用户体验影响小的结果。
Pairwise Approach
解释
相对 Pointwise 而言,Pairwise 更在乎的是文档之间的顺序,他主要将排序问题归结为二元分类问题,这时候相应的机器学习算法就比较多了,比如 Boost、SVM、神经网络等。对于同一 query 的相关文档集中,对任何两个不同 label 的文档,都可以得到一个训练实例 (y_i, y_j),
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%80%8E%E4%B9%88%E7%90%86%E8%A7%A3%E5%9F%BA%E4%BA%8E%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E5%9B%9B%E5%A4%A7%E6%94%AF%E6%9F%B1%E5%88%92%E5%88%86%E7%9A%84%E5%AD%A6%E4%B9%A0%E6%8E%92%E5%BA%8F%E6%96%B9%E6%B3%95/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com



{kind=link}