性能调优总结
使用正确的 transformations操作
虽然开发者达到某一目标,可以通过不同的transformations操作,但是有时候不同的姿势,性能差异非常明显。优化姿势的总体目标是尽可能少的产生 shuffle, 和待被 shuffled data。因为shffule过程存在写盘和节点间网络IO的开销 repartition , join, cogroup, and any of the *By or *ByKey transformations can result in shuffles.
-
避免使用
groupByKeyrdd.groupByKey().mapValues(_.sum)和rdd.reduceByKey(_ + _). 会产生同样的结果,但是前者操作会拿全部数据在集群中进行shuffle,后者,会在本地做一个partition内的combine操作,减少接下来进行shuffle的网络IO -
如果在输入值 和 输出值 类型不同的情况下,要避免使用
reduceByKey例如, 我们要找出每个key所对应的去重后的字符串,意味着返回的value是一个集合, 而原始rdd是字符串,所以一种实现方式是考虑先通过map函数将value转换为集合再进行
reduceByKey
rdd.map(kv => (kv._1, new Set[String]() + kv._2))
.reduceByKey(_ ++ _)
这样做导致了 大量的 Set 对象创建,每个KV都要搞一个Set对象。 最佳方式是使用 aggregateByKey, aggregateByKey 适用与输入和输出类型不同的聚合场景,同时 aggregateByKey 会在map端提前进行聚合进而更加高效。
val zero = new collection.mutable.Set[String]()
rdd.aggregateByKey(zero)(
(set, v) => set += v,
(set1, set2) => set1 ++= set2)
-
避免适用
flatMap-join-groupByWhen two datasets are already grouped by key and you want to join them and keep them grouped, you can just use cogroup. That avoids all the overhead associated with unpacking and repacking the groups.
一篇关于
cogroup的文章: https://blog.csdn.net/stevekangpei/article/details/76020555
一种可以避免shffule的场景
如果多个rdd被相同的partitioner 进行了partition,且每个rdd的partitions数目相同, 两个partition后的rdd结果join的时候不会再次进行shuffle
rdd1 = someRdd.reduceByKey(...)
rdd2 = someOtherRdd.reduceByKey(...)
rdd3 = rdd1.join(rdd2)
rdd1的一个partition的所有key,都会出现在rdd2的某一个partition中
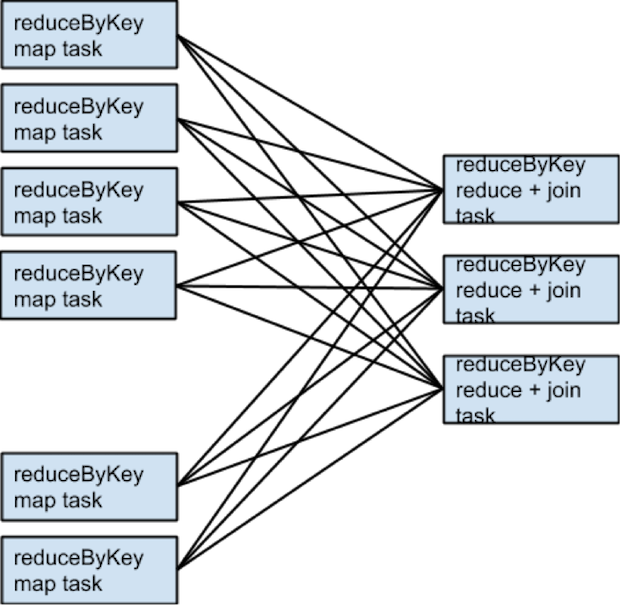
如果rdd1 和 rdd2 使用不同的partitioner, 或者有不同的partition数目,, 在这种情况下, 具有更少partition数目的rdd在join之前会被reshuffled
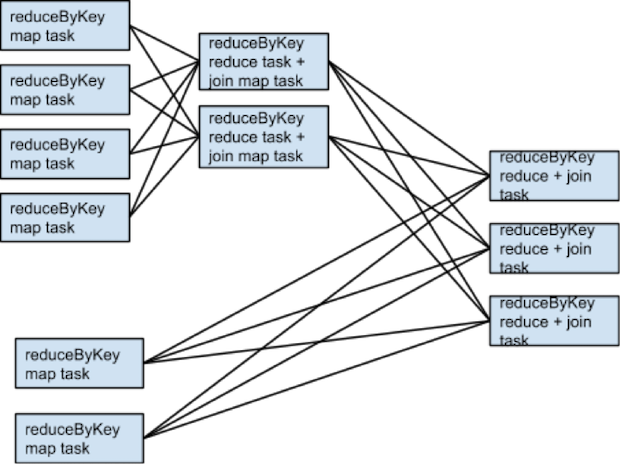
再来看看join时怎么优化shuffle
在写Spark程序时,在我们join操作的性能有问题时, 我们经常会见到这样的错误消息 OOM (java.lang.OutOfMemoryError), 还有很多挺古怪的概念词出现 shuffling, repartition, exchanging, query plans。我们接下来只考虑工作中常见的单个key join的场景
Spark内部join过程
我们知道在关系型数据库中, join操作可以利用各种索引树来提高性能。但是Spark并没有什么主键索引等概念,倒是有个 Optimization Engine 来做一些资源优化。
我们来通过一个常见的的join场景,来看下它的 执行计划:
val join = sql("""
SELECT one.a, one.b as value_b, two.c as value_c
FROM table_one as one JOIN table_two as two ON one.a == two.a
""").as[JoinResult]
join.explain
== Physical Plan ==
*SortMergeJoin [a#5973], [a#5962], Inner
:- *Sort [a#5973 ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(a#5973, 200)
: +- *Project [a#5837 AS a#5973, c#5838 AS value#5974]
: +- *Filter isnotnull(a#5837)
: +- *FileScan csv [a#5837,c#5838] Batched: false, Format: CSV, Location: InMemoryFileIndex[file:/tmp/counta/201706], PartitionFilters: [], PushedFilters: [IsNotNull(a)], ReadSchema: struct<a:string,c:int>
+- *Sort [a#5962 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(a#5962, 200)
+- *Project [a#5854 AS a#5962, b#5855 AS value#5963]
+- *Filter isnotnull(a#5854)
+- *FileScan csv [a#5854,b#5855] Batched: false, Format: CSV, Location: InMemoryFileIndex[file:/tmp/counta/201705], PartitionFilters: [], PushedFilters: [IsNotNull(a)], ReadSchema: struct<a:string,b:int>
Spark首先会尝试去除不参与join的数据,nulls或者无用的列, 再将所有数据集进行排序来避免 n*m 复杂度的join。 这种排序会涉及大量的 网络 IO和磁盘IO。了解了默认的join过程,那么接下来我们可以针对业务不同的场景进行优化
小数据集 VS 小数据集 (单机内存完全cover住)
这种场景应该没人会在意,可能就是一个单机的spark sql join
val oneDF= sql("SELECT * FROM table_one")
val twoDF= sql("SELECT * FROM table_two")
sql("""
SELECT one.a, one.b as value_b, two.c as value_c
FROM table_one as one JOIN table_two as two
ON one.a == two.a
""").as[JoinResult]
//or using a more programmatic notation
oneDF.join(twoDF,oneDF("a") === twoDF("a"))
小数据集 VS [中数据集(整个数据无法放入内存,不过key列所有值可以) | 大数据集(整个数据无法放入内存,不过key列所有值可以) ]
val oneDS= sql("select a, b as value from table_one").as[Entry]
val twoDS= sql("select a, c as value from table_two").as[Entry]
val twoBS = spark.sparkContext.broadcast(twoDS.sort("a").collect())
oneDS.map(r => {
val foundAtTwo = twoBS.value.find(r.a)
JoinResult(r.a, r.value, foundAtTwo.map(_.value))
}).count()
这个时候可以将小数据集通过 广播变量 的方式,广播到每个节点,这样可以在大数据集的每个partition内进行本地访问小数据集
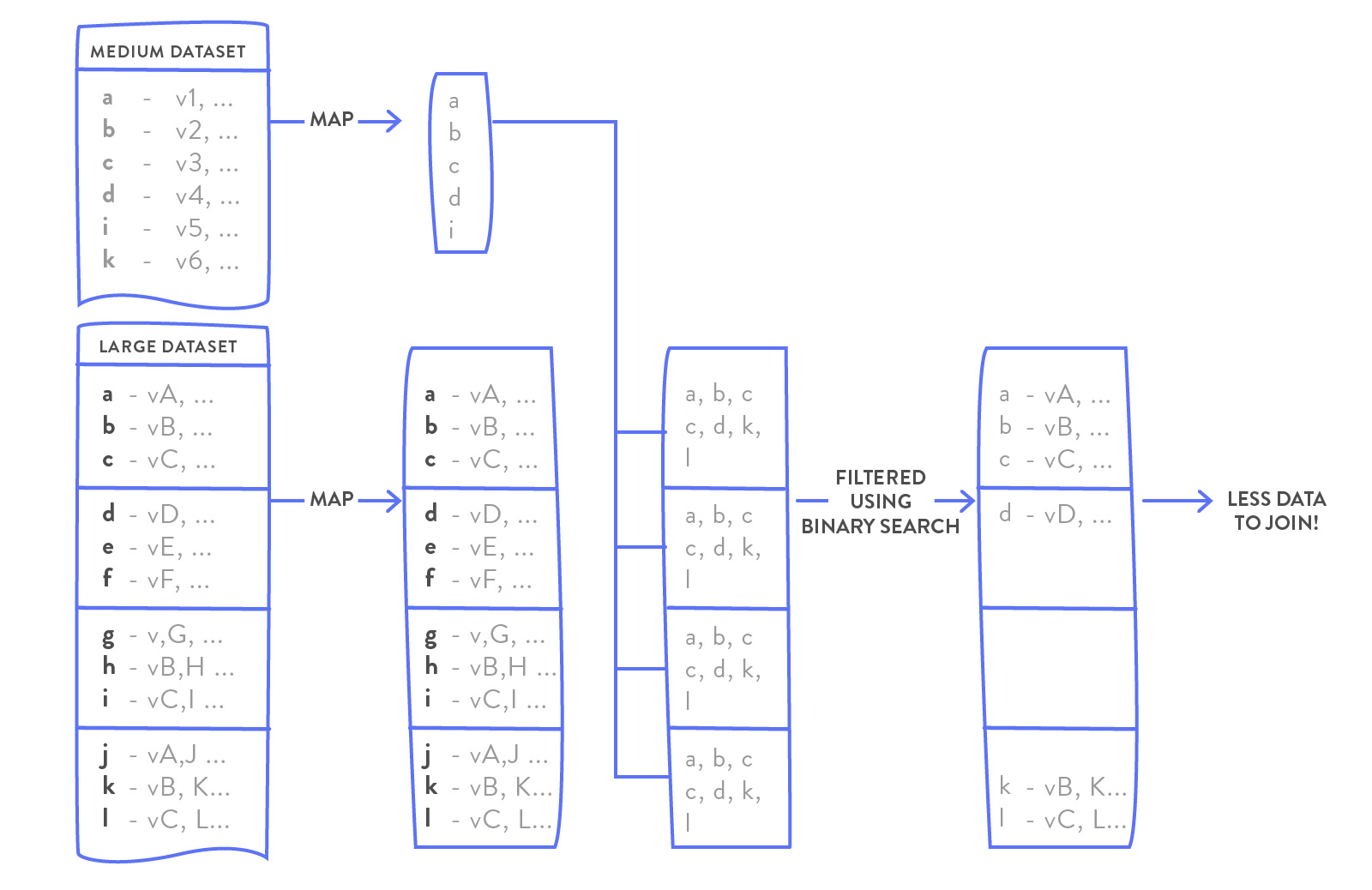
为提高查找性能,可以使用二分查找
oneDS.map(r => {
val foundAtTwo = binarySearch(twoBS.value, r.a).map(n => twoBS.value(n))
JoinResult(r.a, r.value, foundAtTwo.map(_.value))
}).count()
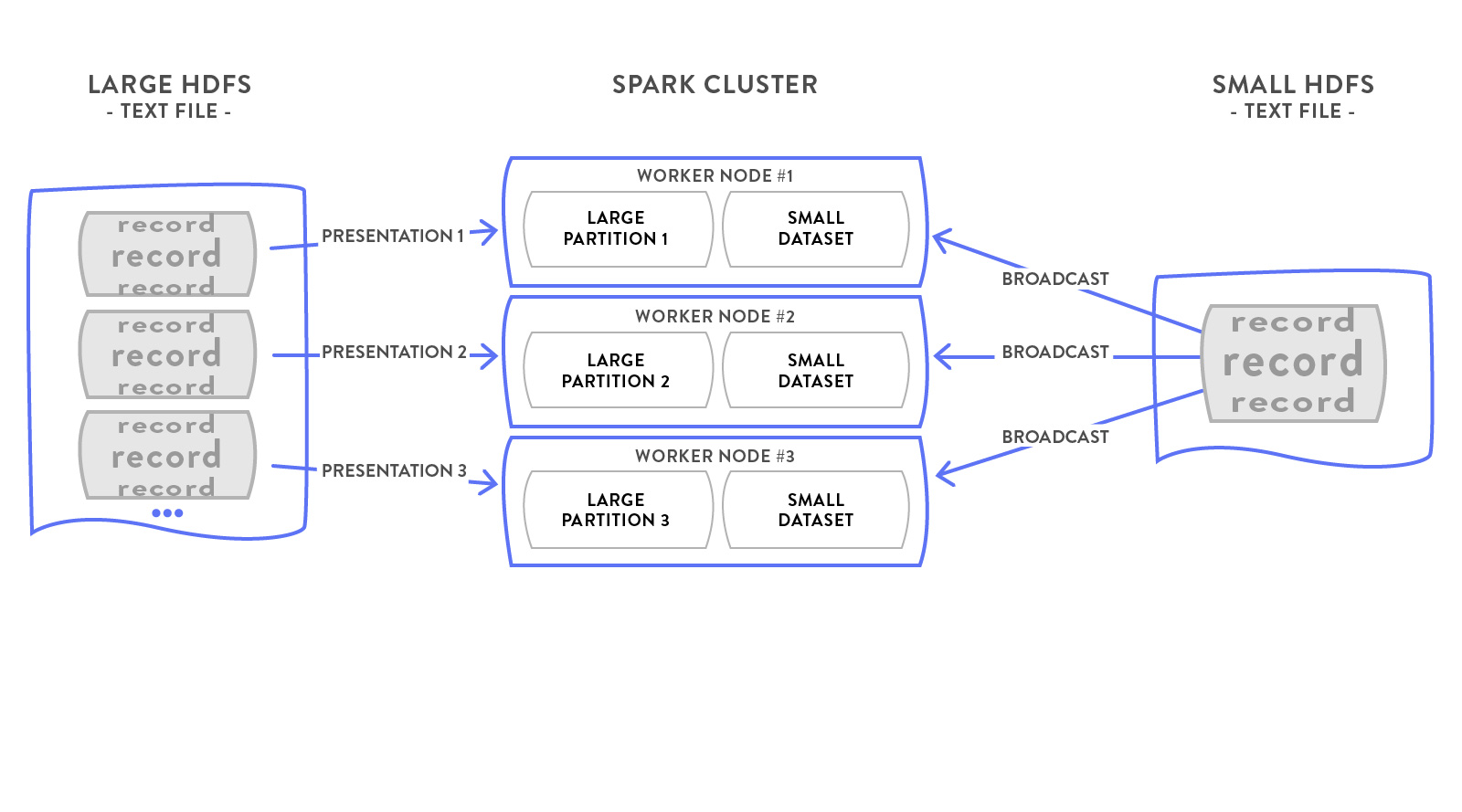
中数据集 VS 大数据集
某些时候 中数据集可能太大,只能把key索引到内存:
import scala.collection.Searching._
val oneDS= sql("SELECT a, b as value FROM table_one").as[Entry]
val twoDS= sql("SELECT a, c as value FROM table_two").as[Entry]
val twoBS = spark.sparkContext.broadcast(twoDS.map(r=> r.a).sort().collect().toIndexedSeq)
val reducedOneDS = oneDS.filter(r => {
twoBS.value.search(r.a).isInstanceOf[Found]
})
shuffle 性能优化
大多数 Spark 作业的性能主要消耗在了 shuffle 环节,因为该环节包含了大量的磁盘 IO、序列化、网络数据传输等操作。因此,如果要让作业的性能更上一层楼,就有必要对 shuffle 过程进行调优。但是也必须提醒的是,影响一个 Spark 作业性能的因素,主要还是代码开发、资源参数以及数据倾斜,shuffle 调优只能在整个 Spark 的性能调优中占到一小部分而已。因此务必把握住调优的基本原则,千万不要舍本逐末。下面详细讲解 shuffle 的原理,以及相关参数的说明,同时给出各个参数的调优建议。
A、未经优化的 HashShuffleManager
下图说明了未经优化的 HashShuffleManager 的原理,这里先明确一个假设前提:每个 executor 只有 1 个 cpu core,也就是说,无论这个 executor 上分配多少个 task 线程,同一时间都只能执行一个 task 线程。
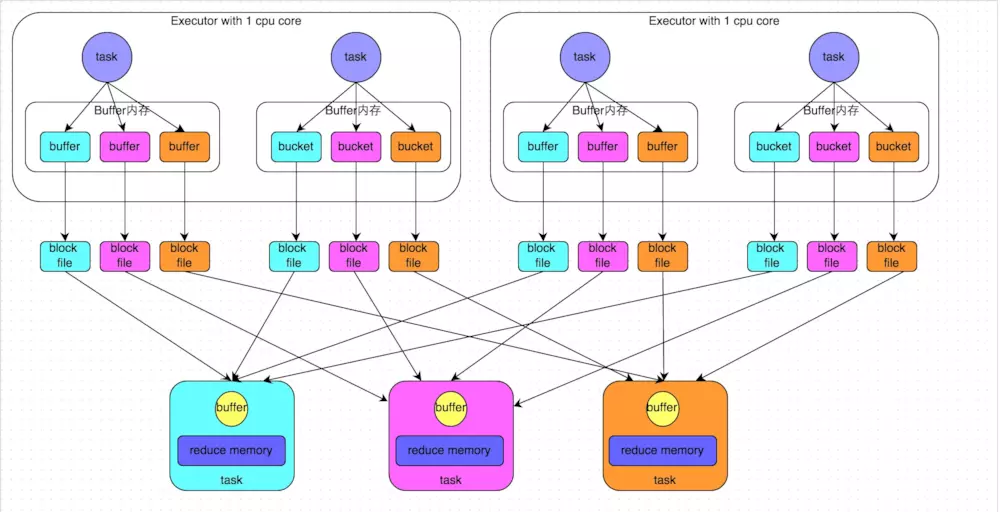
从 shuffle write 说起,shuffle write 阶段,主要就是在一个 stage 结束计算之后,为了下一个 stage 可以执行 shuffle 类的算子(比如 reduceByKey),而将每个 task 处理的数据按 key 进行“分类”。所谓“分类”,就是对相同的 key 执行 hash 算法,从而将相同 key 都写入同一个磁盘文件中,而每一个磁盘文件都只属于下游 stage 的一个 task。在将数据写入磁盘之前,会先将数据写入内存缓冲中,当内存缓冲填满之后,才会溢写到磁盘文件中去。
那么每个执行 shuffle write 的 task,要为下一个 stage 创建多少个磁盘文件呢?很简单,下一个 stage 的 task 有多少个,当前 stage 的每个 task 就要创建多少份磁盘文件。比如下一个 stage 总共有 100 个 task,那么当前 stage 的每个 task 都要创建 100 份磁盘文件。如果当前 stage 有 50 个 task,总共有 10 个 executor,每个 executor 执行 5 个 Task,那么每个 executor 上总共就要创建 500 个磁盘文件,所有 executor 上会创建 5000 个磁盘文件。由此可见,未经优化的 shuffle write 操作所产生的磁盘文件的数量是极其惊人的。
接着来说说 shuffle read,shuffle read,通常就是一个 stage 刚开始时要做的事情。此时该 stage 的每一个 task 就需要将上一个 stage 的计算结果中的所有相同 key,从各个节点上通过网络都拉取到自己所在的节点上,然后进行 key 的聚合或连接等操作。由于 shuffle write 的过程中,task 给下游 stage 的每个 task 都创建了一个磁盘文件,因此 shuffle read 的过程中,每个 task 只要从上游 stage 的所有 task 所在节点上,拉取属于自己的那一个磁盘文件即可。
shuffle read 的拉取过程是一边拉取一边进行聚合。每个 shuffle read task 都会有一个自己的 buffer 缓冲,每次都只能拉取与 buffer 缓冲相同大小的数据,然后通过内存中的一个 Map 进行聚合等操作。聚合完一批数据后,再拉取下一批数据,并放到 buffer 缓冲中进行聚合操作。以此类推,直到最后将所有数据拉取完,并得到最终的结果。
B、优化后的 HashShuffleManager
下图说明了优化后的 HashShuffleManager 的原理,这里说的优化,是指可以设置一个参数,spark.shuffle.consolidateFiles。该参数默认值为 false,将其设置为 true 即可开启优化机制。通常来说,如果使用 HashShuffleManager,那么都建议开启这个选项。
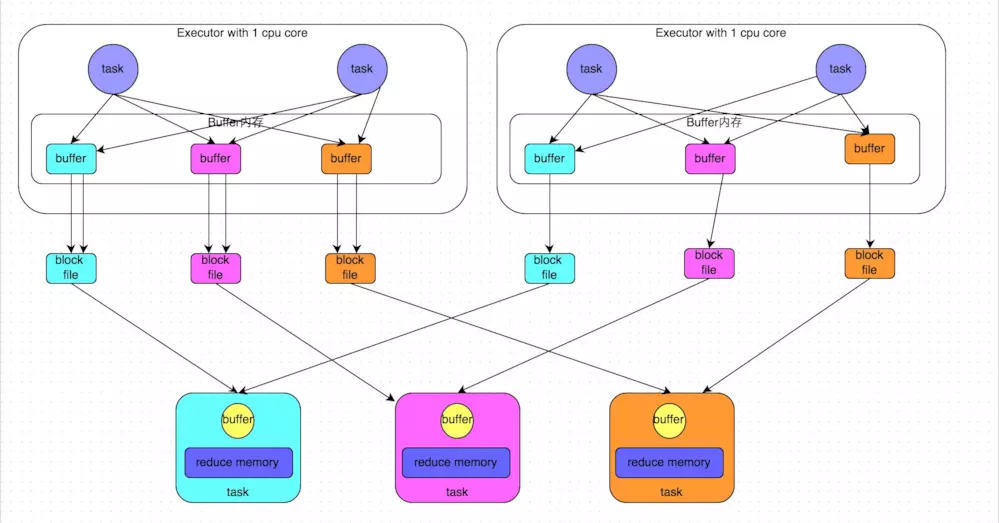
开启 consolidate 机制之后,在 shuffle write 过程中,task 就不是为下游 stage 的每个 task 创建一个磁盘文件了。此时会出现 shuffleFileGroup 的概念,每个 shuffleFileGroup 会对应一批磁盘文件,磁盘文件的数量与下游 stage 的 task 数量是相同的。一个 executor 上有多少个 cpu core,就可以并行执行多少个 task。而第一批并行执行的每个 task 都会创建一个 shuffleFileGroup,并将数据写入对应的磁盘文件中。
当 executor 的 cpu core 执行完一批 task,接着执行下一批 task 时,下一批 task 就会复用之前已有的 shuffleFileGroup,包括其中的磁盘文件。也就是说,此时 task 会将数据写入已有的磁盘文件中,而不会写入新的磁盘文件中。因此,consolidate 机制允许不同的 task 复用同一批磁盘文件,这样就可以有效地将多个 task 的磁盘文件进行一定程度上的合并,从而大幅度减少磁盘文件的数量,进而提升 shuffle write 的性能。
假设第二个 stage 有 100 个 task,第一个 stage 有 50 个 task,总共还是有 10 个 executor,每个 executor 执行 5 个 task。那么原本使用未经优化的 HashShuffleManager 时,每个 executor 会产生 500 个磁盘文件,所有 executor 会产生 5000 个磁盘文件。但是此时经过优化之后,每个 executor 创建的磁盘文件的数量的计算公式为:cpu core 的数量 * 下一个 stage 的 task 数量。也就是说,每个 executor 此时只会创建 100 个磁盘文件,所有 executor 只会创建 1000 个磁盘文件。
C、SortShuffleManager 运行原理
下图说明了普通的 SortShuffleManager 的原理,在该模式下,数据会先写入一个内存数据结构中,此时根据不同的 shuffle 算子,可能选用不同的数据结构。如果是 reduceByKey 这种聚合类的 shuffle 算子,那么会选用 Map 数据结构,一边通过 Map 进行聚合,一边写入内存;如果是 join 这种普通的 shuffle 算子,那么会选用 Array 数据结构,直接写入内存。接着,每写一条数据进入内存数据结构之后,就会判断一下,是否达到了某个临界阈值。如果达到临界阈值的话,那么就会尝试将内存数据结构中的数据溢写到磁盘,然后清空内存数据结构。
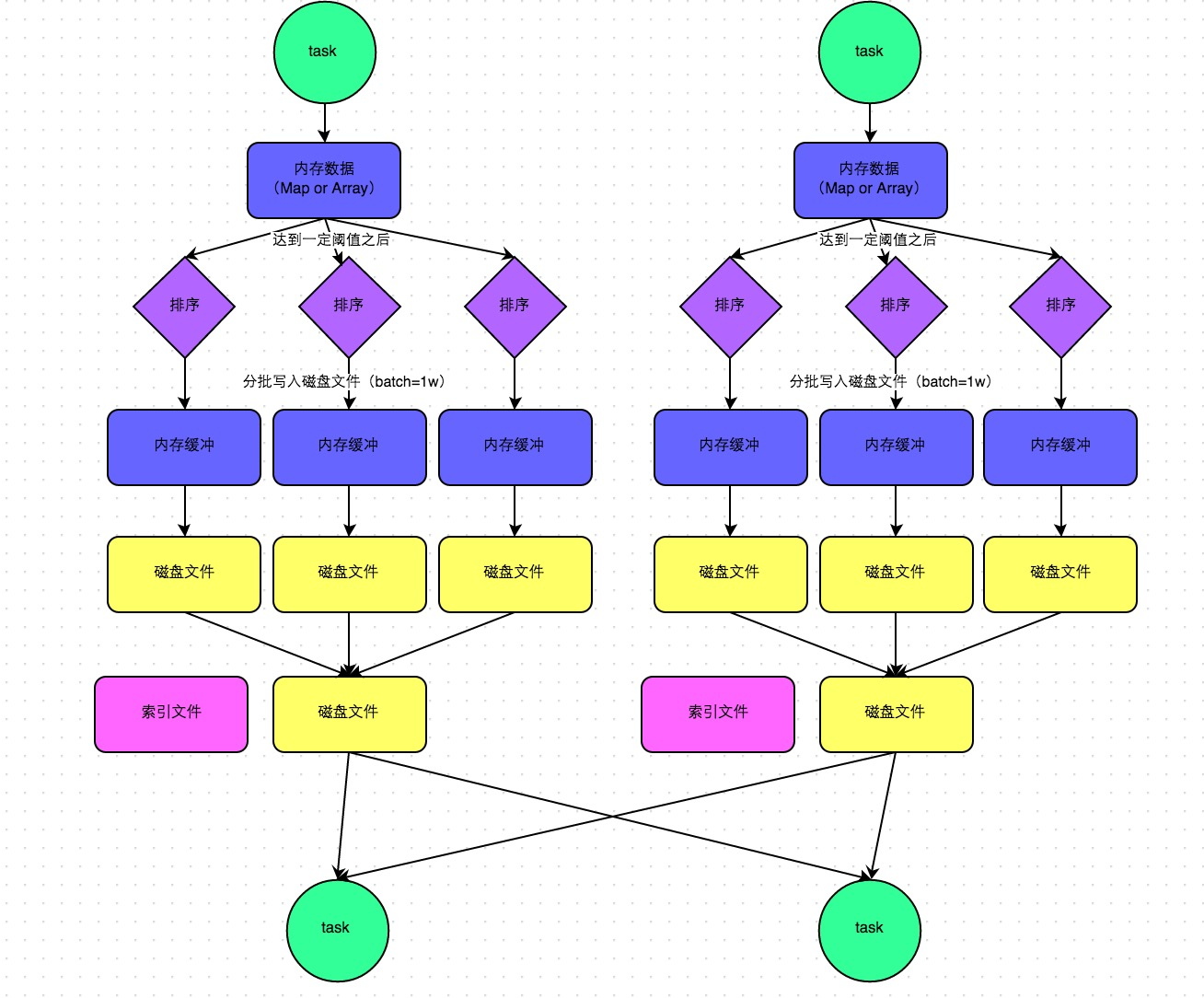
在溢写到磁盘文件之前,会先根据 key 对内存数据结构中已有的数据进行排序。排序过后,会分批将数据写入磁盘文件。默认的 batch 数量是 10000 条,也就是说,排序好的数据,会以每批 1 万条数据的形式分批写入磁盘文件。写入磁盘文件是通过 Java 的 BufferedOutputStream 实现的。BufferedOutputStream 是 Java 的缓冲输出流,首先会将数据缓冲在内存中,当内存缓冲满溢之后再一次写入磁盘文件中,这样可以减少磁盘 IO 次数,提升性能。
一个 task 将所有数据写入内存数据结构的过程中,会发生多次磁盘溢写操作,也就会产生多个临时文件。最后会将之前所有的临时磁盘文件都进行合并,这就是 merge 过程,此时会将之前所有临时磁盘文件中的数据读取出来,然后依次写入最终的磁盘文件之中。此外,由于一个 task 就只对应一个磁盘文件,也就意味着该 task 为下游 stage 的 task 准备的数据都在这一个文件中,因此还会单独写一份索引文件,其中标识了下游各个 task 的数据在文件中的 start offset 与 end offset。
SortShuffleManager 由于有一个磁盘文件 merge 的过程,因此大大减少了文件数量。比如第一个 stage 有 50 个 task,总共有 10 个 Executor,每个 executor 执行 5 个 task,而第二个 stage 有 100 个 task。由于每个 task 最终只有一个磁盘文件,因此,此时每个 executor 上只有 5 个磁盘文件,所有 Executor 只有 50 个磁盘文件。
D、bypass SortShuffleManager运行机制
下图说明了 bypass SortShuffleManager 的原理,bypass 运行机制的触发条件如下:
lshuffle map task 数量小于 spark.shuffle.sort.bypassMergeThreshold 参数的值;
l 不是聚合类的 shuffle 算子(比如 reduceByKey)。
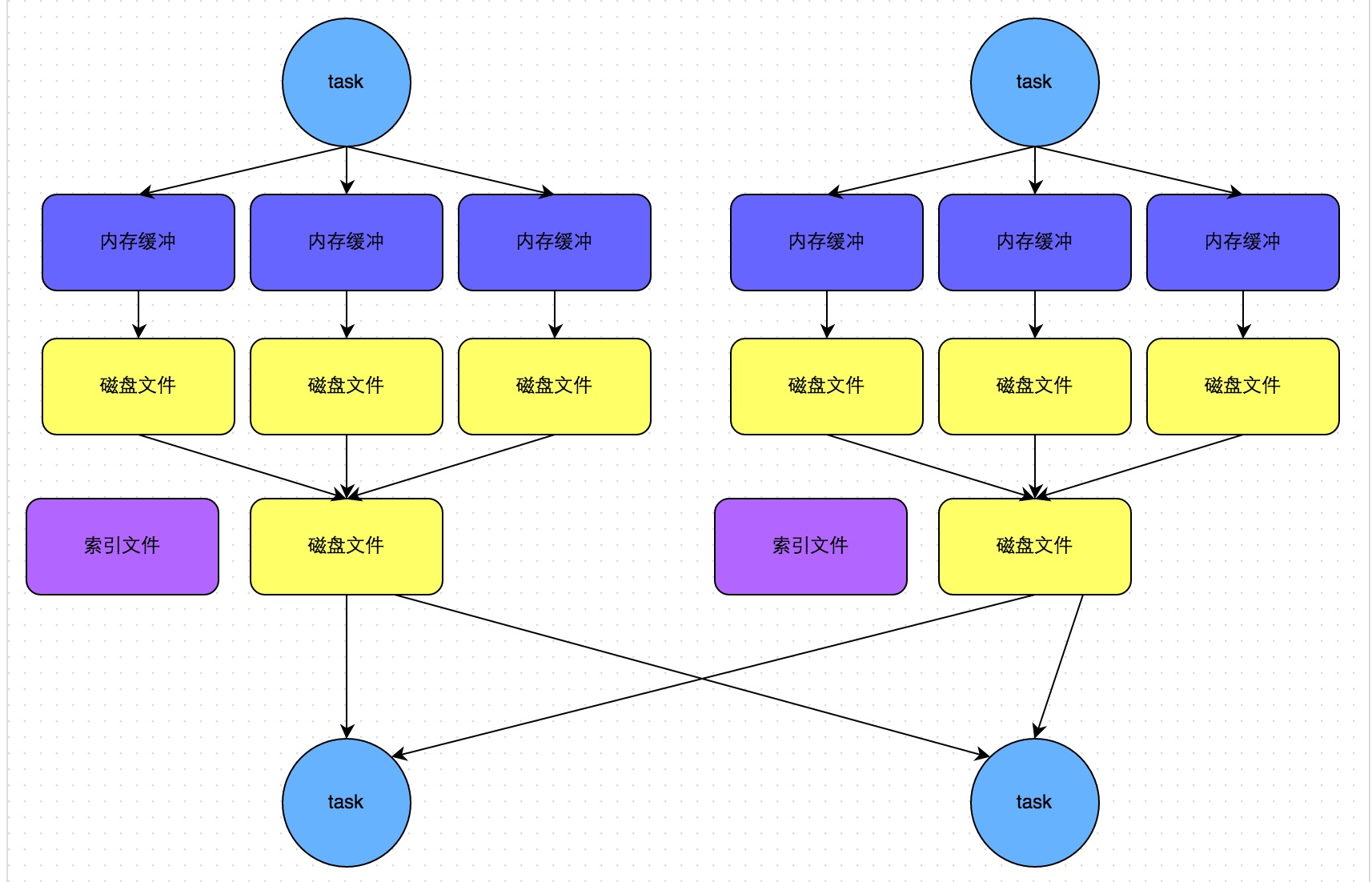
此时 task 会为每个下游 task 都创建一个临时磁盘文件,并将数据按 key 进行 hash 然后根据 key 的 hash 值,将 key 写入对应的磁盘文件之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。
该过程的磁盘写机制其实跟未经优化的 HashShuffleManager 是一模一样的,因为都要创建数量惊人的磁盘文件,只是在最后会做一个磁盘文件的合并而已。因此少量的最终磁盘文件,也让该机制相对未经优化的 HashShuffleManager 来说,shuffle read 的性能会更好。
而该机制与
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%80%A7%E8%83%BD%E8%B0%83%E4%BC%98%E6%80%BB%E7%BB%93/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


