技术深度学习排序在招聘搜索场景的演进
58同城 白博 稿

01 背景
搜索推荐部作为中台部门为整个58集团提供搜索基础服务能力,我们在20年成功落地了深度学习模型,并在租房业务取得了不错的效果[1]。本着深入产业化的原则,我们后续又落地到招聘、黄页等多个场景。本文针对我们在招聘业务的深度学习排序工作,做一个简要介绍。首先从模型特征出发,结合招聘业务的多角度信息挖掘,介绍了模型演进的几个关键成果,之后从效能提升出发,介绍了离线工程方面的几个优化点,最后对未来的工作重点进行了简述。
初期落地在58租房业务的深度学习排序模型为DIEN[2],具有如下结构:
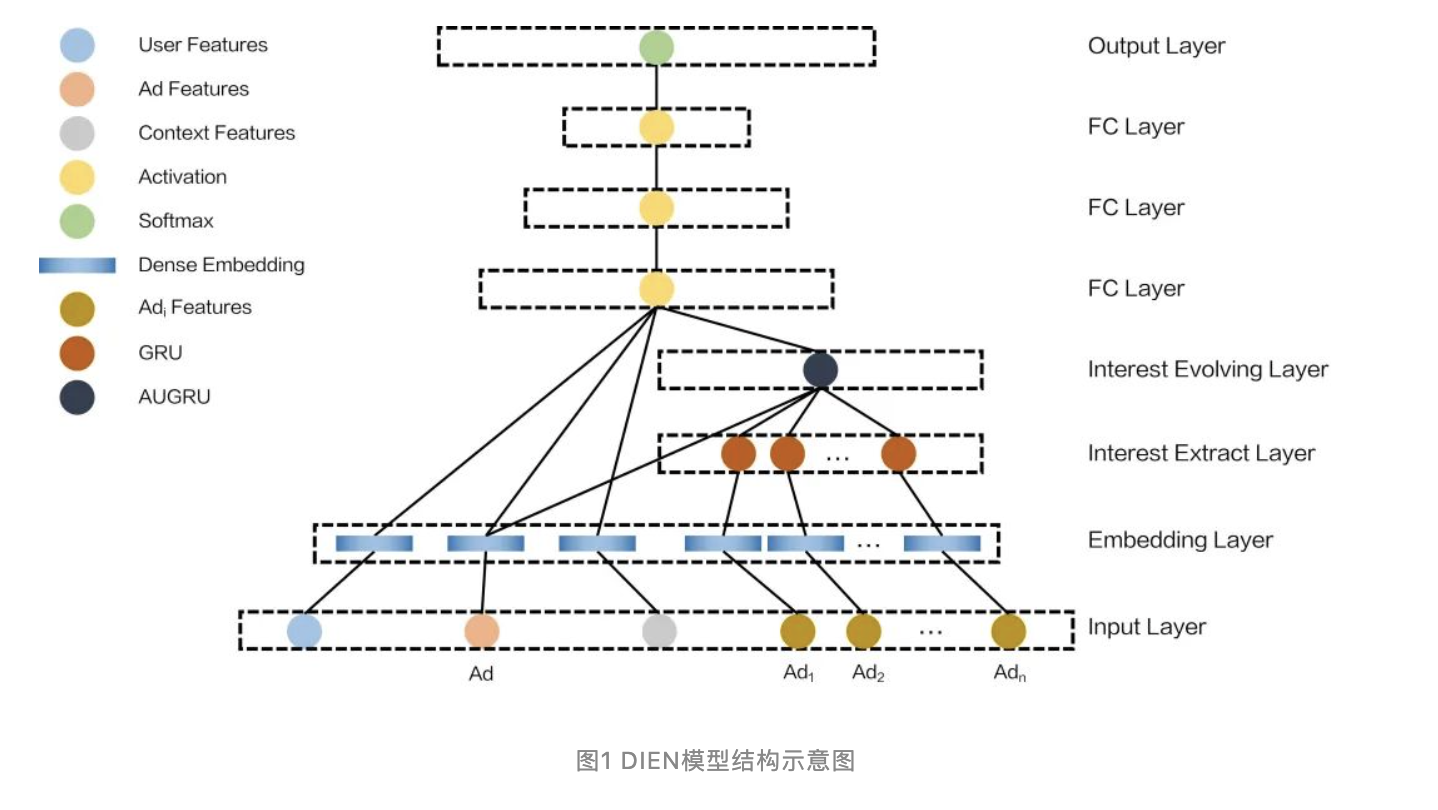
DIEN可以很好的捕获用户历史兴趣,相比DNN,额外构建了兴趣提取层(Interest Extract Layer)和兴趣发展层(Interest Evolving Layer),综合利用GRU和Attention结构,专门针对用户的历史点击序列提取了更合理的embedding表征。我们先前的模型对于用户历史兴趣信息的应用局限于各种统计特征,在换用DIEN处理更原始的用户历史序列特征时,拿到了很不错的线上效果。
02 模型特征挖掘
2.1 更多特征信息
业务之间蕴含不同的特征信息,建模时需要考虑特殊性,以更好的应对具体场景的优化任务。考虑到为模型提供更多维度更丰富的输入信息,我们更新了模型的输入层,新增了两种输入特征:多值特征和语义向量特征。
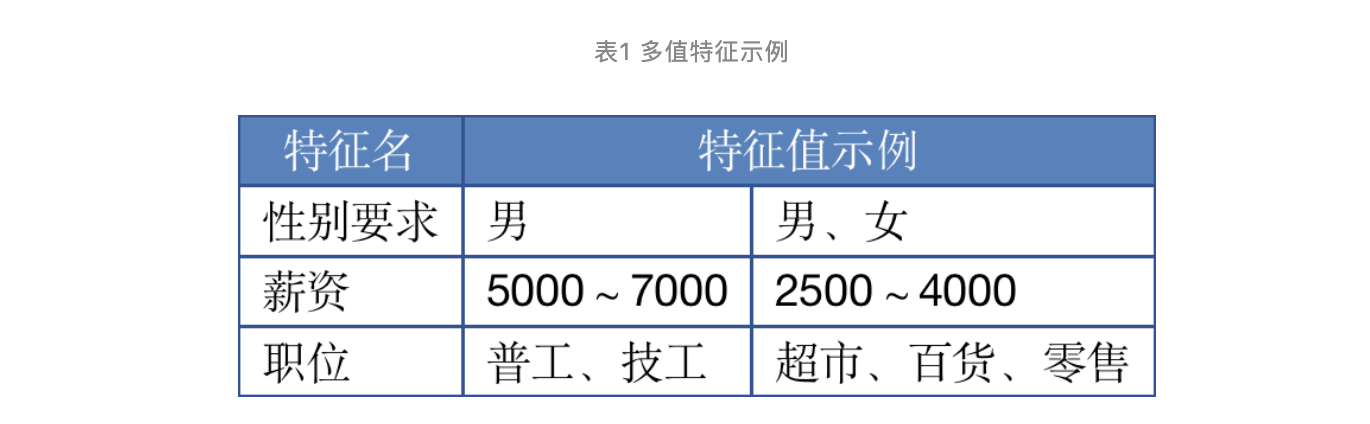
多值特征,是指一个帖子特征,可能包含了多个特征值,如下表所示:
语义向量特征,是指搜索召回侧使用的query、帖子的语义向量,这部分由负责召回的同学优化落地,通常是由BERT等其他语义深度模型提取得到的信息表征,蕴含了更高阶的语义,是现有特征集所缺乏的信息。
因此,DIEN模型结构更新为如下图所示形式:
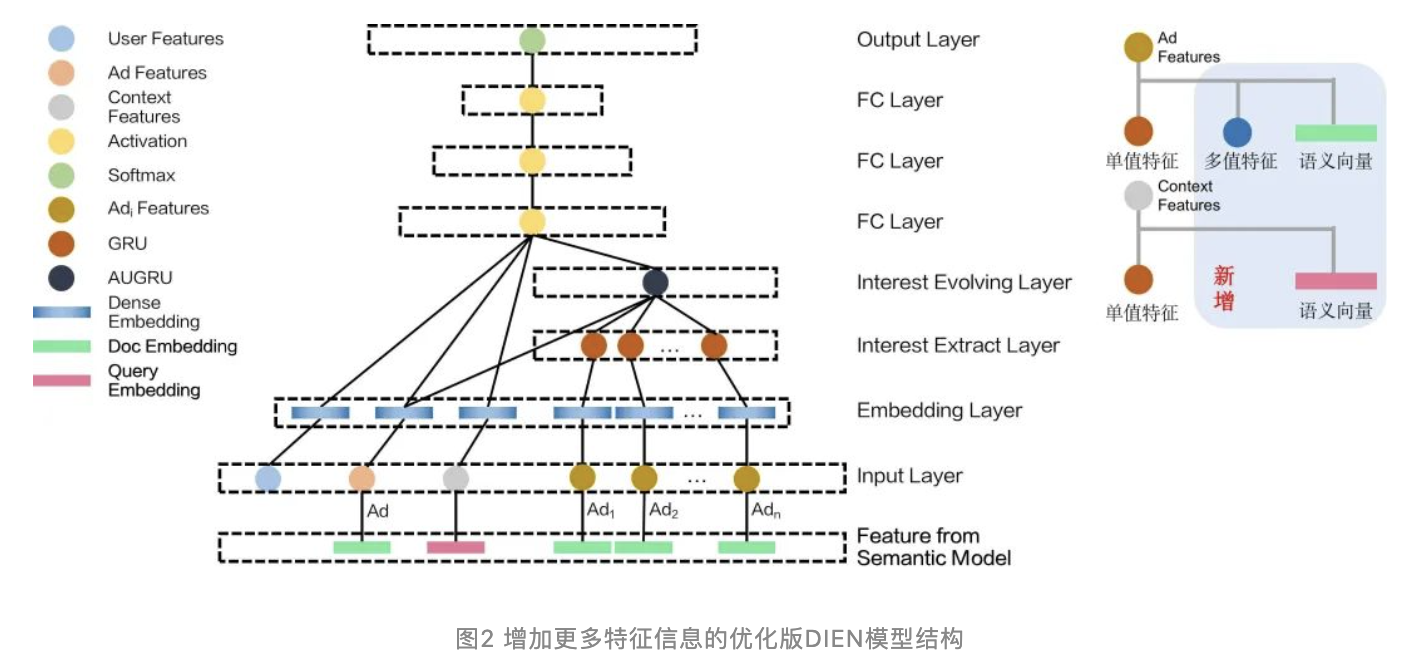
具体在映射特征到embedding时,多值特征采用了multi-hot编码方式,语义向量直接使用原浮点值不做映射。
在加入如上新特征后,离线验证效果如下表:
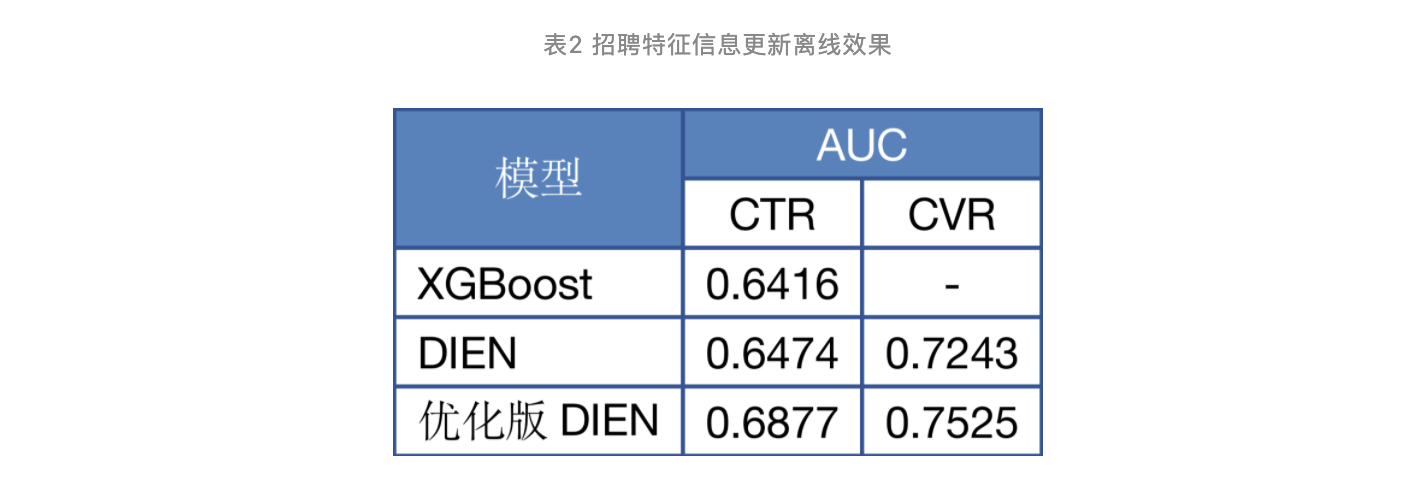
可以看出,相比原始DIEN,增加了更多维度信息的优化版DIEN,在模型评测指标AUC上有3-4个点的提升,因此我们将模型在招聘的四个子场景上线,线上的效果表现如下表:
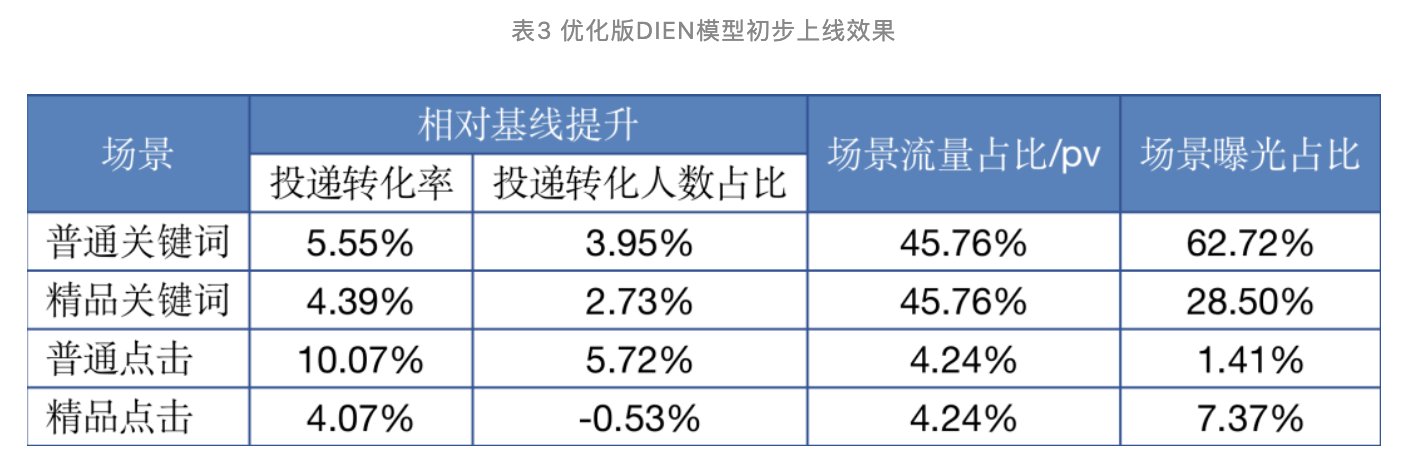
搜索侧在招聘有四种子场景:用户通过输入框键入搜索词后,发起的搜索我们称为关键词搜索;用户通过点击页面的筛选列表进入某个职位,我们称为点击搜索。每种搜索场景下,搜索侧包含两种帖子类型:普通和精品,区别在于两种帖子展现的位置略有区别,精品贴相对普通贴会更靠上。从表3可以看出,加入了更多特征信息的优化版DIEN模型,在招聘多个子场景的提升相对明显。
2.2 更合理的模型应用和更新策略
招聘业务C端用户的检索词符合典型的长尾分布,长尾检索往往因为意图小众、数据稀疏等原因,更容易出现高质量检索结果少的情况。我们统计了单天某时间段的用户搜索情况,具体见下图:
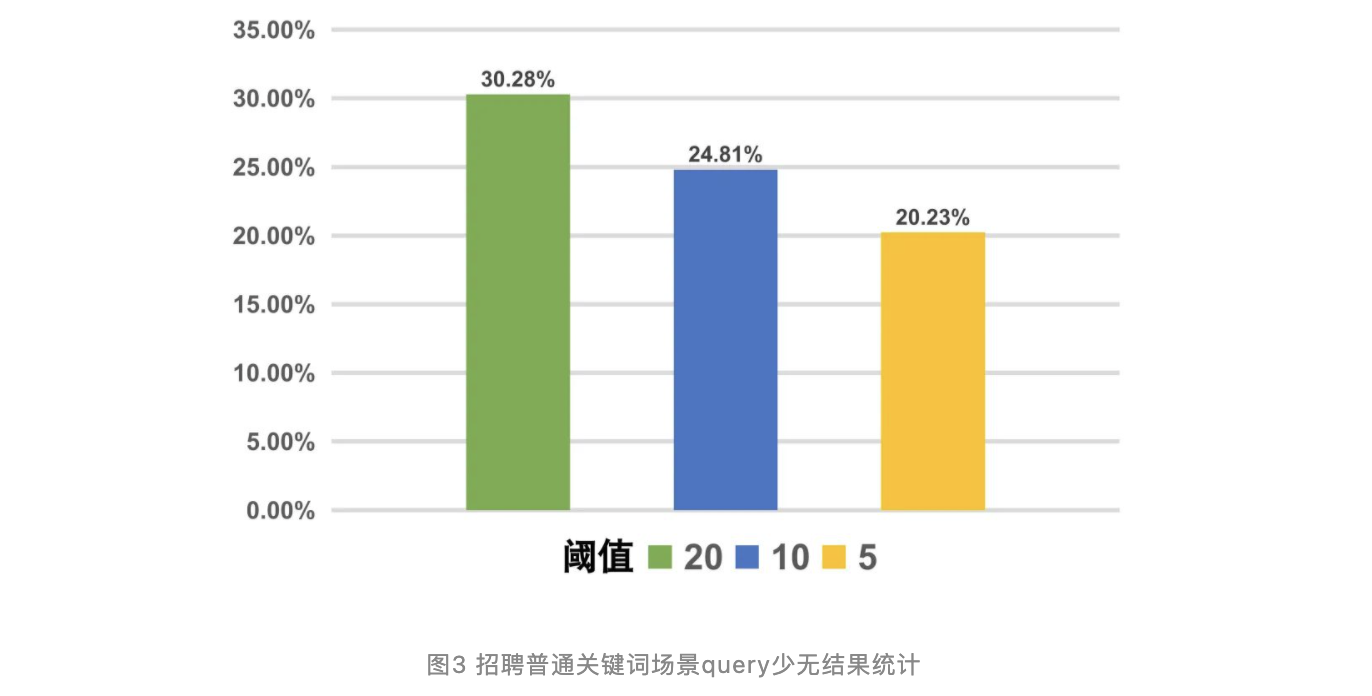
结合表3和图3,对于流量占比最大的关键词搜索,尤其是曝光占比最多的普通关键词场景,用户搜索后获取结果较少的情况比较明显,比如图3中,小于20条搜索结果的query占比达到了30%,在这种情况下,参与排序的帖子数量很少,极大限制了排序空间,导致离线提升兑换到线上的提升幅度大打折扣,DIEN模型排序的重要性被大大降低。因此表2中离线指标提升巨大的情况下,表3中的关键词场景收益却比预想中低很多。
基于招聘搜索召回结果少的情况,我们组负责召回的同学,进行了系统的召回优化,通过query理解、语义召回等技术手段,在一定的搜索质量约束下,将更多有投递可能性的帖子召回,参与后面的粗排、精排,以更充分的发挥DIEN模型的能力。所以在初期增加了更多特征信息的DIEN模型上线后,我们进一步在语义召回结果上应用了DIEN模型排序。
上线观察一段时间后,我们发现在招聘场景下,模型随日期的衰减相比租房要快的多,一周后模型线下AUC指标就会掉1个点左右,因此为了保证模型效果的稳定性,进一步完成了模型按天自动更新的策略,从离线数据、模型训练到模型更新,制定了完整的流程。
上线的具体效果如下表:
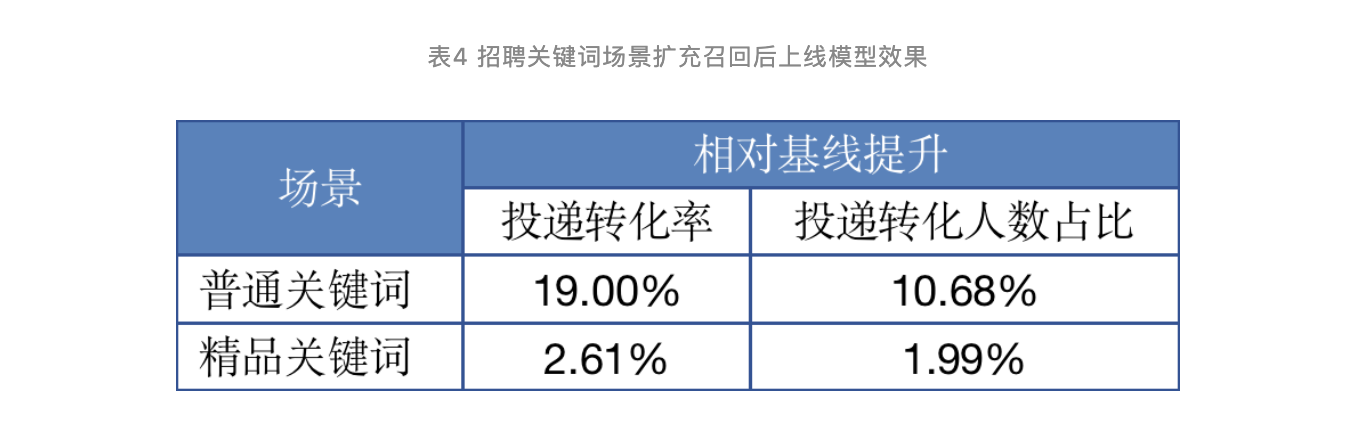
注意我们只在关键词场景上做了优化,这是因为点击场景的流量占比很小,因此我们优先集中精力优化了关键词场景。其中,精品关键词的收益来自于模型自动更新策略,说明离线数据合理利用的重要性,保持模型对新数据的敏感,可以有效提升模型的线上表现。
普通关键词场景的显著提升一部分来自于自动更新策略,更大的一部分得益于召回、粗排优化,增加了DIEN模型精排的优化空间。因此,从召回、粗排到模型精排,全流程的协作至关重要,通过召回等前置路径扩大模型的排序应用范围是很有效的手段。排序能力依赖于各个子环节,全链路的优化才可能获得最好的线上效果。
2.3 更丰富的序列信息
模型现有的序列信息,主要包含了用户过去一段时间内点击过的所有帖子特征,例如帖子的薪资、职位、年龄要求等。在招聘场景的模型优化上,业务线更关注投递转化率指标,但模型仅在多目标学习时,通过loss显式的建立了输入特征到转化行为的关系,输入信息并没有显式的区分用户的转化意图。
因此除点击序列外,我们从点击序列中进一步抽取了有用户转化行为的部分,具体为提取用户曾打过电话、投过简历的帖子次数构成转化序列。
针对新构建的转化序列,主要在DIEN的兴趣发展层强化了转化行为的信息,如下图所示:
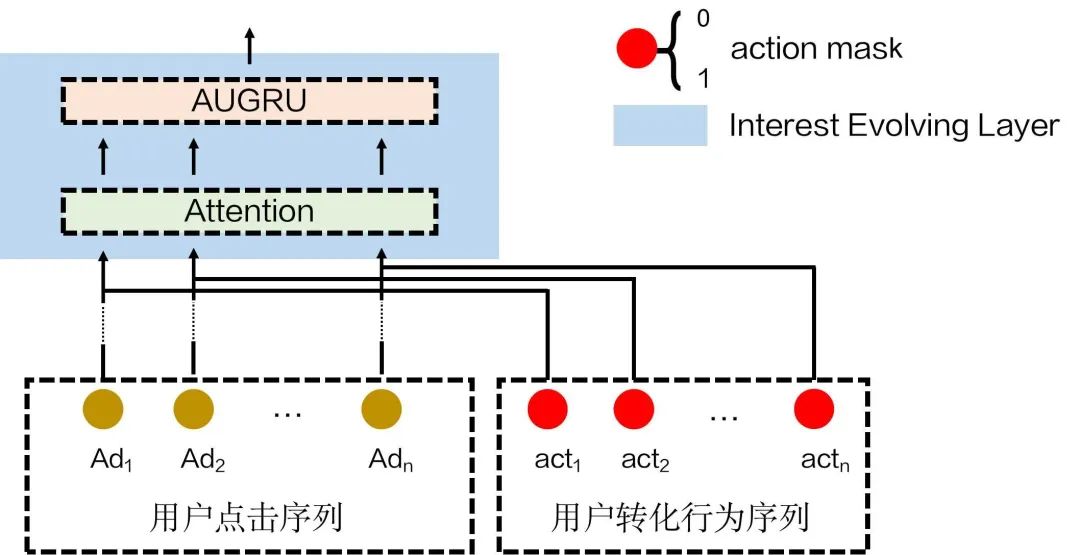
图4 DIEN加入转化序列示意图
我们在兴趣发展层的Attention部分,为Q查询得到的V1,附加了转化序列作为mask,新建了V2,并将V1与V2叠加作为最终的V,相当于加强了序列中有转化行为的部分权重。
不论用户的点击或转化序列,都是从用户历史浏览过的帖子维度建模了用户信息,为了引入更多维度的信息,我们还新增了用户历史搜索过的关键词序列,其中包含了用户搜索query、query对应语义向量、搜索时地域等信息。使用时对应帖子侧的语义向量,与搜索关键词序列中的query侧语义向量做点积得到相似度,再选取最大相似度作为候选贴和历史关键词序列的匹配特征。
除上述对序列信息的更新外,我们还对模型的多目标学习做了调整,之前多目标loss定义如下:
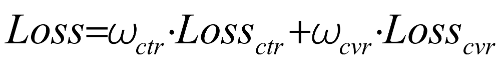
整体优化目标采用多个子目标的加权和,是比较简单的多目标优化方法。为了更合理的建模多目标,我们参考ESMM[3]对loss进行了改造,采用CTR和CTCVR的连乘来构造CVR的学习目标,隐式的建模转化行为,更符合实际情况即用户先点击进入某个帖子,才能继续产生转化。
2.4 更合理的特征交叉信息
在租房业务时,DIEN之前落地更早的一版模型为DeepFM[4],也取得了一定的线上效果,招聘场景针5DIEN进行了几轮优化后,将视角返回到特征信息的使用上。DIEN主要的效果提升,在于对用户的历史行为做了合理且充分的建模,但对于特征和特征之间的关联关系,没有像DeepFM一样显式建立交叉机制,因此,我们整合了DeepFM和DIEN,对于不同类特征间的关联信息进行建模,但初期实验效果较差,DeepFM部分对于整体的贡献很少,提升仅在千分之三左右。
为更好的建模特征间的关联关系,我们落地了阿里提出的CAN[5]模型。CAN从笛卡尔积的角度出发,认为笛卡尔积方式建模特征和特征间的关联,相比FM隐向量方式更合理,但笛卡尔积会导致参数膨胀,对于取值为N、M的特征建模,笛卡尔积取值为N*M,对于线上实时性要求很高的排序模型是不可接受的。CAN提出了一种MLP拟合笛卡尔积的替代框架,如下图:
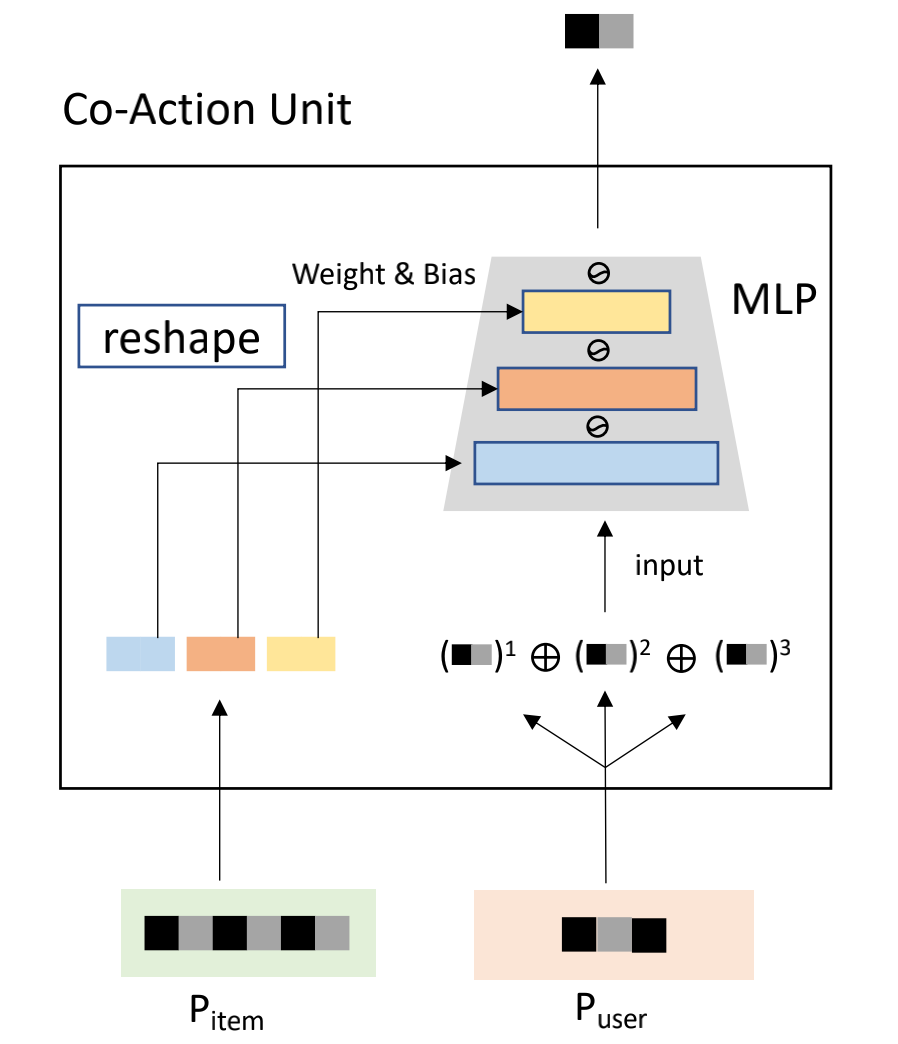
图5 CAN特征交互结构
图中Pitem为候选item的特征,Puser为用户序列里的特征。CAN将候选item的特征构建一个embedding表,从中取出一部分当做MLP的参数,将序列里的特征作为MLP的输入,这样MLP的输出就作为特征关联信息。
进一步的,我们改进了特征交互结构,除用户序列和候选贴的特征关联外,也支持任意种类特征间的关联,如用户特征中的用户薪资画像和候选贴特征中的职位。最终形成的DIEN和CAN的联合结构类似于Wide&Deep的方式,如下图:
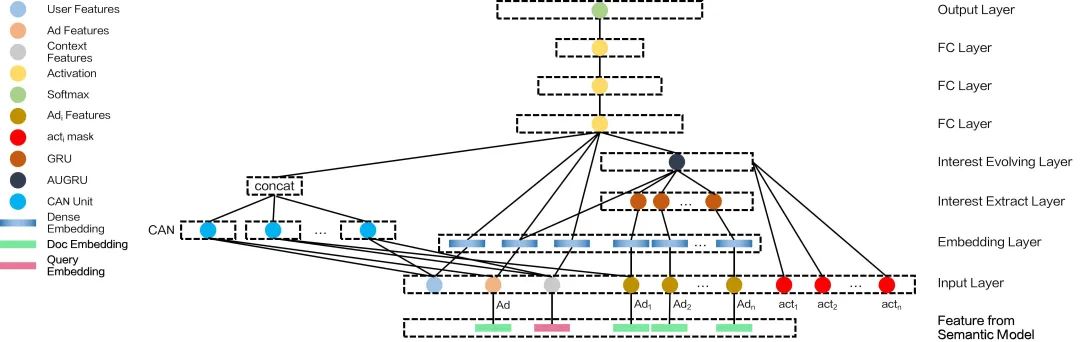
图6 DIEN融合CAN特征交互结构示意图
可看出,CAN结构从输入层交叉任意两组特征,每个结构保持自己的独立参数,从而在获取特征关联关系时,不受embedding方式影响,相比FM提前了特征交互的时机且不共享不同特征组合间的交互信息,能够更合理的建模两种特征的共现关系。
离线实验时,我们结合2.3节所述的新序列信息建模进行了对比实验,结果如下表:
表5 DIEN优化离线实验结果
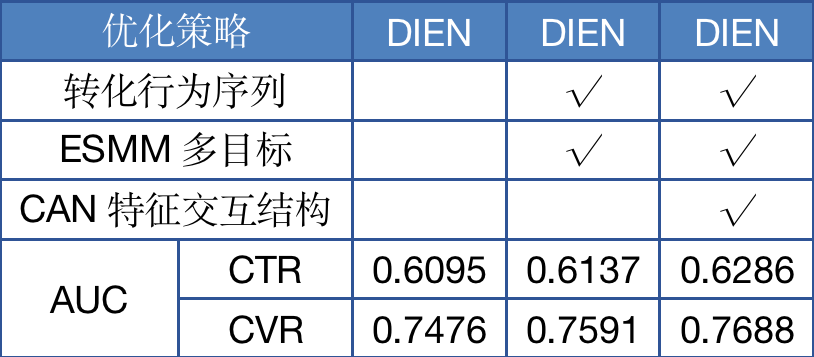
从表中可以看出合理的建模特征间的关联关系的重要性,在转化序列和ESMM带来更多用户转化行为信息的基础上,进一步借助特征间的关联提升了模型效果。值得一提的是,相比于CAN论文中所说同类特征间的关联关系,我们发现在招聘场景下,不同类特征间的关联信息为我们带来了更多的效果提升,仅将同类特征建模,比如候选贴的职位与用户历史点击序列的职位,线下只拿到了千分之四的收益。我们认为DIEN在建模用户序列时,已经包含了同类特征间的关联关系,所以CAN结构引入的额外信息收效甚微,但DIEN对不同类特征间的关联信息捕获不充分,因此CAN收益明显。
带有CAN结构的模型上线时,虽然MLP参数量相比笛卡尔积小很多,但特征组合间参数独立,过多的特征组合也会拖慢模型预测速度,因此我们依据业务知识,从82个特征中筛选了22组特征组合,最终上线效果如下:
表6 DIEN优化模型在普通关键词场景上线效果

上线后观测,带有CAN结构的DIEN模型相比基线DIEN,预测平均耗时增加5ms,T99增加8ms,超时控制在0.5%左右,能够满足线上预测实时性的要求。
03 离线流程优化
算法工程师从来都不是单纯靠算法就可以解决所有业务问题的,必须落地到具体业务场景,遇到各种瓶颈再尝试突破。除了上述模型方面的工作之外,我们也花了很大力气构建合理完善的离线流程,保证模型的迭代效率。
3.1 离线数据优化
从2节所述模型的信息更新可以看出,我们持续不断的为模型引入更多维度的特征信息,这也客观的带来了离线数据的膨胀。尤其是语义向量的引入,序列中的每个点击帖子都有自己的向量,并且向量我们直接用了召回侧同学的优化结果,召回侧的版本迭代优化也促使我们不断变更离线数据,在租房业务构建的离线数据生产流程时间成本过高,所以我们重构了招聘场景的离线数据流程。
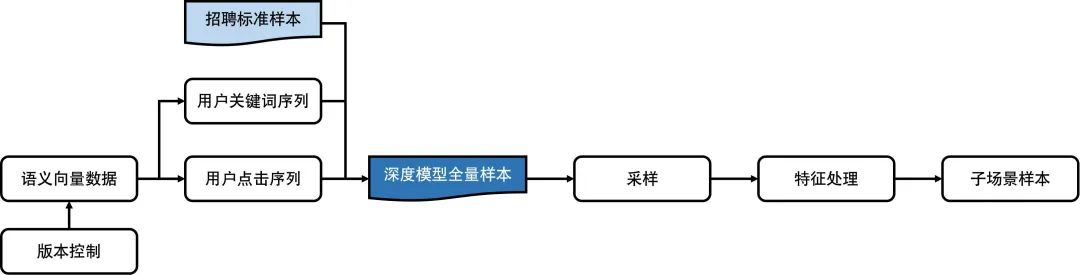
图7 招聘模型离线数据生产流程
原先序列数据为串行生成,我们调整为并行生成多份序列,待招聘标准样本产出后整合为模型全量样本,极大提升了数据的生产效率。此外,样本加入语义向量时,由于帖子和用户维度都有向量特征,所以除了标准样本之外,对于用户序列中的每个帖子,也需要加入语义向量信息。因此向量信息的获取数目极其庞大,以21年6月6日单天数据为例,需要加入向量的帖子ID在请求多个向量版本时的访问量在33亿多。
因此,如何更合理高效的加入语义向量特征,先后迭代了3个不同的版本,见下图:
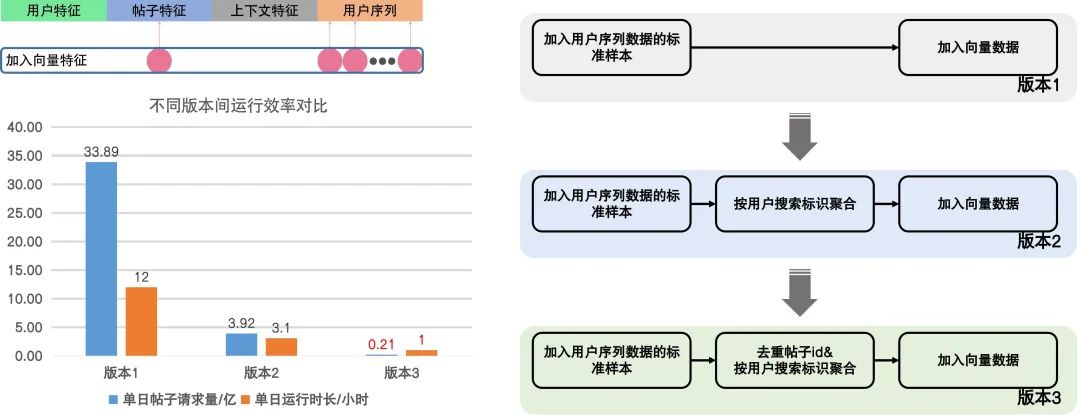
图8 多版本语义向量加入离线数据优化流程
版本2在1的基础上,采用用户的唯一搜索标识优化了请求量,版本3进一步的先获取所有帖子ID,去重得到向量后再拼接回原有样本,大幅度减少了单日样本所需的帖子请求量,在运行时长上相比先前版本提速明显。如图所示,优化后的版本效率提升显著,使整体模型所需训练样本的生成时间进一步减少,从而满足模型高频率更新的要求。
3.2 线上效果监控
此外,上线后模型的效果在某些天内会有较大波动,为了确保离线流程稳定可控,除了在上述序列数据生产、多版本语义向量请求时加了失败率监控外,对于实时性要求比较高的几类特征,我们都在线下补充完善了数据监控,针对线上线下的数据一致进行校验,以便及时发现数据问题。同时,为了及时监控模型的线上效果,我们也建立了模型的AB实验报表,更方便的观测模型实际效果。
图9 某特征数据监控示意图
3.3 模型提效
对于不断加入的向量和序列数据,很大程度丰富了模型输入信息的同时,也带来了其他问题,除了存储上的压力外,模型训练时的速度大幅减慢,GPU利用率非常低。
我们分析了模型每次迭代时的操作耗时,发现是由于我们模型训练采用了从HDFS实时拉取数据的tensorflow dataset机制,膨胀的数据使每次迭代时的下载成为很耗时的工作,极大增加了模型的训练时间。而且一周的训练数据存储占用高达2T以上,我们使用的58深度模型训练平台WPAI最高支持拉取1T数据到镜像环境,因此直接预下载数据到本地再训练的策略也不可行。
所以,我们调整了模型的数据格式,将csv数据转换到tfrecord格式,并采用gzip方式压缩数据,转换后的数据大小显著减少。我们参考开源实现[6],采用了MapReduce方式转换数据,针对8000万左右的训练数据,只需不到3分钟便可转换完成。
此外,我们构建dataset时,在map操作构建了处理样本行的dataset后,使用了padded_batch操作,能够对batch内不同长度的序列数据自动补零对齐维度。但原先只在map时做了prefetch的预加载优化,tensorflow在dataset的转换操作时,每次转换都相当于构建一个新的dataset对象,因此padded_batch没有接收到之前的优化逻辑,需要单独再进行一次prefetch优化。
如上操作后,优化效果如下图:
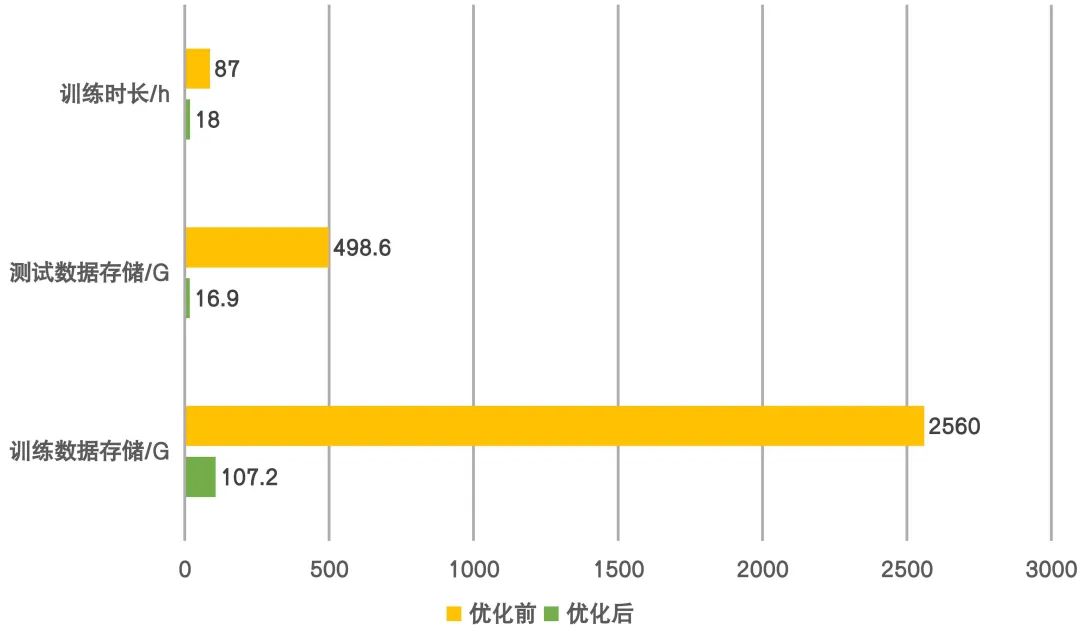
图10 模型训练提效
经过离线流程的优化后,模型优化迭代的效率大大提升,我们不论是更新模型结构加入更多维度的特征,还是保持较高频率的模型更新,都更为便捷。如2.2节所述,自动更新策略也能为我们带来线上效果2个点左右的提升,充分表明了算法同学在拓展模型能力的同时,也应该不断完善数据的基础建设,从而更从容的完成业务目标。
04 未来工作计划
招聘业务包含了四个子场景,我们之前的优化抓了普通关键词这一流量大头,对于其他子场景的优化工作有所欠缺,怎样有效的将优化策略迁移到不同的子场景,或者进一步地,怎样挖掘多个子场景间的共有信息,从而提升所有场景的模型效果,是一个值得思考的问题。此外,对于不同的子场景,我们在模型上线阶段,都要重复性的进行一些工作,这为我们带来了很高的维护成本。
我们参考STAR[7]模型的思想,初步进行了一些工作,结合现有模型框架,实现了不同场景间的信息独立和共享,仅采用一天数据训练和测试的实验结果如下表:
表7 STAR初步实验结果
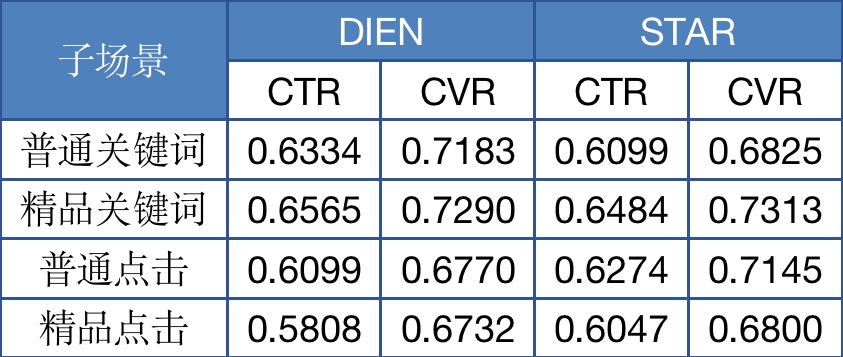
通过场景间的数据交互,小流量场景的模型效果得到了增强,但大流量场景没有收益。后续我们会继续调整STAR的结构,实现所有场景的效果提升,并在上线时只部署一个模型,来提供不同场景下的模型预测服务,降低我们的维护成本,使我们能集中力量在模型优化上做出更多成果。
搜索排序的核心目标是更好的对用户需求与帖子做匹配,因此对于返回结果的相关性有着强要求。可以看到经过模型层面的几轮优化,投递收益逐渐缩小,所以我们之后会花更大的精力在提升用户搜索体验上。目前我们为了保证相关性约束,在精排模型上叠加了相关性分层的策略,但未来希望将相关性和现有模型深入结合,在兼顾转化率的同时,不断提升排序结果的相关性。目前我们在召回和粗排侧有一些相关性的工作,精排加入相关性目标后,也可以更好的和前述环节配合优化,从召回开始打通模型的全链路优化。
另外,持续提升搜索体验也是搜索的核心优化目标之一,目前,我们团队已经在query理解、query改写、语义向量检索、相关性排序等技术方向开展了非常多的工作,后续,我们会在这些技术方向继续进行深度优化,持续提升搜索效果。
作者简介
白博,58同城TEG—搜索排序部高级算法工程师,专注于58同城垂类搜索排序优化,负责深度学习模型的具体场景落地与迭代。
部门简介
58同城TEG搜索排序部,旨在打造搜索技术中台,输出分词、纠错、语义向量等NLP基础服务及召回、排序服务,全面赋能58核心业务场景,解决业务痛点与难点;目前合作业务:房产、招聘、汽车、二手、本地生活等,覆盖58同城主要核心业务场景、千万级DAU,未来将持续深耕搜索排序技术(包括但不限于NLP、知识图谱、机器学习、深度学习等),进一步拓展业务宽度及深度,提升用户体验。
欢迎NLP、搜索排序相关算法同学加入,发挥才能共同成长,简历可发至邮箱:luke@58.com
参考文献
[1] https://mp.weixin.qq.com/s/cMyXnqKbemt4kBpLMgl8GA
[2] Zhou G, Mou N, Fan Y, et al. Deep interest evolution network for click-through rate prediction[C]//Proceedings of the AAAI conference on artificial intelligence. 2019, 33(01): 5941-5948.
[3] Ma X, Zhao L, Huang G, et al. Entire space multi-task model: An effective approach for estimating post-click conversion rate[C]//The 41st International
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%8A%80%E6%9C%AF%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E6%8E%92%E5%BA%8F%E5%9C%A8%E6%8B%9B%E8%81%98%E6%90%9C%E7%B4%A2%E5%9C%BA%E6%99%AF%E7%9A%84%E6%BC%94%E8%BF%9B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


