搜索引擎新架构与不得不说的故事

阿里巴巴搜索引擎HA3架构
1.HA3架构分为在线和离线两部分
- 在线是一个传统的2层服务架构,分别叫做QRS和search。QRS负责接受用户请求,做一些简单处理之后把请求发给下面的search节点,search节点负责加载索引并完成检索,最终由QRS汇集各个search节点的结果并返回给用户。
- 离线部分分为两个环节,一个环节是数据的预处理,其核心的工作是把业务和算法维度的数据加工成对索引友好的大宽表,另一个环节是索引的构建,它的主要挑战是既要支持大规模的索引更新,也要保障索引是实时性。
2.HA3的特点主要有三个:
- 第一个是高性能的服务架构;
- 第二个是丰富的索引能力;
- 第三个是金字塔形的算法工作框架
这些特点是HA3在阿里巴巴集团内风靡非常有利的武器,但随着这几年业务的发展,这一架构逐渐成了我们再往前进一步的拦路虎。
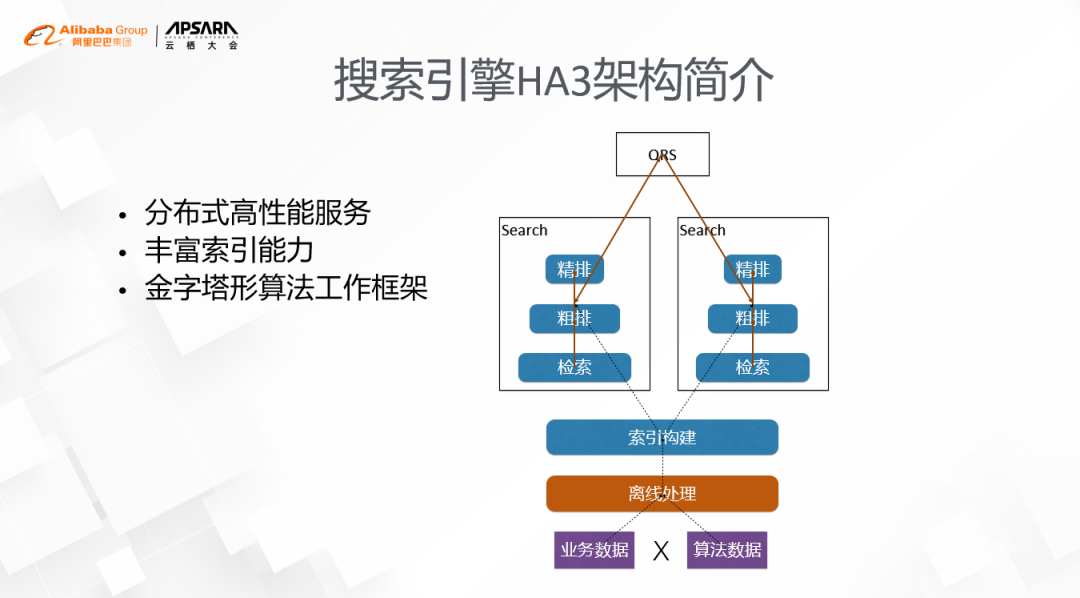
搜索引擎HA3核心挑战
具体体现在2个方面,一个是深度学习的渗透,另一个是数据维度的膨胀。
1. 深度学习
它的使用范围,从早期的精排,逐步扩散到了粗排、检索,比如向量索引的召回。深度学习的引入本身也会带来2个问题:一个是深度模型的本身的网络结构通常比较复杂,对执行流程和模型大小都有非常高的要求,传统的pipeline工作模式是非常难以有效支持的;另外一个问题是模型和特征数据的实时更新也对索引的能力提出了很大的挑战,在线上百亿级别的更新是一个常态。
2. 数据维度的膨胀
以电商领域为例,原来考虑的维度主要是买家、卖家这两个维度,现在得考虑位置、配送、门店、履约等等,同样是配送,有3公里5公里送的,有同城的,还有跨城的,像这样的例子还有很多。而搜索引擎离线的工作流程会把各个维度的数据join成一张大宽表,这会导致数据更新的规模成笛卡尔积的形式展开,在新场景下,无论是更新的量级还是时效性上都很难满足
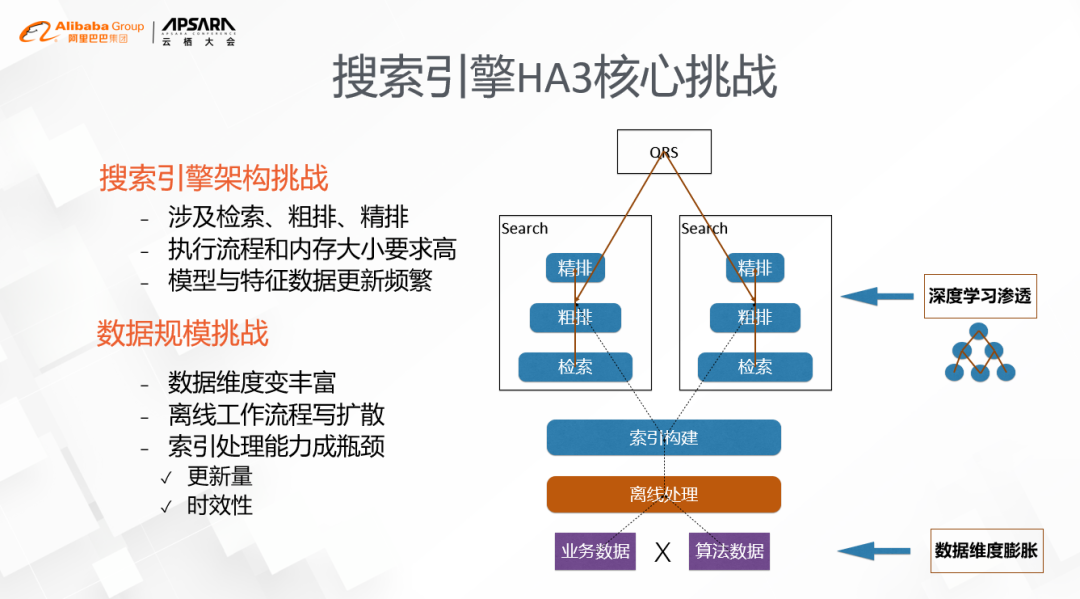
搜索传统解决方案
就是根据业务数据维度的特点,把引擎分拆成过多个不同的实例,然后在业务层通过查询不同的引擎实例来得到结果。比如说饿了么的搜索引擎就有门店、商品等维度的数据,为了解决门店状态的实时变化对索引的冲击,可以部署两个搜索引擎实例,一个用来搜索合适的门店,另外一个用来搜索合适的商品,由业务方先查门店引擎再查商品引擎来完成。但这个方案有一个明显的缺点,那就是符合用户意图的门店非常多的时候,门店的数据需要从门店引擎序列化到业务方再发送给商品引擎,这里序列化的开销非常大,往往需要对返回的门店数目做一定截断,而截断的门店中很可能有更匹配用户意图的,这样对业务效果也会有比较大的影响。特别热门的商区,不管是对用户还是卖家,都是非常大的损失。
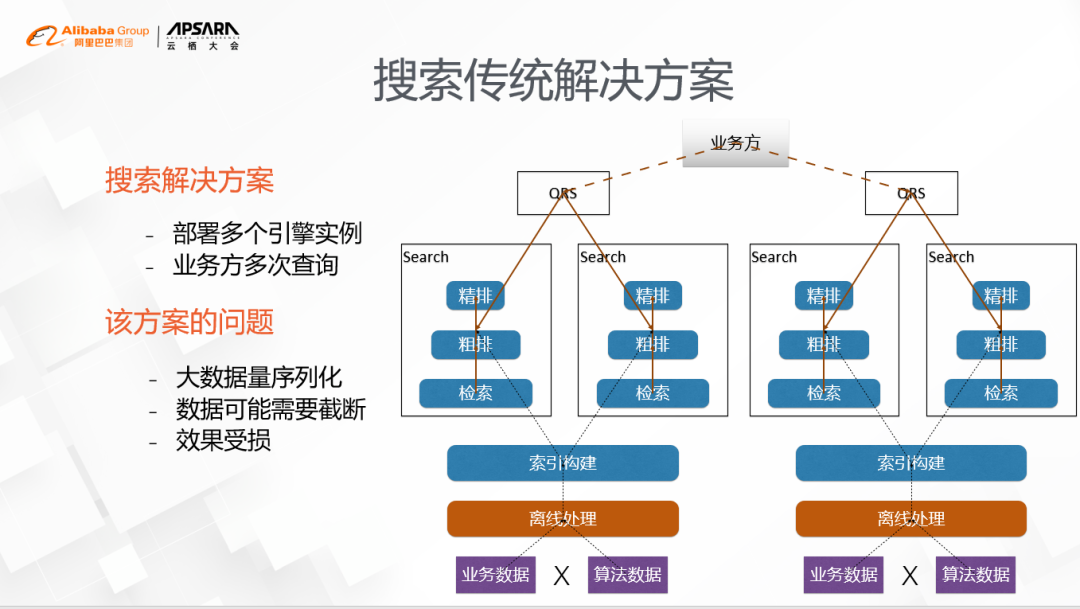
HA3 SQL新的解决方案
以数据库SQL的执行方式来重塑搜索,核心要点有3条。
1.将原来大宽表的模式扩展,成支持多表,每个表的索引加载、更新、切换做到相互独立,把原来需要离线join的操作变成在线查询时join。
2.彻底抛弃原有的pipeline的工作模式,以DAG图化的方式来执行,并将搜索的功能抽象成一个个独立的算子,与深度学习的执行引擎进行统一。
3.以SQL的方式来表达图化的查询流程,这样不光用户使用起来简单,也可以复用SQL生态的一些基础功能。举个例子,电商个性化搜索技术里面,把商品、个性化推荐、深度模型等信息分别放到不同的表中,配合上灵活的索引格式,比如倒排索引、正排索引、KV索引等等,加上执行引擎本身可以支持并行、异步、编译优化等技术,不管是内存还是CPU都能得到有效利用,很轻松地就能解决业务上的各种问题。
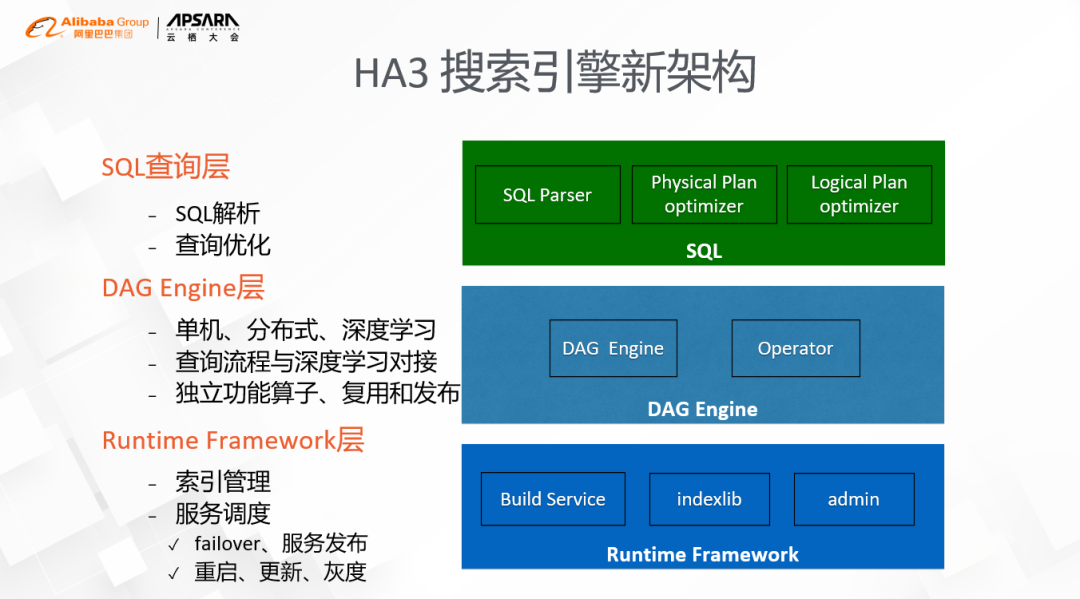
搜索引擎HA3新的架构
主要分为三层:
- 最底下一层是searchRuntime的Framework,其核心职责主要有索引管理和服务调度,其中索引部分主要是加载的策略和查询接口,如计算存储分离的支持、实时索引构建的支持等等;服务调度主要处理的是进程的failover和服务的更新,即通常意义的面向终态的二层调度,主要的特点是以统一的方式做进程的重启、程序的更新、灰度的发布等等。
- 中间这一层是DAG引擎层,其核心内容有两个,一个是执行引擎本身,另一个就是算子。这里的执行引擎主要有三部分的能力,包括单机内图的执行,分布式的通信和深度学习,通过算子间的互联,我们能够很方便的把搜索的查询流程和深度学习进行对接,实现深度学习在搜索的各个阶段的渗透,如向量检索、粗排和精排。算子部分的抽象是这轮架构抽象最重要的一环,把原来面向过程式的开发变成了独立功能的开发,一方面要求算子本身的功能要尽可能内聚,另一方面算子级别的管理也更有利于功能的复用和发布。
- 最上面一层是SQL查询层,核心的工作有两部分,一个是SQL解析,另外一个是查询优化。由于DAG的流程可以任意定制,如何让用户更方便地构建图、更方便的进行算子间的协作会是很关键的问题,简单、通用是个必须考虑的,这也是我们首选SQL的原因;另外一个原因是业界SQL的执行器,通常包含逻辑优化和物理优化两个环节,这个对一个复杂的DAG的执行提供了非常好的抽象,我们也利用了这个机制来进行了很多细致的优化,包括图的变换、算子合并、编译优化等等。
实践案例
1. 饿了么
外卖搜索场景的例子,假设用户在搜索框里面输入了一个关键词"牛肉面",搜索引擎后台的流程大体如下:通过用户的位置信息找到现在还在营业的、并且能卖牛肉面的门店,每个门店给出最匹配的商品,最后返回最符合用户需求的门店与商品。在这里,门店营业情况如何、配送能力是否足够、对应的商品有没有卖完,这些数据都需要实时更新的,而在大规模的数据里面快速找到匹配的信息,也涉及到丰富的索引技术,比如空间索引、倒排索引、向量索引等等,最后门店和商品的排序也要依赖深度模型的参与,用户的偏好、优惠信息、距离都是很重要的因素。原有的搜索流程是基于elasticsearch通过分别查询门店和商品维度的表来实现的,但会有查询结果截断和深度学习接入困难的问题,而在HA3上这些问题都非常容易解决,迁移到新架构后,不光业务的长尾问题消失了,而且性能还提升1倍,给后续算法的迭代留下了非常大的空间,这里性能的提升主要来自于索引结构和查询优化上的一些工作。
2.淘宝本地生活的服务
其核心的诉求也是希望在淘宝的搜索里面引入本地服务的概念,如天猫超市和盒马的小时达的业务,通过将门店和商品维度的数据单独分拆,不光更
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%90%9C%E7%B4%A2%E5%BC%95%E6%93%8E%E6%96%B0%E6%9E%B6%E6%9E%84%E4%B8%8E%E4%B8%8D%E5%BE%97%E4%B8%8D%E8%AF%B4%E7%9A%84%E6%95%85%E4%BA%8B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


