搜索性能优化实践单机提升
作者: 韦子扬 录信数软
随着互联网的快速发展,网络上的数据也在不断增多,各类文章、图片、视频都充斥于各类网站和应用程序之中,用户如果想要在这些海量的信息中寻找和获取自身所喜爱的内容,就会需要使用搜索的功能。而面对这样海量复杂的数据,传统数据库搜索无法实现 快速的响应和模糊搜索,一般针对这种情况都会采用全文检索技术,而Elasticsearch(以下简写为ES)和Solr就是目前最常用的全文检索引擎。
而对于搜索引擎而言,查询的响应速度是最为重要,也是最直观会被用户所感知的。本次针对于新闻搜索场景的ES优化,实现了将单机QPS是从8/s升到108/s,提升了120%,并且通过优化节约了30%服务器成本。
下面,enjoy:
项目优化背景
该项目为一个企业舆情监测系统,通过监测企业的各类公开信息和新闻来帮助用户快速了解企业动态,掌握企业舆情走向。而用户所操作的最多的一个核心功能就是搜索,囊括了新闻搜索、事件搜索、公司搜索。其中新闻搜索由于更新频率快、时效性强,因此数据量最大,也是最容易被用户感知到“速度慢”、“卡”、“转不动”的一个模块。
因此,本次优化的核心背景就是舆情系统的新闻搜索速度慢,QPS过低,具体可以参考下图:

本次测试是在单机情况下进行的,采用的测试工具是k6,测试方法是通过发起10个线程模拟10个用户的并发请求,观察10分钟内的处理请求数。
通过测试显示,新闻搜索的单机服务器QPS为8.9/s。由于是单机测试,正式上线后会采用集群,因此正式环境中的QPS肯定会远远大于这个数字。并且由于搜索业务调用比较频繁,QPS小于10会让客户感到明显的卡顿,因此该问题亟需优化。另外公司大量的业务依赖于ES,因此研究如何提升新闻搜索也可以对优化其他类似的业务有启发,例如实体链接、知识图谱包括基础架构部的日志收集ELK等等。

ES优化过程
1.段合并
也就是对ES内部的新闻索引进行 force segment,这是一种非常常见的加速ES查询速度的手段。
(1)原理
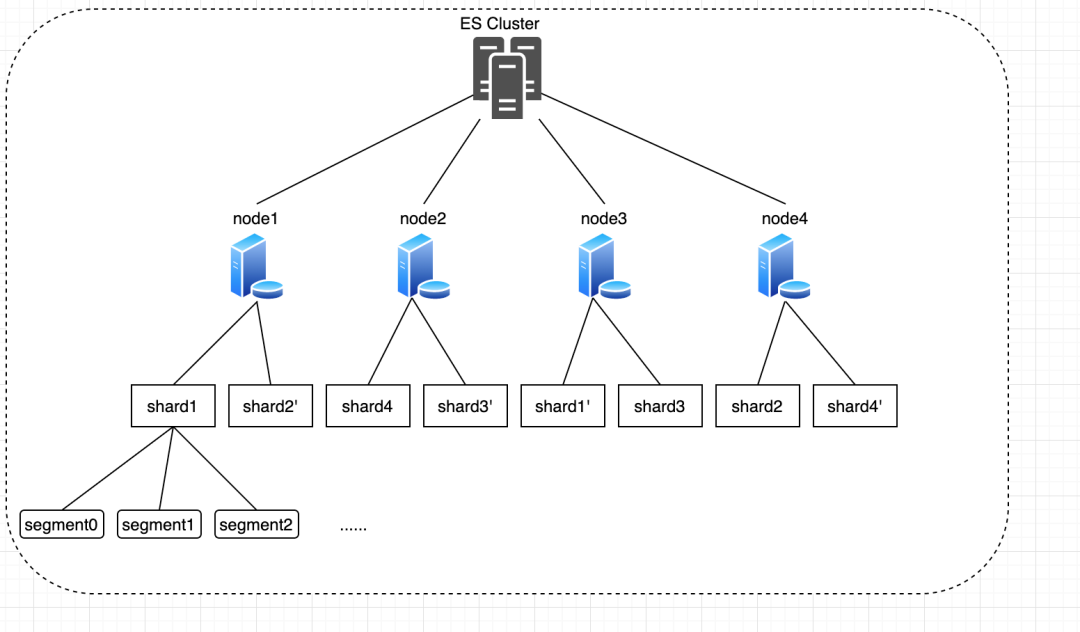
一个index的所有数据在一个集群中是分布在不同的nodes上的,而一个node又是由若干shards来组成的,一个shard就是一个Lucene实例,是一个基本的搜索单元,发送给ES的查询请求,最终会打到所有的Lucene实例中去进行搜索(1个ES的索引有1个或者多个分片 ,分片对应实际存储数据的Lucene的索引),并进行聚合。而对于一个Lucene实例来说,索引文件又是由大量的segments来组成的,每次查询,Lucene实例都会打开所有的segments分段来进行搜索,而打开segments又需要维持响应数量的文件句柄、上下文环境等,所以底层的segments的数量会影响到搜索效率,大量的小segment会严重拖慢搜索速度。
这里留一个坑有空来填,就是段合并的原理,为什么每次flush后触发的段合并仍然会有大量的小分段?合并分段会给线上索引带来怎样的影响?其中采用的怎样的算法我会在后面描述。
官方文档参考: Force merge
总结来说,对 冷索引 执行force merge有如下好处:
- 单一的大分段比众多小分段占用磁盘空间要小
- 减少打开的文件句柄
- 加快搜索速度,因为lucene搜索需要检索全部分段
- 单个分段加载到内存时,占用的Memory更小
(2)操作
POST <host>/<index>/_forcemerge?max_num_segments=
(3)效果
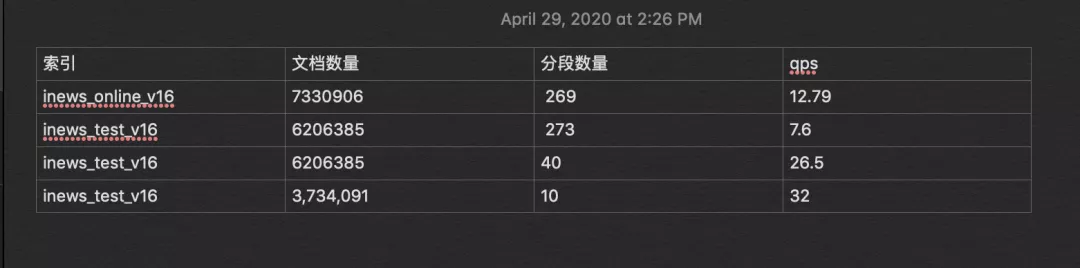
通过段合并,分段数量从269 到10 ,QPS数值提升了大约3倍。
2.使用highlight取代全文
由于在优化时错将pprof的CPU时间当做了实际运行时间,而字符串操作又占据了CPU时间的大头,因此当时就想办法先降低字符串操作的次数。先前采用的是召回阶段直接将整篇新闻内容全部召回给精排算特征用,该方法算的准,但是总共会带来两个问题,一个是IO带来的传输速度慢,粗排阶段总共召回100篇,平均一篇文章5KB左右,总共大约500KB,但如果只召回highliaht部分,可以减少到10KB以下;另外就是文章篇幅长,在算特征的时候,处理时间也会相应地提升。
用highlight取代全文也并不会对搜索结果造成什么影响,因为新闻搜索对新闻的时间特征特别敏感,所以其他内容特征在最后的打分中不起决定作用。
最后QPS的实际提升效果较为一般,服务器QPS大致在32 -> 35,算是有了小幅提升。
3.优化精排
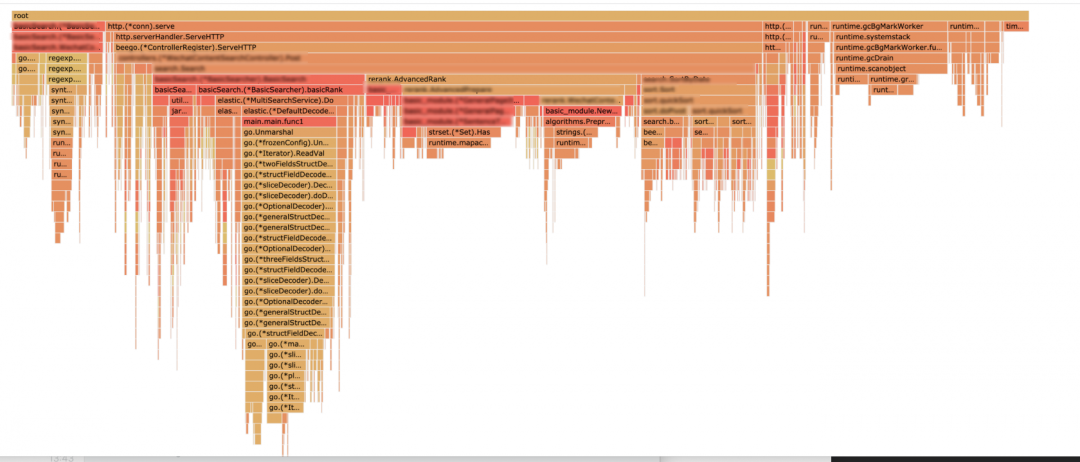
通过如下的PPROF图,我们可以发现,在NewSentence这个函数里面strings.Split 和strings.ToLower占据了很大的比重:

下面分析一下这一步的代码究竟在执行什么:
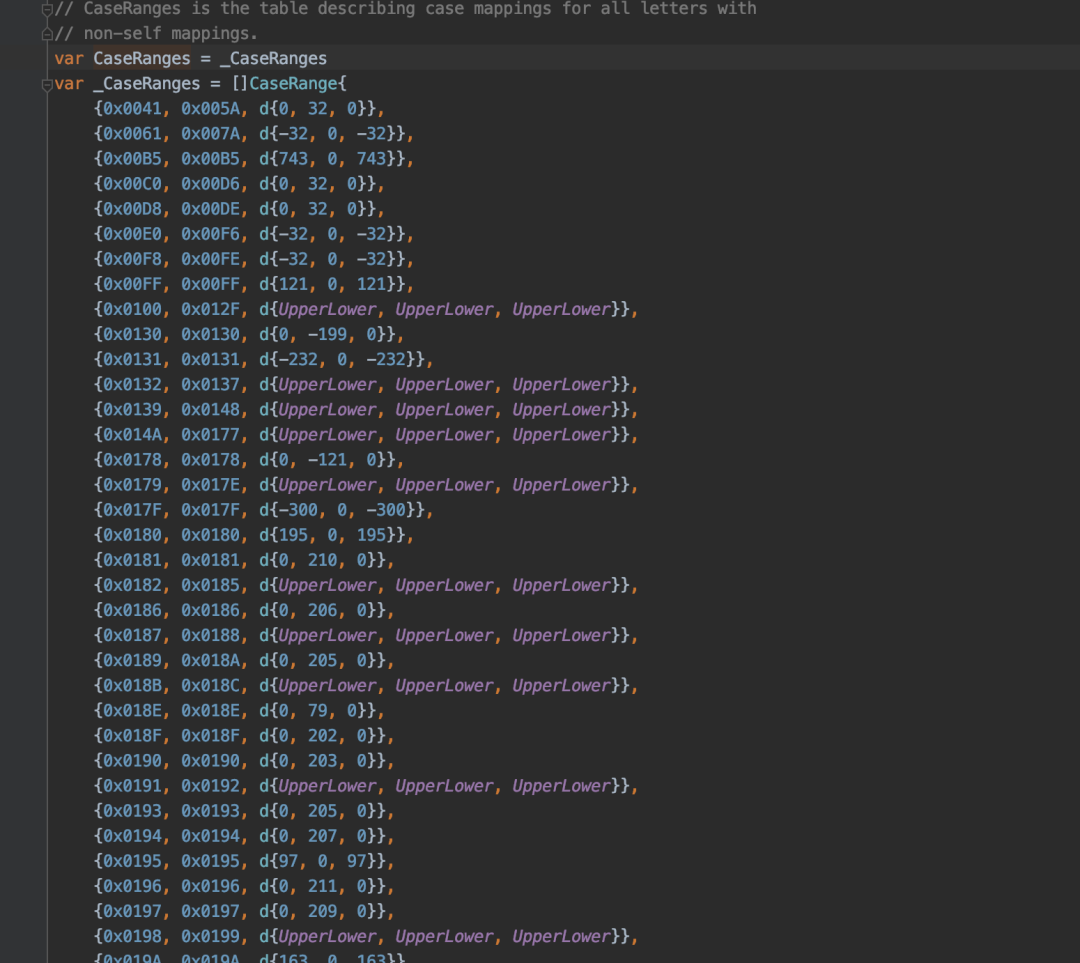
func NewSentence(indexCategory string, field string, text string, k1 float64, b float64, weight float64, id string) *SentenceType {
textBlank := strings.ToLower(strings.Replace(text, "
", "
", -1))
textBlankVec := strings.Split(textBlank, " ")
NonBlankVec := make([]string, 0, len(textBlankVec))
for _, term := range textBlankVec {
if len(term) > 0 {
NonBlankVec = append(NonBlankVec, term)
}
}
length := len(NonBlankVec)
// 涉及公司敏感代码,以下省略
}
这个函数的目的是 根据ES召回的粗排内容生成为精排准备的数据。
函数先把换行符后面加个空格方便分句,然后把字符全部小写,最后按照空格分词。
那么我们有从两个方面可以优化:
第一,ToLower中为什么有map操作?这步在干什么?标准库里的ToLower方法是否干了一些无关操作?
第二,为什么不考虑把上面这些操作结合起来只遍历一遍所有字符呢?
针对第一个问题,我们可以参考golang的ToLower官方实现:
// ToLower returns s with all Unicode letters mapped to their lower case.
func ToLower(s string) string {
isASCII, hasUpper := true, false
for i := 0; i < len(s); i++ {
c := s[i]
if c >= utf8.RuneSelf {
isASCII = false
break
}
hasUpper = hasUpper || ('A' <= c && c <= 'Z')
}
if isASCII { // optimize for ASCII-only strings.
if !hasUpper {
return s
}
var b Builder
b.Grow(len(s))
for i := 0; i < len(s); i++ {
c := s[i]
if 'A' <= c && c <= 'Z' {
c += 'a' - 'A'
}
b.WriteByte(c)
}
return b.String()
}
return Map(unicode.ToLower, s)
}
简单来说,golang为了满足全世界字母的大小写转换,所以当它判定字符串中有非ascii码的时候,就会走Map函数去进行其他语言的大小写转换,比如德语的ä会被转写为Ä,全世界这么多语言有非常多的大小写映射,所以要在内存里面装一个大table 来表示各种语言的大小写映射,而查找字符,则是用的二分法来查找。
而我们恰恰是中文字符,所以每次都会走这个Map,但中文没有大小写区分,所以做了很多无用功。为了规避这一点,就需要自己写Lowercase方法。
对于第二个问题而言,我们只需要把这些操作放在一个方法里面走一次遍历完成Tolower, split, replace操作即可。
// PreprocessText 这步的目的是要把lower replace split 混在一起做加速, split是用空格来做分割, 另外只提取非空字符
func PreprocessText(s string) []string{
result := make([]string, 0, CountSpace(s))
builder := strings.Builder{}
for i:=0;i<len(s);i++{
c := s[i]
if c == ' ' || c == '
'{
if builder.Len() > 0{
result = append(result, builder.String())
}
if c == '
'{
result = append(result, "
")
}
builder = strings.Builder{}
continue
}
if 'A' <= c && c <='Z'{
c += 'a' - 'A'
}
builder.WriteByte(c)
}
if builder.Len() > 0{
result = append(result, builder.String())
}
return result
}
最终的优化效果就是,从CPU耗时上,精排比以前缩减了大约50%。
实际QPS的提升却并不明显,主要原因是引发性能瓶颈的桎梏并不在精排上。但是优化还是有意义的,当需要用golang处理大量文本来实现一些底层函数时可以得到加速,用go bench 来评估一下速度:
BenchmarkOfStandardMethod-8 1000000000 0.000166 ns/op
BenchmarkOfNewMethod-8 1000000000 0.000098 ns/op
第一行是用的标准库实现,第二行是我们自己重写的。理论上性能提升了60%。
4.优化ES query 语句
在保证召回相关度的情况下,用户更希望看到的是近期的数据,总共有两种方法来实现目的:
第一,采用多个date filter来召回数据,并维护一个set保证召回的数据不重复。
具体来说,每个filter都是一个时间段,例如”近3天” ”近7天" “近30天” 这三个filter, 在每个时间段里去取TOP100的数据,最终召回300条数据送到精排。问题在于:即便采用go routine进行并发请求,但根据木桶效应,其速度依然取决于最慢的那个query,如下图显示,其实际处理时间是1.67s,另外还很容易对ES集群造成很大的压力。

第二,采用gaussian decay function。
它其实是在ES打分时,加入了一个function score,考虑其时间因素来进行召回, 但是因为它本质上是个function score,而function score又是个性能杀手,所以当时我们没考虑使用这个。
最终,我们决定通过测试来决定最终采取哪种方式来实现近期数据的召回,我们采用vue为10,并发请求1min来进行测试,下图分别为多date filter qps和Gaussian decay function的测试结果:
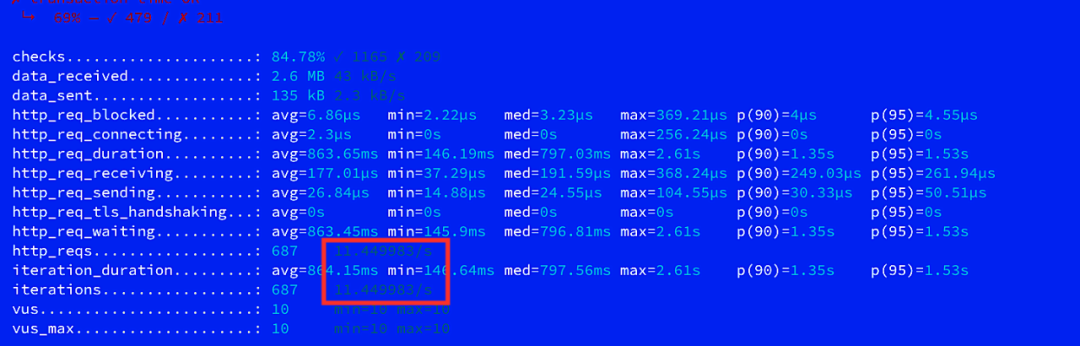
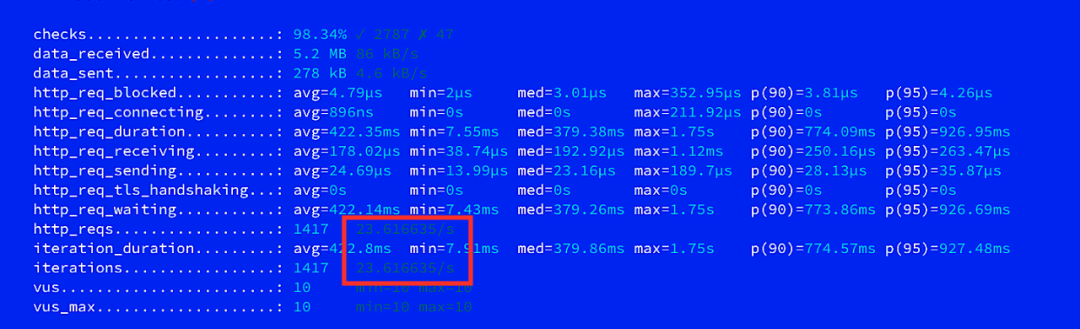
最终测试显示,相比于多date filter qps的方式,Gaussian decay function的QPS要明显高出很多,因此选择Gaussian decay function的方式。
5.自建ES Cluster, 扩大Nodes数量
公司的系统是部署于亚马逊AWS之上,原来使用的AWS 提供一个包含kibana在内的完整开箱即用的ES 集群服务,管理监控起来十分方便。
但AWS的ES Cluster为了安全性等考虑,加入了太多限制,使得机器利用率不高,而且大量API无法使用,包括动态同义词方案,close index, 查看segment具体情况等,从而对优化形成了很大的掣肘。
因此想要更深入地控制ES集群,就必须采取自建ES集群的方式。本来这里是有一个指向公司内网wiki的外链的,由于涉及公司保密问题,因此自建的详细步骤就不在这里说了。
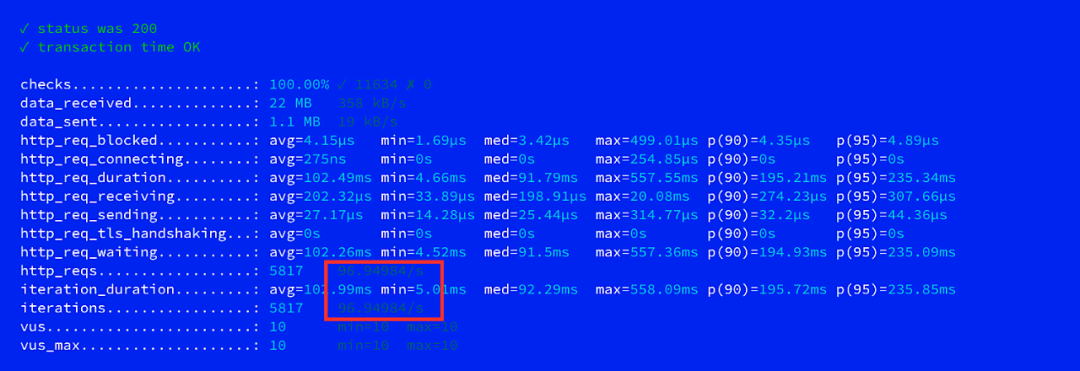
简单来说,在费用降低的情况下提高了机器的配置以及data node 的数量。并且采用了高版本的ES以及Kibana,在成本降低30%的情况下,将QPS 提升到 96/s。
6.优化 shards 数量
关于这个主题,我也是在公司wiki单独有个栏目介绍,所以这里就不放链接了,简而言之,我做了一个对比试验,一个index有10个shards,�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%90%9C%E7%B4%A2%E6%80%A7%E8%83%BD%E4%BC%98%E5%8C%96%E5%AE%9E%E8%B7%B5%E5%8D%95%E6%9C%BA%E6%8F%90%E5%8D%87/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


