搜索相关性算法在中的探索

李明阳 滴滴技术
导读:今天给大家分享的主题是搜索匹配问题在 DiDi Food 中的一些探索与应用。本文首先介绍了搜索相关性的一些背景,之后介绍了业界常见的三种匹配模型,以及在 DiDi Food 业务中的模型效果对比。
匹配模型包括:1. 基于表征 的深度匹配模型;2. 基于交互 的深度匹配模型;3. 同时 基于表征与交互 的深度模型。文章最后会介绍目前搜索匹配算法在 DiDi Food 业务中的一些效果。
一 . 搜索相关性
搜索相关性模型本质上是一个匹配的过程,即用户通过一个具体请求,例如发送一个 **query **来抽取想要得到的信息。搜索引擎就是要将用户的意图与网站的信息做一个匹配来返回给用户。具体到 DiDi Food 的业务场景中就是:用户输入 query 进行搜索后,搜索引擎将与用户 query 匹配的店铺、菜品返回给用户。这个过程可以抽象为一个 query-doc 的语义间隔匹配问题。
▍语义匹配
语义匹配 与传统的 字符匹配 同属于传统的 NLP 文本匹配任务,区别在于语义匹配不一定要求两端文本上存在相同的单词,更关注两段文本在表达意思上是否满足目标任务。
这里通过下表具体解释两者的区别:

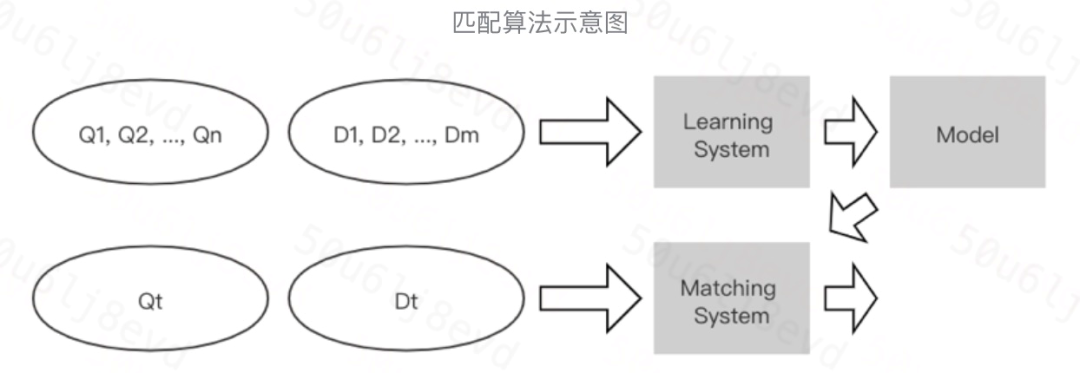
在一般的语义匹配算法中,训练数据为 label 好的 query-doc 关系组。目标函数为 f(q,d)或 P(r|q,d),分别对应判别模型和生成模型。query 和 doc 一般通过对应的特征向量或 one-hot-id。label 可以是[0,1]这样的离散值,也可以是连续的数值得分。
▍Matching vs. Ranking
在一般的搜索与推荐任务中,目前业界主流的做法都是根据业务目标将其拆解为 匹配问题(很多称为召回问题)和排序问题。
在搜索中,匹配问题的目标通常是要解决 query-doc 的相关性, 即 query-doc 的语义间隔问题。它的输入往往是 query 和某一特定的 doc。 Matching 的难点在于找到正确的匹配 case,剔除错误的匹配 case。
排序问题的目标通常是要解决列表序的问题。它的输入往往是一系列的 doc。 Ranking 的难点在于将正确或转化率高的元素放到列表的头部。
在 DiDi Food 的业务场景中也根据匹配与排序问题的不同分为策略粗排与策略精排两部分。
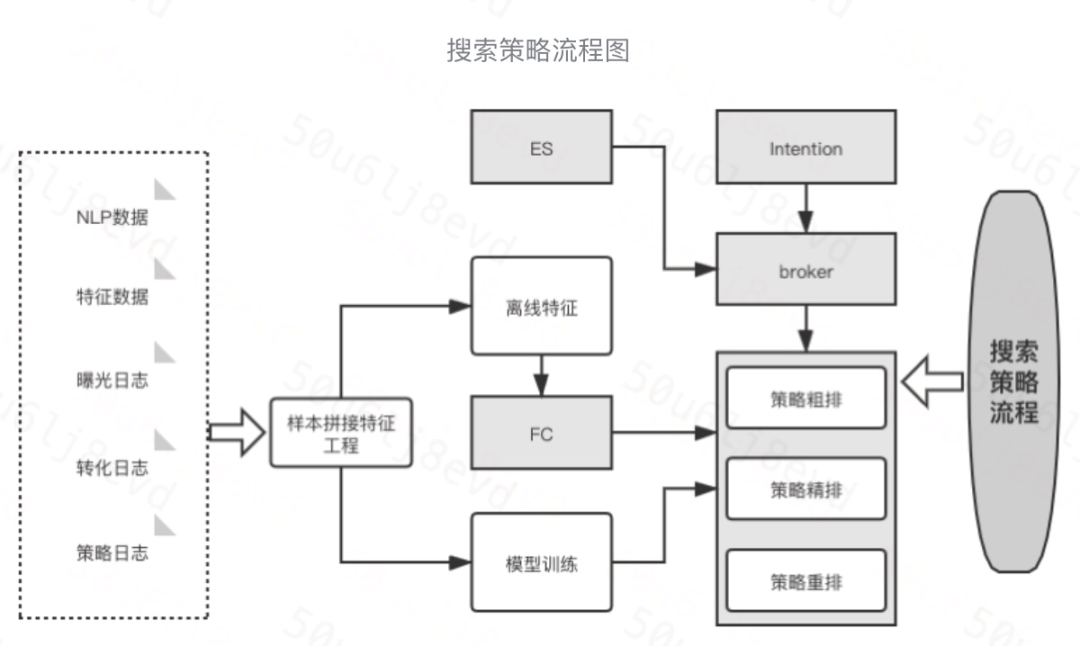
- 通过意图模块对用户的意图进行分析,其中包括 query 纠错、同近义词扩展等。
- broker 通过 ES 将店带菜进行召回,策略对所有召回店带菜做搜索粗排,这里属于匹配算法,目标找到相关性较高的店带菜。
- 将粗排结果的 top N 个店带菜做搜索精排,这里属于转化率模型,目标提高用户的下单转化。
- 对店带菜做搜索重排,这里主要包括一些产品规则等,最后将结果透传回 broker
二 .深度匹配算法

相较于传统的匹配算法,例如 TF-IDF, LSA, BM25 等,DiDi Food 在搜索场景中探索了业界主流的几种深度模型。我们把常见的用于匹配的深度学习模型分为三类,包括:基于 representation 表征的深度模型,基于 interaction 交互的深度模型以及同时基于表征与交互的深度模型。
为方便后文介绍,这里先区别以下几个概念:
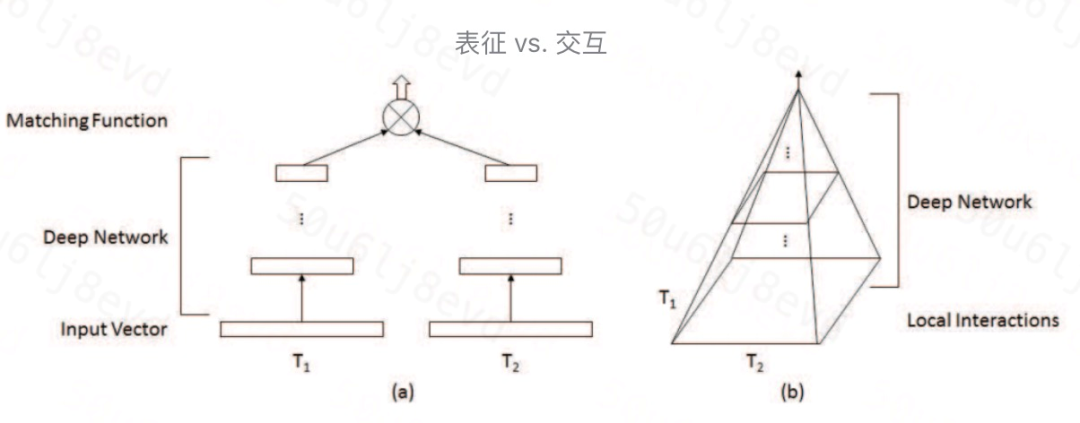
1. Representation vs. Interaction
Match(T1, T2)=F(Φ(T1), Φ(T2))
-
Representation based
学习文本的表征,可以提前把文本的 语义向量 计算好,在线预测时不用实时计算。在学习出文本向量前,两者没有任何交互,可能导致细粒度匹配信号丢失。同时两个文本的向量可能属于不同的向量空间,需要通过上层的融合层和 loss 拉进两个向量间的距离。
F 函数为一个复杂的表征函数,Φ是一个简单的打分函数。
-
Interaction based
通过 局部交互矩阵 保留有细粒度、精细化的匹配信号,上层使用更大粒度的 pattern 进行匹配信息提取,同时该类模型的可解释性更好。缺点在于一般此类模型的在线计算代价更大。F 函数为一个简单的映射函数,Φ是一个复杂的深度模型函数。
2. Similarity vs. Relevance

- Simiarity:通常是判断两个同质的文本的语义、意思是否相似,其匹配函数是对称的,代表任务有 NLP 的同义句识别。
- Relevance:通常是判断两个不同质的文本(query 与 doc)是否相关,其匹配函数是不对称的,代表任务有搜索网页检索。
3. Global vs. Local
- Global Distribution:从全局匹配更偏向 语义 上的匹配
- Local Context:从局部匹配更偏向 字符 上的匹配
4. Exact Term Matches vs. Inexact Term Matches vs. Term Position Matches
- Exact Term Matches:传统的 IR 模型(例如 BM25 算法)是基于 query 和 doc 的精确匹配计数计算的,它们可以在最少甚至没有训练数据的情况下使用,可以直接用于新任务或语料库。
- Inexact Term Matches:query 和 doc 之间的非精确匹配是指利用嵌入空间学习 term 语义进行匹配的技术。
- Term Position Matches:query 和 doc 中 term 的匹配位置不仅反映文档的潜在相关部分所在位置(例如标题、段首等),而且还反映了 query 各个 term 匹配彼此的聚合程度。

上方左图说 case 为当 query 为 president of united states 时,exact term matches 和 inexact term matches 的匹配效果(绿色越深表明匹配程度越高);
上方右图说明当 query term 在 doc 中的匹配位置较为集中时相关性才高,当匹配位置相距较远或较分散时说明匹配程度很低。
▍Representation Based Model
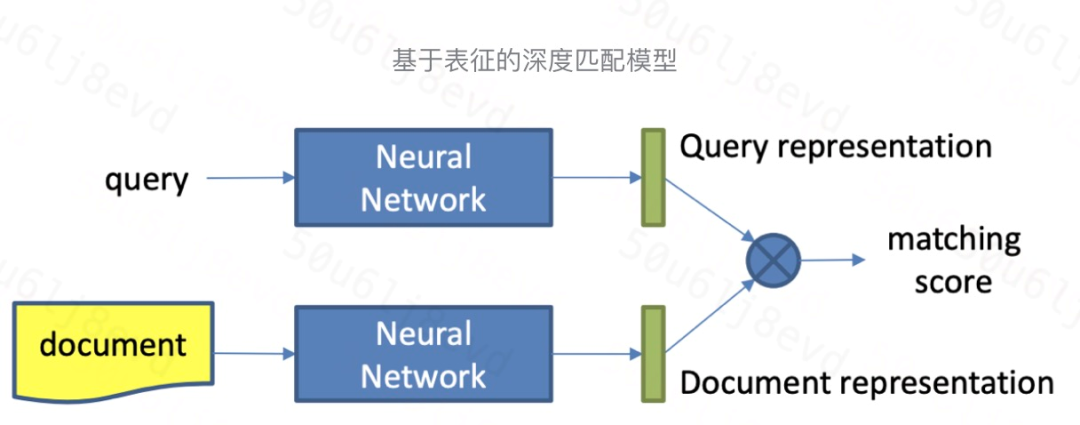
基于表征的深度匹配模型基本结构如图所示,一般分为两步:
- 计算 query 和 doc 的 representation
- 对两者的 representation 进行 matching 计算
我们以 DSSM 模型为例。
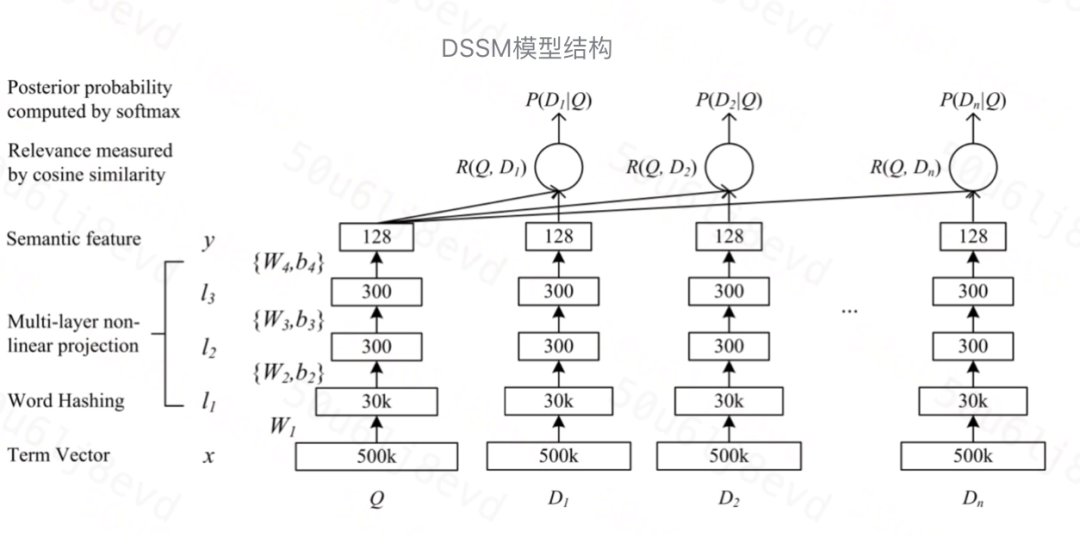
输入层
输入层是把文本映射到一个向量空间里并输入到 DNN 中,这里英文和中文的处理方式有很大不同。
英文的出入层处理方式是通过 **word hashing **方式。通常是用 **letter-trigrams **来切分单词(3 个字母为一组,#表示开始和结束符)。
**例如 boy 这个单词,会被切为 #bo,boy,oy#**
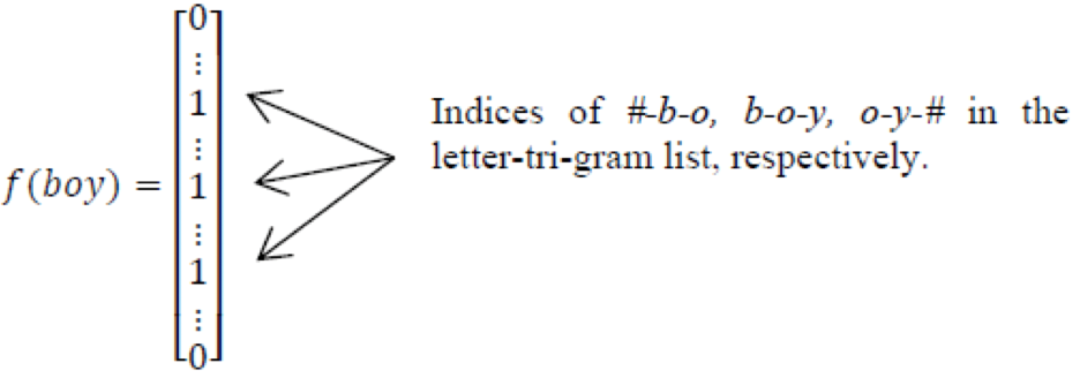
word hashing 的好处有两个:
- 压缩空间:50 万个单词的 one-hot 向量空间可以通过 letter-trigrams 压缩为一个 3 万维的向量空间。
- 增强泛化能力:三个字母的表达往往能代表英文中的前缀和后缀,而前后缀往往具有通用的语义。
除此之外,之所以选择 3 个字母的切分粒度,是综合考虑了向量空间和单词冲突。
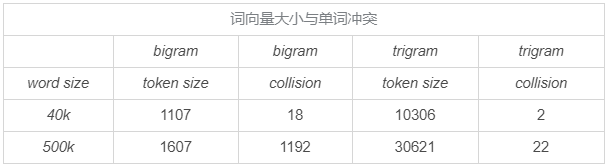
中文的分词是 NLP 领域的难题,准确度往往难以满足要求。所以对于中文的处理方式是不做分词处理,直接以单字作为最小粒度。
常用单字数量为 1.5 万左右,而双字的话大约到百万级了,所以这里出于向量空间的考虑,采用单字向量即(one-hot)作为输入,向量空间约 1.5 万维左右。
表示层
DSSM 的表示层采用 **BOW(bag of words)**的方式,相当于把字向量的位置信息抛弃了,整个句子的词都放在了一个袋子里,不分先后顺序。这样做会损失一定信息,后续的 **CNN-DSSM 和 LSTM-DSSM **可以在一定程度上解决这个问题。紧接着是一个含有多个隐藏层的 DNN。
用 Wi 表示第 i 层的权值矩阵,用 bi 表示第 i 层的偏置项,则可以得到下面公式。
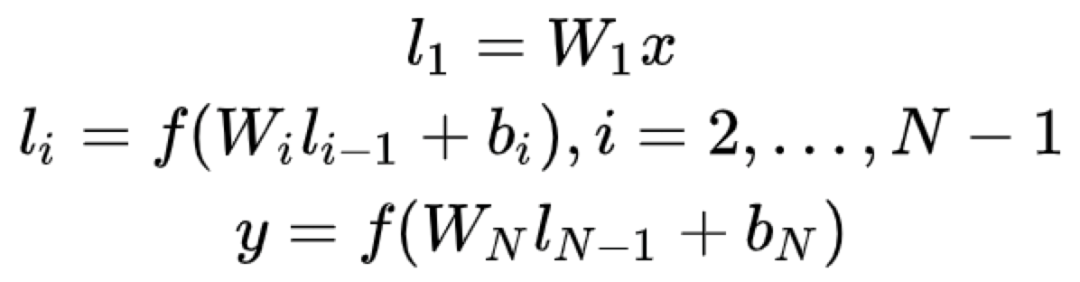
用 tanh 作为隐藏层和输出层的激活函数,最终输出一个 128 维的低维语义向量。
匹配层
query 和 doc 的语义相似性可以用这两个语义向量(128 维)的 cosine 距离,即余弦相似度来表示。
通过 softmax 函数可以把 query 与证样本 doc 的语义相似性转化为一个后验概率。
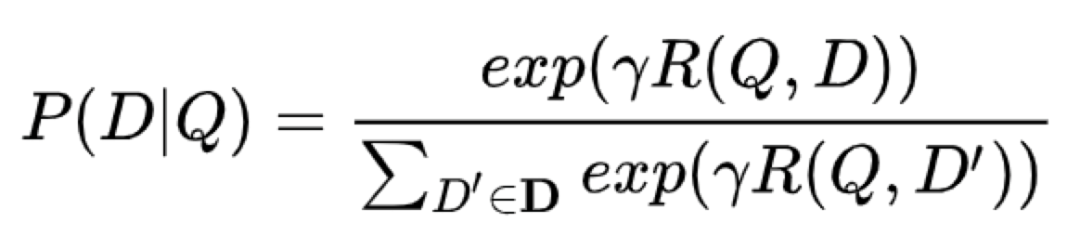
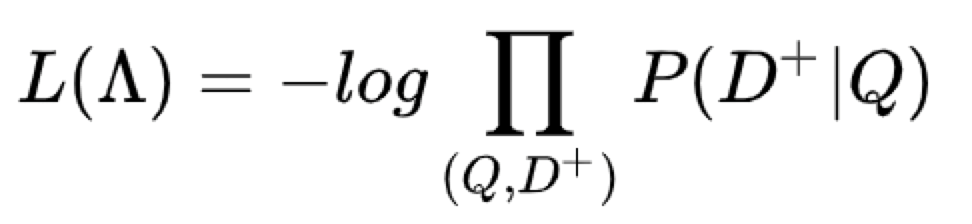
其中,γ 为 softmax 的平滑因子。在训练阶段,通过极大似然估计,我们最小化损失函数。
▍Interaction Based Model
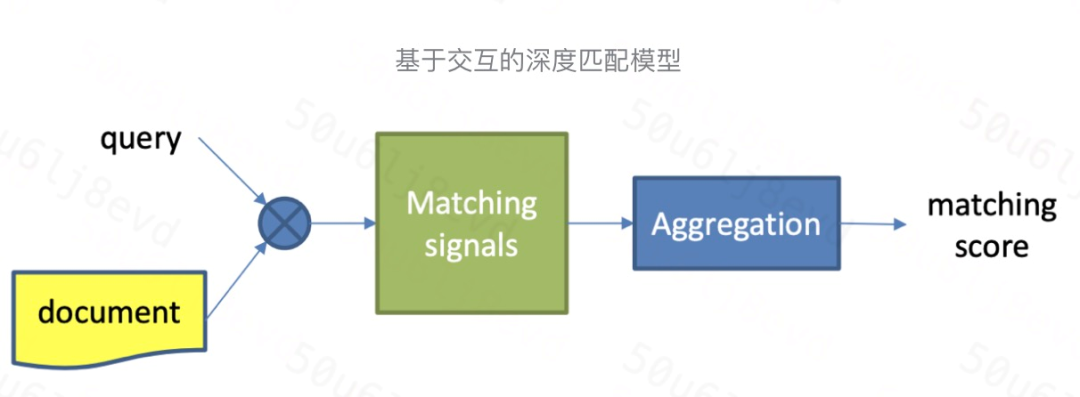
基于交互的深度匹配模型基本结构如图所示,一般分为两步:
- 建立基本的底层匹配信号
- 根据底层匹配信号提取匹配 pattern
我们以 DRMM 模型 为例。
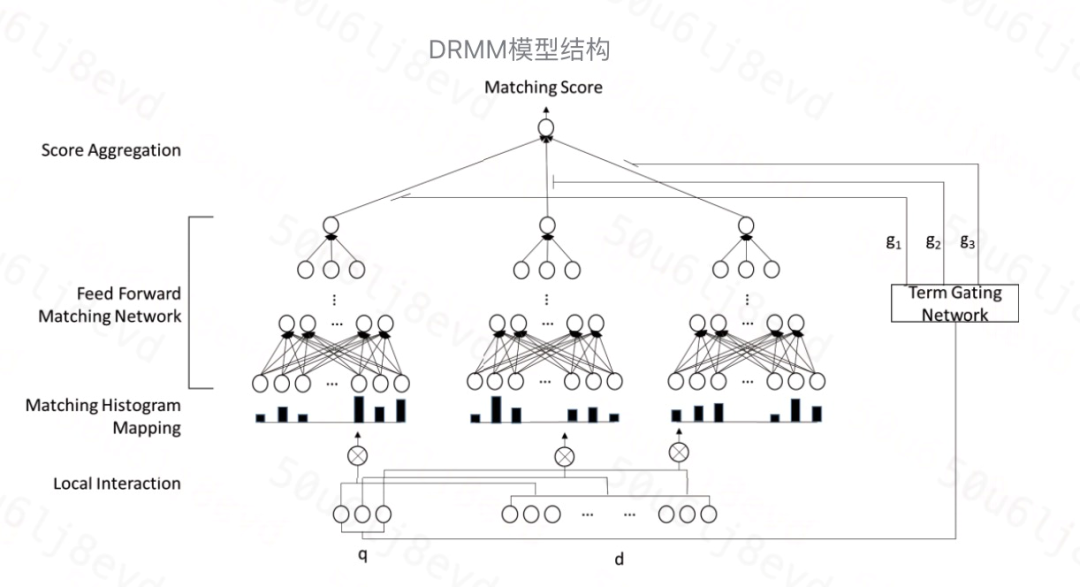
输入层
query 和 doc 通过预训练好的词向量 q={w1, w2,…,wM},d={w1, w2,…,wN}作为输入。
其中每一个 w 都是一个 t 维的词向量。
局部交互矩阵-匹配直方图

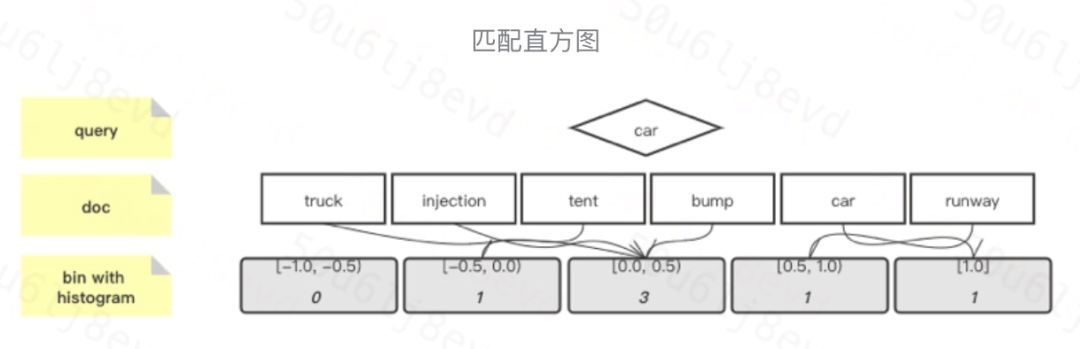
模型首先对 query 和 doc 每个 term 对都建立了局部交互关系。传统的 局部交互矩阵 存在一个重要问题,即 query 和 doc 的长度都是不定的,而模型需要转换成固定长度。除此之外,局部匹配矩阵保留了位置表征,这对于位置敏感的任务非常有效。但 该模型认为在搜索匹配问题中,更关注匹配信号的强度,所以该模型将其转化为匹配直方图。
匹配直方图将两两 term 的相似度根据分桶原理放入不同的桶中。例如 cosine 相似度的取值范围在[-1, 1]之间,所以将 interval 离散化成有序的 bins,对每个 bin 中的局部交互值数量进行累计。本文使用固定大小的 bins,将精确匹配的作为单独的 bin(即匹配分数为 1 的)。
假设 bin 的大小为 0.5,那么可以得到 5 个 bins,即{[-1, -0.5), [-0.5, -0), [0, 0.5), [0.5, 1), [1, 1]}升序排列。给定 query 为 car 以及一个文档(truck, injection, tent, bump, car, runway),对应的余弦相似度分别为(0.2, 0.3, -0.25, 0.4, 1.0, 0.75),可以得到匹配直方图为[0, 1, 3, 1, 1]。
模型尝试了 3 种匹配直方图映射的计数方式
- 基于计数的直方图 CH:最简单的转换方法,直接计算每个 bin 中对应值的数量。
- 归一化直方图 NH:对每个 bin 中的计数值进行归一化(基于总数量),关注不能交互值数量的相对大小。
- 基于计数值对数的直方图 LCH:对每个 bin 中的计数值取对数,同样是为了压缩取值范围,让模型可以更容易学到乘性关系。
隐藏层
模型采用 DNN 作为隐藏层而非与局部交互矩阵对应的 CNN,这样 避免了池化层对于一些细微信号的丢失。
term 门网络
DRMM 采用了基于 query term 级别的联合深度网络,可以清楚地建模 每个 query term 的重要性。这里使用了 term 门网络,计算每个 query term 的聚合权重:
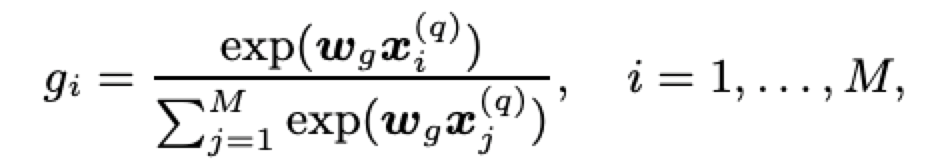
模型尝试了两种不同的输入向量:
- Term Vector (TF):xi(q)表示第 i 个词的词向量,wg 表示同样维度的 term 门网络权重向量。
- 逆文档频率(IDF):IDF 是表征单词重要性的重要信号,这里 xi(q)表示第 i 个单词的 IDF,wg 即为一个常数。
▍Representation & Interaction Based Model
此类模型 融合了基于交互的匹配模型与基于表征的匹配模型的优点, 分为对应的 local model 和 distributed model 两部分。distributed model 在匹配之前将 query 和 doc 文本投影到嵌入空间中;而 local model 在交互矩阵上操作,将每个 query 与每个 doc 进行比较。最终得分是来 local 得分和 distributed 网络的得分之和。
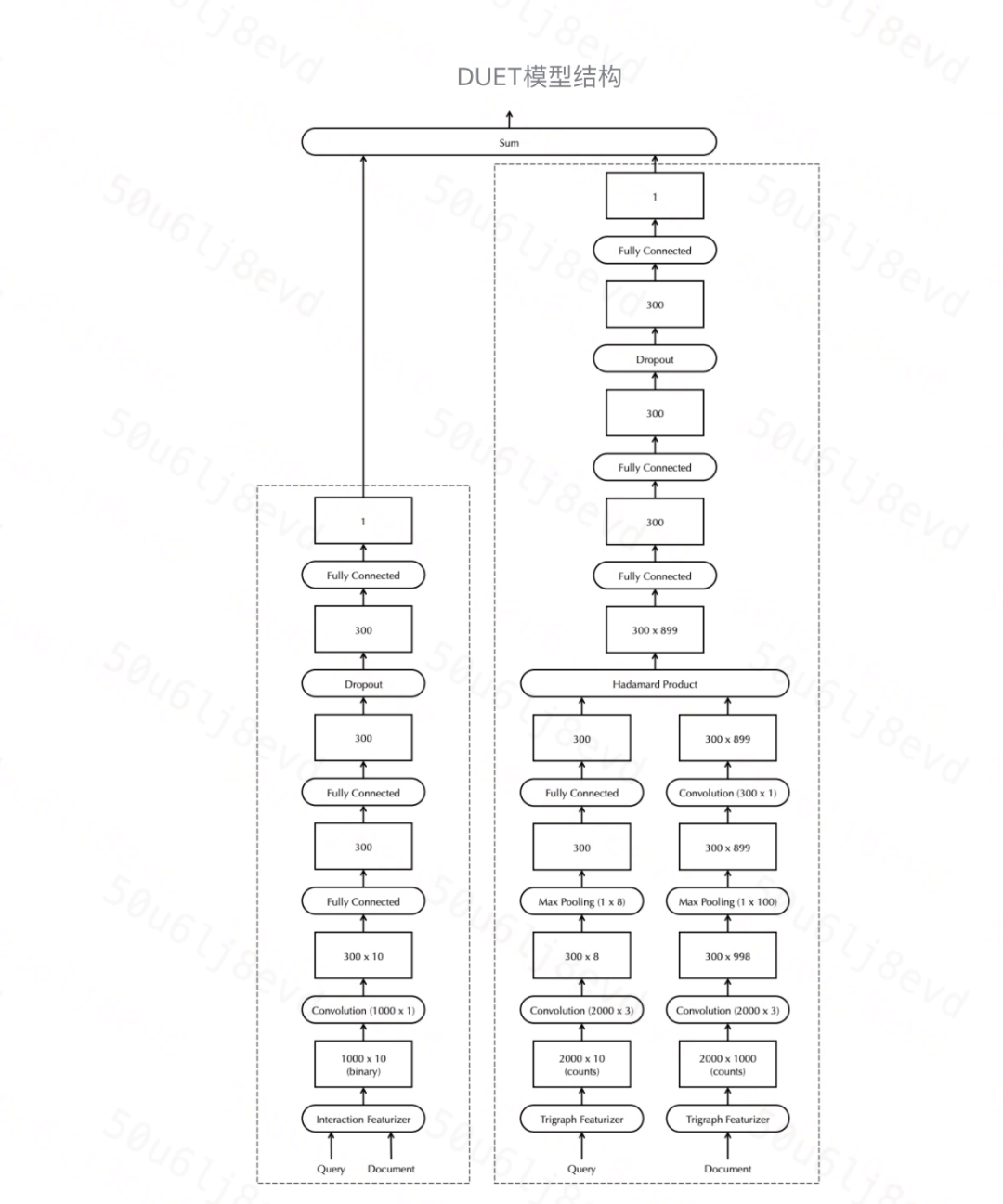
输入层
我们固定所有 query 和 doc 的输入长度,仅考虑 query 中的前 10 个 term Q=[q1, q2, …, q10]和 doc 中的前 1000 个 term D=[d1, d2, …, d1000]。如果 query 或 term 短于这些目标维度,则输入向量用 0 填充。其中,q 和 d 都是 m × 1 的向量。
query 中 term 数 nq;doc 中 term 数 nd。
Local model
Local Model 基于 query term 在 doc 中的精准匹配来衡量 doc 的相关性。每个 term 表达为 one-hot 的向量(m 维,m 为词典大小)。然后,模型生成**局部交互矩阵 **X=D^T × Q,大小为 nd × nq,获取 query term 在 doc 中的每个精确匹配和位置信息。但是 X 不保留 term 本身的信息。因此, Local Model 不能从训练语料中学习 term 的特定属性,也不能对不同 term 之间的交互进行建模。
X 首先经过卷积层,有 c 个 filters,其核大小为 nd × 1(doc 的 term 数),跨距为 1。
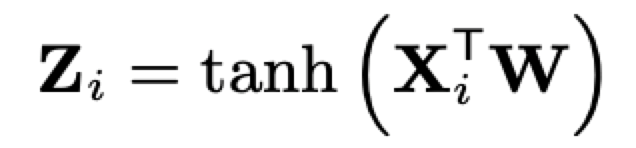
Zi,是 qi 与 doc 中的所有 term 进行匹配的函数的输出。Xi 是局部交互矩阵 X 的第 i 行。W(nd × c 矩阵)是卷积层要学习的参数。Z 的维度为 c × nq。模型使用 c=300 的 filters。卷积层的输出然后通过两个全连接层、drop-out 层、最终的全连接层,得到一个单个的实数值。Local Model 中的所有节点都使用双曲正切作为激活函数进行非线性处理。
Distributed model
Distributed Model 学习 query 和 doc 文本的稠密低维向量表示,然后计算它们在嵌入空间中的相似性。不同于 Local Model 中对 term 进行 one-hot 编码,Distributed Model 用了基于 trigram 的方式对每个 term 进行表示,然后用 trigram 频率矢量来表达这个 term(长度为 md)。
在 distributed 部分中,不直接计算矩阵 Q(md × nq)和矩阵 D(md × nd)的交互,而 对这种基于字符的输入先学习一系列的非线性转换。
对于 query 和 doc,第一步是卷积,md × 3 的卷积窗,filter size 为 300。它将 3 个连续 term 投影到一个 300 维向量,stride 为 1,再投影接下来的 3 个 term,依此类推。其中,对于 query,卷积层生成维数为 300 × 8 的张量;对于 doc,它生成维度 300 × 998。
接下来,是 max-pooling 层。对于 query,池化层的核维数为 1 × 8。对于 doc,维数为 1 × 100。因此,对于 query,得到 300 × 1 的矩阵 Q~。对于 doc,得到 300 × 899 的矩阵 D~。D~可以被解释为 899 个独立的 embedding,每个 embedding 对应于 doc 内不同的相等大小的文本跨度。**该模型选择基于窗口的最大池策略,而不是 CDSSM 采用的全局最大池策略,是因为基于窗口的方法允许模型区分 doc 不同部分中的匹配项。**当处理长文档,尤其是包含许多不同主题的混合文档时,保留匹配位置的模型可能更适用。
query 的最大池化层的输出后续连接全连接层;对于 doc,300 × 899 的维度矩阵输出,由另一卷积层运算(filter size 为 300、kernel size 为 300 × 1、stride 为 1)。 **这些卷积层和最大池层的组合使得 distributed 模型能够学习文本的适当表示,以实�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%90%9C%E7%B4%A2%E7%9B%B8%E5%85%B3%E6%80%A7%E7%AE%97%E6%B3%95%E5%9C%A8%E4%B8%AD%E7%9A%84%E6%8E%A2%E7%B4%A2/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


