新东方在线教育实时数仓的落地实践

以下文章来源于ApacheDoris ,作者ApacheDoris
背景介绍
在传统数据仓库方面,通常以 T+1 离线批量计算为主,按照数仓建模方式,把要处理的业务按照主题域划分,构建各种数据模型,来满足公司经营分析,财务分析等各种公司管理层的数据需求。
然而,随着在线教育快速发展市场竞争非常激烈,T+1 的方式在某些需求上很难对业务产生实际的价值,很可能因为数据延迟导致业务动作滞后,管理要求跟进不及时,最终导致客户流失,影响公司业务发展。
目前我们遇到的主要痛点如下:
- 续费业务场景: 在线教育上课主要分为 4 个时段(春季,暑假,秋季,寒假)。当每一个时段上课要结束的时候,就会有一个续费周期,每个学科每个班级续费率的高低直接影响公司是否盈利的问题。所以实时的观测每个学科每个班级每个学科负责人每个教学负责人的续费率完成情况就显得尤为重要。
- 直播行课场景: 分析课中学员与老师互动行为,其中包含实时的连麦、发言、红包等行为数据,同时分析学员实时到课、完课、考试等数据对于管理学员和调整老师动作有重要的指导意义。
- 销售场景 :监控新线索的实时分配,以及后续销售外呼频次、外呼时长,统计销售线索覆盖量,外呼覆盖量等指标。通过分析销售对于学员的跟进与转化数据,对比个人和团队当日人次和金额达成目标,指导运营管理动作。
- 算法线索分场景 :每当进行广告投放的时候,针对每一个销售线索给出一个评分值,来评估这个线索可能转化的高低,利于销售人员更好的跟进,提高转化率。
实时数仓技术架构
01 实时数仓选型
在 2020 年以前公司实时数据部分,主要由小时级和分钟级的支持。小时级部分使用基于 Hive/Spark 的小时级任务方案,分钟级使用 Spark-Streaming 方案。
- 基于 Hive/Spark 小时级方案虽然能满足快速响应业务需求和变化的特点,但延迟性还是很高,并且大量的小时任务对集群计算资源有很大压力,很有可能导致这一批小时任务根本跑不完。
- 分钟级 Spark-Streaming 方案,能够满足数据时效性需求,但采用纯代码方式来开发,无法满足快速变化的数据需求
基于此,我们开始调研业界方案,目前业界有主要有两种实时数仓方案,分别是实时数仓方案和准实时数仓方案。
02 实时数仓方案
实时数仓方案分别可以采用 Lambda 架构和 Kappa 架构。
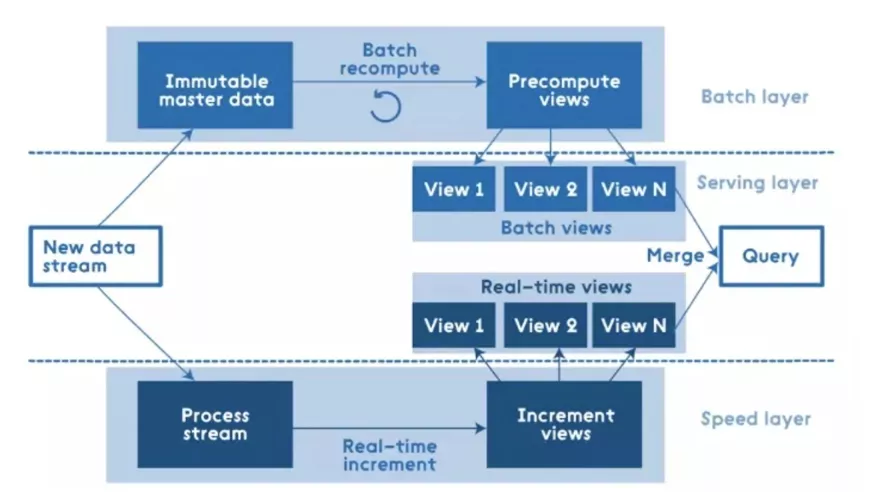
Lambda 架构
如上图所示例,Lambda 架构存在离线和实时两条链路,实时部分以消息队列的方式实时增量消费,一般以 Flink 和 Kafka 的组合实现,维度表存在 MySQL 数据库或者 Hbase ;离线部分一般采用 T+1 周期调度分析历史存量数据,每天凌晨产出,更新覆盖前一天的结果数据,计算引擎通常会选择 Hive ,优点是数据准确度高,出错后容易修复数据;缺点是架构复杂,运维成本高。
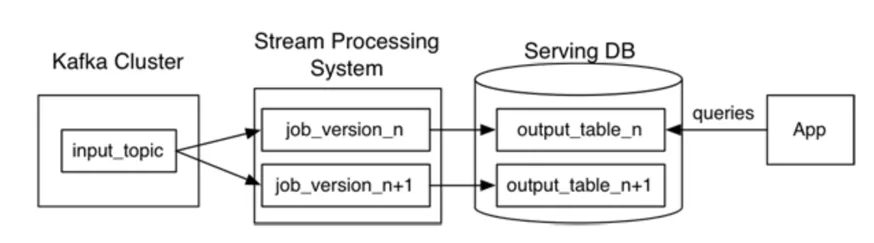
Kappa 架构
Kappa 架构是由 LinkedIn 的 Jay Kreps 提出的(参考 Paper: https://www.oreilly.com/radar/questioning-the-lambda-architecture/ ),作为 Lambda 方案的一个简化版,它移除了离线生产链路,思路是通过在 Kafka 里保存全量历史数据,当需要历史计算的时候,就启动一个任务从头开始消费数据。优点是架构相对简化,数据来源单一,共用一套代码,开发效率高;缺点是必须要求消息队列中保存了存量数据,而且主要业务逻辑在计算层,比较消耗内存计算资源。
但由于之前流处理系统本身不成熟,对窗口计算、事件时间、乱序问题和 SQL 支持上的不成熟,导致大部分公司普遍采用 Lambda 架构方案。但自从 2020 年 2 月 11 日,Flink 发布了 1.10 以及随后的 1.11 版本,引入了 Blink Planner 和 Hive 集成极大地增强了对于 SQL 和流批一体支持,这为真正实现 Kappa 架构带来了一丝希望。
03 准实时数仓方案
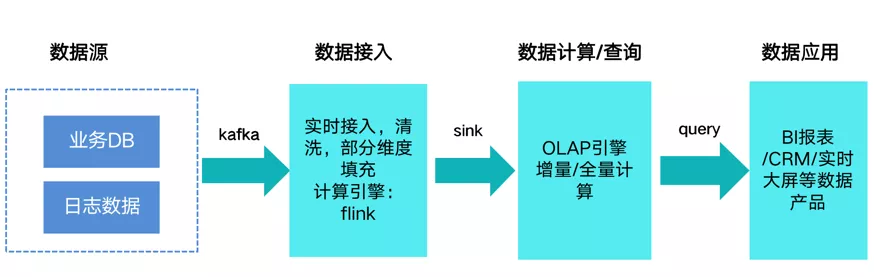
准实时数仓方案
其核心思路是,采用 OLAP 引擎来解决聚合计算和明细数据查询问题,配合分钟级别调度(一般是 30 或者 15 分钟)能力来支持业务实时数据需求。该架构优点是:
- 一般 OLAP 引擎都对 SQL 的支持度很好,开发成本极低少量人员都可以支持复杂的业务需求,灵活应对业务变化。对于差钱的公司来说无疑非常节约成本的(财大气粗的公司除外);
- 对于数据修复成本低,因为可以基于一个周期内的数据进行全量计算,所以修复数据只需要重跑任务即可;
- 对于运维成本也较低,只需要监控任务运行成功失败即可;
- 对于数据时效性要求较高的场景,配合 Flink 实时计算能力,在数据接入的时候进行部分聚合计算,之后再把结果写入 OLAP 引擎,不需要再配合调度计算,以此来到达秒级延迟。
该架构的缺点是:
- 将计算转移到了 OLAP 引擎并同时兼顾了计算和查询需求,对 OLAP 引擎性能有较高的要求;
- 因为计算转移到了 OLAP 端,所以这种方案适用的数据体量规模有一定限制。
基于 Doris 的准实时方案
结合公司数据规模、业务灵活性、成本方面的考虑,我们选用的准实时的方案。那么接下来的就是确定采用什么 OLAP 引擎的问题了,目前业界开源的 OLAP 引擎主要有 Clickhouse、Durid、Doris、Impala+Kudu、Presto等。
这些引擎目前业界都有公司采用,比如:头条采用 Clickhouse(因为头条数据量巨大,并且头条专门有一个团队来优化和改进 Clickhouse 的内核,有钱就是好),快手采用 Durid 、Doris 美团/作业帮有采用,Impala+Kudu 网易是深度用户,Presto 主要用做 Adhoc 查询。
对此可以看到这些引擎都可以采用,主要问题是,是否对这些引擎有足够的掌握程度以及引擎本身学习成本。经过一番对比,结合之前本身对 Doris 有一定的了解,再横向对比了使用公司的规模,最后选择了 Doris 引擎。
Doris 的优点 如下:
- 单表和多表 Join 查询性能都很强,可以同时较好支持宽表查询场景和复杂多表查询,灵活性高
- 支持实时数据更新操作
- 支持流式和批量数据导入
- 兼容 MySQL 协议和标准 SQL
- 支持 HA,在线升级扩容,运维成本低
总体架构
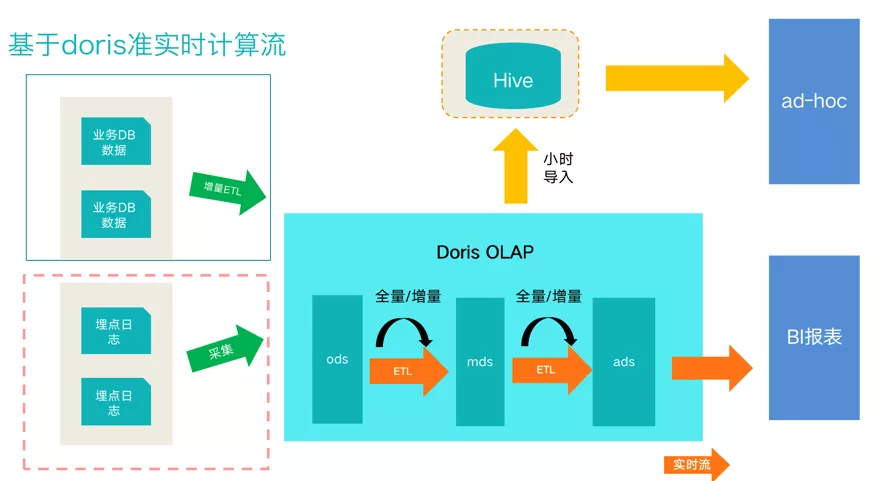
系统架构方案
上图是目前公司采用的架构方案,总体流程如下:
- 数据接入部分,分为业务数据和日志数据。业务数据通过 Binlog 方式收集到 Kafka 后,再通过 Flink 写入到 Doris ODS 层中
- MDS 层,采用每 10 分钟、半小时、一小时进行增量或全量的方式更新,构建业务模型层
- ADS 层,构建大宽表层加速上层查询速度
- 对于一些临时的 Ad hoc 大查询需求,通过 Doris 的 Export 功能导出到 Hive 通过 Presto 提供查询,避免影响在线业务核心报表
- BI 查询直接通过 MySQL 协议访问 DB,配合查询层缓存来提供报表分析服务
- 每层 ETL 任务通过自研调度系统调度运行,报警监控一体化
在实际业务应用中也遇到了一些问题�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%96%B0%E4%B8%9C%E6%96%B9%E5%9C%A8%E7%BA%BF%E6%95%99%E8%82%B2%E5%AE%9E%E6%97%B6%E6%95%B0%E4%BB%93%E7%9A%84%E8%90%BD%E5%9C%B0%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


