普渡大学李攀好的图表示到底是什么

分享嘉宾:李攀博士 普渡大学 助理教授
编辑整理:吴祺尧 加州大学圣地亚哥分校
出品平台:DataFunTalk
导读: 图数据在现实生活中无处不在,社交媒体、互联网、生物科学领域以及知识图谱中都存在它的身影。图表示学习是最近一个相对而言比较热门并且重点研究的方向。今天,我想从信息理论的角度来探讨图表示学习,主要会围绕下面三点展开:
- 图表示学习介绍
- GIB: Graph Information Bottleneck
- AD-GCL: Graph Contrastive Learning basedon GIB
01 图表示学习介绍
首先和大家分享下图表示学习与图神经网络GNN。
1. 图表示学习
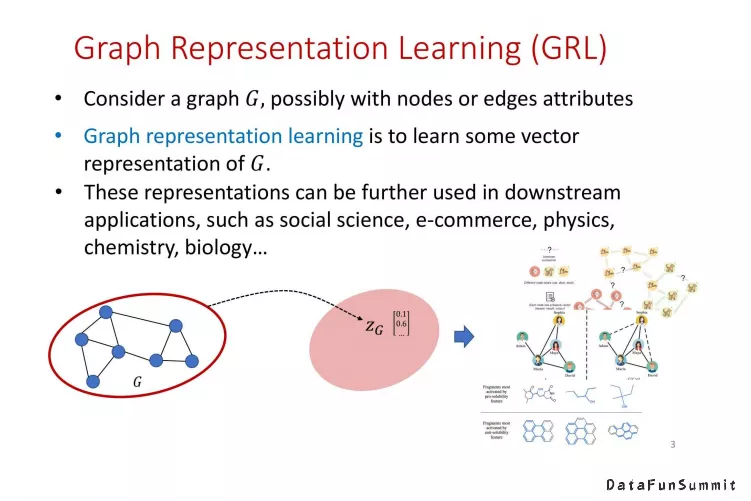
图是一种离散结构,图表示学习的目的是为了使用一种向量型的表达将图表示为一个向量空间,使得它可以在下游应用中更方便地被使用。图表示学习基本上打败了之前所有的经典图的一些表示方法(例如核方法),所以它已经被广泛利用在各式各样的应用中。
2. 图神经网络

图表示学习有很多实现方式,我们今天想要探讨的是一种基于图神经网络的通用实现形式,其具体实现可以由message passing算法迭代来表达。我们首先会给每一个节点赋予一个向量表示,DNN的作用是逐步更新对应的向量表示。更新的做法是通过聚合邻居节点的向量并经过一定的非线性变换(通常由MLP或者神经网络加上非线性激活函数)来实现。大家最熟悉的GNN的应用是在节点层面的,我们将节点最终的向量表达去除并输入至后续的分类器来完成节点预测和分类任务,亦或者是节点回归问题。针对全图的表示问题,一般的做法会将所有节点的向量表达集中到一起,即pooling操作,之后再使用集中后的表达来做最终预测。
我们今天主要想介绍两个从信息理论角度来切入的工作。第一个叫做Graph Information Bottleneck (GIB),旨在回答“什么是一个好的图表示”这个问题。GIB重点关注图的鲁棒性问题,提出基于图信息瓶颈的优化准则。第二个是我们组近期的工作,其想法源于GIB的训练是需要后续任务的标签信息,而我们希望能将InformationBottleneck的想法运用于无标签的情形,即AD-GCL。首先我先来介绍图信息瓶颈的工作。
02 GIB:Graph Information Bottleneck
1. GIB提出的动机

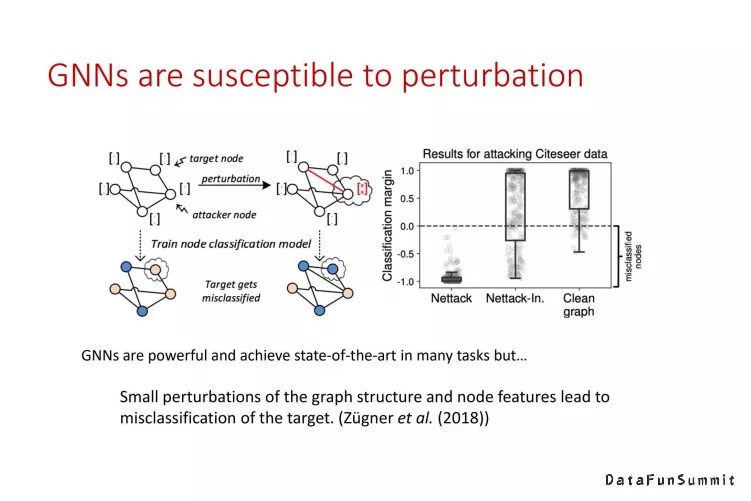
由于图结构的离散型,GNN对干扰十分敏感,即经过结构扰动后图表示的输出变化非常大。基于GNN的这一缺点,我们开始反思什么样才是一种好的图表示,即我们需要寻求一个更好的准则来描述好的图表示,进而避免得到受数据本身影响非常大的向量表达。

传统GNN方法中,如果一个图表示可以在测试集上得到优秀的预测结果,那么我们就称其表示能力好或者有某种很好的性质。但是实际应用中,由于我们收集的数据质量不好或者一些人为因素的影响导致数据并不能反映实际的、完整的分布。在这种情况下我们仅仅使用测试数据集上的表现来衡量一个好的图表示是远远不够的。我们希望一个好的图表示是鲁棒的、稳定的,并且拥有迁移的能力。具体来说,我们希望即使数据出现了分布漂移或者受到人为的扰动后,好的图表示仍然可拥有之前所述的性质。我们给出的核心想法是:一个好的图表示需要捕捉最少充分信息量minimal sufficient information。

之所以传统的图表示以及图模型对数据扰动十分敏感,主要是因为它会掺杂一些和我们的目标不直接相关的冗余信息。我们可以使用信息论中的韦恩图来表示这个现象,如上图所示。当然,如果数据扰动出现在了必要信息区域,无论什么样的模型产生的输出都会受到影响。但是如果模型额外捕捉了阴影部分的冗余信息,由于这部分信息与下游任务并没有关系,那么模型就存在着低鲁棒性的风险,即若数据扰动发生在了冗余区域,那么其仍然会对模型的输出产生巨大影响。我们希望GNN避免过参数化的问题,这样可以使它不仅仅在局部采样的测试数据集上表现较好,又可以拥有鲁棒、稳定的性质。我们使用的方法就是让GNN学习最少充分信息量minimum sufficient information。
2. GIB的原理与算法

在介绍GIB数学优化目标之前,我们先回顾一下互信息的概念。互信息本质上描述了两个随机变量的相关性。如果我们给定了两个随机变量X和Y,X和Y之间的互信息衡量的是:如果我们知道了其中一个随机变量,另一个随机变量的不确定降低了多少。如果X和Y是相互独立的,那么它们之间的互信息为0,互信息越大表示我们知道了其中一个变量,另外一个变量就基本确定了。不严谨地说,在X和Y都是离散分布的情况下,当两个变量之间存在着一一对应的关系,互信息可以取到最大值。

下面我们根据互信息的概念建立GraphInformation Bottleneck(GIB)。我们将Y记作下游任务的标签,即我们的目标数据;D是输入样本,在图学习的场景下输入数据不仅包含特征X还包含了图结构A。GIB的目标是最大化图表示Z和下游任务数据Y的互信息,同时希望最小化图表示Z与原始输入样本的互信息,具体公式如上图所示。其中β大于0,最终GIB优化的目标函数就是将两个目标相结合后得到的。强调一下,GIB是希望图表示能够抓住对于后续任务足够多的信息量,但又不希望图表示从原始输入样本中继承太多信息。
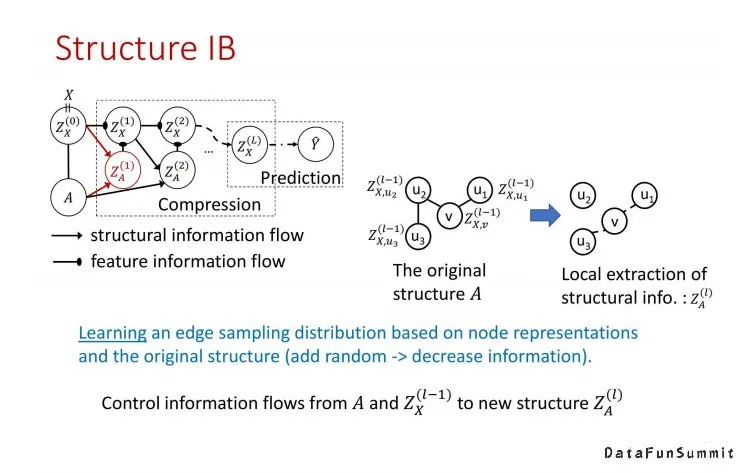
具体算法推导可以参见已发表的论文Graph Information Bottleneck,这里我们简要介绍一下算法的实现。算法大体上可以看作是一个先做压缩再做预测的过程。压缩过程的输入是节点特征与图结构信息。在压缩的过程中,与传统GNN中仅仅更新图节点特征不同,算法会先更新图结构A,进而更新节点特征。从信息论的角度来看,我们每次执行压缩操作改变图结构A和节点特征X就是在减少图表示Z与A,X的互信息。在GIB中,我们采用增加随机性的方法来达到减少互信息的目的。因为互信息的定义是知道一个随机变量后对另外一个随机变量的不确定性的减少程度,那么注入随机变量意味着会丢失一定的信息量。所以我们可以通过注入随机性的手段来使图表示逐步压缩其从输入样本中继承的信息。具体地,我们首先利用节点特征与图结构并且加入随机信息(图的边采样操作),从而生成新的图结构;之后基于新的图结构对节点特征做一次GNN中标准message passing。当然,message passing操作中还是在节点特征里需要注入随机信息来降低信息量。当然,我们需要使得注入随机信息以及交替更新图结构和节点特征的过程是可以被训练的(具体做法同样可以参考GIB的论文),从而使得得到的图表示会在优化过程中丢弃和下游任务无关的信息,从而达到我们的目的。
需要重点指出的是,GIB与InfoMax最关键的区别是:InfoMax的优化目标是希望图表示能抓住尽量多的输入样本信息,而GIB的优化目标是逐步丢弃输入样本信息,从而使得最终得到的图表示更加鲁棒。
3. 实验结果
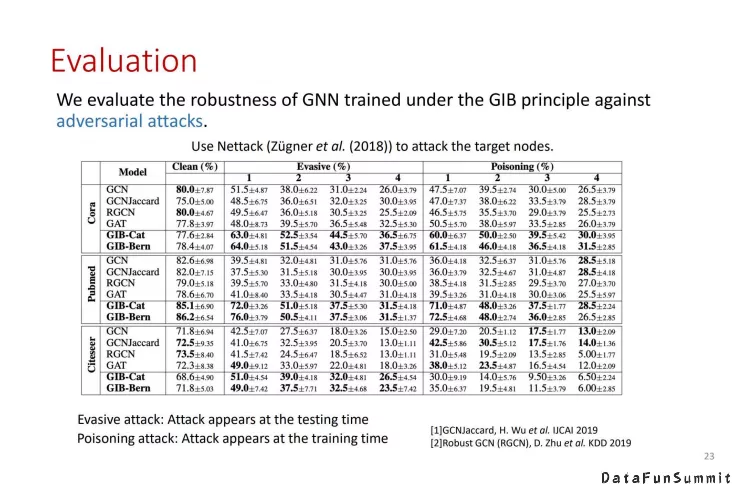
我们使用了三个标准的数据集,并采用了adversarialattack的手段对GNN进行调整,从而衡量GNN的鲁棒性。其中Cat和Bern对应着删边时遵循的概率分布。测试结果表明GIB不仅比GCN更加出色,而且在大多数情况下比专门在数据集上进行优化图神经网络性能更加。

我们还采用了对节点特征进行随机扰动的方法来衡量GNN的鲁棒性。具体地,我们给节点特征加入了高斯噪声。实验同样证明了GIB比起之前所有GNN的baseline性能更出色,证明了其鲁棒性和稳定性。
03 AD-GCL:Graph Contrastive Learning basedon GIB

GIB需要知道下游任务Y(即下游任务标签)才能写出优化目标,进行变分优化。有没有办法在不知道下有任务的时候训练好GNN呢。结合目前热门的图对比学习,针对GIB的缺陷,我们提出了AD-GCL (Adversarial Graph Augmentation toImprove Graph Contrastive Learning)。

在实际应用中,收集任务的标签值十分困难。比如在社交网络场景下,即使我们有海量的原始用户行为数据,但是获取显式反馈代价高昂。类似地,在科学研究领域,收集准确的标签值往往需要大量耗时的实验。但是,神经网络的训练需要大量带标签的训练数据(data hungry)。
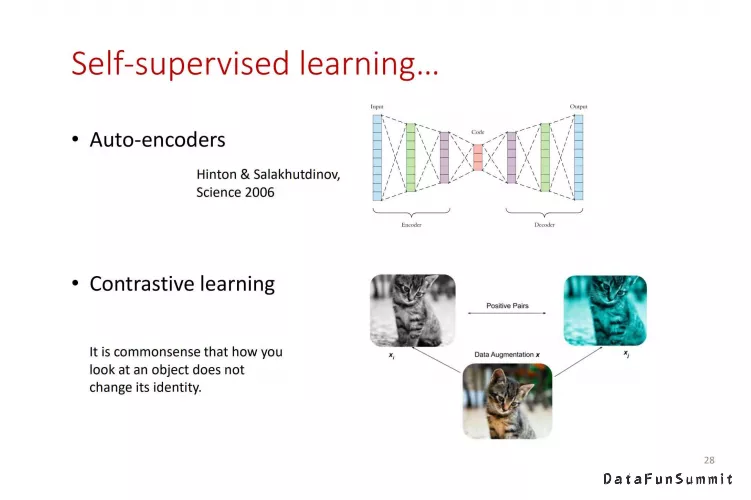
近两年比较热门的解决方案都是从使用尽量少的标签信息的角度出发来优化神经网络。自监督学习十分适合这种场景,主要分为两个框架:自编码器(Auto-Encoders)以及对比学习(Contrastive Learning)。AD-GCL使用的正是对比学习的框架,其逻辑在于输入数据经过不同扰动后仍然对应的是同一个数据。由相同数据经过不同扰动形成的一对数据可以形成一个正样本对,而反之对不同数据进行扰动后形成的一组数据便可以看作为一个负样本对,最后使用正负样本对来训练模型来学习数据特征,于此同时不需要数据的标签值,进而解决data hungry的问题。
1. 图对比学习
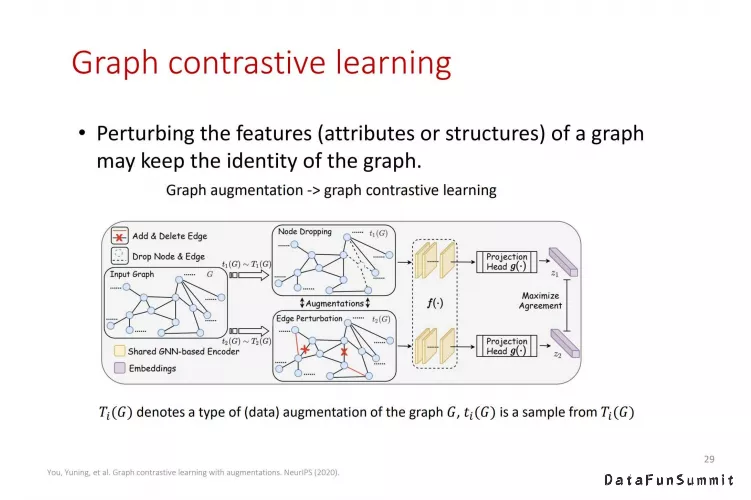
在图学习中运用对比学习的具体方法是对图结构或者特征进行扰动,例如加边/删边、加点/删点、更改节点特征等。如果两个扰动后的图源于同一张图,那么我们就把它们构造为一个正样本对,否则就为负样本对。这一过程也可以被称之为图增强(Graph Augmentation),而图对比学习也正式利用这样的图增强机制来适配对比学习框架。
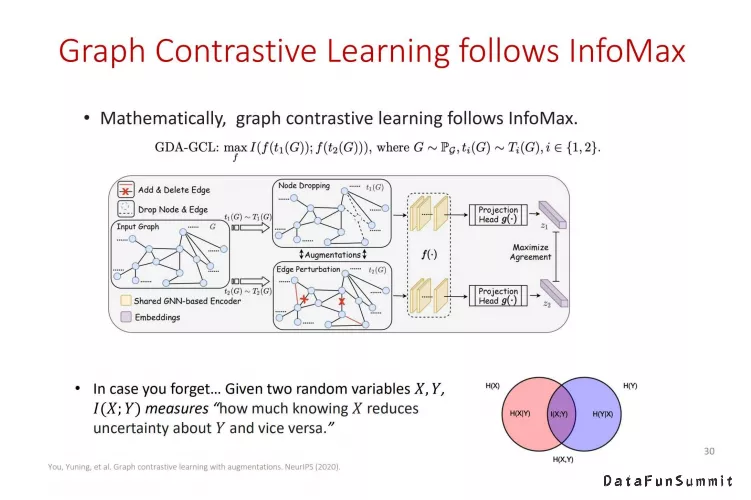
从数学上来分析,图对比学习遵循InfoMax原则。我们对图进行T1和T2两个不同的随机扰动(T为一个概率分布),并分别从中采样出两个新的图。如果两个新图源自于同一张图,它们所对应的图表达的互信息应该尽可能大。正如之前所述,互信息达到最大的条件是两个分布(严谨的说是离散分布)存在一对一的映射关系,而在图对比学习中就以希望同一个图经过扰动后得到的两个图表达存在着一一对应关系。进而,InfoMax的数学表达可以被解释为在一张图经过不同扰动后不会改变图的Identity Information(即依然保留着图与扰动后的新图的一一对应关系)。

但是InfoMax存在问题。实际应用中数据集的获取都是依靠采样来完成的,而在采样后的离散数据集上想要达到InfoMax只需要保证原图G和图表达f(G)形成一对一的映射关系。然而,图表达并不需要抓住所有有用的数据信息就可以建立这样的映射,使得其没有达到设计InfoMax原则时的初衷。进一步分析,InfoMax的上述缺点会导致编码器encoder学习到与后续任务完全不相关的信息,甚至噪声信息已经足够可以使得G与f(G)的互信息最大化,即满足了InfoMax原则但是并没有充分表达原始数据集。我们为了可视化InfoMax的缺陷做了一组对比实验。一组GNN使用下游任务训练集的真实标签值进行训练,而另一组使用随机生成的标签值进行训练。实验发现我们使用随机标签对训练进行约束时,GNN仍然可以达到InfoMax,即在G与f(G)构建一组一对一映射关系。而进行真正的下游任务测试时,其性能显然十分差。实验证明了InfoMax并不是一个很好的图对比学习原则。
2. 将GIB运用至图对比学习

InfoMax存在的问题可以使用Graph Information Bottleneck来解决。InfoMax的目的是最大化I(D;Z),即数据集和特征表达的互信息,而GIB想要最小化I(D;Z)并且最大化下游任务与特征表达的互信息I(Y;Z)。传统GIB需要知道下游任务Y的信息,并不属于自监督学习,而AD-GCL给出了对应的解决方法。

我们的具体做法是在瞄准了图对比学习的图增强阶段。之前大部分文章在运用图增强时都会利用领域先验知识,人工设计并且与数据集强相关的策略或者直接删边删点的方法。但想要使用GIB就需要模型学习一个图增强的机制,利用对抗学习的思想来达到GIB的目标。

AD-GCL的核心思想在于利用图增强的过程使得编码器encoder抓住充足但少量的信息就可以完成随机扰动后的图表达与原图之间的互信息的最大化,即实现一一映射关系。值得注意的时,这个学习过程和下游任务的标签无关,因为我们的目标仅仅是构建一个一一映射关系。写成数学优化式子的话,AD-GCL的优化目标是一个min-max问题,具体公式如图所示。从实现层面来讲,最小化信息其实等价于引入尽量多的随机信息/干扰。AD-GCL采用的扰动方法是对原始图的边进行删除操作,但是删除的概率是可学习的。总结来说,图增强过程(GDA)最终目的是为了学习一个最大的丢弃概率分布,使得经过GDA后的图表示与原图存在一对一映射关系。当然我们需要加入正则项(控制丢弃边的总概率)来防止模型学习到过于激进的扰动策略。详细数学理论推导可以参考AD-GCL的论文。
3. 实验结果
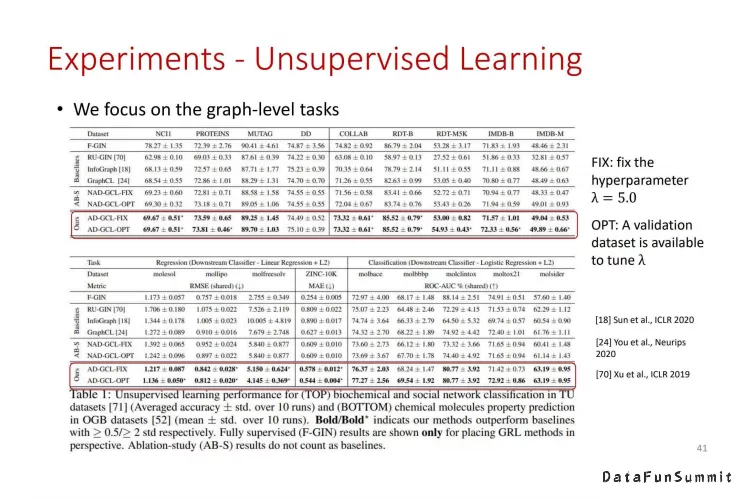
实验中我们使用AD-GCL与baseline以及使用随机设定的删边概率的图对比学习方法在三种不同类型数据集上进行比较,结果表明AD-GCL的表现均超过了其他方法。
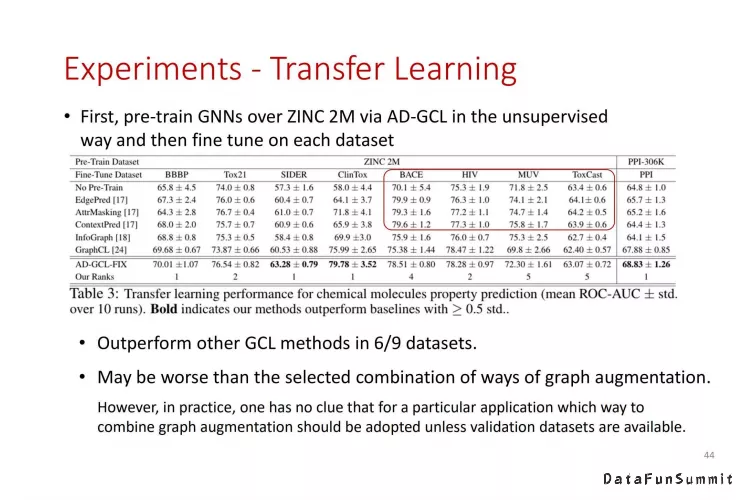
我们还对AD-GCL进行了迁移学习的比较实验。在九个数据集中,AD-GCL在其中6个数据集上表现最佳,但是在其他三个数据上相比一些在对应数据集上精挑细选的方法还是有一些差距。
04 精彩问答
Q:GIB的最佳应用案例有哪些?
A:我们在论文中只做了节点分类任务。近期会议中出现了一篇使用GIB来完成全图分类的工作(molecule �
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%99%AE%E6%B8%A1%E5%A4%A7%E5%AD%A6%E6%9D%8E%E6%94%80%E5%A5%BD%E7%9A%84%E5%9B%BE%E8%A1%A8%E7%A4%BA%E5%88%B0%E5%BA%95%E6%98%AF%E4%BB%80%E4%B9%88/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


