有赞搜索引擎从到技术解析

分享嘉宾: 毛夏君 老师
内容来源: DataFun AI Talk《搜索引擎从0到1》
出品社区: DataFun

今天主要分享的是一些搜索工程方面的意见,首先介绍下一个完整的搜索引擎是由哪几部分组成的,然后是搜索内部文件的读和写,最后是搜索系统中主要的核心要点分析以及对应的案例分析。最后是有赞方面的经验分享,和我们所做的实战。

首先要构建一个搜索引擎一般以开源搜索引擎为优先考虑,如果完全自研搜索引擎成本很高。目前比较流行的开源搜索引擎有sphinx、lucene/solr/elasticsearch,还有可以做搜索引擎但是功能还不完善的有Redisearch、bleve/groonga/pgsql fulltext search。我们选择的是Elasticsearch,选择的依据是分布式、高可用,还有就是面向文档存储,存储的数据格式是json格式;不用限制其内部schema;插件很丰富,提供各种功能的插件服务;社区也很活跃,提出的问题和建议能很快响应;还有就是自带Xpack组件,提供一些机器学习算法。
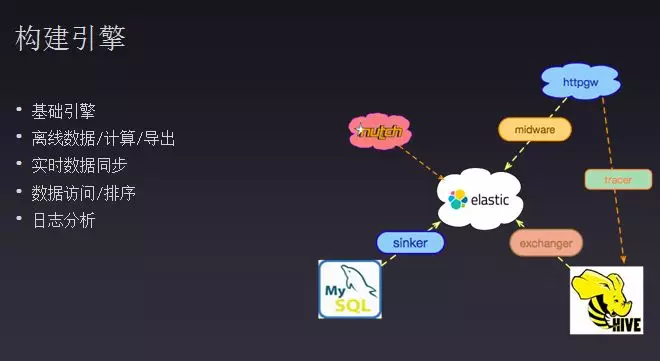
接下来讲一下如何构建搜索系统,第一步是搜索引擎选择,选择适合自已业务需求的搜索引擎;第二步是数据,选择好搜索引擎还需要数据,实现数据的导入导出,一般都是从大数据里面计算搜索数据,利用离散数据解决转化率等问题。有了大数据需要和Elasticsearch进行交互,需要开发和包装。第三个还需要实现实时数据同步,数据的增删改等操作都需要在搜索引擎里面实现同步,还有原始数据也需要实时同步到搜索引擎中去。第四步就是数据部署完成后如何让外部用户访问,在一般搜素引擎中对搜索的数据会进行个性化排序。还有在web端和Elasticsearch有一个中间件加载搜索结果和插入广告,对前五页或者十页进行一个精排。用户访问后,需要对用户访问的结果和行为进行一些跟踪,这时就需要对访问日志进行一个分析,因此会有一个日志分析系统,将用户数据通过离散计算返回给搜索引擎中。还有一些搜索引擎会进行一些爬虫。
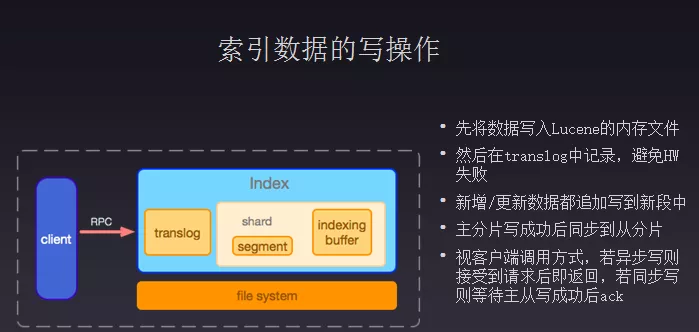
接下来讲一下数据在搜索中的写入和读取,Elasticsearch是基于Lucene开发,数据读写都是基于Lucene的api包装。客户端通过RPC写数据后,而Lucene的index文件指定为不可变,只是往后面叠加不会进行更新。在涉及文档变更时,如果实时变更索引文件磁盘IO会有很大的负载,可能就很难支撑线上大量读写操作,因此会在内存里面暂存一段索引数据,持续去增加其内存栈。一个数据请求过来后会先在内存栈保存数据,避免数据丢失会有一个translog,确保掉连后能将数据追回,真实落盘的索引文件会存储在文件系统中。访问索引数据可以像HDFS或者shard来加速访问,这些都是通过文件系统来解决。
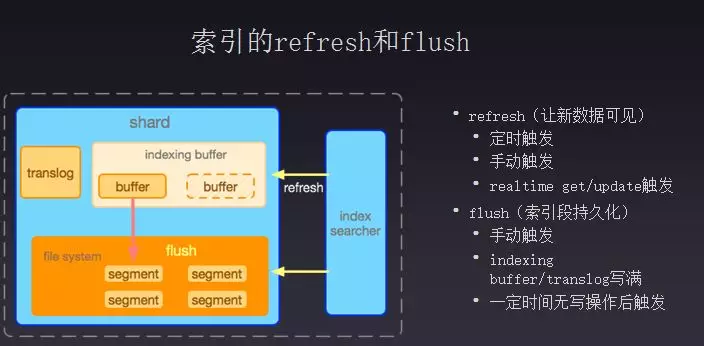
第二个局势索引的刷新和flush,泛文件是定时生成的、不可变,写进的数据是在一个新的段中。段文件访问时需要在原始数据查询记录,元数据不是实时更新的,需要通过一次refresh来加载泛文件。refresh的功能就是让新数据可见,触发由于有一个后台内存,每个5秒进行一次查找段文件,将其反馈到segment中,同时也可以手动触发。还有在update数据时,也会进行refresh操作,否则也不能拿到最新数据。Flush就是将数据从内存栈写到磁盘中,功能是使数据持久化,因为有数据落盘才能进行数据清理否则会导致数据量很大。这个阶段会自动定时落盘清理数据,如果translog超出设定的大小也会强制将数据放到磁盘中去,同时也可以手动触发。
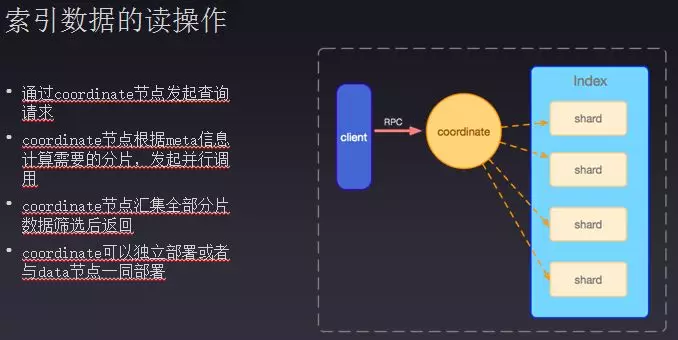
分布式系统会将数据分布到多台机器中或者多个节点,每个节点就相当于真实的索引。查询请求过来会有一个coordinate将数据入流到对应的分片上,Elasticsearch在创建的时候就可以指定其分片数,如果只指定一个节点会出现数据倾斜,也不能充分利用多台机器的性能,因此一般会依据机器数量来制定分片数。查询时需要从每个分片中找到满足对应查询条件的数据,然后在coordinate里面做一个汇聚。如图要查询100条数据,需要在分片中查询100次数据,最后汇聚400条数据,再从这400条数据依据优先级做一个优先级队列取100条数据,返回给客户端,分片数越多查询效率越低,但是写的性能会变高。在设置分片时需要依据业务需求,如果主要是来读就将分片数设置的少一些,如果是写的话就将分片数匹配机器数据量达到最大存储量。
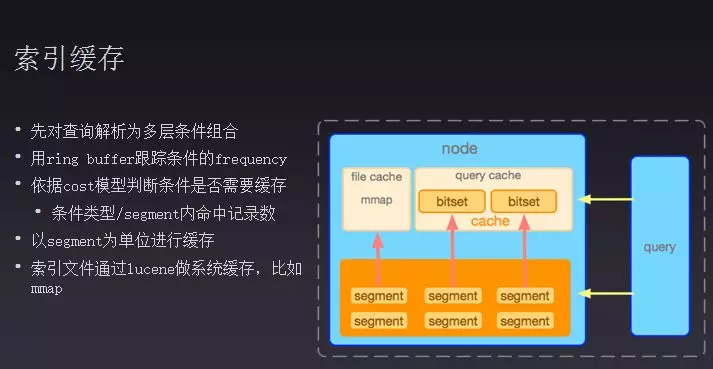
搜索或者大数据市场一般采用LSM来存储数据,在检索时如何在段文件中快速找到文档,像mysql等关系型数据库有B+式索引,能够很快找到数据。但是在搜索系统中需要遍历所有段文件才能找到所需要的数据。因此为了提高性能需要采用缓存的形式,跳过磁盘操作直接在内存里面查询,能够有效的提高访问性能。Elasticsearch缓存主要有:首先是query cache,请求过来之后会将查询条件拆分多层,单独a、b、c作为一个,a、b、c组合也作为一个,在段文件中做集群查询操作。假设a条件命中文档特别多,会将a条件的数据做一个bitset放到内存里面,下一次执行a条件就直接从内存里面查询。在操作系统层面,会将段文件做一个mmap,减少数据在内存中的拷贝,用户访问时可以直接定位到索引目录上去,这样可以在一定程度上加速访问性能。
需要注意的是(1)有些高成本的查询erms/range,只要重复执行两次,就将其加载到缓存中去,在查询时要避免使用这类型的条件,要使用时尽量使查询效率变高,range查询昨天到今天时将时间间隔设置到2-3秒,这样查询能够重复利用,每次查询虽然是不一样的,但是内存里面是满足查询要求的。(2)再一个就是合理分配分片数,写的化就尽量匹配机器数达到最大存储量。(3)索引文件不可变,在删改数据都需要增加栈,将新加的数据加到里面去,增加一个标记位写到新的文件中去。如库存字段为100,一直卖到0会进行100次更新操作,在索引中每一条数据都会当做一条新数据写入索引文件里面,在查询ID等于1要查一百次数据,因此在使用时尽量少去做更新操作。(4)还要做适当的隔离,Elasticsearch的数据隔离是以节点为单位,当某一节点访问过大就会抢用闲时节点资源。因此对于不同业务间最好做一些隔离,避免资源相互影响。
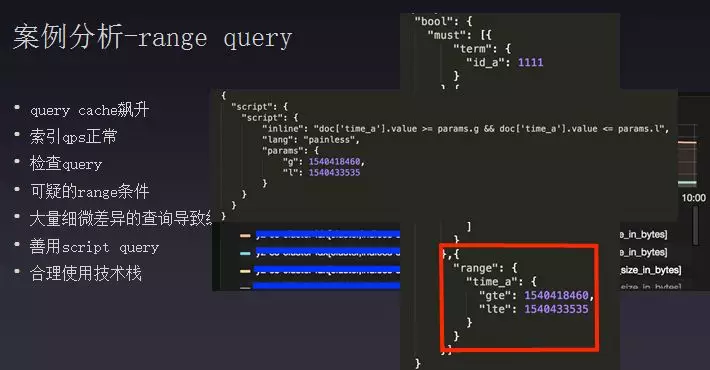
接下来分享一下我们的相关案例以及相应的经验总结,突然出现一个机器query cache突然飙升,缓存从几百兆一下升到20多个G,排查过程首先查询索引是否有大的访问量,然后检查到底查询了什么数据,然后发现range条件异常,是一个高耗时查询,放到cache里面条件是命中一定要大。如果每次都查询这么大的数据,时间跨度是几十秒,这时就会有很多重复的缓存进入query cache里面,当时命中的数据有2500万转化为bitmap大约几十兆,但是查询持续不断,过了几个小时内存就会不断飙升。最后解决方案是将查询换一下,利用script查询替换,拿到查询条件用脚本进行过滤,目的是查询内容不再进入缓存。这样做的原因一个是因为它是个单纯的遍历操作,缓存利用率较低;时间范围筛选的结果数据比较大,总共有3千万条数据,命中条件有一千两百万条数据,拿到中间结果再用脚本过滤效果会比较好。再者就是合理使用技术栈,有些使用特定数据库会比传统效率高很多。
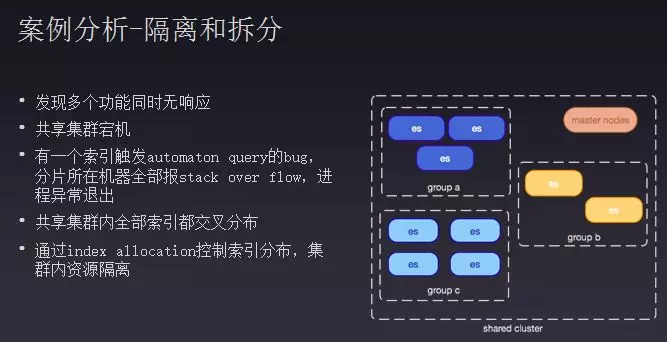
第二个案例是隔离和拆分,有一个双十一发现所有功能组件都无法响应,排查发现所有共享集群都宕机。具体排查发现触发一个索引bug,7以前版本做match、前置查询或者正则查询时使用自动机,构建好自动机后会通过递归去判断状态是否是有限的,如果自动机过大就容易形成宕机。解决方案就是给整个共享集群加一个分组,把每几个机器打一个标签,指定存储机器组实现资源分组,这样无论出现何种bug只会影响自己组的机器。
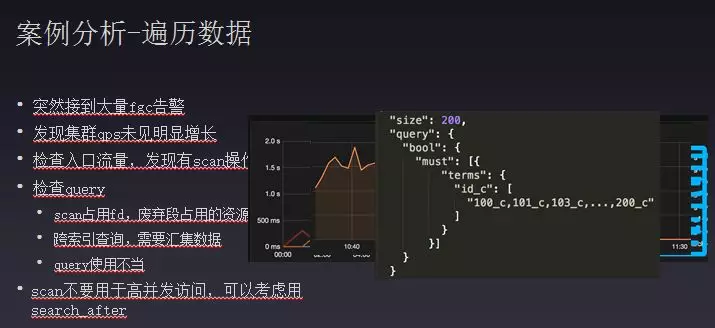
第三个案例是关于遍历数据的操作,有次突然接到大量fgc告警,查询有大量fgc,占用的内存也比较大。排查发现集群的qps并未明显增长,然后查询入口流量是否有变化,发现scan操作有明显的波动且和接收fgc告警时间相匹配,接着检查其查询什么内容,发现问题有以下几个方面:(1)Elasticsearch遍历时scan占用fd,锁定scan发起时所有的段文件,因此废弃段占用的资源无法删除,只有等scan结束后才能回收掉。因此scan发起的量越大,占有的资源就越多;(2)索引本身做了一个跨索引查询,一下查询三四个索引数据,这样需要在每一个索引跨分片查询取得数据然后汇聚数据。再加上跨索引,每一个索引都要执行一次操作,每次查询占用内存较大,因此会短时间产生大量垃圾数据;(3)query使用不当,scan完成没有执行回收操作而是等待它自动回收机制,会对机器产生大量垃圾数据。
解决方案就是scan不要去用于高并发操作,可以使用search_after,因为scan操作不能重置,每一次操作都会下移,如果重置就发生数据丢失。而search_after不会发生,因为需要手动指定要查询哪一片段的数据。
接下来讲一下有赞在Elasticsearch部署上的一些经验。上图是一些相关配置,虽然有一些调整,但是没有非常微妙的操作,都是依据垃圾回收情况、日志进行调优。还有透明大页,很多大数据应用都是将透明大页关掉,这样能够减少一些问题。在服务设置mater-nodes,避免服务异常。在routing.allocation可以控制索引分片的分布,分布多少节点,每一个节点最多分布多少分片,这都是可以通过该参数进行设置。索引设置就是一些默认参数如分片数、副本数等可以通过一个template匹配索引创建的模板。还有个strict mapping,Elasticsearch可以在写数据时动态推测数据字段类型,但是会有个问题,如身份证或者邮政编码字段如果事先没有定义字段类型,就会以第一个输入的字段值作为类型,如果出错就不能修改,只能重新建索引这样成本较大。
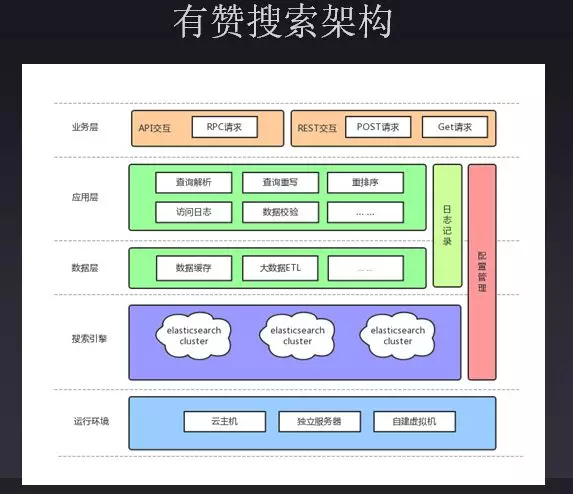
当前系统架构,最上层是业务层,暴露的接口可以用RPC方式或者rest接口直接调用。在应用层会做一些查询解析、查询重写、重排序、访问日志的记录,包括数据校验。数据层主要是缓存,缓存整个查询结果,Elasticsearch缓存查询条件的结果,这样可以避免流量进入Elasticsearch中。还有就�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%9C%89%E8%B5%9E%E6%90%9C%E7%B4%A2%E5%BC%95%E6%93%8E%E4%BB%8E%E5%88%B0%E6%8A%80%E6%9C%AF%E8%A7%A3%E6%9E%90/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


