有赞算法平台之模型部署演进
稿|三余
一、前言
模型部署作为算法工程落地的最后一公里,其天然对算法团队而言具有较高的复杂性,不仅要考虑如何高效地部署、管理不同框架模型,还需要考虑分布式服务的负载均衡、故障容错、可扩展性、资源隔离、限流、核心指标监控等问题。这些都极大的依赖于工程团队的能力,不是算法团队的强项,如何解决这最后一公里,让焦点聚焦在模型开发上,是模型部署服务模块需要解决的问题。
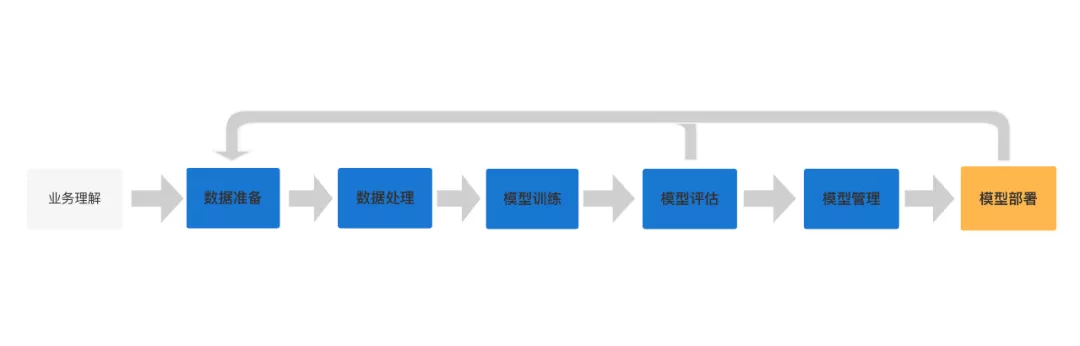
二、原有架构
2.1 架构设计
在有赞算法平台Sunfish包含算法训练和模型部署两部分, 模型部署的模块称为ABox(小盒子)。
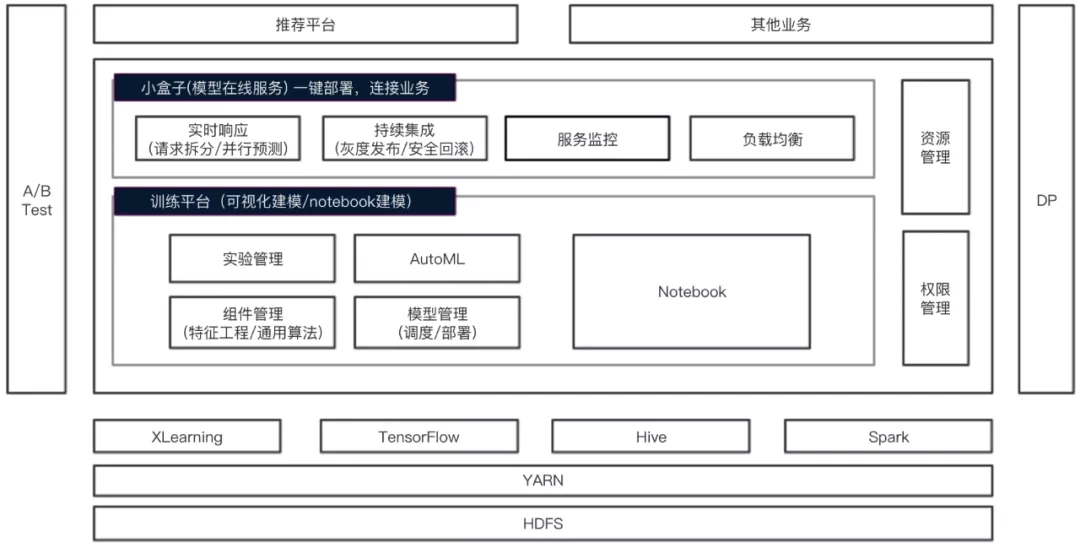
ABox 主要提供将模型部署为在线服务的功能, 主要包含以下功能:
- 提供 tensorflow 模型的服务加载和版本管理、弹性部署
- 提供 tensorflow 模型和其他模型服务(自己部署在额外服务器上)的路由管理
- 提供模型输入和输出的自定义处理逻辑执行
- 提供服务主机的负载均衡管理
- 收集的 Metric 写入上报到 kafka,通过 druid 做监控,并提供指标界面查询
其整体的架构设计如下图所示分为 3 个模块: master、 worker 和 manager, 各自主要职责为:
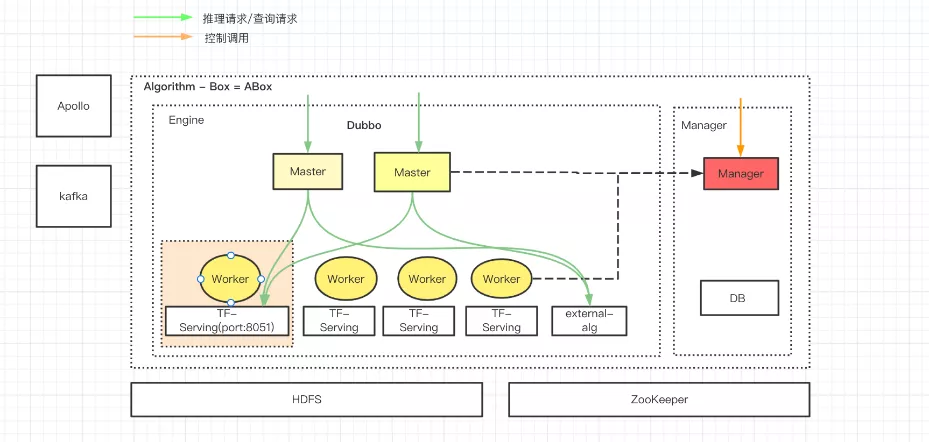
master:
-
业务请求的路由
根据 zookeeper 上的动态路由选择将请求直接路由给可以访问的服务(这里包括TF-Serving 服务和第三方注册REST服务,多个服务之间采用轮询的方式), 请求不会经过worker。
-
自定义 jar 包(udl: user defined lib)执行
在模型预测前和预测后可以加载自定义处理逻辑,可以对模型的输入数据和输出数据进行预处理
worker:
- 注册本机信息,负责上报心跳给 manager, 心跳包含本机上的算法服务的健康状态
- 负责算法模型的本地拉取, 由 tf-serving 服务加载模型
manager:
- 负责服务器(master 和 worker)的注册和下线
- 负责算法和模型的创建
- 提供 udl 的更新接口
- 提供集群、业务组管理的接口
- 提供模型的部署和上下线功能
- 提供第三方算法的注册和上下线功能
2.2 痛点问题
基于以上架构,ABox 能较好的支持 tensorflow cpu 模型的部署,但存在以下问题:
痛点1 运维投入大
- 扩缩容需要人工调用接口
- 模型服务最多实例个数取决于 worker 节点个数, 横向扩容需要增加机器
- 除 tensorflow 模型部署, 其他需要人工调用接口注册 URL 到 master 来提供路由能力
- tfserving 采用容器化部署,模型加载过多易 OOM,无法自动拉起
痛点2 负载不均衡
- 模型按照一定的资源调度策略分布在各个 worker 节点上,各 worker 节点资源使用容易不均衡
痛点3 资源未隔离
- 热点模型占用大量的CPU/内存,容易影响其他模型服务
痛点4 缺乏通用性
- 模型服务无法统一管理, tensorflow 模型和其他框架模型管理割裂
- 没有GPU模型服务部署功能
三、改造升级
3.1 seldon介绍
基于前述问题,为了统一不同框架模型部署服务的管理, 为了增加 cpu 和 gpu 模型的统一部署功能, 为了简化运维操作,我们引入了 seldon 这个开源的基于云原生的模型部署服务。
seldon 是一个基于 K8S 的集成的模型部署方案, 内置了很多通用的例如 tfserving、 sklearn server、mlflow server、triton这样的模型推理服务器(inference server)。除了这些还可以通过自己实现自定义的 inference server 提供一些额外的模型服务支持。
seldon 通过将你的模型部署为K8S上的微服务,来提供 HTTP/GRPC 接口给业务调用。
我们来看下 seldon 的核心模块, 如下图所示:
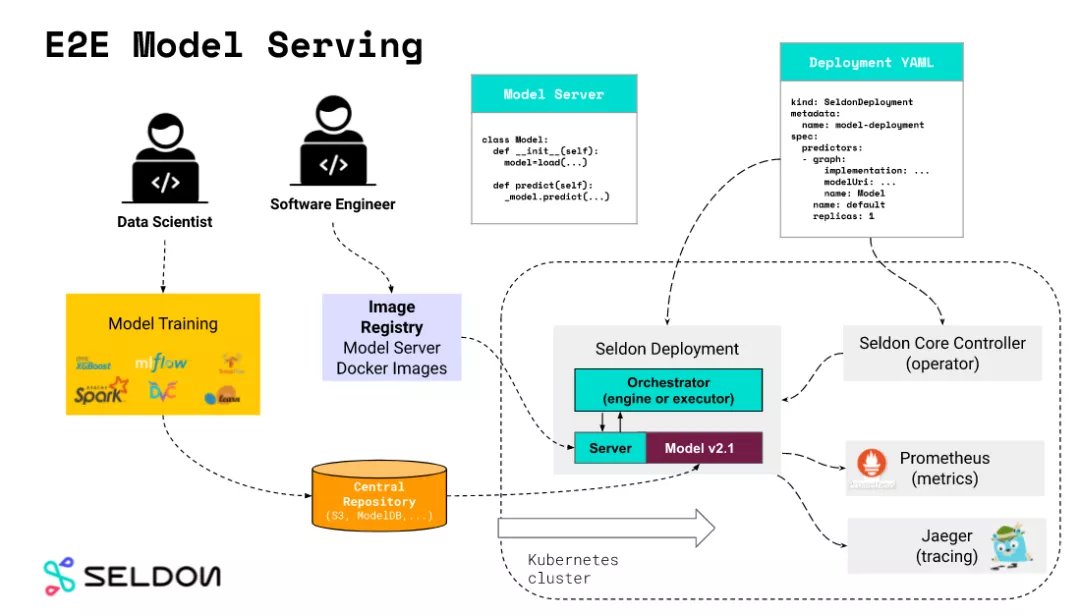
seldon 的核心模块是它的 Seldon Core Controller, 即 operator 模块, 该模块用来管理 Seldon Deployment 资源( Custom Resource )。seldon 通过 CRD 向 K8S 注册自定义资源,Seldon Core Controller 负责处理该资源的 CRUD, 我们通过创建/删除/修改 Seldon Deployment 来达到创建/删除/修改模型服务的目的。
除此之外, seldon 还可以集成 Prometheus 和 Jaeger 来提供模型服务的指标监控和调用追踪能力。
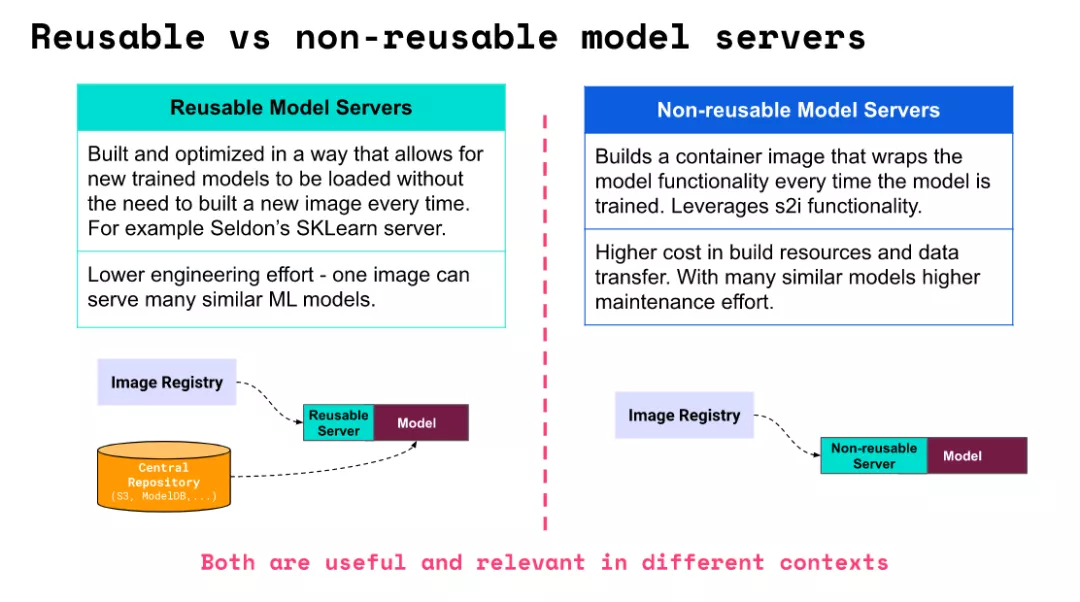
seldon 的另一核心概念是 Model Server , 即加载模型用来提供HTTP接口的模型推理服务器。Model Server 有两种类型, 分为 Reusable Model Servers 和 Non-Reusable Model Servers 。他们的差别从名字就可以看出, 前者是不同模型之间可复用的,后者是固定模型的。
Reusable Model Servers 通过配置的模型地址,从外部的模型仓库下载模型, seldon 模型预置了较多的开源模型推理服务器, 包含 tfserving , triton 都属于 Reusable Model Servers。
Non-Resuable Model Servers 将模型打入自定义镜像内部,不需要单独从外部加载模型, 适合做一些特殊化处理以及不需要频繁更新的场景。
例如启动一个 tensorflow 的模型服务, mnist.yaml 文件定义如下:
apiVersion: machinelearning.seldon.io/v1alpha2
kind: SeldonDeployment
metadata:
name: tfserving
spec:
name: mnist
predictors:
- graph:
children: []
implementation: TENSORFLOW_SERVER
modelUri: gs://seldon-models/tfserving/mnist-model
name: mnist-model
parameters:
- name: signature_name
type: STRING
value: predict_images
- name: model_name
type: STRING
value: mnist-model
name: default
replicas: 1
这里声明一个名为 minist 的 SeldonDeployment 资源,主要的配置参数就是 implementation 和 modelUri。
implementation 指定此次 Model Server 使用预置的 tfserving 服务器, 并且需要指定模型的 modelUri 地址。
通过 kubectl create -f mnist.yaml 我们就可以创建一个 Seldon Deployment 资源。
通过 kubectl get sdep 可以看到的 Seldon Deployment minist,该 Seldon Deployment 资源会管理对应的所需要的 Deployment、 Service 和 Virtual Service。
3.2 设计方案
基于公司内部 K8S 环境,在商量了如何部署seldon的后,我们最后决定的架构如图所示:
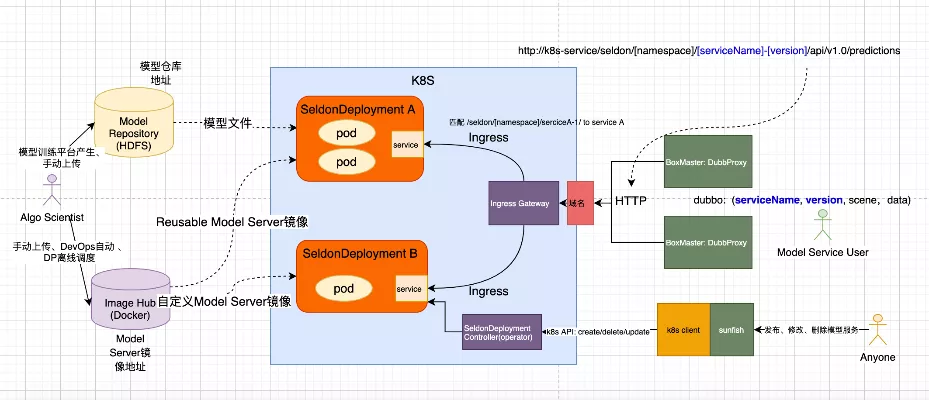
在引入 seldon 管理模型服务部署的同时,进行了以下的改造:
- 保留 ABox master 作为 Dubbo 请求接入入口, master 负责将请求根据协议封装成 http 请求 K8S 集群的 ingress controller
- 修改 Ingress Controller 为 Nginx Ingress Controller, 通过为每个模型服务生成 Ingress 规则路由到指定的 K8S service
- 增加 HDFS-Intializer 用于 Reusable Model Server 中的 hdfs:// 协议的 modelUri
- 基于腾讯云的 GpuManager 方案实现GPU的虚拟化和共享
- 通过在算法平台集成 K8S client 进行 Seldon Deployment 和 Ingress的 CRUD
- 为自定义镜像提供日志收集服务
- 为模型服务增加资源使用展示
下面来介绍 seldon 模型服务部署的主要改造部分。
3.2.1 Ingress Controller 替换
seldon 通过 Ingress Controller 来提供集群外服务的统一访问, 然后通过 istio 或者 ambassador 提供服务的路由和分流, 默认的 istio 服务较为强大,但由于公司内部 K8S 不提供 istio 服务的维护,为了便于运维, 我们在部署 seldon operator 的时候关闭了 istio 和 ambassador 的功能,然后通过自己的客户端实现在 seldon deployment 和 ingress 的统一创建/删除/更新管理。
**3.2.2
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%9C%89%E8%B5%9E%E7%AE%97%E6%B3%95%E5%B9%B3%E5%8F%B0%E4%B9%8B%E6%A8%A1%E5%9E%8B%E9%83%A8%E7%BD%B2%E6%BC%94%E8%BF%9B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


