有赞订单搜索架构演进之路
文 | 王爷 on 交易
一、前情提要
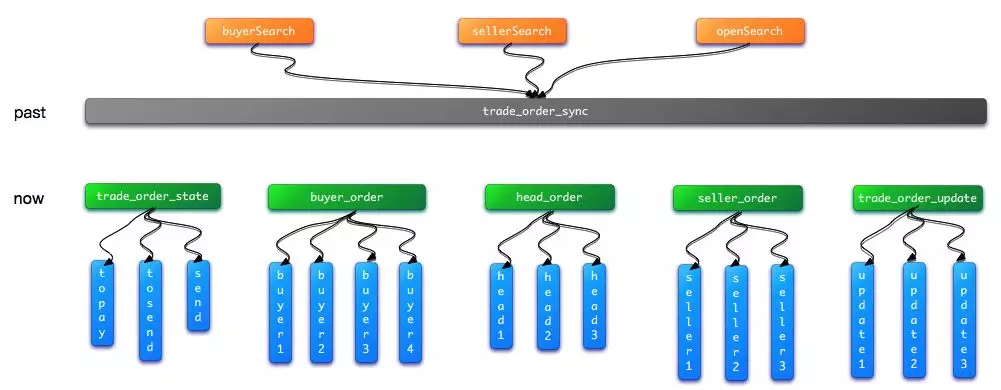
时节如流,两年前的今天写了 有赞订单管理的三生三世与十面埋伏,转眼两年过去了,这套架构发展的如何,遇到了什么新的挑战和收获,今天主要来一起整理回顾下有赞订单搜索AKF架构演进之路。
之前将散落在 DB 多个分片中的数据在 ES 做了一次聚合,带来了巨大的好处,同步任务少,维护成本低。尤其是订单迁移这一块,之前由于是分片设计,所以当订单触发迁移时候,需要将数据插入新分片,确认无误后还需要删除老分片数据,流程繁琐易错,统一收拢后对于 ES 来说,各个端订单迁移,都只是一次更新操作,无比简单。补充介绍下订单迁移:
-
买家订单迁移 针对新用户转变为关注用户,从系统 mock 的 buyerId 到真正分配的 buyerId 订单的迁移。
-
卖家订单迁移 针对店铺模型升级,比如从微商城到零售连锁,原门店独立需要迁移订单。
二、新的挑战
然而随着业务的不断发展,聚合后的索引也开始暴露各种问题。
-
数据量增长比预期要快很多,亿级别的索引,慢查也开始出现,像一个庞然大物蠢蠢欲动。
-
为了满足商家的一些个性搜索需求,很多搜索需求都属于极少数会查询到的,但是都会被加到同一个主索引中,使得主索引字段不断增多。
三、应对
3.1 合久必分
为了解决以上挑战,踏上了可扩展性架构拆分之路。简单介绍下有赞订单搜索的几个维度:
-
B 端商家单店搜索(商家管理单店订单)
-
B 端商家总店跨分店搜索(连锁总店管理分店订单)
-
C 端买家跨店铺搜索(买家管理跨店所有订单)
由于既要 ToB 又要 ToC ,而 B 端零售连锁商家的引入,增加了不少复杂度,因为有总店 MU 来管理多个 BU 单元,需要跨多个店铺查询。无论怎么分片,单一维度都必然存在跨分片搜索的场景。计划优先按数据冷热分离来拆分,而如何区分和定义这个冷热数据?最近一天,一月,一段时间的搜索,都比较范,缺乏数据支撑。
念念不忘,必有回响。
3.1.1 热状态索引
于是观察了下我们的监控,发现了奇妙的规律。所有搜索场景中,常见的按支付方式,物流类型,商品名称,订单类型等搜索占比很少,而按订单状态搜索占比最多,约 53% ,也就是一半多的搜索流量全部来自于订单状态检索。
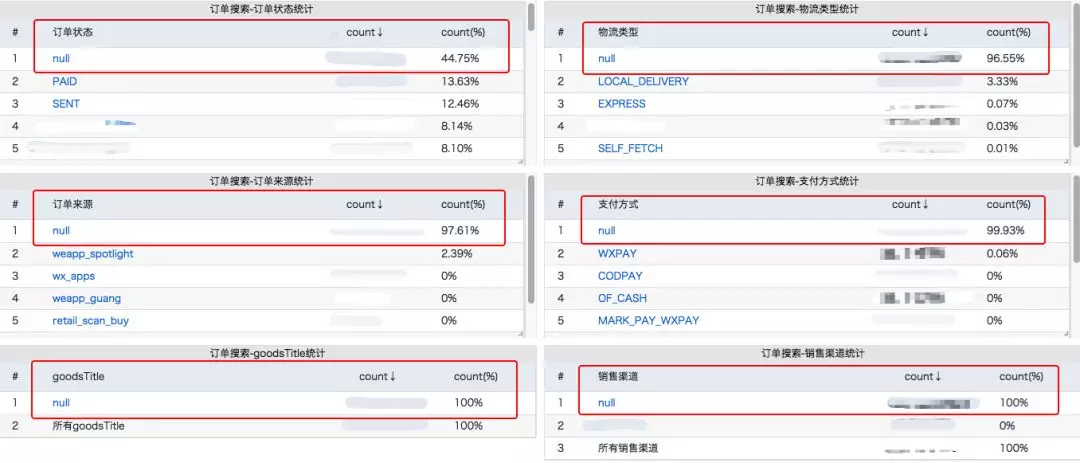
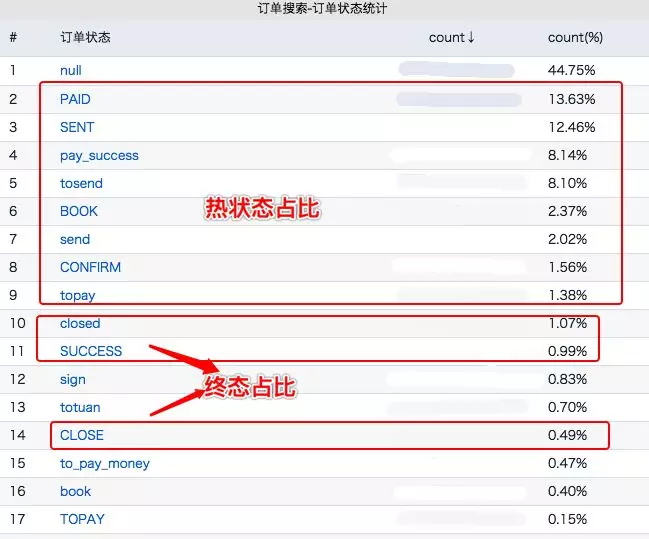
而细化了下这 53% 的订单状态搜索中,其中 3% 左右搜索终态订单(已完成,已关闭),其中 50% 所有流量全部都是搜热状态订单(待付款,待发货,待成团,待接单,已发货),-_- 忽略比较乱的枚举,历史多个版本统计合一。
不禁让人兴奋,为什么?因为无论订单量如何激增,处于热状态的订单数不会持续暴增,因为所有订单都会陆续流转到终态,比如超时 30 分钟未付款,订单从待支付变成已关闭状态,比如订单发货 7 天后,从已发货状态变成已完成。统计了下,热状态订单总量在千万级别,且一直比较平稳的进行流转。
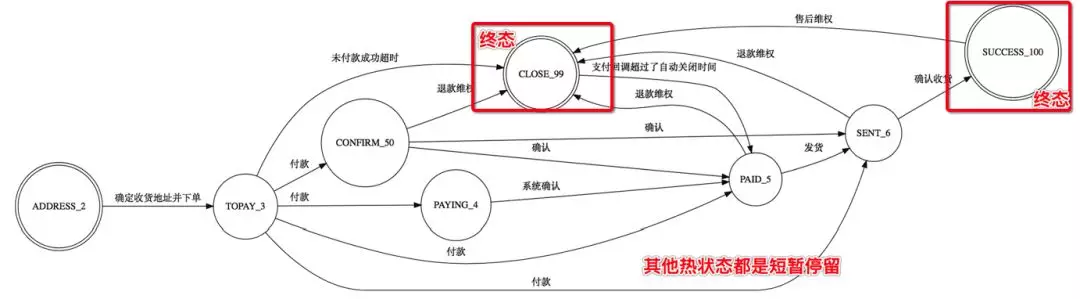
也就是说我们用这个千万级小索引,就承接了整个订单搜索一半左右的流量。无论是统计,总店查询,各种跨分片维度查询,都可以支持。因为它是一个热状态订单数据全集,包含所有分片场景,无比兴奋。目前该索引已在线上平稳运行近一年。
3.1.2 时间分片索引
那么对于那些终态订单,数据量随着订单状态流转会变得越来越大,如何扩展,时间分片是个不错的选择,有赞订单搜索早期最早做的切分就是按下单时间分片,之前业务数据量小,每半年一个,到后来发展改成了每 3 个月一个,到现在即使每一个月一个索引都显得有些庞大。具体还是要结合搜索场景,理论上终态订单检索的量比较小,也可以换个思维从产品层面有个引导,比如默认只展示最近半年订单,也是一种思路。
3.2 扩展依据
3.2.1 AKF 扩展立方体
在《架构即未来》与《架构真经》中都反复提到这个立方体,结合我们的实际情况,确实受益匪浅,给了我们指引的方法论。
X 轴 : 关注水平的数据和服务克隆,比如主备集群,数据完全一样复制。克隆多个系统(加机器)负载均衡分配请求。
-
优点:成本最低,实施简单
-
缺点:当个产品过大时,服务响应变慢
-
场景:发展初期,业务复杂度低,需要增加系统容量
Y 轴 : 关注应用中职责的划分,比如数据业务维度拆分。比如交易库,商品库,会员库拆分。
-
优点:故障隔离,提高响应时间,更聚焦
-
缺点:成本相对较高
-
场景:业务复杂,数据量大,代码耦合度高,团队规模大
Z 轴 : 关注服务和数据的优先级划分,数据用户维度拆分。比如常见的按用户维度买卖家切分数据分片。
-
优点:降低故障风险,影响范围可控,可以带来更大的扩展性
-
缺点:成本最高
-
场景:用户指数级快速增长
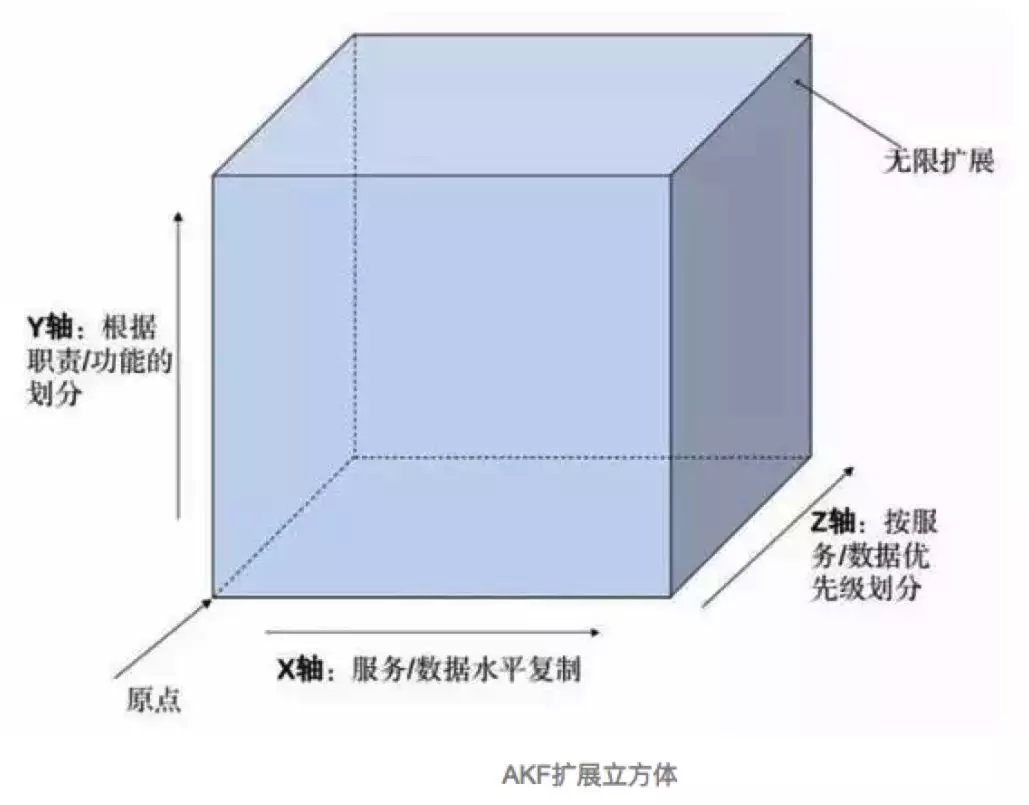
上面介绍的热状态订单拆分其实就是朝 Y 轴方向扩展,当然 AKF 可扩展立方体的精髓就在于不要一直只在一个轴方向上扩展,要根据不同的业务场景,数据规模,做到有针对性的扩展,理论上 XYZ 轴可以做到某种程度的无限扩展。目前有赞订单搜索的总体索引架构如下,涵盖 3 个轴方向。
3.3 现状
四、收获
上面简单介绍了下有赞订单搜索 AKF 扩展之路,下面再简单聊下过程中的几个意外收获,受益良多,可以给类似业务同学一个可以尝试的参考。
4.1 可扩展性索引字段设计
之前迁移到 ES 里就是看中 ES 的多索引检索能力,然而多变的产品需求通过不断加字段的模式,也会使索引变得越来越大,不好维护,有没有一种可扩展性的方式,来以不变或者以小变应对需求的万变呢。答案是肯定的,list< String > 字段设计,比如目前开放了搜索扩展点给有赞云,商家可以自定义的建立自己的检索字段,K 和 V 都有商家自己把控,如何做到代码可配置化,业务代码无感知呢,按照我们的约定需要检索的字段进入 list< k_v > 格式,即可做到。关于细节订单管理系列博文之可配置化订单搜索博文中会详细进一步介绍。
4.2 轻量级统计
统计一直是各大公司比较重要的一块,有赞也是,几乎有订单的地方都会看到各种订单数统计,早期统计场景比较简单,比如统计待发货,已发货,退款订单等都可以通过一个 sql 或者一个脚本任务就可以统计出来,但是随着有赞业务发展的越来越快,比如统计一个加入担保交易+已经完成7天内+发生退款的订单数,普通的统计模式通过更改统计 sql ,再刷个离线数据也是能做到的,但是周期往往较长,而且不够灵活,一旦有部分统计失败报错的,排查问题很困难,只能再全量重新统计。而这里我们采用了另一种视角,用搜索来做统计,�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%9C%89%E8%B5%9E%E8%AE%A2%E5%8D%95%E6%90%9C%E7%B4%A2%E6%9E%B6%E6%9E%84%E6%BC%94%E8%BF%9B%E4%B9%8B%E8%B7%AF/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


