构造对象九
本文承接 构造 IndexWriter 对象(八),继续介绍调用 IndexWriter 的构造函数的流程。
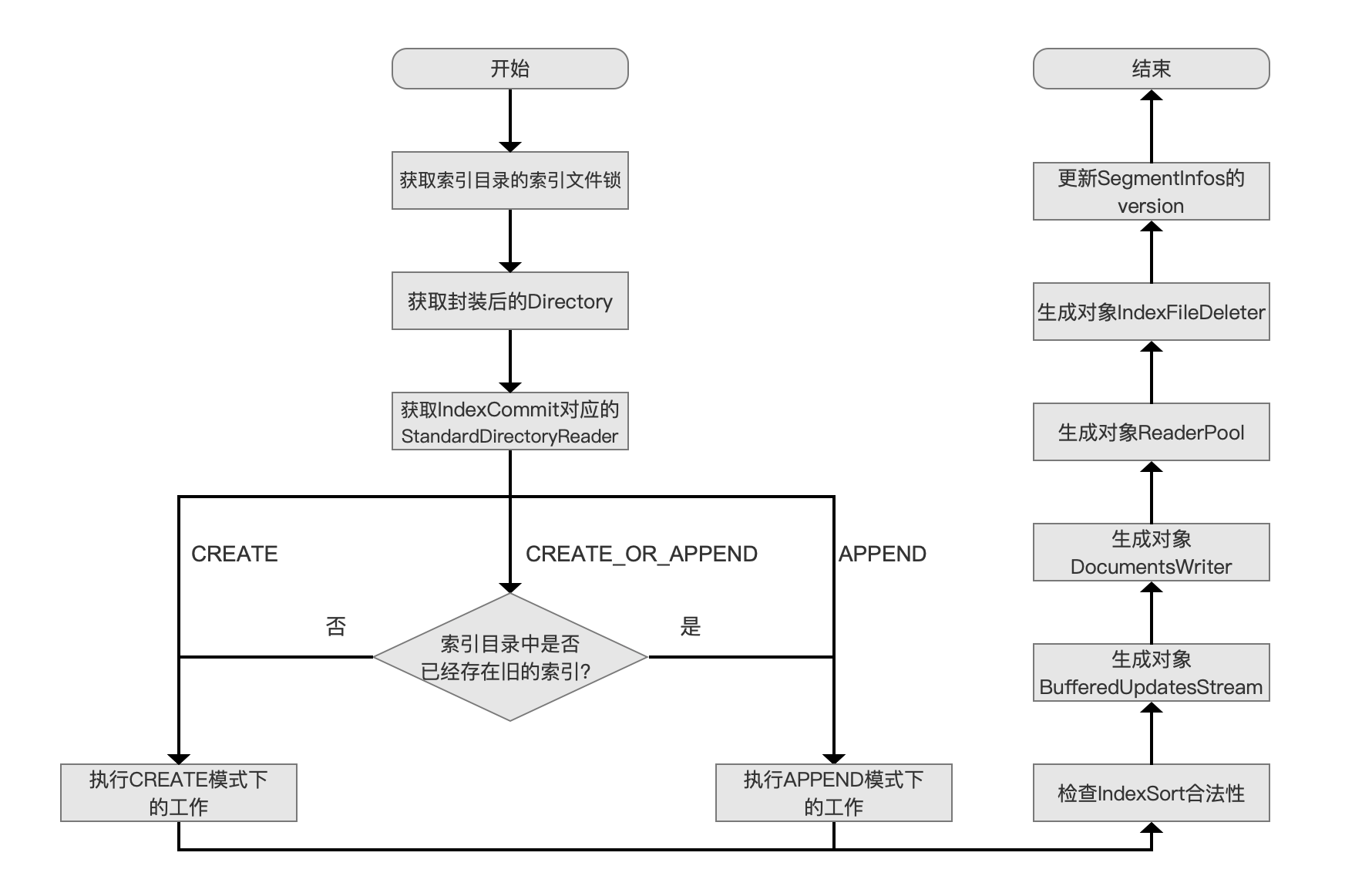
调用 IndexWriter 的构造函数的流程图
图 1:
生成对象 IndexFileDeleter
我们紧接上一篇文章,继续介绍剩余的流程点,下面先给出 IndexFileDeleter 的构造函数流程图:
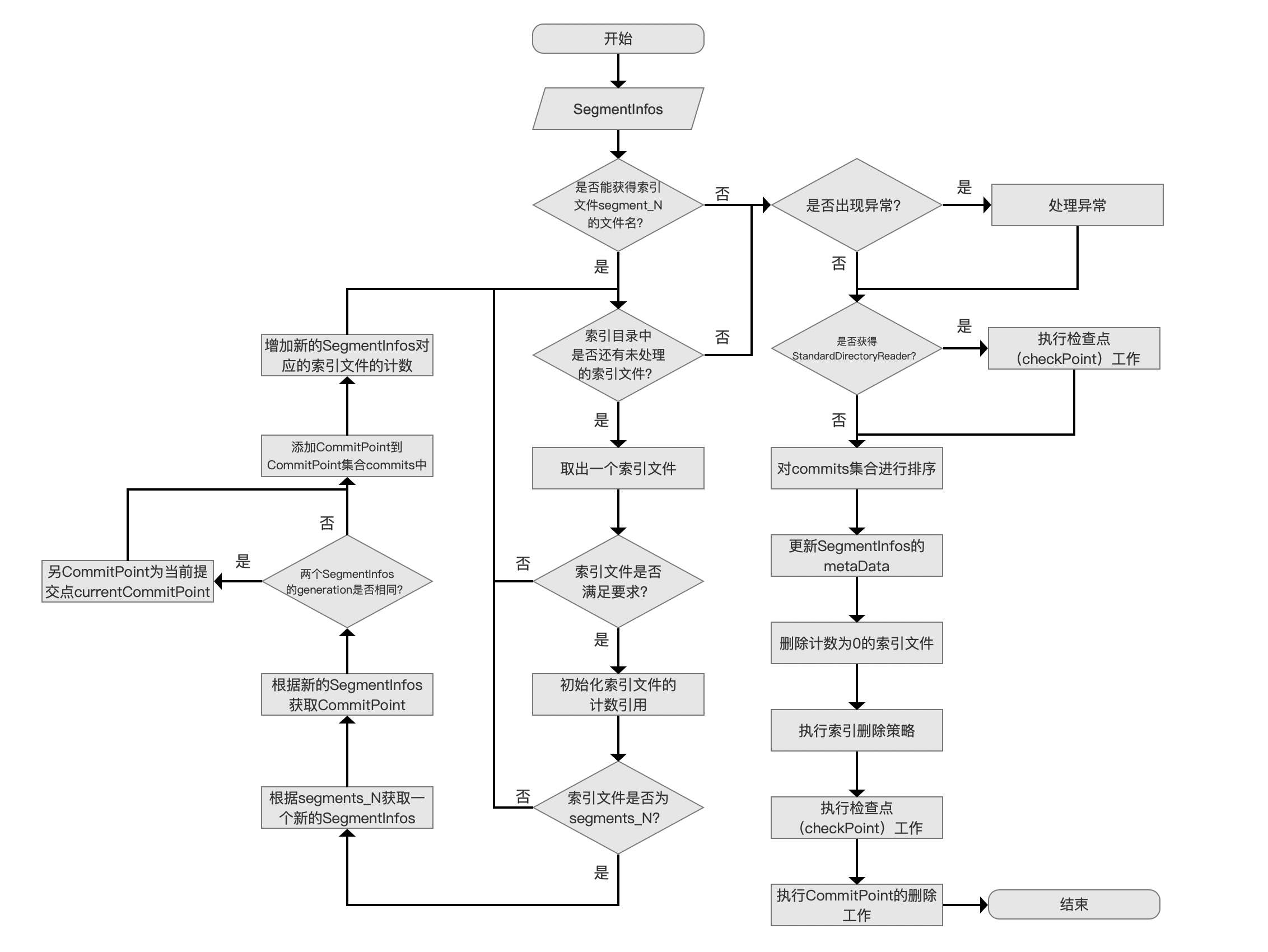
IndexFileDeleter 的构造函数流程图
图 2:
更新 SegmentInfos 的 metaData
图 3:

我们先介绍下需要更新 SegmentInfos 的哪些 metaData:
- generation:该值该值是一个迭代编号(generation number),用来命名下一次 commit()生成的 segments_N 的 N 值
- nextWriteDelGen:该值是一个迭代编号,用来命名一个段的下一次生成的 索引文件。liv
- nextWriteFieldInfosGen:该值是一个迭代编号,用来命名一个段的下一次生成的 索引文件。fnm
- nextWriteDocValuesGen:该值是一个迭代编号,用来命名一个段的下一次生成的 索引文件。dvm&&.dvd
我们通过下面的例子来介绍上面的 metaData 的用途,图 4 的例子使用的索引删除策略为 NoDeletionPolicy,完整的 demo 见: https://github.com/LuXugang/Lucene-7.5.0/blob/master/LuceneDemo/src/main/java/lucene/index/InflateGenerationTest.java 。
图 4:
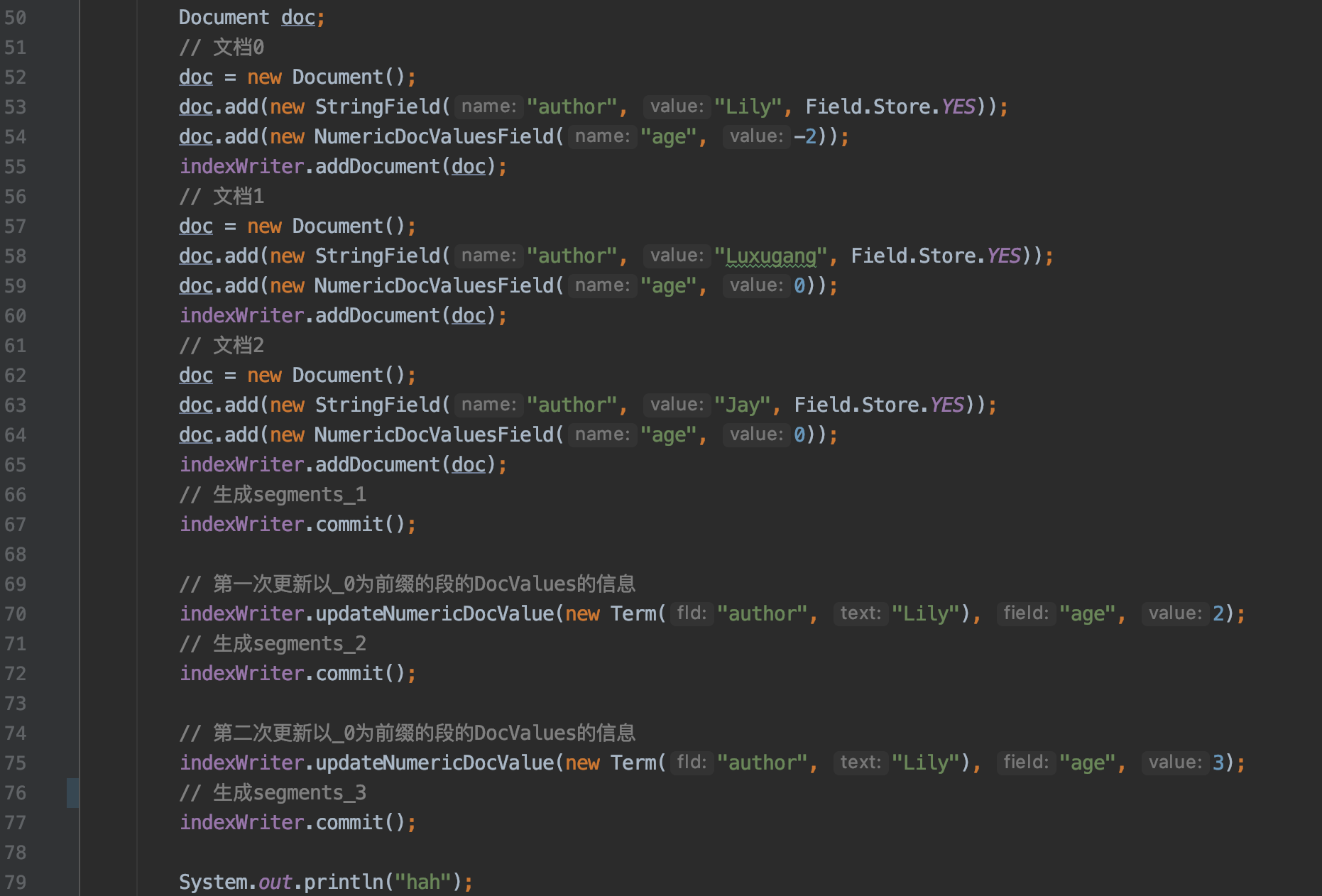
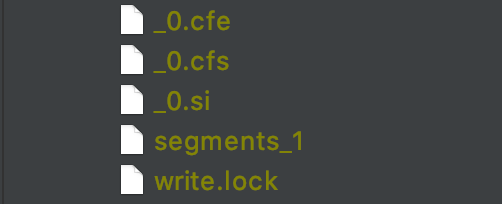
图 4 中的例子描述的是,在代码第 67 行执行 IndexWriter.commitI()之后生成一个段,该段的索引信息对应为索引目录中以_0 为前缀的索引文件,如下所示:
图 5:
随后执行了图 4 中的第 70 行的 DocValues 的更新操作,由于以_0 为前缀的段中的文档满足该更新条件,即该段中包含域名为"author"、域值为"Lily"的文档,故在执行完第 72 行的 IndexWriter.commit()操作后,索引目录中的索引文件如下所示:
图 6:
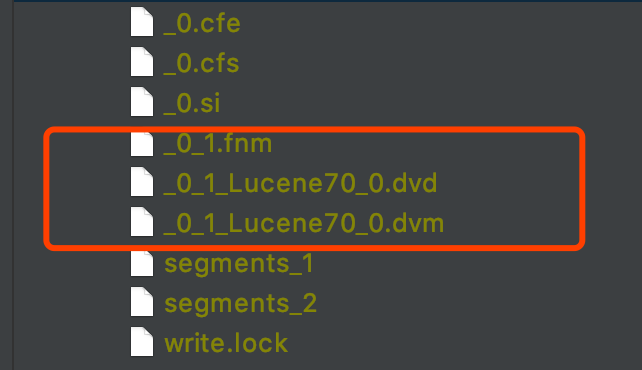
图 6 中的三个索引文件_0_1.fnm、_0_1.Lucene70_0.dvd、_0_1.Lucene70_0.dvm 描述了第一次的 DocValue 更新后以_0 为前缀的段中的 DocValues 信息,随后继续执行图 4 中第 75 行的 DocValues 的更新操作,同样的以_0 为为前缀的段中的文档仍然满足该更新条件,故在执行完第 77 行的 IndexWriter.commit()操作后,索引目录中的索引文件如下所示:
图 7:
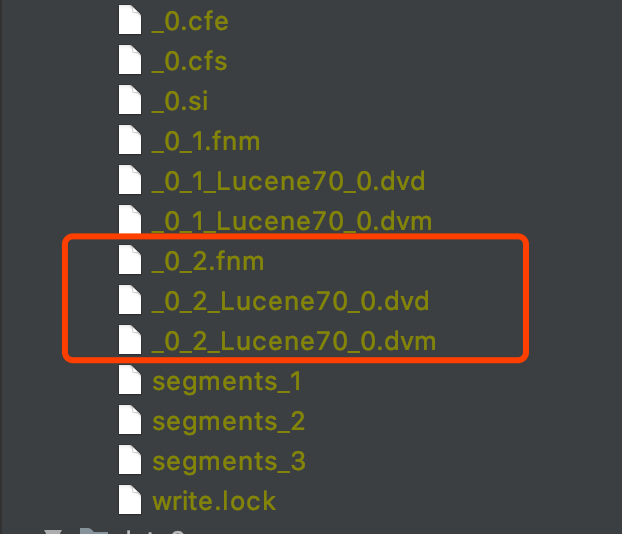
图 7 中的三个索引文件_0_2.fnm、_0_2.Lucene70_0.dvd、_0_2.Lucene70_0.dvm 描述了第二次的 DocValue 更新后以_0 为前缀的段中的 DocValues 信息。
图 8:
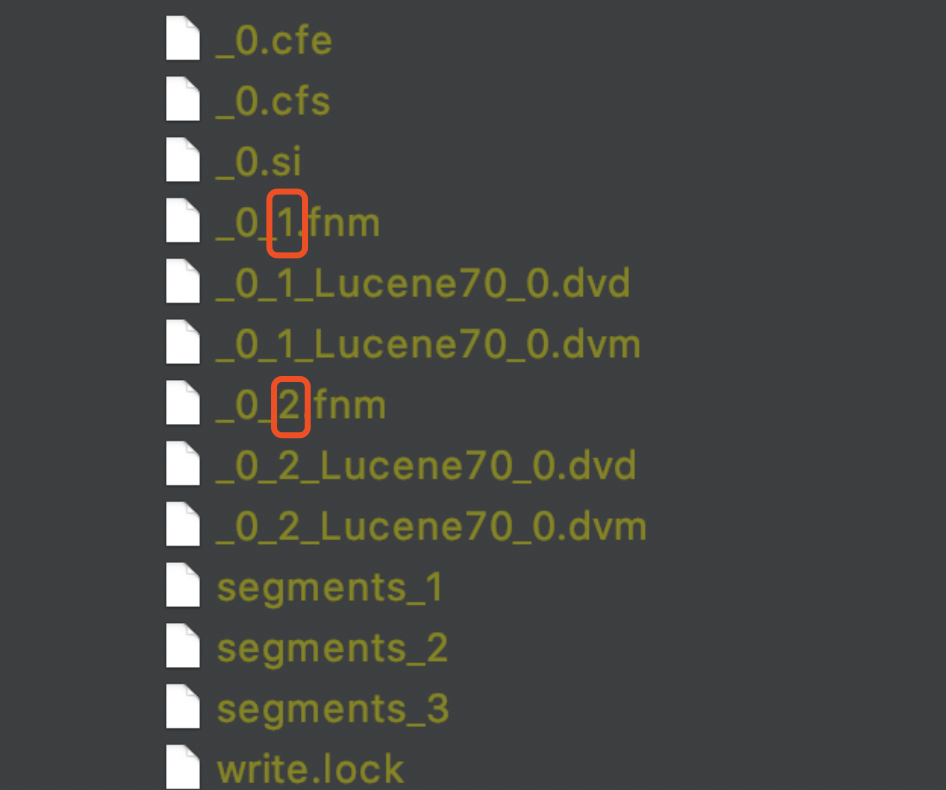
我们以两次生成索引文件。fnm 为例,nextWriteFieldInfosGen 用来命名下次生成索引文件。fnm,图 8 中红框标注的两个值即迭代编号(generation number)通过 nextWriteFieldInfosGen 来命名, 在生成图 8 的两个索引文件。fnm 后,此时 nextWriteFieldInfosGen 的值变为 3,为下一次生成索引文件。fnm 作准备,nextWriteDocValuesGen 是同样的意思,用来命名索引文件。dvd、.dvm。
我们再给出下面的例子来介绍下 nextWriteDelGen,完整 demo 见: https://github.com/LuXugang/Lucene-7.5.0/blob/master/LuceneDemo/src/main/java/lucene/index/MultiDeleteTest.java 。:
图 9:
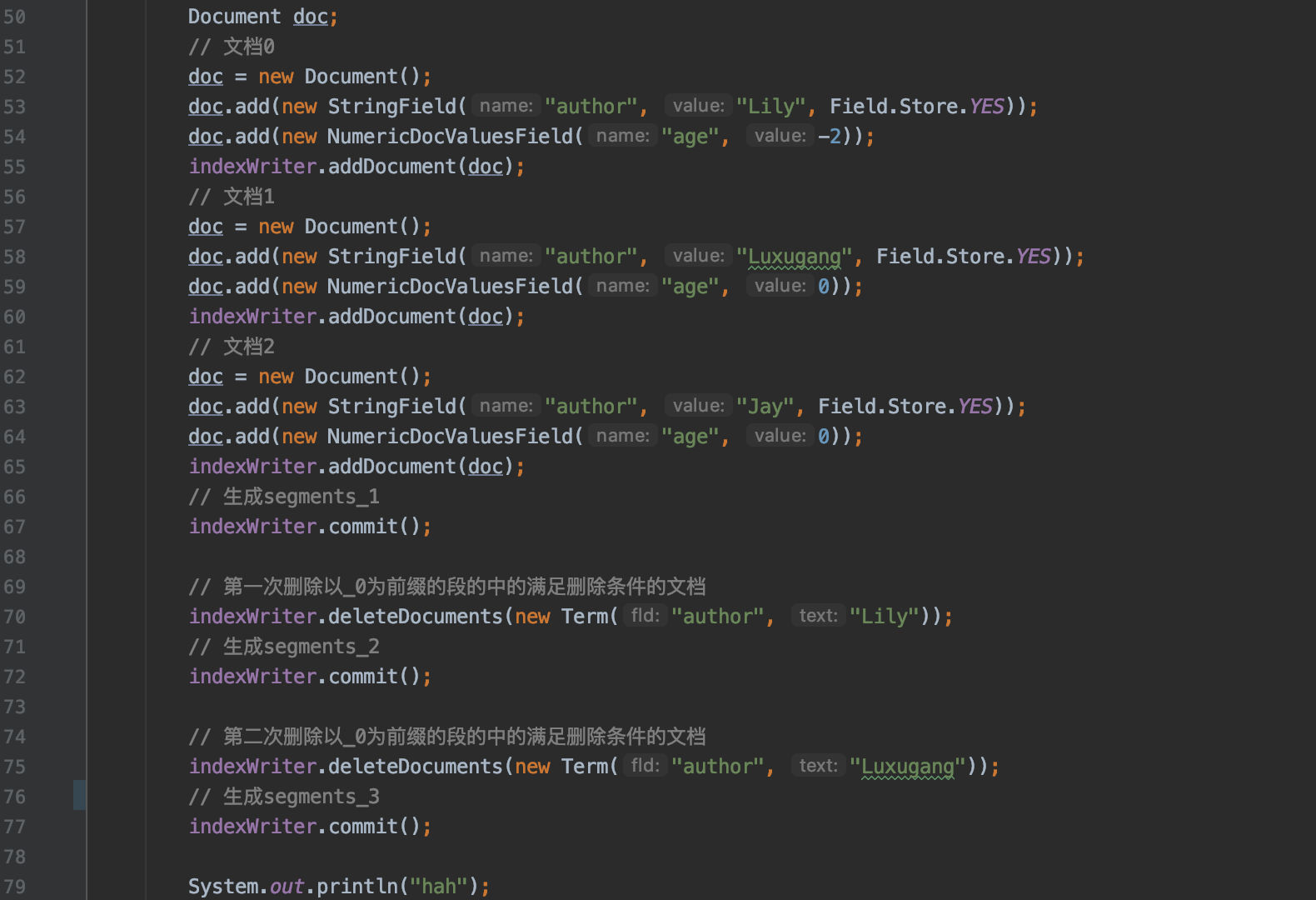
图 10:
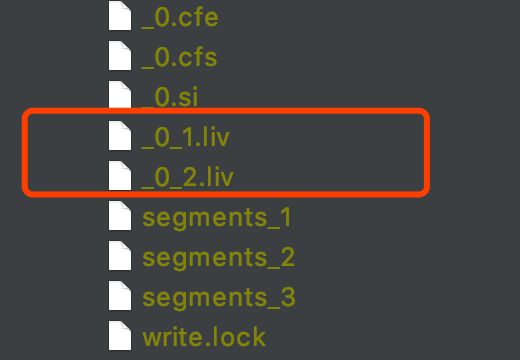
图 10 为图 9 的例子执行结束后的索引目录的内容,可以发现它跟 nextWriteFieldInfosGen、nextWriteDocValuesGen 是一样的用法。
我们换一个例子来介绍 segments_N 文件跟迭代编号之间的关系,该例子的完整 demo 见 https://github.com/LuXugang/Lucene-7.5.0/blob/master/LuceneDemo/src/main/java/lucene/index/MultiDeleteUpdateTest.java ,本文就不贴出来了,直接给出运行结束后索引目录中的内容:
图 11:
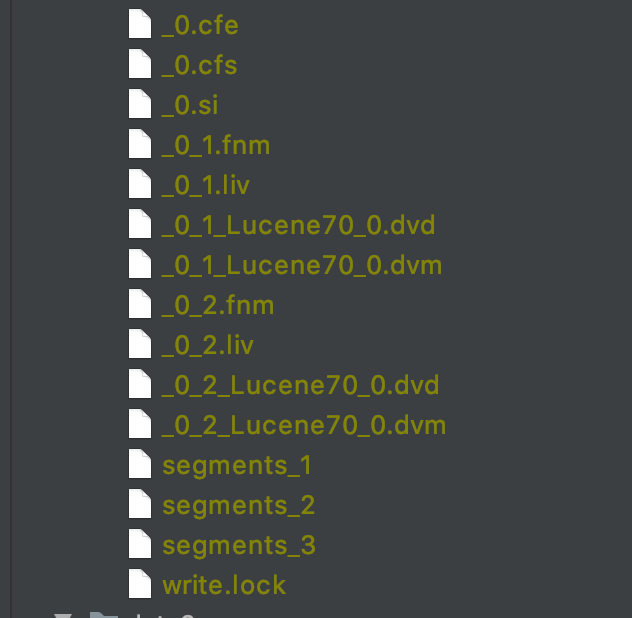
我们以图 11 中的 segments_3 为例,介绍生成的索引文件。fnm、.dvd、.dvm 的迭代编号在 segments_N 文件中的描述:
图 12:
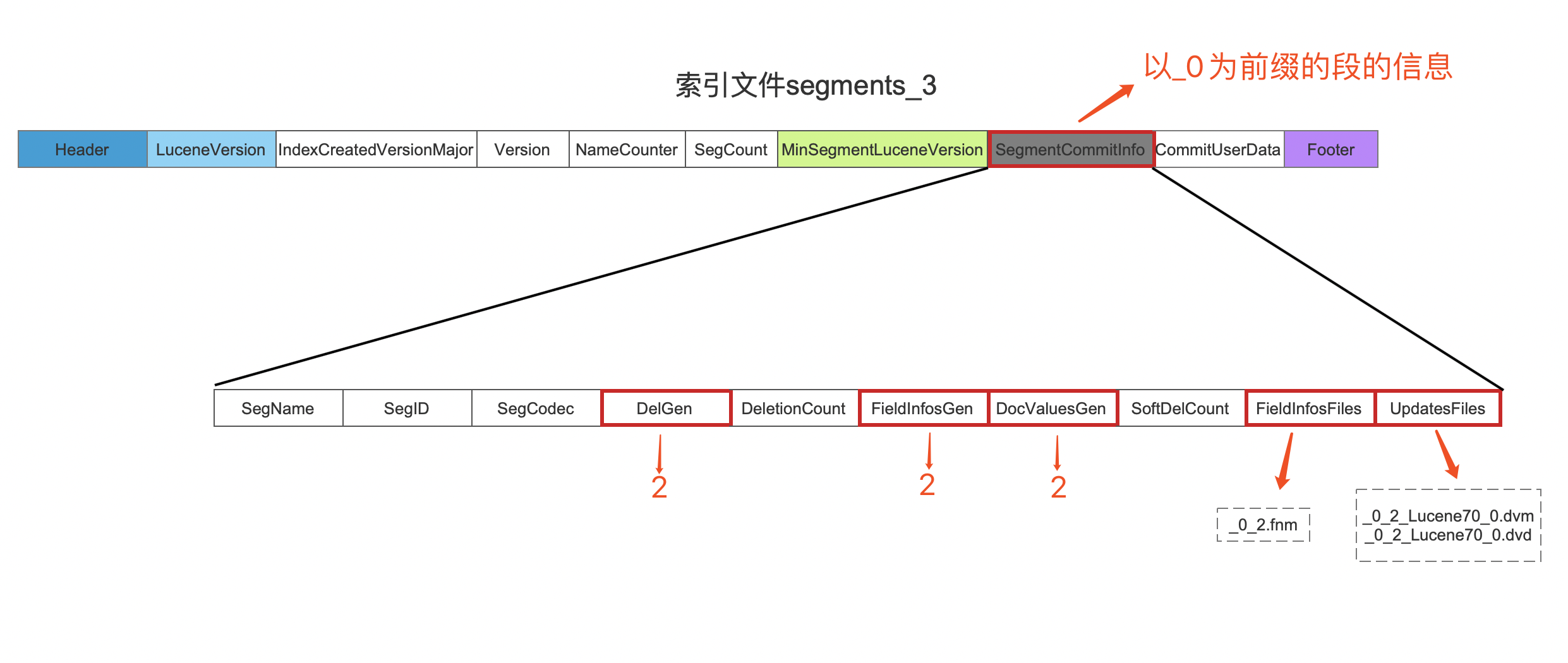
图 12 中,DelGen 即图 11 中索引文件_0_2.liv 的迭代编号,FieldInfosGen 即图 11 中索引文件_0_2.fnm 的迭代编号,DocValuesGen 即图 11 中索引文件 _0_2_Lucene70_0.dvd、 _0_2_Lucene70_0.dvm 的迭代编号,而 FieldInfosFiles 中描述的是以_0 为前缀的段的域信息对应的索引文件名,UpdatesFiles 中描述的是以_0 为前缀的段的 DocValues 的信息对应的索引文件名。
继续给出 segment_2 的例子,不作多余的介绍:
图 13:
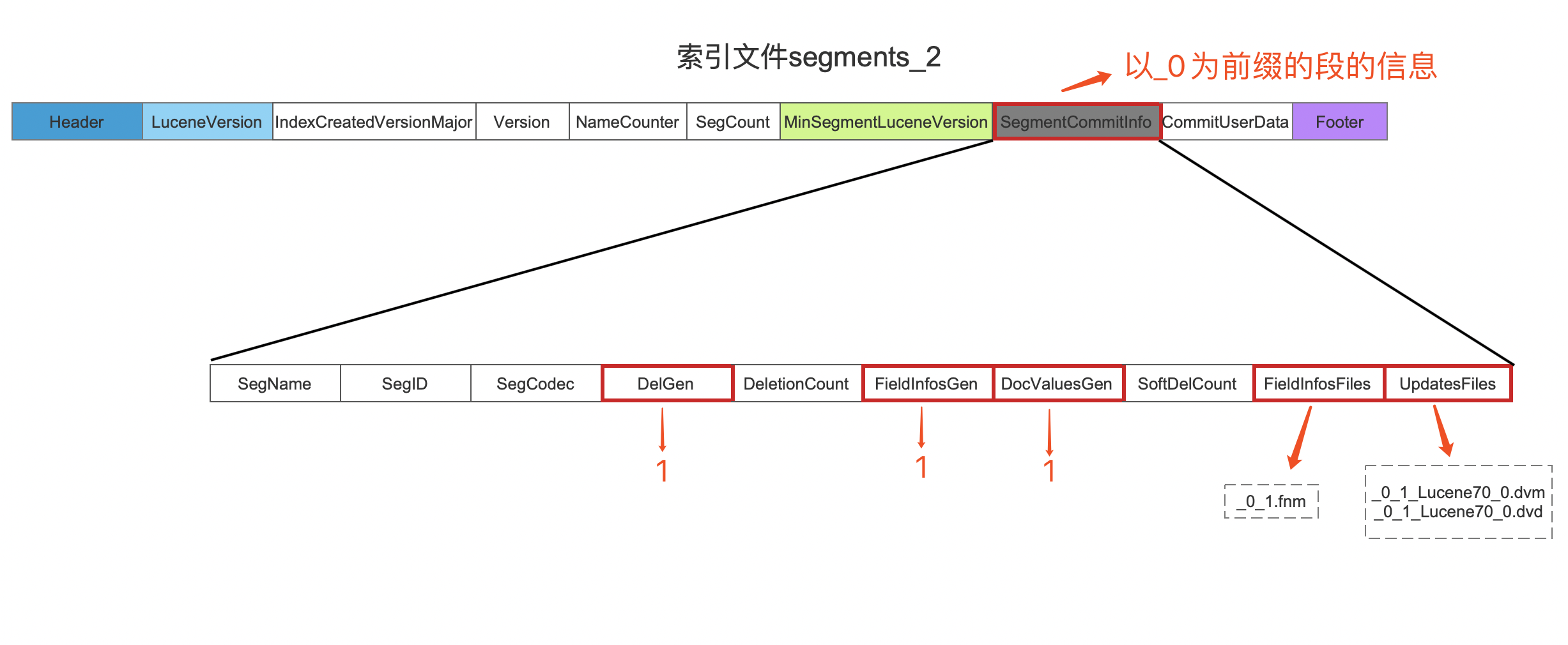
接着我们继续介绍为什么要执行更新 SegmentInfos 的 metaData 的操作:
先给出源码中的注释,该流程点对应在源码中的方法为: IndexFileDeleter.inflateGens(…) 。
Set all gens beyond what we currently see in the directory, to avoid double-write in cases where the previous IndexWriter did not gracefully close/rollback (e.g. os/machine crashed or lost power) 上述的注释中,directory 即索引目录、gens 就是上文中我们提到的 4 个迭代编号,该注释的大意描述的是,之前的 IndexWriter 没有“优雅”的退出(操作系统/物理机 崩溃或者断电),导致索引目录中生成了一些“不优雅”的文件,为了避免新的 IndexWriter 生成的索引文件的文件名与索引目录中的相同(即 double-write)可能会引起一些问题,不如先根据索引目录中索引文件找到 gens 的各自的最大值 N,使得随后生成的索引文件的迭代编号从 N+1 开始。
看完上文中的注释不然引申出下面的三个问题:
问题一:“不优雅”的文件有哪些:
作者无法列出所有的不优雅的文件,只介绍某些我们可以通过代码演示的文件,并且会给出对应的 demo:
- pending_segments_N 文件:在 文档提交之 commit 系列文章中,我们知道执行 IndexWriter.commit()是一个两阶段提交的过程,如果在二阶段提交的第一阶段成功执行后,即生成了 pending_segments_N 文件,IndexWriter 无法执行二阶段提交的第二阶段,比如操作系统/物理机 崩溃或者断电,那么在索引目录中就会存在 pending_segments_N 文件,我们可以通过这个 demo 来演示: https://github.com/LuXugang/Lucene-7.5.0/blob/master/LuceneDemo/src/main/java/lucene/index/UnGracefulIndexFilesTest1.java
该 demo 运行结束后,索引目录中的文件如下所示:
图 14:
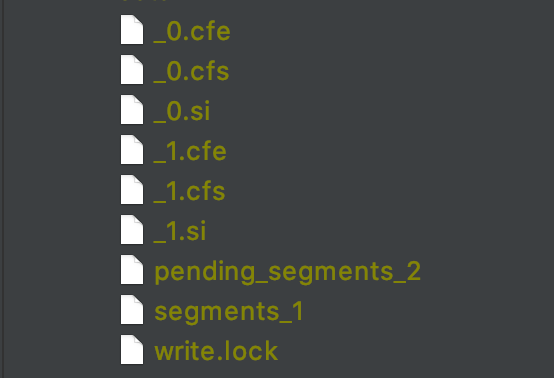
从图 14 可以看出,IndexWriter 成功的执行了一次 commit()操作,即生成了 segments_1 文件,当再次执行 commit()操作时,只成功执行了二阶段提交的第一阶段,即只生成了 pending_segments_2 文件。
- 修改了索引目录中的内容,但是没有 commit:执行了文档的增删改之后,但是没有执行 commit()操作就异常退出了,那么上一次 commit 之后的生成的索引文件都是“不优雅”的
- 无法删除的索引文件:由于本人对文件系统没有深入的理解,这方面的内容不敢妄言,故直接给出 Lucene 在源码中的解释
On windows, a file delete can fail because there is still an open file handle against it. We record this in pendingDeletes and try again later. 问题二:为什么新的 IndexWriter 生成的索引文件的文件名可能会与索引目录中的相同:
我们先给出 SegmentCommitInfo 对象的构造函数:
图 15:
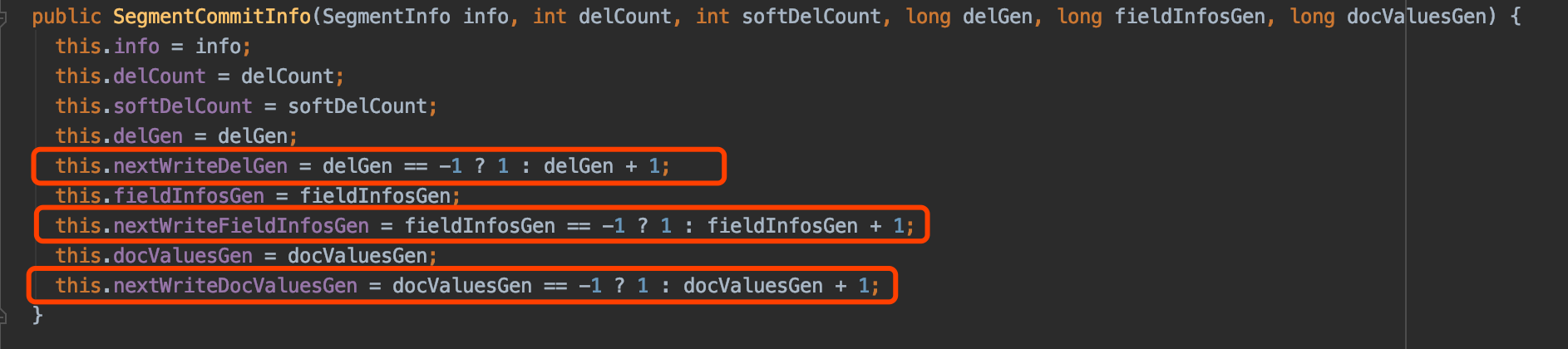
我们以图 11 为例,如果我们另 segments_2 中的内容作为 IndexCommit 来构造一个新的 IndexWriter,此时以_0 为前缀的段的 delGen、fieldInfosGen、docValuesGen 都为 1,那么根据图 15 的构造函数,nextWriteDelGen、nextWriteFieldInfosGen、nextWriteDocValuesGen 都会被初始化为 2,也就说如果以_0 为前缀的段在后续的操作中满足删除或者 DocValues 的更新操作,新生成的。fnm、.dvd、.dvm 的迭代编号就是 2,那么就会出现与图 11 中的索引文件有相同的文件名
问题三:新的 IndexWriter 生成的索引文件的文件名与索引目录中的相同(即 double-write)可能会引起哪些问题:
其中一个问题是即将生成的某个索引文件的文件名与索引目录中某个无法删除的索引文件的文件名是一致的,那必然会出问题,另外在 Linux 平台,如果挂载的文件系统是 CIFS(Common Internet File System),也是有可能出现文件无法删除的情况。
综上所述,能避免这些问题的最好方式就是根据索引目录中索引文件找到 gens 的各自的最大值 N,使得随后生成的索引文件的迭代编号从 N+1 开始,使得新生成的索引文件不可能与索引目录中的任何索引文件重名。
删除计数为 0 的索引文件
图 16:

该流程用来删除索引目录中那些计数为 0 的索引文件,那么问题就来了:
索引目录中哪些索引文件的计数会为 0 呢::
我们在文章 构造 IndexWriter 对象(八) 中说道,在图 17 的流程中,会根据索引目录中的 segments_N 文件,找到对应的所有索引文件,然后增加了这些索引文件的计数�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%9E%84%E9%80%A0%E5%AF%B9%E8%B1%A1%E4%B9%9D/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


