查询性能调优实践亿级数据查询毫秒级返回
1、概述
本文简要描述ES查询性能的优化过程。忽略很多细节,其实整个过程并不顺利,因为并没有一个明确的指引,教你怎么做就能让性能大幅提升。很多时候不同业务有不同的场景,还是需要自己摸索一番。比如用filter过滤取代query查询,明明官方文档说filter速度更快。但应用到我们业务来,一开始却没有明显效果。经过反复测试,发现虽然filter可以省略计算分数的环节,但我们的业务查询场景,一次返回数据量不会很多,最大的瓶颈不在于打分,而在于range过滤和排序。可是range过滤和排序,这方面在网上却很少被提及。所以还是要自己根据业务场景多思考多验证。
一开始优化效果很突出,耗时从100秒一下子降低到10秒以内。但越往后其实越难做。好比从10分考到60分不容易,但90分考到95分就更加困难。
我们自己定的优化目标是1秒,是达到效果了。
2、ES查询性能优化效果
优化前,随便一个ES查询耗时就高达170秒,接近3分钟。

注意上面的ES查询语句还不是最复杂的,还可以加上qua搜索、关键词模糊搜索,再把日期范围拉长,再加上日期排序。无法想像,耗时会变得多么惨不忍睹,简直要变成离线查询了。
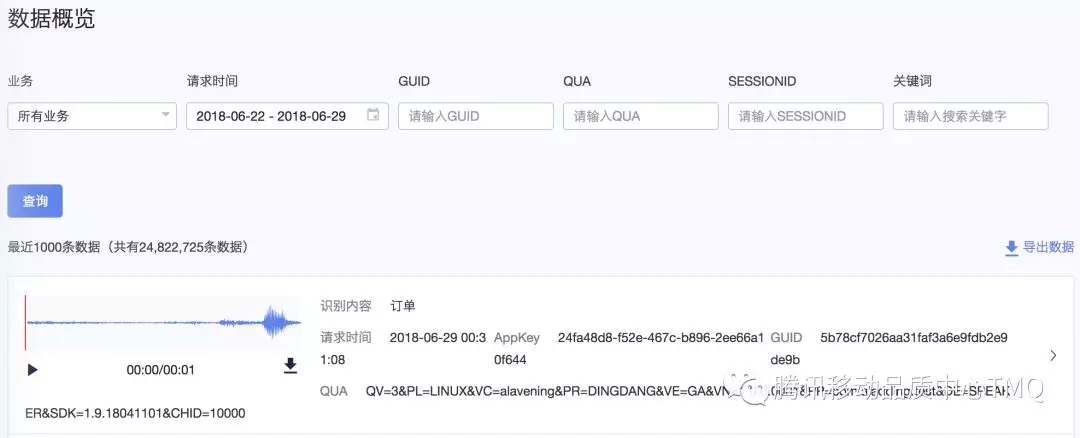
可实际上,yiya页面是在线用户进行实时查询,所以这么高的耗时是不能忍受的,需要优化。那么,数据量有上亿,耗时优化到多少才合适呢?作为一个实时接口,能不能做到1秒内ES查询返回结果呢?
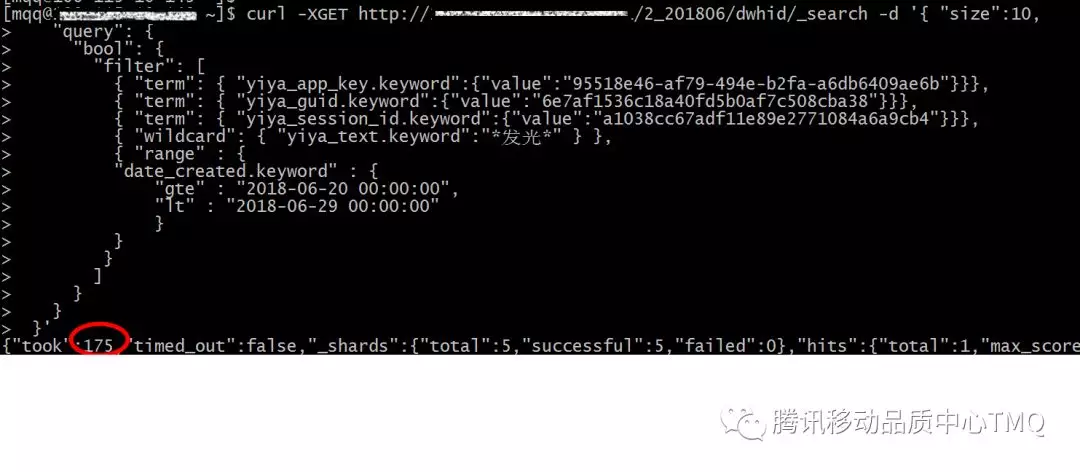
经过优化,ES查询耗时从之前的动辄3分钟,已经变成毫秒级了。
3、ES查询性能调优
3.1 拆分索引
ES能存千亿数据,不表示你可以在匹配到千亿数据时还能秒级返回。拆分索引是指你在搜索时,必须尽量缩小搜索的数据集范围。
-
按照数据源拆分,每个数据源独立索引。
-
按照时间拆分,每月建索引。
原先是按照数据源天然地分开索引。但日积月累,单个数据源的数据也日益膨胀,月新增一亿条数据。所以要按照时间拆分,把单个数据源按照年月进一步地拆分。
3.2 字段拉平
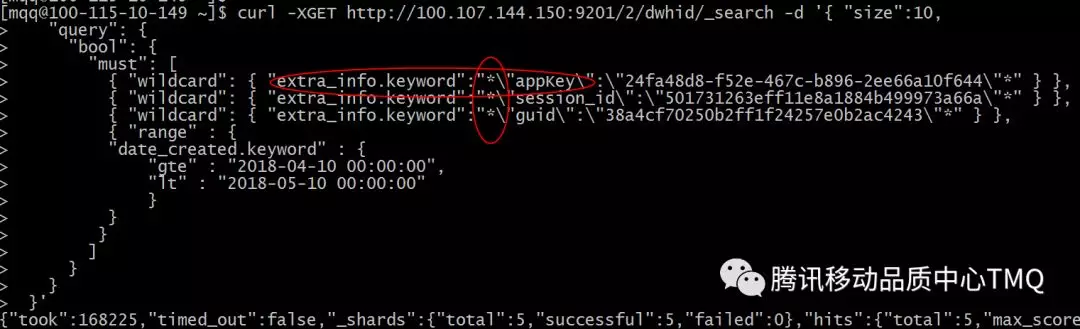
原先是把几个搜索字段都放在extra_info里面,导致只能在extra_info进行搜索。这带来两个问题:
-
extra_info字段巨大,查询性能很低。
-
由于extra_info字段是黑盒,只能在里面进行模糊匹配,性能进一步降低。
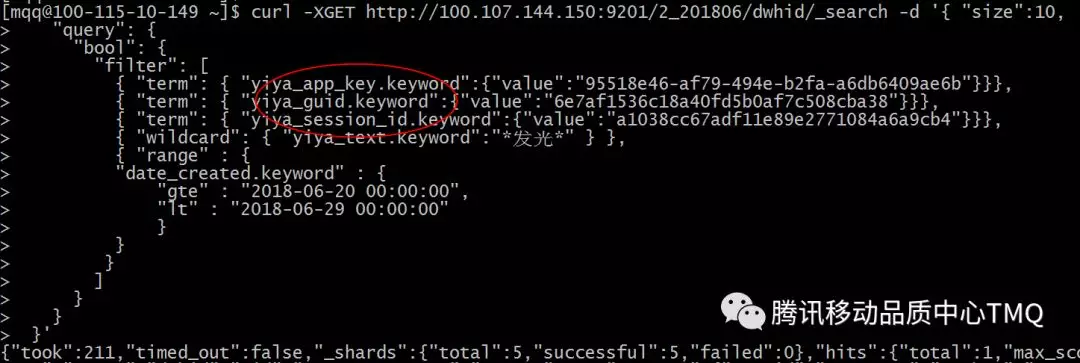
优化后,把搜索字段全部拉平到上一层,不再从extra_info字段进行查询。
3.3 减少模糊匹配
模糊匹配耗时会随数据量线性增长,尽量使用match匹配(有索引),避免使用模糊匹配(wildcard)。
跟yiya业务方沟通过,qua字段的搜索没有必要是模糊搜索,所以修改为精确匹配。
但业务方要求关键词搜索必须是模糊搜索。不过即使模糊匹配,也尽量避免左模糊这样的模式匹配,资源消耗严重。可以使用match进行分词搜索。
3.4 使用日期字段搜索范围
原先ES的日期date_created字段是用字符串存储。

但对字符串的字段类型进行range过滤并不高效。
字符串范围适用于一个基数较小的字段,一个唯一短语个数较少的字段。你的唯一短语数越多,搜索就越慢。
数字和日期字段的索引方式让他们在计算范围时十分高效。但对于
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%9F%A5%E8%AF%A2%E6%80%A7%E8%83%BD%E8%B0%83%E4%BC%98%E5%AE%9E%E8%B7%B5%E4%BA%BF%E7%BA%A7%E6%95%B0%E6%8D%AE%E6%9F%A5%E8%AF%A2%E6%AF%AB%E7%A7%92%E7%BA%A7%E8%BF%94%E5%9B%9E/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


