浅谈有赞搜索质量保障体系
作者:张家瑜
部门:业务中台/测试开发
前言
有赞搜索中台的前身是ES中间件,并没有一个中台的概念,相应的就会有一个问题,业务接入搜索场景的时候还需要为此投入开发资源同步搜索设计,一个需求上线往往耗时很久,重复性工作较多,所以就有了后来的搜索中台的成立,将搜索完整链路的复杂性折叠成一个简单完整的搜索产品,让业务方直击搜索需求,无需费心搜索实现;在此前提下,如何针对搜索中台进行一个从0到1的完整的质量保障也是一个挑战,且中台面临的问题可能跟传统业务面临的不大一样,保障手段也需要更多样化。
一、搜索质量面临的问题及痛点
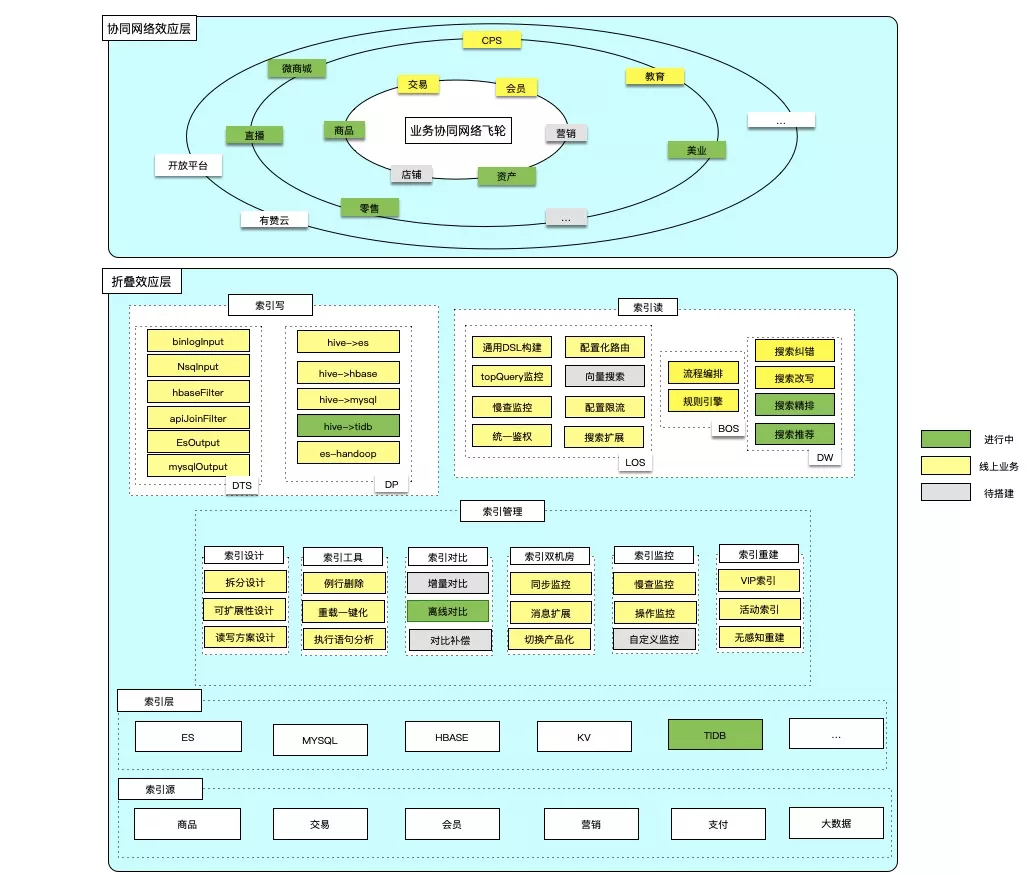
目前搜索业务架构如下图所示,笼统的说可以分两层,最上面一层协同网络效应层,也就是服务业务层,包括商品、交易、会员、营销、资产这几个核心业务场景,还有外围的零售、教育、美业、直播业务,第二层折叠效应层,将各种底层能力折叠在一起,包括索引写,索引读,索引管理,集群管理,其中集群管理包括双机房同步、索引重建、重载、监控等,依赖的组件不限于ES,还有Hbase、DTS、Flink、DP等;
针对服务应用层、底层能力支撑层都面临着不同的问题,概括的分为三个部分,分别是影响面评估不准、流程规范为零、稳定性较差:
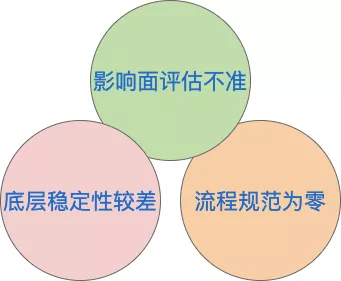
痛点1:影响面评估不准
服务业务层面临的最大的问题就是业务场景评估,目前有赞搜索业务几乎包含B端C端大部分核心业务,读场景占比量更大,例如B端商品管理页面、订单管理页面、会员业务搜索等,这时候就会遇到一个问题,如果ES进行了升级或者底层做了改造,怎样才能保障上游各个业务场景都没有问题,怎样保障回归用例完全覆盖,避免引发业务线上故障,是搜索中台核心要考虑的问题。
痛点2:底层稳定性较差
这块问题主要集中在底层集群,ES集群抖动会直接影响上游业务,在搜索前期不仅缺少一系列的监控报警,双机房切换也是纯手工一行一行操作,除此之外搜索涉及到的技术栈不止ES组件,还涉及到Hbase、Flink、DTS、NSQ等等,期间任何一个组件出现问题都会导致搜索读写异常,线上出现任何波动我们除了重启只能坐以待毙,需要整理出一套见招拆招的紧急预案;除了集群自身的问题,业务方的正确使用也是一个关键点,例如大in操作或者数组oversize这些如何避免,慢查query如何及时检测优化等等。
痛点3:流程规范为零
有赞搜索中台刚开始是以ES中间件为基础一步步搭建起来的,流程规范为零,一条业务线从搭建初始到后面能够正常运转,中间少不了开发跟测试同学之间做好的各种约定,且双方能够很好的执行这些约定才能保障这条业务线的稳定性,搜索中台的业务迭代很复杂,除了一些项目支持、日常支持之外,还会有比较多的压测需求、索引迁移、集群切换等等,针对每个模块都需要制定相应的规范及约定。
为了解决上述痛点,搜索中台质量侧从如下几个方面进行落地实践:
二、多方位保障手段
1 基线用例集补齐
为了保证用例集尽可能的覆盖业务场景,搜索中台的持续集成包括三个部分:流量回放+小流量场景补全(ci集成用例)+场景用例执行集;
- 流量回放:目前搜索主要接流量回放的场景都是读场景,经评估搜索读应用可接入应用12个已接入12个,涉及读接口35个,每个读接口对应的场景都配置相应标签识别,整体可覆盖读场景80%以上,但是流量回放有个弊端,能覆盖80%的场景,剩余的20%的场景因流量太小可能采集不到,这样就需要额外的集成用例补充以保证用例集的完整;
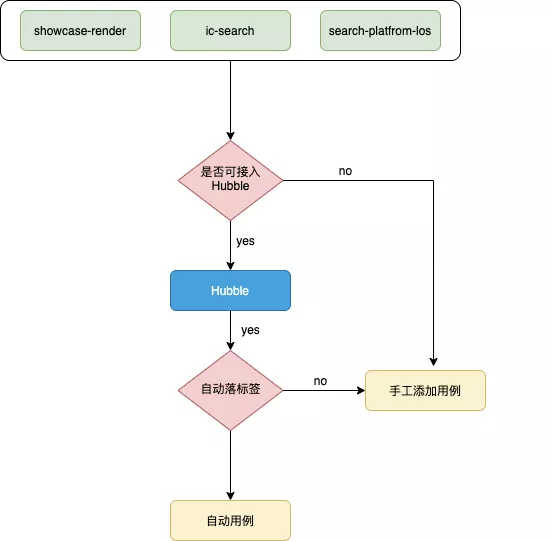
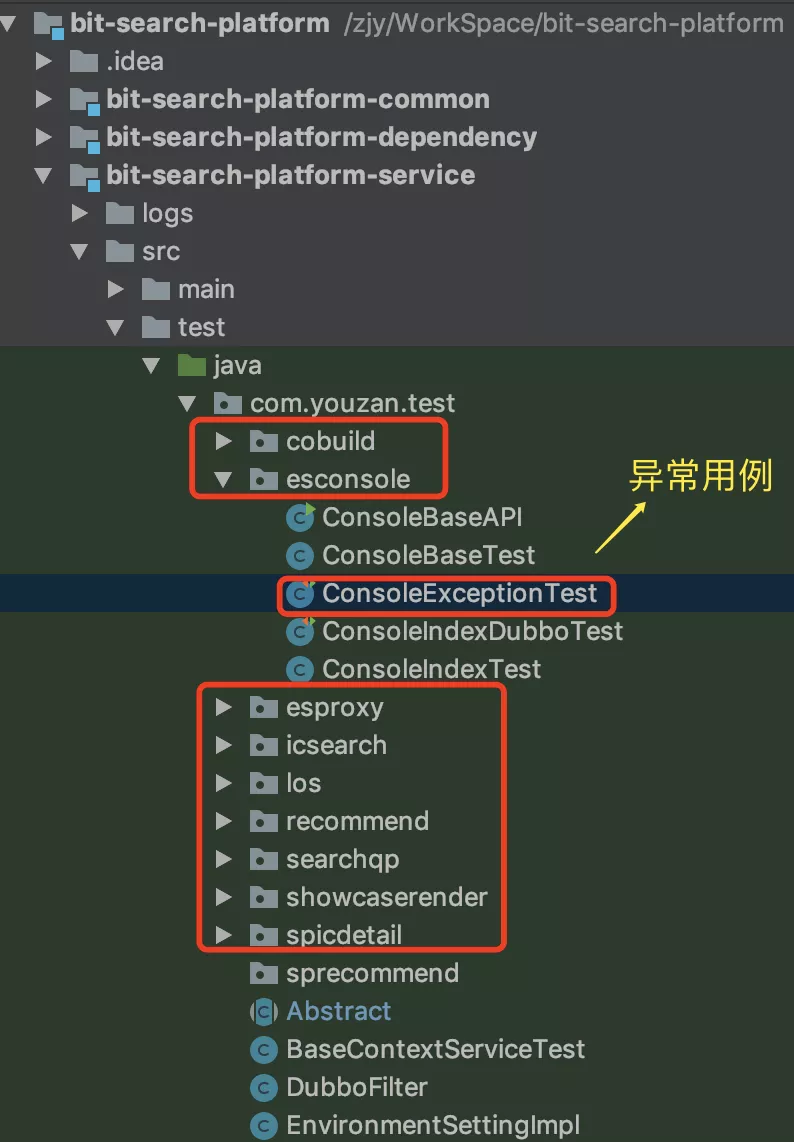
- CI集成用例:我们单独搭建了搜索测试工程:bit-search-platform,用以补充剩下的小流量场景用例及异常用例,包括业务层的ic-search和showcase-render,底层的es-proxy及console等等;
- 场景用例执行集:以上两种都是针对应用级别的用例,但是如果支持项目的话,需要单独的用例执行集,方便开发自测和测试回归,我们针对几个大模块在接口测试平台补充了相应的核心场景执行集,例如:C端商品搜索、B端商品搜索、搜索BOS场景等。
2 业务及集群稳定性实践
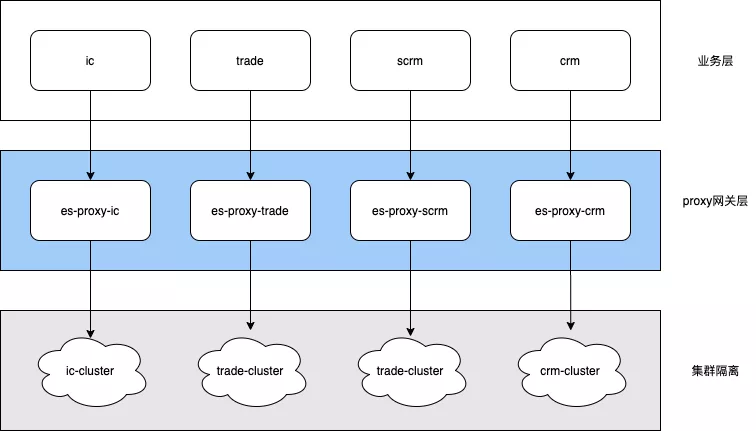
原架构中底层es-proxy承接整个公司的读写流量,不同业务公用一套应用难免就会相互影响,例如商品业务这边有大量读操作过来了,走到proxy会把线程池占满,请求会大量堆积在线程队列里无法处理,从而影响其他业务线。此问题是线上偶发问题,在测试环境和压测中会被放大,测试抛出风险推开发出优化方案。优化方案最终采取dubbo分组隔离的方式进行业务隔离,如下图:商品业务线走ic分组、交易业务线走trade分组,这样的话大流量的C端商品读并不会影响到交易订单搜索了,实现了业务单元的影响隔离;本次的架构升级给后续的整个搜索业务和集群的稳定性做了不少贡献。
接下来会从三个方面具体介绍搜索稳定性保障:性能专项、演练预案、监控治理:
2.1 性能专项测试
目前搜索业务的性能需求主要分以下三点:
- 业务域如交易域和商品域核心索引搜索场景基线SLA支持及es底层线上单链路摸高;
- 各业务方对ES千奇百怪的使用方式引发的超时reject等进行压测比对(nested嵌套、multi_search、agg等);
- ES版本升级时,官方提供的专门针对ES集群的压测工具,通过搭建集群环境及不同类型数据的准备,对ES单datanode和多datanode进行压测比对,得出集群整体基线SLA;
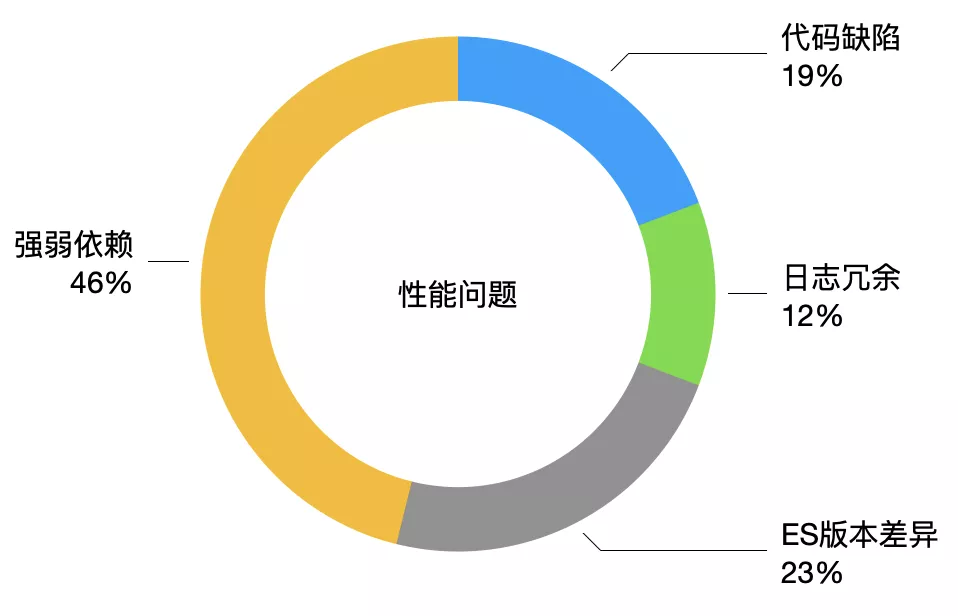
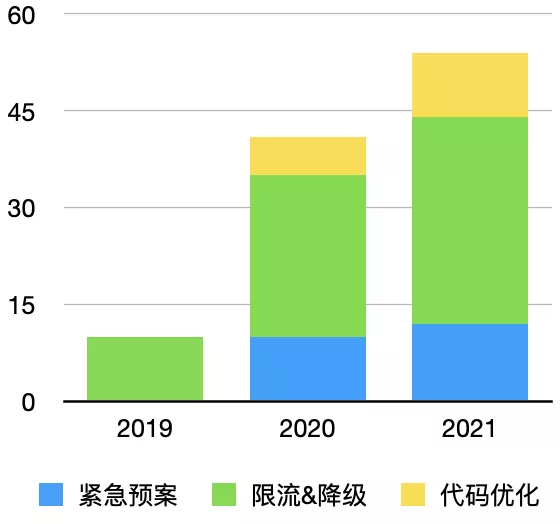
压测过程中共发现性能问题粗略计算下来26个,主要集中在强弱依赖,这就涉及到强依赖如何进行兜底、弱依赖如何降级的问题;

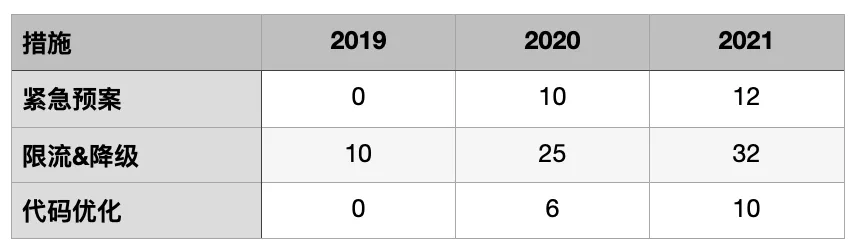
下面统计了一下从2019年中开始到目前为止通过性能压测手段间接推进落地的一些措施,核心在限流降级:
2.2 演练及紧急预案
2.2.1 演练
针对异常及故障进行常态化演练,包括ES双机房切换演练、索引迁移演练、业务线日常演练,异常演练等等,截止目前为止大大小小的演练执行了大概18次,值得一提的双机房切换演练,往年ES双机房切换方案无脚本化执行,纯手工敲命令,全靠经验跟临场发挥,切换耗时基本1个小时以上,且每次切换必修数据,耗时耗人耗精力,演练的目的是为了快速高效切换,一键脚本化,保障了切换时间保持在10分钟内,打破了“ES一切换必故障”的魔咒!

2.2.2 预案
通过演练以及结合线上问题预估出可能的风险,推进开发进行一些技术改造,配合执行验证预案效果,下图为核心的几个预案:

简单举例:
ES异常处理Tips:
ES集群异常场景大部分都会涉及到一个索引切流到备的操作,我们通过apollo配置双机房分流,紧急情况直接切备:
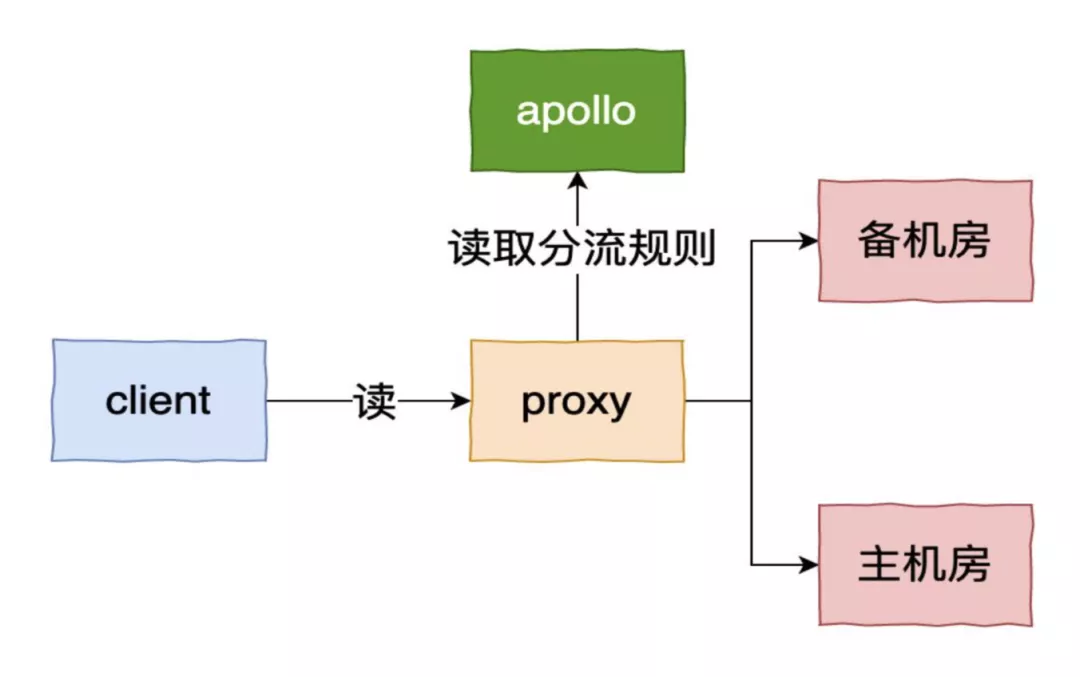
但是如果切备还解决不了问题,就需要对集群做更细粒度操作,问题大致可分为以下几个异常场景:
1、proxy线程池满
- 先检查确定问题诱因,proxy或者ES集群,观察ES集群是否健康
- ES集群问题,处理不过来负载高出现reject
- 写reject提高吞吐量,修改refresh_interval(默认5s)改大
- 读reject,增加proxy层Tesla索引限流
- 如果某一机器出现reject,分片迁移,使集群平衡
2、CPU高负载爆满
- 清除集群缓存
- 更改索引刷新时间,将refresh_interval(默认5s)调大
- 切到备机房,将问题索引切到备机房
- 迁移分片,使集群平衡
- 针对索引限流,避免影响其他索引,Tesla限流
- 重启,某个节点上执行
3、某一节点不可用
- 切备,单独索引切备
- 重建索引,导入备份数据
2.3 监控治理
搜索承接将近300个的索引,每个索引的慢查或者错误使用都可能会拉高整体集群的load,所以急需一套完善的监控体系实时监控各条业务线及索引的操作情况;
搜索监控治理主要为事前、事中、事后:
事前监控
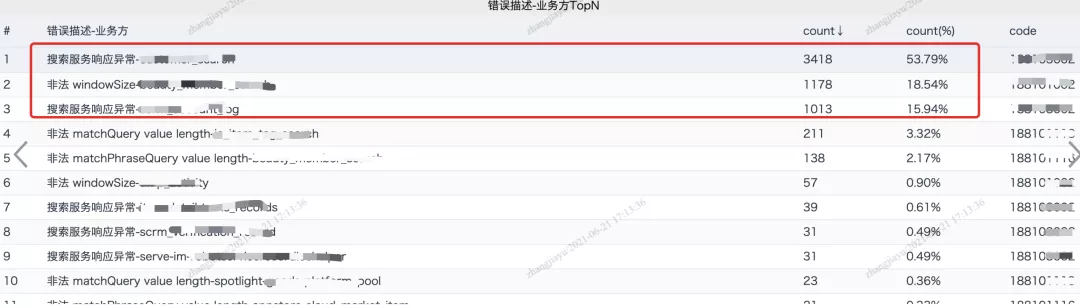
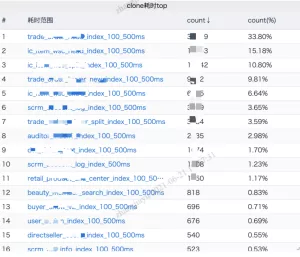
ES慢查统计、Top Query、错误码监控、总体性能指标、操作占比等,这些以天网大盘的形式实时监测,目前总共配置了11个大盘,主要是为了提前感知到业务方错误使用的方式和慢查Query的业务场景,如下图所示:
事中监控
主要包括应用级别监控,底层集群监控,另外还有依赖的中间件监控,Tesla告警等,主要是应用发布或者集群索引迁移的时候能够及时观测应用及集群情况;
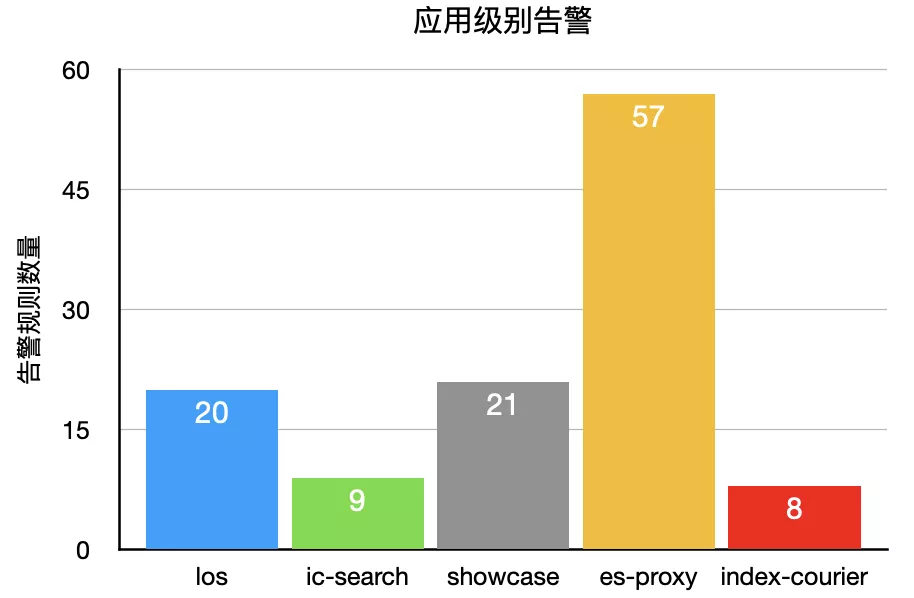
应用级别:L1L2级别应用已经全部覆盖,告警项有rt、同比、线程池、KV及NSQ等;
ES集群:grafana监控26个,告警涉及到每个集群的CPU、磁盘、bulk及search操作,load等;
中间件主要有:kv、nsq配置在应用级别,flink监控告警配置在任务级别;
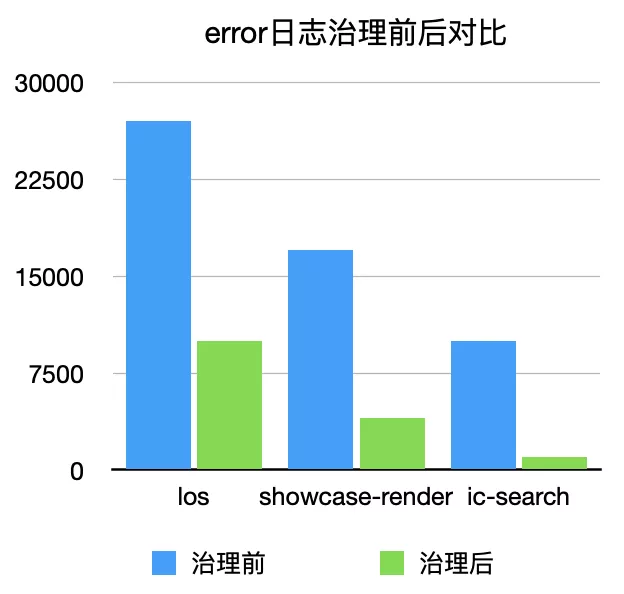
此外错误日志治理是2021 H1重点,为了提高error日志的准确性,降低排查难度,目前L1应用error量至少降低60%,报警粒度细化到了场景,例如“获取商品详情异常”、“店铺服务异常”、“美业深翻&value过长”等等;
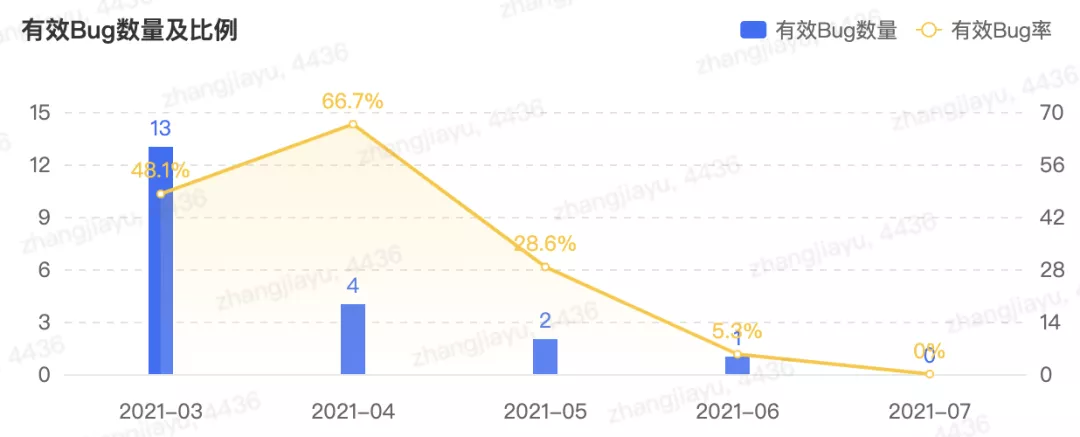
经过2021年上半年监控告警治理,线上有效bug数明显降低,如下图所示:
事后监控
搜索事后监控场景不是很多,事后的线上数据如果有问题肯定也是“木已成舟”,主要包括BCP定时对账,即同步链路上Hbase与es数据对比,还包括一些索引级别的每天读写请求量,大部分是为了统计或后续索引优化提供依据。
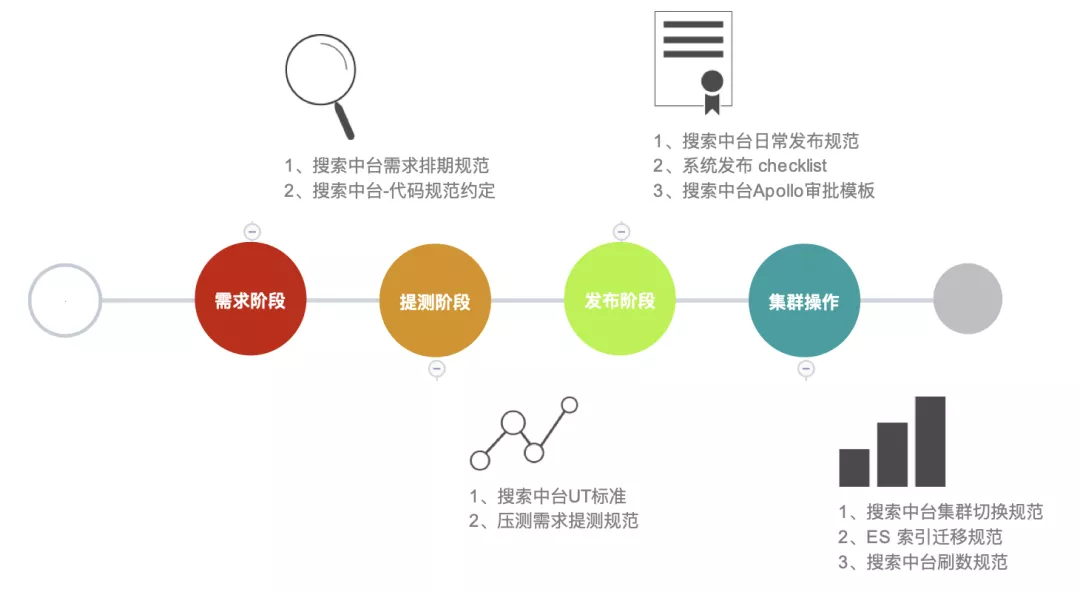
3 搜索中台流程规范补全
俗话说:无规矩不成方圆,搜索各项流程的制定也是经历一波阵痛,有不少是依据线上问题和跟研发的合作磨合下一步步补充起来的,如下图所示:
其中在研发提测质量上,搜索中台从搭建初始单测覆盖率为0,针对这种情况,我们对搜索的应用进行了一个梳理,重新定义各应用的UT标准,其中L1级别应用增量覆盖率需要达85%,L2级别应用增量覆盖率达75%,杜绝出现无断言或断言过简的情况,通过流程规范的卡点,目前搜索核心应用单测情况:
,商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


