深入搜索引擎原理
之前几段工作经历都与搜索有关,现在也有业务在用搜索,对搜索引擎做一个原理性的分享,包括搜索的一系列核心数据结构和算法,尽量覆盖搜索引擎的核心原理,但不涉及数据挖掘、NLP等。文章有点长,多多指点~~
一、搜索引擎引题
搜索引擎是什么?
这里有个概念需要提一下。信息检索 (Information Retrieval 简称 IR) 和 搜索 (Search) 是有区别的,信息检索是一门学科,研究信息的获取、表示、存储、组织和访问,而搜索只是信息检索的一个分支,其他的如问答系统、信息抽取、信息过滤也可以是信息检索。
本文要讲的搜索引擎,是通常意义上的全文搜索引擎、垂直搜索引擎的普遍原理,比如 Google、Baidu,天猫搜索商品、口碑搜索美食、飞猪搜索酒店等。
Lucene 是非常出名且高效的全文检索工具包,ES 和 Solr 底层都是使用的 Lucene,本文的大部分原理和算法都会以 Lucene 来举例介绍。
为什么需要搜索引擎?
看一个实际的例子:如何从一个亿级数据的商品表里,寻找名字含“秋裤”的 商品。
使用SQL Like
select * from item where name like '%秋裤%'
如上,大家第一能想到的实现是用 like,但这无法使用上索引,会在大量数据集上做一次遍历操作,查询会非常的慢。有没有更简单的方法呢,可能会说能不能加个秋裤的分类或者标签,很好,那如果新增一个商品品类怎么办呢?要加无数个分类和标签吗?如何能更简单高效的处理全文检索呢?
使用搜索引擎
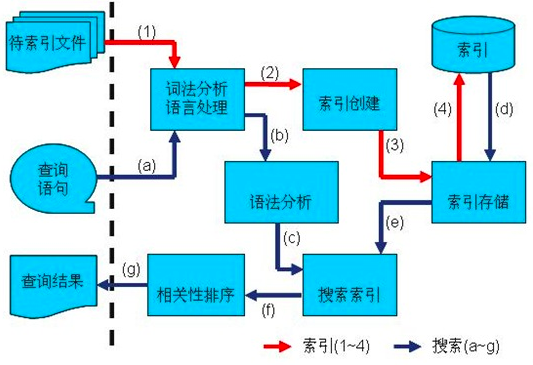
答案是搜索,会事先 build 一个倒排索引,通过词法语法分析、分词、构建词典、构建倒排表、压缩优化等操作构建一个索引,查询时通过词典能快速拿到结果。这既能解决全文检索的问题,又能解决了SQL查询速度慢的问题。
那么,淘宝是如何在1毫秒从上亿个商品找到上千种秋裤的呢,谷歌如何在1毫秒从万亿个网页中找寻到与你关键字匹配的几十万个网页,如此大的数据量是怎么做到毫秒返回的。
二、搜索引擎是怎么做的?
Part1. 分词
分词就是对一段文本,通过规则或者算法分出多个词,每个词作为搜索的最细粒度一个个单字或者单词。**只有分词后有这个词,搜索才能搜到,分词的正确性非常重要。**分词粒度太大,搜索召回率就会偏低,分词粒度太小,准确率就会降低。如何恰到好处的分词,是搜索引擎需要做的第一步。
正确性&粒度
- 分词正确性
- “他说的确实在理”,这句话如何分词?
- “他-说-的确-实在-理” [错误语义]
- “他-说-的-确实-在理” [正确语义]
- 分词的粒度
- “中华人民共和国宪法”,这句话如何分词?
- “中华人民共和国-宪法”,[搜索 中华、共和国 无结果]
- “中华-人民-共和国-宪法”,[搜索 共和 无结果]
- “中-华-人-民-共-和-国-宪-法”,[搜索其中任意字都有结果]
分词的粒度并不是越小越好,他会降低准确率,比如搜索 “中秋” 也会出现上条结果,而且粒度越小,索引词典越大,搜索效率也会下降,后面会细说。
如何准确的把控分词,涉及到 NLP 的内容啦,这里就不展开了。
停用词
很多语句中的词都是没有意义的,比如 “的”,“在” 等副词、谓词,英文中的 “a”,“an”,“the”,在搜索是无任何意义的,所以在分词构建索引时都会去除,降低不不要的索引空间,叫停用词 (StopWord)。
通常可以通过文档集频率和维护停用词表的方式来判断停用词。
词项处理
词项处理,是指在原本的词项上在做一些额外的处理,比如归一化、词形归并、词干还原等操作,以提高搜索的效果。并不是所有的需求和业务都要词项处理,需要根据场景来判断。
1.归一化
- USA - U.S.A. [缩写]
- 7月30日 - 7/30 [中英文]
- color - colour [通假词]
- 开心 - 高兴 [同义词扩展范畴]
这样查询 U.S.A. 也能得到 USA 的结果,同义词可以算作归一化处理,不过同义词还可以有其他的处理方式。
2.词形归并(Lemmatization)
针对英语同一个词有不同的形态,可以做词形归并成一个,如:
- am, are, is -> be
- car, cars, car’s, cars’ -> car
- the boy’s cars are different colors -> the boy car be different color
3.词干还原(Stemming)
通常指的就粗略的去除单词两端词缀的启发式过程
- automate(s), automatic, automation -> automat.
- 高高兴兴 -> 高兴 [中文重叠词还原]
- 明明白白 -> 明白
英文的常见词干还原算法,Porter算法。
Part2、倒排索引
要了解倒排索引,先看一下什么是正排索引。比如有下面两句话:
- id1, “搜索引擎提供检索服务”
- id2, “搜索引擎是信息检索系统”
正排索引
正排索引就是 MySQL 里的 B+ Tree,索引的结果是:
- “搜索引擎是信息检索系统” -> id2
- “搜索引擎提供检索服务” -> id1
表示对完整内容按字典序排序,得到一个有序的列表,以加快检索的速度。
倒排索引
第一步 分词
- “搜索引擎-提供-检索-服务” -> id1
- “搜索引擎-信息-检索-系统” -> id2
第二步 将分词项构建一个词典
- 搜索引擎
- 提供
- 检索
- 服务
- 信息
- 系统
第三步 构建倒排链
- 搜索引擎 -> id1, id2
- 提供 -> id1
- 检索 -> id1, id2
- 服务 -> id1
- 信息 -> id2
- 系统 -> id2
由此,一个倒排索引就完成了,搜索 “检索” 时,得到 id1, id2,说明这两条数据都有,搜索 “服务” 只有 id1 存在。但如果搜索 “检索系统”,此时会先建搜索词按照与构建同一种策略分词,得到 “检索-系统”,两个词项,分别搜索 检索 -> id1, id2 和 系统 -> id2,然后对其做一个交集,得到 id2。同理,通过求并集可以支持更复杂的查询。
倒排索引到此也就讲清楚了吧。
存储结构
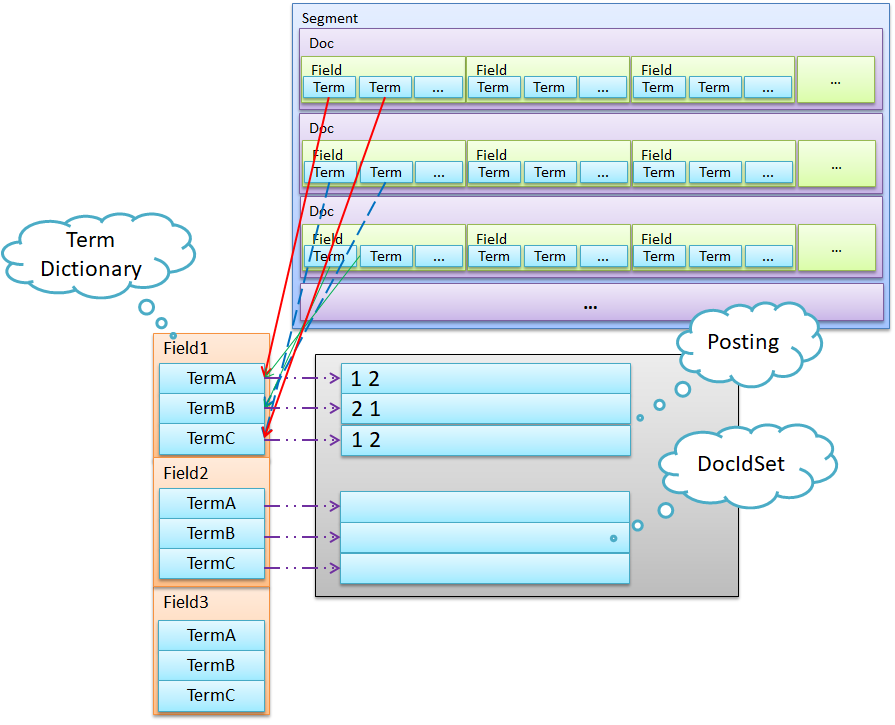
以 Lucene 为例,简单说明一下 Lucene 的存储结构。从大到小是Index -> Segment -> Doc -> Field -> Term,类比 MySQL 为 Database -> Table -> Record -> Field -> Value。
Part 3、查询结果排序
搜索结果排序是根据 关键字 和 Document 的相关性得分排序,通常意义下,除了可以人工的设置权重 boost,也存在一套非常有用的相关性得分算法,看完你会觉得非常有意思。
TF-IDF
TF(词频)-IDF(逆文档频率) 在自动提取文章关键词上经常用到,通过它可以知道某个关键字在这篇文档里的重要程度。其中 TF 表示某个 Term 在 Document 里出现的频次,越高说明越重要;DF 表示在全部 Document 里,共有多少个 Document 出现了这个词,DF 越大,说明这个词很常见,并不重要,越小反而说明他越重要,IDF 是 DF 的倒数(取log), IDF 越大,表示这个词越重要。
TF-IDF 怎么影响搜索排序,举一个实际例子来解释:
假定现在有一篇博客**《Blink 实战总结》**,我们要统计这篇文章的关键字,首先是对文章分词统计词频,出现次数最多的词是–“的”、“是”、“在”,这些是“停用词”,基本上在所有的文章里都会出现,他对找到结果毫无帮助,全部过滤掉。
只考虑剩下的有实际意义的词,如果文章中词频数关系: “Blink” > “词频” = “总结”,那么肯定是 Blink 是这篇文章更重要的关键字。但又会遇到了另一个问题,如果发现 “Blink”、“实战”、“总结"这三个词的出现次数一样多。这是不是意味着,作为关键词,它们的重要性是一样的?
不是的,通过统计全部博客,你发现 含关键字总博客数: “Blink” < “实战” < “总结”,这时候说明 “Blink” 不怎么常见,一旦出现,一定相比 “实战” 和 “总结”,对这篇文章的重要性更大。
BM25
上面解释了 TF 和 IDF,那么 TF 和 IDF 谁更重要呢,怎么计算最终的相关性得分呢?那就是 BM25。
BM25算法,通常用来作搜索相关性平分。一句话概况其主要思想:对Query进行语素解析,生成语素qi;然后,对于每个搜索结果D,计算每个语素qi与D的相关性得分,最后,将qi相对于D的相关性得分进行加权求和,从而得到Query与D的相关性得分。
BM25算法的一般性公式如下:
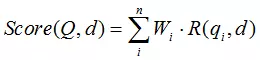
其中,Q表示Query,qi表示Q解析之后的一个语素(对中文而言,我们可以把对Query的分词作为语素分析,每个词看成语素qi。);d表示一个搜索结果文档;Wi表示语素qi的权重;R(qi,d)表示语素qi与文档d的相关性得分。
其中 Wi 通常使用 IDF 来表达,R 使用 TF 来表达;综上,BM25算法的相关性得分公式可总结为:
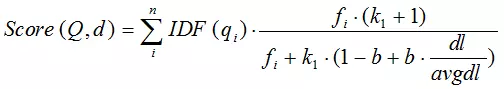
BM25 通过使用不同的语素分析方法、语素权重判定方法,以及语素与文档的相关性判定方法,我们可以衍生出不同的搜索相关性得分计算方法,这就为我们设计算法提供了较大的灵活性。
Part 4、空间索引
在点评口碑上,经常有类似的场景,搜索 “1公里以内的美食”,那么这个1公里怎么实现呢?
在数据库中可以通过暴力计算、矩形过滤、以及B树对经度和维度建索引,但这性能仍然很慢(可参考 为什么需要空间索引 )。搜索里用了一个很巧妙的方法,Geo Hash。
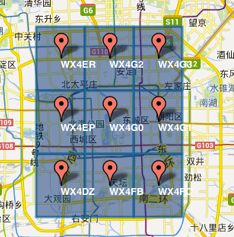
如上图,表示根据 GeoHash 对北京几个区域生成的字符串,有几个特点:
- 一个字符串,代表一个矩形区域
- 字符串越长,表示的范围越精确 (长度为8时精度在19米左右,而当编码长度为9时精度在2米左右)
- 字符串相似的,表示距离相近 (这就可以利用字符串的前缀匹配来查询附近的POI信息)
Geo Hash 如何编码?
地球上任何一个位置都可以用经纬度表示,纬度的区间是 [-90, 90],经度的区间 [-180, 180]。比如天安门的坐标是 39.908,116.397,整体编码过程如下:
一、对纬度 39.908 的编码如下:
- 将纬度划分2个区间,左区间 [-90, 0) 用 0 表示,右区间 [0, 90] 用 1 表示, 39.908 处在右区间,故第一位编码是 1;
- 在将 [0, 90] 划分2个区间,左区间 [0, 45) 用 0 表示,右区间 [45, 90] 用 1 表示,39.908处在左区间, 故第二位编码是 0;
- 同1、2的计算步骤,39.908 的最后10位编码是 “10111 00011”
二、对经度 116.397 的编码如下:
- 将经度划分2个区间,左区间 [-180, 0) 用 0 表示,右区间 [0, 180] 用 1 表示,116.397处在右区间, 故第一位编码是 1;
- 在将 [0, 180] 划分2个区间,左区间 [0, 90) 用 0 表示,右区间 [90, 180] 用 1 表示,116.397处在右区间,故第二位编码是 1;
- 同1、2的计算步骤,116.397 的最后6位编码是 “11010 01011”
三、合并组码
- 将奇数位放经度,偶数位放纬度,把2串编码组合生成新串:“11100 11101 00100 01111”;
- 通过 Base32 编码,每5个二进制编码一个数,“28 29 04 15”
- 根据 Base32 表,得到 Geo Hash 为:“WX4G”
即最后天安门的4位 Geo Hash 为 “WX4G”,如果需要经度更准确,在对应的经纬度编码粒度再往下追溯即可。
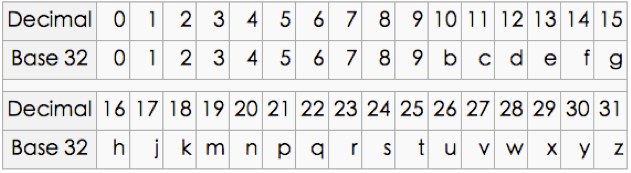
附:Base32 编码图
Geo Hash 如何用于地理搜索?
举个例子,搜索天安门附近 200 米的景点,如下是天安门附近的Geo编码
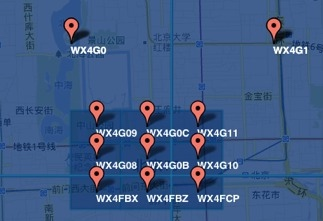
搜索过程如下:
- 首先确定天安门的Geo Hash为 WX4G0B,(6位区域码约 0.34平分千米,约为长宽600米区域)
- 而6位编码表示 600 米,半径 300 米 > 要求的 200 米,搜索所有编码为 WX4G0B 的景点即可
- 但是由于天安门处于 WX4G0B 的边缘位置,并不一定处在正中心。这就需要将 WX4G0B 附近的8个区域同时纳入搜索,故搜索 WX4G0B、WX4G09、WX4G0C 一共9个编码的景点
- 第3步已经将范围缩小到很小的一个区间,但是得到的景点距离并不是准确的,需要在通过距离计算过滤出小于 200 米的景点,得到最终结果。
由上面步骤可以看出,Geo Hash 将原本大量的距离计算,变成一个字符串检索缩小范围后,再进行小范围的距离计算,及快速又准确的进行距离搜索。
Geo Hash 依据的数学原理
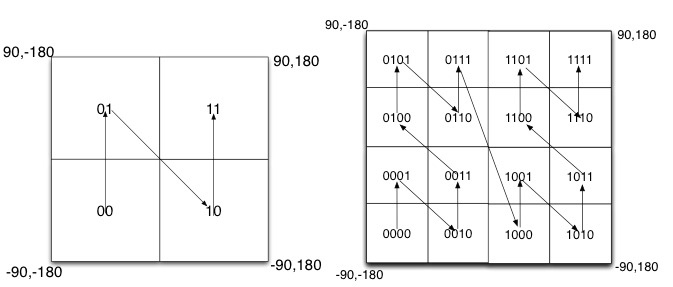
如图所示,我们将二进制编码的结果填写到空间中,当将空间划分为四块时候,编码的顺序分别是左下角00,左上角01,右下脚10,右上角11,也就是类似于Z的曲线。当我们递归的将各个块分解成更小的子块时,编码的顺序是自相似的(分形),每一个子快也形成Z曲线,这种类型的曲线被称为Peano空间填充曲线。
这种类型的空间填充曲线的优点是将二维空间转换成一维曲线(事实上是分形维),对大部分而言,编码相似的距离也相近, 但Peano空间填充曲线最大的缺点就是突变性,有些编码相邻但距离却相差很远,比如0111与1000,编码是相邻的,但距离相差很大。

除Peano空间填充曲线外,还有很多空间填充曲线,如图所示,其中效果公认较好是Hilbert空间填充曲线,相较于Peano曲线而言,Hilbert曲线没有较大的突变。为什么GeoHash不选择Hilbert空间填充曲线呢?可能是Peano曲线思路以及计算上比较简单吧,事实上,Peano曲线就是一种四叉树线性编码方式。
Part 5、数值索引
Lucene的倒排索引决定,索引内容是一个可排序的字符串,如果要查找一个数字,那么也需要将数字转成字符串。这样,检索一个数字是没问题的,如果需要搜索一个数值范围,怎么做呢?
要做范围查找,那么要求数字转成的字符串也是有序并单调的,但数字本身的位数是不一样的,最简单的版本就是前缀补0,比如 35, 234, 1 都补成 4 位,得到 0035, 0234, 0001,这样能保证:
数字(a) > 数字(b) ===> 字符串(a) > 字符串(b)
这时候,查询应该用范围内的所有数值或查询,比如查询 [33, 36) 这个范围,对应的查询语法是:
33 || 34 || 35
嗯看起来很好的解决了范围查询,但是,这样存在3个问题:
- 补位多少合适呢?总有一个数字会超出你的补位范围
- 因为存在补位,就会多出很多的空间,这在搜索引擎里宝贵的内存是无法接受的
- 如果是范围查询,需要用多次或查询,性能并不高
故,涉及到范围不能简单的做字符串补位转换,是否存在及节省空间,又能更高效解决问题的方案呢?
就是:
数值Trie树,下面详细介绍
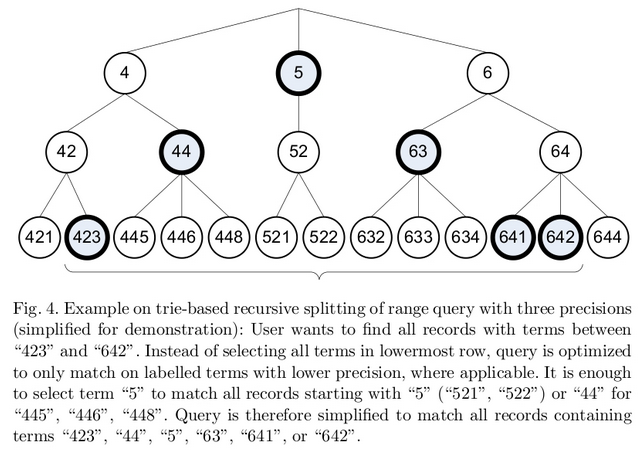
上面说了怎么索引,那么Query呢?比如我给你一个Range Query从423-642,怎么找到那6个term呢?
我们首先可以用shift==0找到范围的起点后终点(有可能没有相等的,比如搜索422,也会找到423)。然后一直往上找,直到找到一个共同的祖先(肯定能找到,因为树根是所有叶子节点的祖先),对应起点,每次往上走的时候, 左边范围节点都要把它右边的兄弟节点都加进去, 右边范围节点都要把它左边的兄弟节点加进去, 若已经到达顶点, 则是将左边范围节点和右边范围节点之间的节点加进行去
查找423到642之间的具体的区间:
- 423-429,640-642
- 43-49,60-63
- 5-5
另外还有一个问题,比如423会被分词成423,42和4,那么4也会被分词成4,那么4表示哪个呢?
所以intToPrefixCoded方法会额外用一个char来保存shift:buffer[0] = (char)(SHIFT_START_INT + shift);
比如423分词的4的shift是2(这里是10进制的例子,二进制也是同样的),423分成423的shift是0,4的shift是0,因此前缀肯定比后缀大。
最后,由于索引在判断时无需感知是否是数字,可以把所有的数字当成二进制处理,这样在存储和效率上更高。
三、搜索引擎的极致优化
LSM思想
LSM (Log Structured Merge Tree),最早是谷歌的 “BigTable” 提出来的,目标是保证写入性能,同时又能支持较高效率的检索,在很多 NoSQL 中都有使用,Lucene 也是使用 LSM 思想来写入。
普通的B+树增加记录可能需要执行 seek+update 操作,这需要大量磁盘寻道移动磁头。而 LSM 采用记录在文件末尾,顺序写入减少移动磁头/寻道,执行效率高于 B+树。具体 LSM 的原理是什么呢?
为了保持磁盘的IO效率,lucene避免对索引文件的直接修改,所有的索引文件一旦生成,就是只读,不能被改变的。其操作过程如下:
- 在内存中保存新增的索引, 内存缓存(也就是memtable);
- 内存中的索引数量达到一定阈值时,触发写操作,将这部分数据批量写入新文件,我们称为segment;也就是 sstable文件
- 新增的segment生成后,不能被修改;
- update操作和delete操作不会立即导致原有的数据被修改或者删除,会以append的方式存储update和delete标记;
- 最终得到大量的 segment,为了减少资源占用,也提高检索效率,会定期的将这些小的 segment 合并成大的 segment,由于map中的数据都是排好序的,所以合并也不会有随机写操作;
- 通过merge,还可以把update和delete操作真正生效,删除多余的数据,节省空间。
合并的过程:
Basic Compaction
每个文件固定N个数量,超过N,则新建一个sstable;当sstable数大于M,则合并一个大sstable;当大sstable的数量大于M,则合并一个更大的sstable文件,依次类推。

但是,这会出现一个问题,就是大量的文件被创建,在最坏的情况下,所有的文件都要搜索。
Levelled Compaction
像 LevelDB 和 Cassandra解决这个问题的方法是:实现了一个分层的,而不是根据文件大小来执行合并操作。
- 每层维护指定数量的文件,保证不让 key 重叠,查找一个 key 只会查找一个 key;
- 每次文件只会被合并到上一层的一个文件。当一层的文件数满足特定个数时,合并到上一层。
所以, LSM 是日志和传统的单文件索引(B+ tree,Hash Index)的中立,他提供一个机制来管理更小的独立的索引文件(sstable)。
通过管理一组索引文件而不是单一的索引文件,LSM 将B+树等结构昂贵的随机IO变的更快,而代价就是读操作要处理大量的索引文件(sstable)而不是一个,另外还是一些IO被合并操作消耗。
Lucene的Segment设计思想,与LSM类似但又有些不同,继承了LSM中数据写入的优点,但是在查询上只能提供近实时而非实时查询。
Segment在被flush或commit之前,数据保存在内存中,是不可被搜索的,这也就是为什么Lucene被称为提供近实时而非实时查询的原因。读了它的代码后,发现它并不是不能实现数据写入即可查,只是实现起来比较复杂。原因是Lucene中数据搜索依赖构建的索引(例如倒排依赖Term Dictionary),Lucene中对数据索引的构建会在Segment flush时,而非实时构建,目的是为了构建最高效索引。当然它可引入另外一套索引机制,在数据实时写入时即构建,但这套索引实现会与当前Segment内索引不同,需要引入额外的写入时索引以及另外一套查询机制,有一定复杂度。
FST
数据字典 Term Dictionary,通常要从数据字典找到指定的词的方法是,将所有词排序,用二分查找即可。这种方式的时间复杂度是 Log(N),占用空间大小是 O(N*len(term))。缺点是消耗内存,存在完整的term,当 term 数达到上千万时,占用内存非常大。
lucene从4开始大量使用的数据结构是FST(Finite State Transducer)。FST有两个优点:
- 空间占用小,通过读 term 拆分复用及前缀和后缀的重用,压缩了存储空间;
- 查询速度快,查询仅有 O(len(term)) 时间复杂度
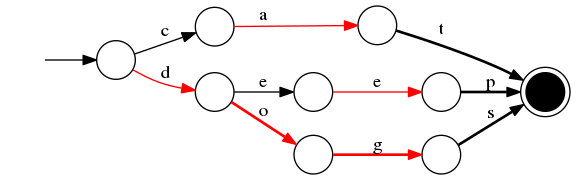
那么 FST 数据结构是什么原理呢? 先来看看什么是 FSM (Finite State Machine), 有限状态机,从“起始状态”到“终止状态”,可接受一个字符后,自循环或转移到下一个状态。
而FST呢,就是一种特殊的 FSM,在 Lucene 中用来实现字典查找功能(NLP中还可以做转换功能),FST 可以表示成FST的形式
举例:对“cat”、 “deep”、 “do”、 “dog” 、“dogs” 这5个单词构建FST(注:必须已排序),结构如下:
当存在 value 为对应的 docId 时,如 cat/0 deep/1 do/2 dog/3 dogs/4, FST 结构图如下:
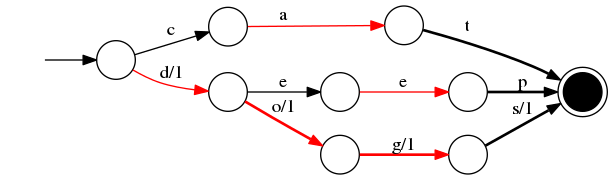
FST 还有一个特点,就是在前缀公用的基础上,还会做一个后缀公用,目标同样是为了压缩存储空间。
其中红色的弧线表 NEXT-optimized,可以通过 画图工具 来测试。
SkipList
为了能够快速查找docid,lucene采用了SkipList这一数据结构。SkipList有以下几个特征:
- 元素排序的,对应到我们的倒排链,lucene是按照docid进行排序,从小到大;
- 跳跃有一个固定的间隔,这个是需要建立SkipList的时候指定好,例如下图以间隔是;
- SkipList的层次,这个是指整个SkipList有几层
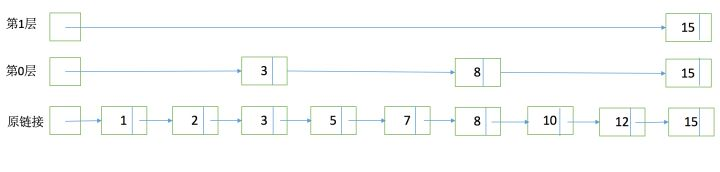
在什么位置设置跳表指针?
• 设置较多的指针,较短的步长, 更多的跳跃机会
• 更多的指针比较次数和更多的存储空间
• 设置较少的指针,较少的指针比较次数,但是需要设置较长的步长较少的连续跳跃
如果倒排表的长度是L,那么在每隔一个步长S处均匀放置跳表指针。
BKD Tree
也叫 Block KD-tree,根据FST思路,如果查询条件非常多,需要对每个条件根据 FST 查出结果,进行求并集操作。如果是数值类型,那么潜在的 Term 可能非常多,查询销量也会很低,为了支持高效的数值类或者多维度查询,引入 BKD Tree。在一维下就是一棵二叉搜索树,在二维下是如果要查询一个区间,logN的复杂度就可以访问到叶子节点对应的倒排链。
- 确定切分维度,这里维度的选取顺序是数据在这个维度方法最大的维度优先。一个直接的理解就是,数据分散越开的维度,我们优先切分。
- 切分点的选这个维度最中间�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%B7%B1%E5%85%A5%E6%90%9C%E7%B4%A2%E5%BC%95%E6%93%8E%E5%8E%9F%E7%90%86/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


