深度学习在高德鲜活度提升中的演进

文章作者:懿林
内容来源:高德技术
导读: 高德地图拥有着数千万的 POI ( Point of Interest ) 兴趣点,如学校、酒店、加油站、超市等。其中伴随着众多 POI 创建的同时,会有大量的 POI 过期,如停业、拆迁、搬迁、更名。这部分 POI 对地图鲜活度和用户体验有着严重的负面影响,需要及时有效地识别并处理。
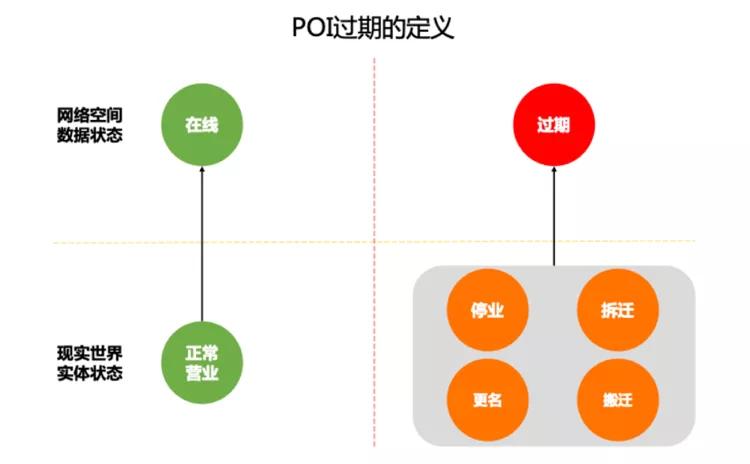
由于实地采集的方式成本高且时效性低,挖掘算法则显得格外重要。其中基于趋势大数据的时序模型,能够覆盖大部分挖掘产能,对 POI 质量提升有着重要意义。
过期 POI 识别本质上可以抽象为一个数据分布非对称的二分类问题。项目中以多源趋势特征为基础,并在迭代中引入高维度稀疏的属性、状态特征,构建符合业务需求的混合模型。
本文将对深度学习技术在高德地图落地的过程中遇到的业务难点,和经过实践检验的可行方案进行系统性的梳理总结。
01 特征工程
过期挖掘的实质是感知伴随 POI 过期而发生的变化,进行事后观测式挖掘,一般都会伴随着 POI 相关活跃度的下降。因此时序模型的关键是构建相关联的特征体系。同时在实践中我们也构造了一些有效的非时序特征进行辅助校正。
1. 时序特征
时序特征方面,建立了 POI 和多种信息的关联关系,并分别整合为月级的统计值,作为时序模型的输入;时间序列窗口方面,考虑到一些周期性的规律的影响,需要两年以上的序列长度来训练模型。
2. 辅助特征
辅助特征方面,首先是将人工核实历史数据进行有效利用。方式是构造一个时间序列长度的 One-Hot 向量,将最后一次人工核实存在的月份标记为 1,其他月份为 0。人工核实存在表示该时间结点附近过期概率较低,若人工更新在趋势下降之后,说明趋势表征过期的概率不高。
其次,调研发现不同行业类型的 POI 有着不同的过期概率,如餐饮和生活服务类过期概率较高,而地名或公交站点等类型则相对低很多。因此将行业类型编号构建为一个时间序列长度的等值向量,作为静态辅助特征。
第三种辅助特征是在分析业务中的漏召回问题时总结构造的。发现有相当部分的新诞生 POI,其入库创建后至今的时长短于序列长度。意味着这部分序列前期存在较多数值为零的伪趋势,会对尾部的真实下降趋势造成干扰从而误判。对此提出了两种优化思路:
- 采用可变长度的 RNN 模型,只截取 POI 创建时间之后部分的序列作为输入。
- 序列长度不变,添加一维"门"序列特征,序列在 POI 创建时间之前的部分数值为 0,之后为 1。如图所示。
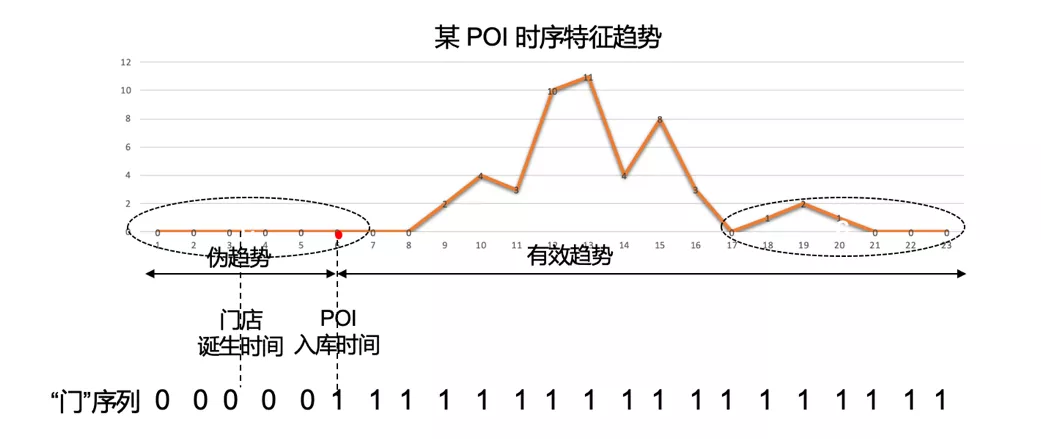
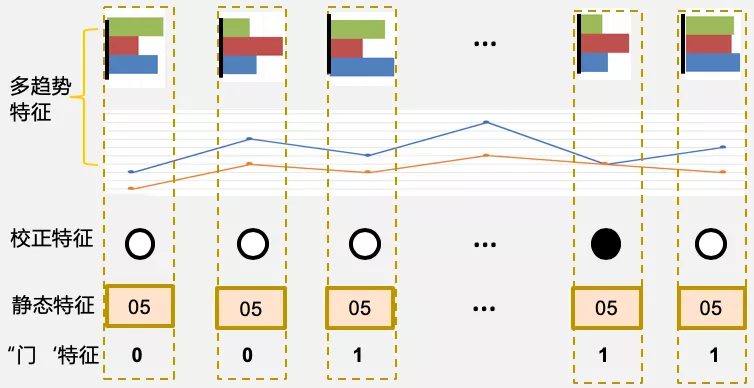
对比采用第二种方案效果更优。考虑到我们只有 POI 的入库创建时间信息,而不了解门店的具体诞生时间,直接按入库时间截取序列,会造成门店诞生和 POI 创建时间段内的特征信息损失;而添加"门"序列则可以在保持信息完备的同时约束高可信区间。最后构建的混合特征示意图如下所示。
02RNN 阶段
循环神经网络 ( RNN,Recurrent Neural Network ) 凭借强大的表征能力在序列建模问题上有非常突出的表现,业务中采用了其变种模型 LSTM。
1. RNN1.0
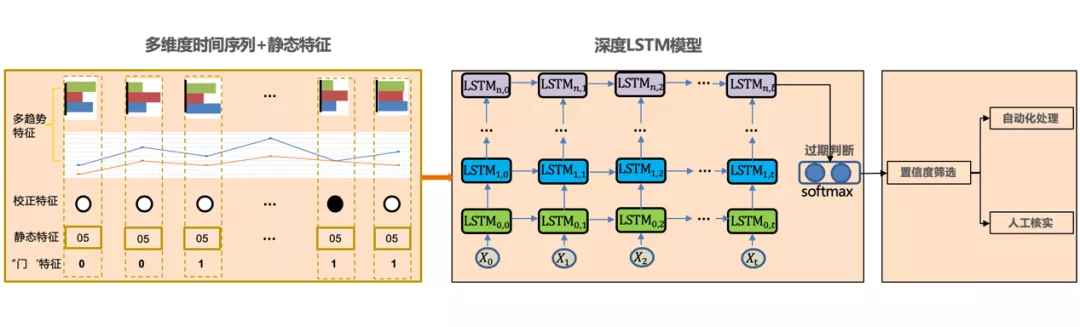
以前述的时序特征和辅助特征为基础,我们采用多层 LSTM 搭建了第一版 RNN 过期挖掘模型,结构如图所示。主要逻辑为,将逐时间点对齐后的特征输入到深度 LSTM 中,在网络最后时刻的输出后,接入一层 SoftMax 计算过期概率。最后根据结果匹配不同的置信度区段,分别进行自动化处理或人工作业等任务。模型初步验证了 RNN 在过期趋势挖掘领域落地的可行性和优势。
2. RNN2.0
高德地图基于导航、搜索或点击等操作频度对 POI 进行了热度排名。头部的热门 POI 如果过期但未及时发现对用户体验的伤害更大。2.0 版本模型升级的主要目标便是进一步提升头部热门段位的过期 POI 发现能力。
分析发现热门 POI 的数据分布相比尾部有较大差异性。头部 POI 的数据量丰富,且数值为 0 的月份很少;相反尾部 POI 则数据稀疏,且有数值月份量级可能也仅为个位数。对于这种头部效应特别明显的状况,单独开发了高热度段特征的头部 RNN 模型,实现定制化挖掘。
另一方面,对于单维度特征缺失的情况,也区分热度采用了不同的填充方式。头部 POI 特征信息丰富,将缺失维度补零让其保持"静默"防止干扰;而尾部特征稀疏,本身已有较多零值,需要插值处理使缺失特征和整体保持相近趋势。方法为将其他维度的数据规范化处理后,采用加权的方式得到插值。

2.0 版模型对头部和尾部的召回能力都有提升,对头部的自动化能力提升尤为明显。
03Wide&Deep 阶段
RNN 模型能够充分发掘时序特征的信息,但特征丰富度不足成为制约自动化能力进一步提升的瓶颈。因此整合业务中的其他数据,从多源信息融合角度升级模型便成为新阶段的工作重点。主要的整合目标包括非时序的静态信息和状态信息,以及新开发的时序特征信息。
模型升级主要借鉴了 Wide&Deep 的思想,并做了很多结合业务实际情况的应用创新。首先我们要把已有的 RNN 模型封装为 Deep 模块后和 Wide 部分联合,相当于重新构建了一个混合模型,涉及到模型结构维度的整合。其次,既有 Deep 的时序信息,又有 Wide 部分的实时状态信息,涉及到数据时间维度的整合。最后是 Wide 部分包含大量的不可量化或比较的类型特征需要编码表征处理,涉及到数据属性维度的整合。
1. Wide & LSTM
特征编码:
我们将非时序特征经过编码后构建 Wide 模块。主要包括属性、状态,以及细分行业类型三种特征。
考虑到某些 POI 属性存在缺失的情况,故编码中第 1 位表示特征是否存在的标志位,后面则为 One-Hot 编码后的对应的属性类型;对于状态特征,同样有一位表示是否特征缺失的标志位,而后面的 One-Hot 编码则表示最新时刻的状态类型;由于不同行业类型有着不同的背景过期率,我们将细分的行业类型做 One-Hot 编码后作为第三种特征。最后将各特征编码依次连接,得到一个高维度的稀疏向量。特征编码的过程如图所示。
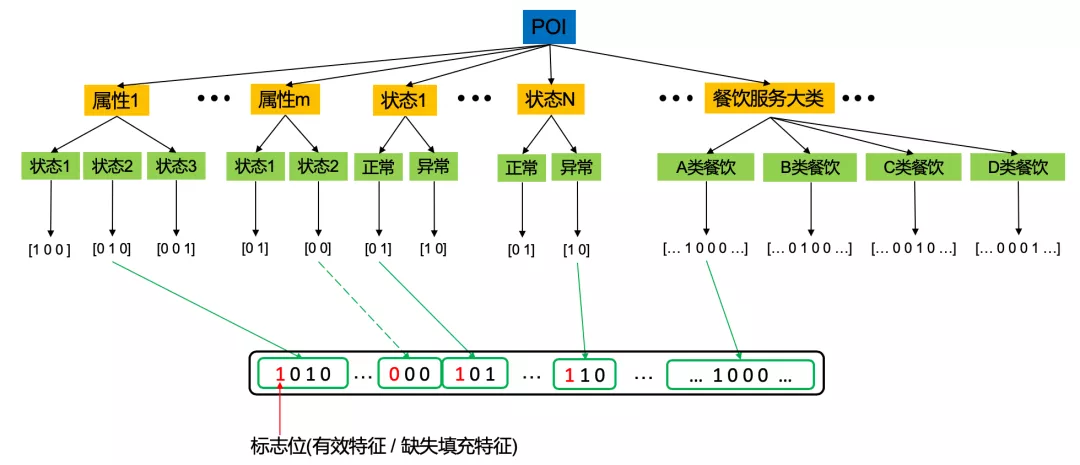
特征耦合:
特征完备之后,将各类特征耦合及模型训练便成为关键。耦合点选在了 SoftMax 输出的前一层。对于 Deep 部分的 RNN 结构,参与耦合的便是最后时间节点的隐层;而对于 Wide 部分的高维度稀疏向量,我们通过一层全连接网络来降维,便得到 Wide 部分的隐层。最后将两部分的隐层连接,输出到 SoftMax 来计算过期概率。
模型采用同步输入 Wide 和 Deep 部分特征的方式联合训练,并调节两部分的耦合隐层的维度来平衡两部分的权重。过期挖掘场景的 Wide & LSTM 模型结构如图所示。
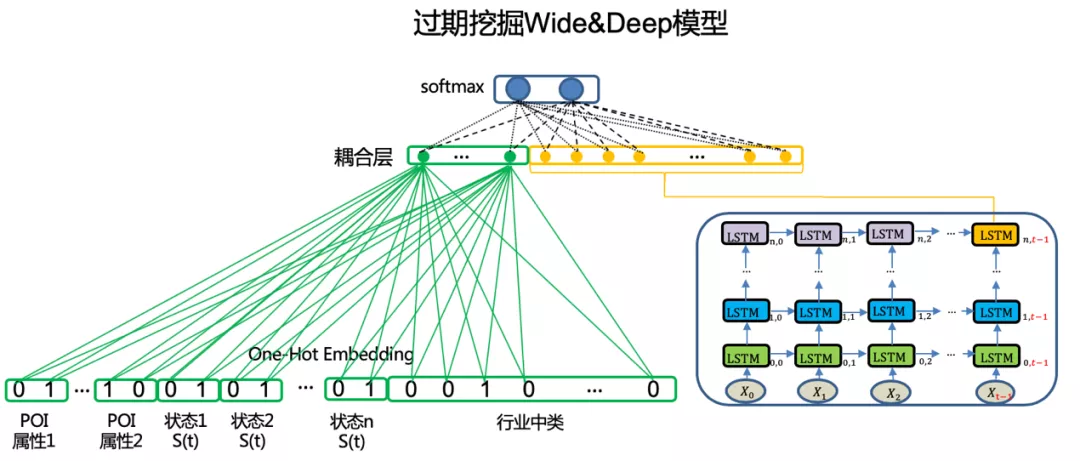
模型经过多次迭代优化后稳定投产,已成为过期挖掘
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E5%9C%A8%E9%AB%98%E5%BE%B7%E9%B2%9C%E6%B4%BB%E5%BA%A6%E6%8F%90%E5%8D%87%E4%B8%AD%E7%9A%84%E6%BC%94%E8%BF%9B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


