源码系列多个的的倒排求交集
这种 Query 组合的文档号合并的代码是在 ConjunctionDISI 类中实现。本文通过一个例子来介绍文档号合并逻辑,这篇文章中对于每个关键字如何获得包含它的文档号,不作详细描述,大家可以去看我添加了详细注释的 ConjunctionDISI 类,相信能一目了然。GitHub 地址是: https://github.com/luxugang/Lucene-7.5.0/blob/master/solr-7.5.0/lucene/core/src/java/org/apache/lucene/search/ConjunctionDISI.java。
例子
添加 10 篇文档到索引中。如下图:
图 1:
使用 WhiteSpaceAnalyzer 进行分词。
查询条件如下图, MUST 描述了满足查询要求的文档必须包含"a"、“b”、“c”、“e” 四个关键字。
图 2:

文档号合并
将包含各个关键字的文档分别放入到各自的数组中,数组元素是文档号。
包含“a”的文档号
图 3:

包含“b”的文档号
图 4:

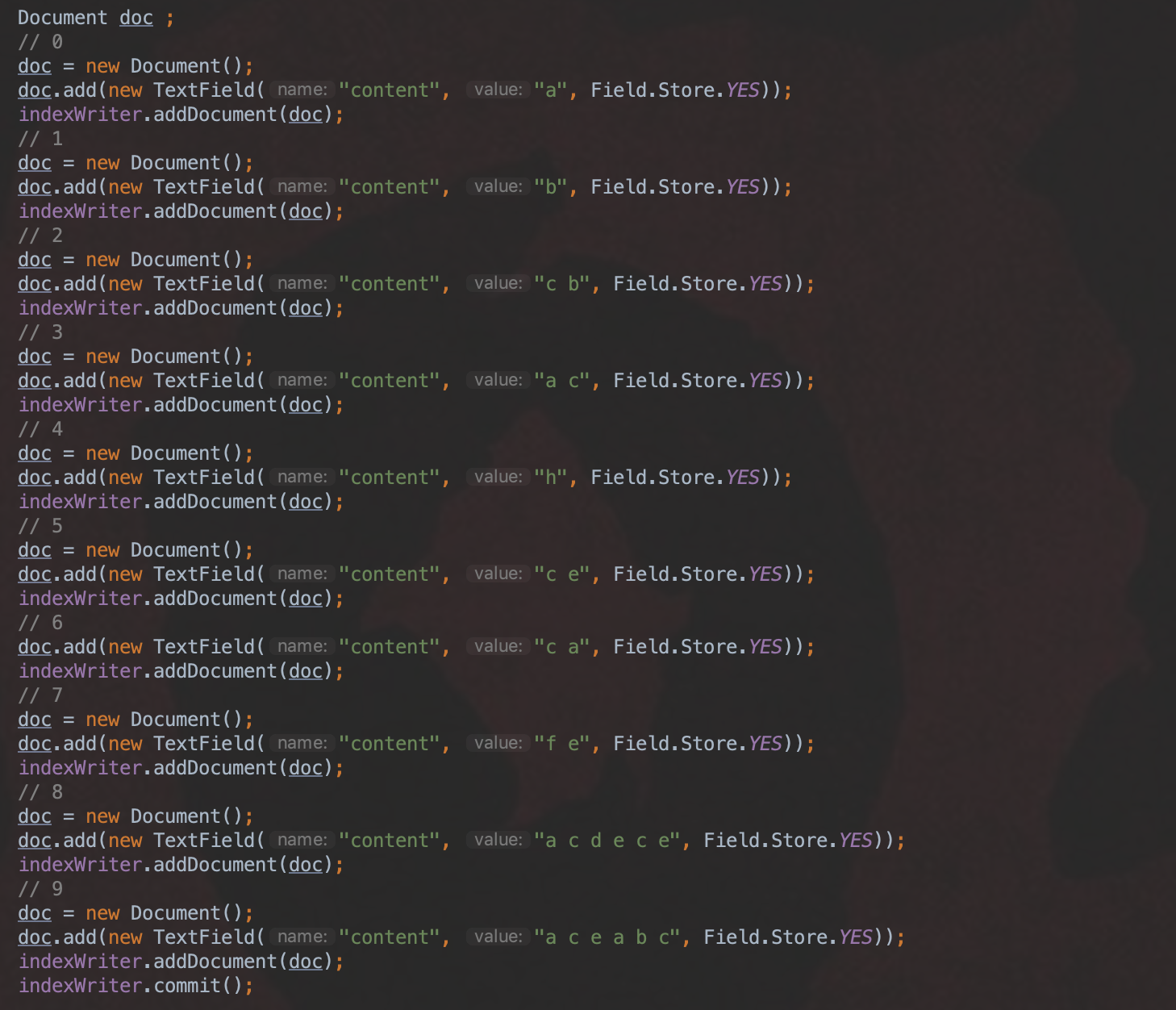
包含“c”的文档号
图 5:
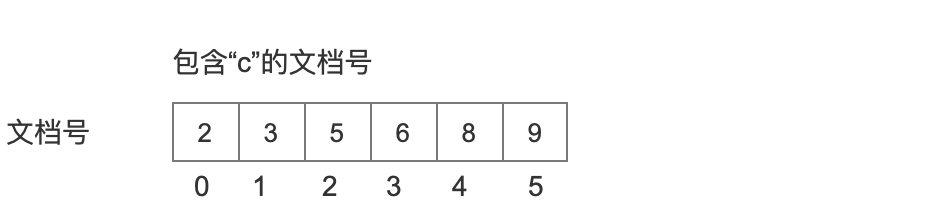
包含“e”的文档号
图 6:

由于满足查询要求的文档中必须都包含"a"、“b”、“c”、“e” 四个关键字,所以满足查询要求的文档个数最多是上面几个数组中最小的数组大小。
所以合并的逻辑即遍历数组大小最小的那个,在上面的例子中,即包含"b"的文档号的数组。每次遍历一个数组元素后,再去其他数组中匹配是否也包含这个文档号。遍历其他数组的顺序同样的按照数组元素大小从小到大的顺序,即包含**“e"的文档号 —> 包含"a"的文档号 —> 包含"c"的文档号**。
合并过程
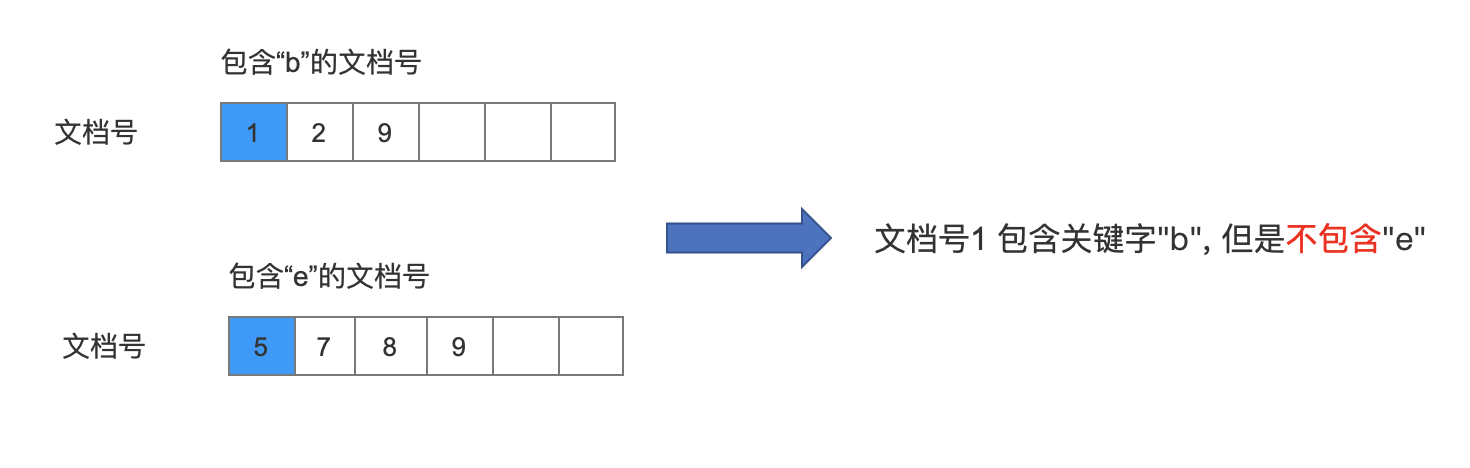
从包含"b"的文档号的数组中取出第一个文档号 doc1 的值 1,然后从包含"e"的文档号的数组中取出第一个不小于 doc1 (1)的文档号 doc2 的值,也就是 5。
比较的结果就是 doc1 (1) ≠ doc2 (5),那么没有必要继续跟其他数组作比较了。因为文档号 1 中不包含关键字"e”。
图 7:
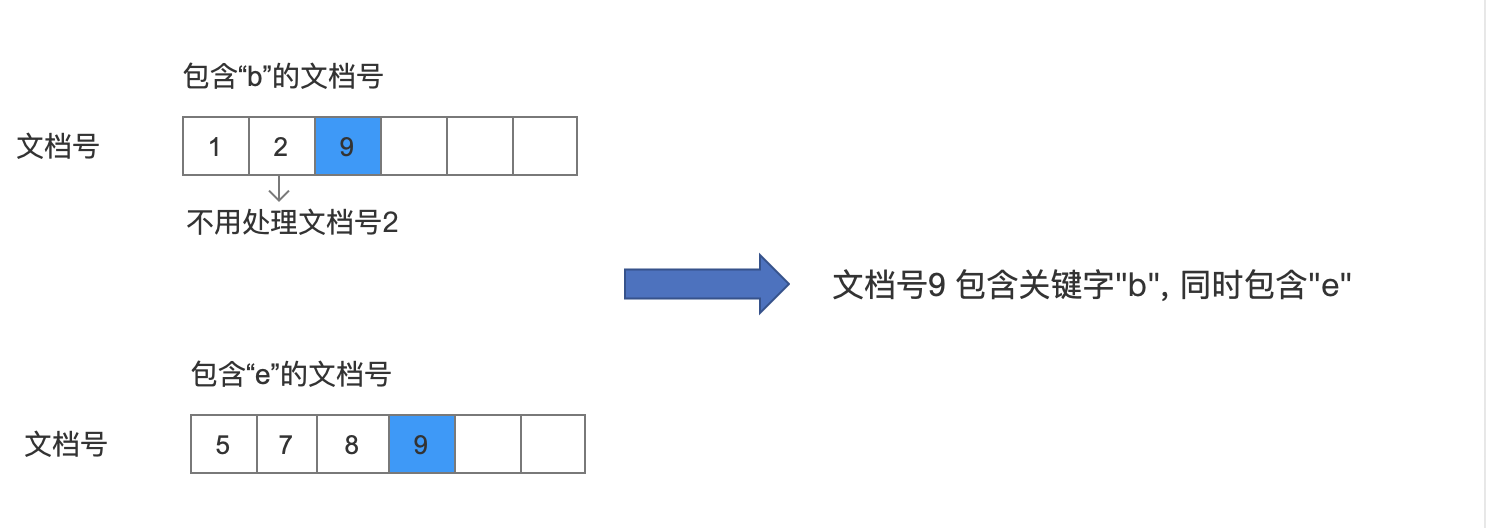
接着继续从包含"b"的文档号的数组中取出不小于 doc2 (5)的值( 在图 7 的比较过程中,我们已经确定文档号 1~文档号 5 中都不同时包含关键字"b"跟"e",所以下一个比较的文档号并不是直接从包含"b"的文档号的数组中取下一个值,即 2,而是根据包含"e"的文档号的数组中的 doc2(5)的值,从包含"b"的文档号的数组中取出不小于 5 的值,即 9),也就是 9,doc1 更新为 9,然后再包含"e"的文档号的数组中取出不小于 doc1(9),也就是 doc2 的值被更新为 9:
图 8:
比较的结果就是 doc1 (9) = doc2 (9), 那么我们就需要继续跟剩余的其他数组元素进行比较了,从包含"a"的文档号数组中取出不小于 doc1 (9)的 文档号 doc3 的值,也就是 9:
图 9:
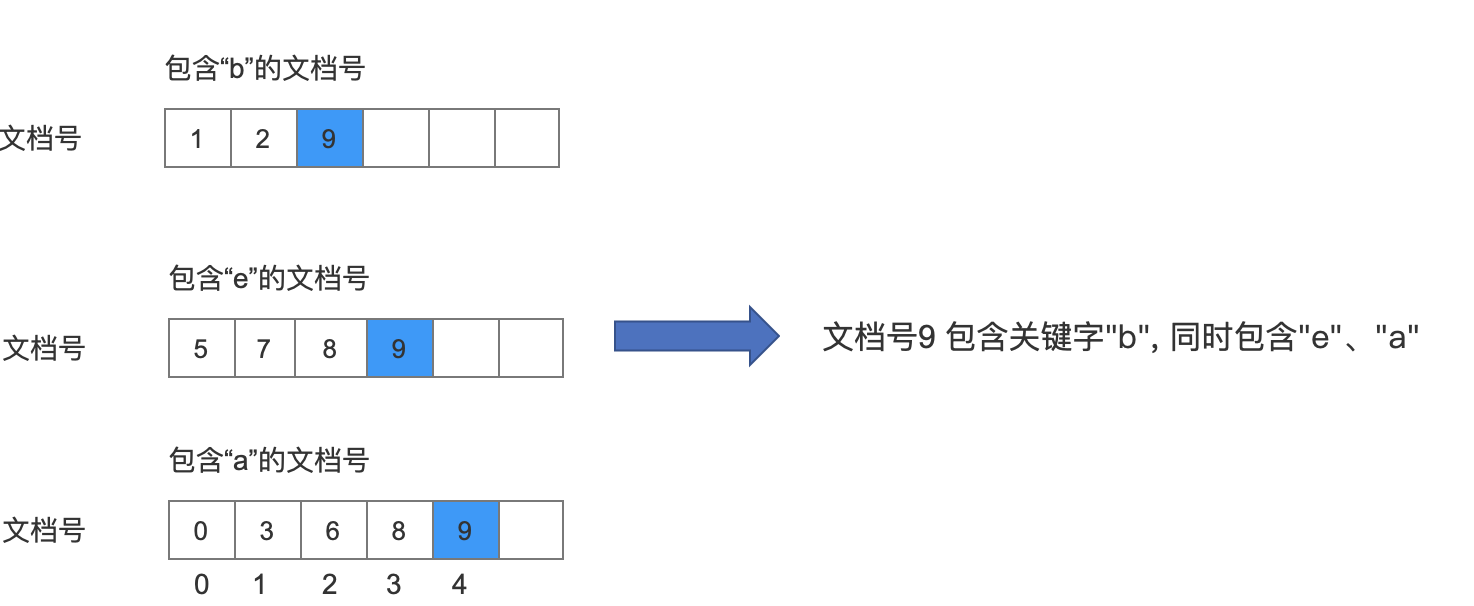
这时候由于 doc1 (9) = doc3 (9),所以需要继续跟包含"c"的文档号的数组中的元素进行比较,从包含"c"的文档号的数组中取出不小于 doc1 (9)的文档号 doc4 的值,也就是 9:
图 10:
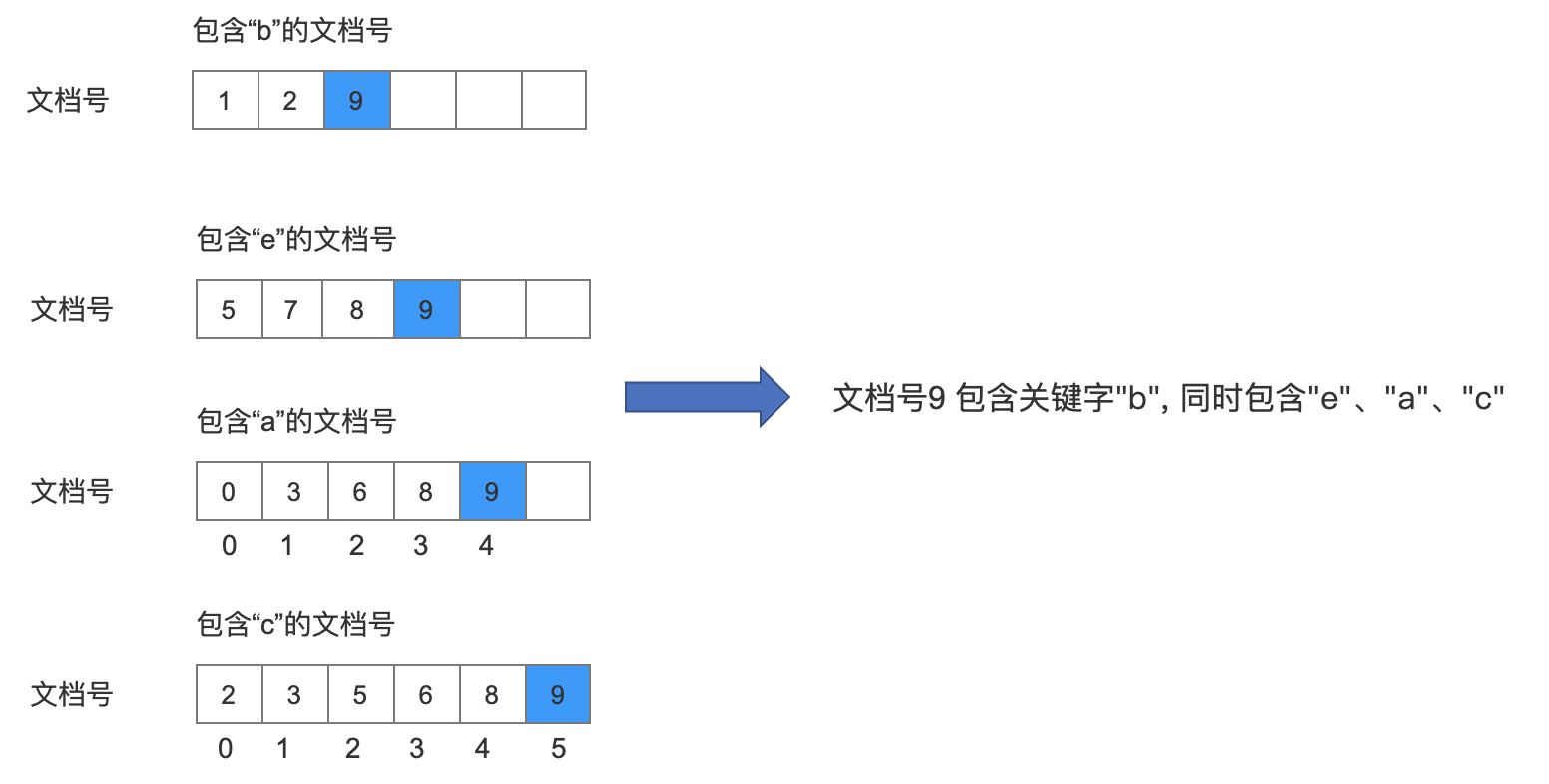
至此所有的数组都遍历结束,并且文档号 9 都在在所有数组中出现,即文档号 9 满足查询要求。
�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%BA%90%E7%A0%81%E7%B3%BB%E5%88%97%E5%A4%9A%E4%B8%AA%E7%9A%84%E7%9A%84%E5%80%92%E6%8E%92%E6%B1%82%E4%BA%A4%E9%9B%86/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


