源码系列有穷自动机
Automaton
在介绍 Automation 类之前先介绍下有穷自动机的概念,有穷自动机分为确定型有穷自动机(DFA)跟不确定型有穷自动机(NFA)。由于本篇文章是为介绍 TermRangeQuery 作准备的,所以只介绍确定性有穷自动机。
确定型有穷自动机(Deterministic Finite Automaton)
这种自动机在读任何输入序列后只能处在一个状态中,术语“确定型”是指这样的事实:在每个输入上存在且仅存在一个状态,自动机可以从当前状态转移到这个状态。
确定型有穷自动机的定义
- 一个确定型有穷自动机包括:一个有穷的状态集合,通常记作Q。
- 一个有穷的 输入符号 集合,通常记作 \sum。
- 一个转移函数,以一个状态和一个输入符号作为变量,返回一个状态。转移函数通常记作\delta。在表示自动机的图中,用状态之间的箭弧和箭弧上的标记来表示\delta。如果q是一个状态,a是一个输入符号,则\delta(q, a)是这样的状态p,使得从p到q有带a标记的箭弧。
- 一个初始状态,是Q中状态之一。
- 一个终结状态或接受状态的集合F。集合F是Q的子集。
通常用缩写 DFA 来指示确定型有穷自动机。最紧凑的 DFA 表示是列出上面 5 个部分,DFA 可以用西面的五元组表示:
A = (Q,
\sum,\delta,q_0,F)
其中 A 是 DFA 的名称,Q是状态集合,\sum是输入符号,\delta是转移函数,q_0是初始状态,F是接受状态集合。
DFA 如何处理串
关于 DFA 需要理解的第一件事情是,DFA 如何决定是否“接受”输入符号序列。DFA 的"语言"是这个 DFA 接受的所有的串的集合。假设a_1a_2…a_n是输入序列。让这个 DFA 从初始状态q_0开始运行。查询转移函数\delta,比如说\delta(q_0,a_1) = q_1,以找出 DFA A 在处理第一个输入符号a_1之后进入的状态。处理下一个输入符号a_2,求\delta(q_1,a_2) 的值,假设这个状态是q_2,以这种方式继续下去,找出状态q_3,q_4,…,q_n,使得对每个i, \delta(q_{i-1},a_i) = q_i。如果q_n属于F,则接受输入a_1a_2…a_n,否则就“拒绝”。
例子
形式化地规定一个 DFA,接受所有仅在串中某个地方有 01 序列的 0 和 1 组成的串,可以把这个语言 L 写成:
{w | w形如 x01y, x 和 y 是只包含 0 和 1 的两个串}
这个语言中的串的例子包括 01、11010 和 100011。不属于这个语言的串的例子包括 0、1000、111000。
对于接受这个语言 L 的自动机,我们知道些什么?首先,输入字母是\sum = {0,1}。有某个状态集合Q,其中一个状态(如q_0)是初始转态。这个自动机需要记住这样的重要事实:至此看到了什么样的输入。为了判定 01 是不是这个输入的一个字串,A 需要记住:
- 是否已经看到了 01?如果是,就接受后续输入的每个序列,即从现在起只处在接受状态中。
- 是否还没有看到 01,但上一个输入是 0,所以如果现在看到 1,就看到 01.并且接受从此开始看到的所有东西?
- 是否还没有看到 01,但上一个输入要么不存在(刚开始运行),要么上次看到 1?在这种情况下,A 直到先看到 0 然后立即看到 1 才接受。
这三个条件每个都能用一个状态表示。条件(3)用初始状态q_0来表示。的确,在刚开始时,需要看到一个 0 然后看到一个 1,但是如果在状态q_0下接着看到一个 1,就并没有更接近于看到 01,所以必须停留在状态q_0中。即,\delta(q_0,1) = q_0。
但是,如果在状态 q_0下接着看到 0,就处在条件(2)中,也就是说,还没有看到 01,但看到了 0。因此,用 q_2来表示条件(2)。在输入 0 上从 q_0出发的转移是\delta(q_0,0) = q_2。
现在,来考虑从状态 q_2出发的转移。如果看到 0,就并没有取得任何进展,但也没有任何退步。还没有看到 01,但 0 是上一个符号,所以还在等待 1。状态 q_2完美地描述了这种局面,所以希望\delta(q_2,0) = q_2。如果在状态q_2看到 1 输入,现在就知道有一个 0 后面跟着 1.就可以进入接受状态,把接受状态称为q_1,q_1对应上面的条件(1)。就是说,\delta(q_2,1) = q_1。
最后,必须设计状态q_1的转移。在这个状态下,已经看到了 01 序列,所以无论发生上面事情,都还是处在这样的局面下:已经看到 01。也就是说,\delta(q_1,0)==\delta(q_1,1)=q_1。
因此,Q = {q_0,q_1,q_2},已经说过,q_0是初始状态,唯一的接受状态是q_1,也就是说,F = {q_1}。接受语言 L(有 01 字串的串的语言)的自动机 A 的完整描述是
A = ({q_0,q_1,q_2}, {0,1}, \delta,q_0,{q_1})
其中\delta是上面描述的转移函数。
转移图
根据上面的例子,生成的转移图如下:
图 1:
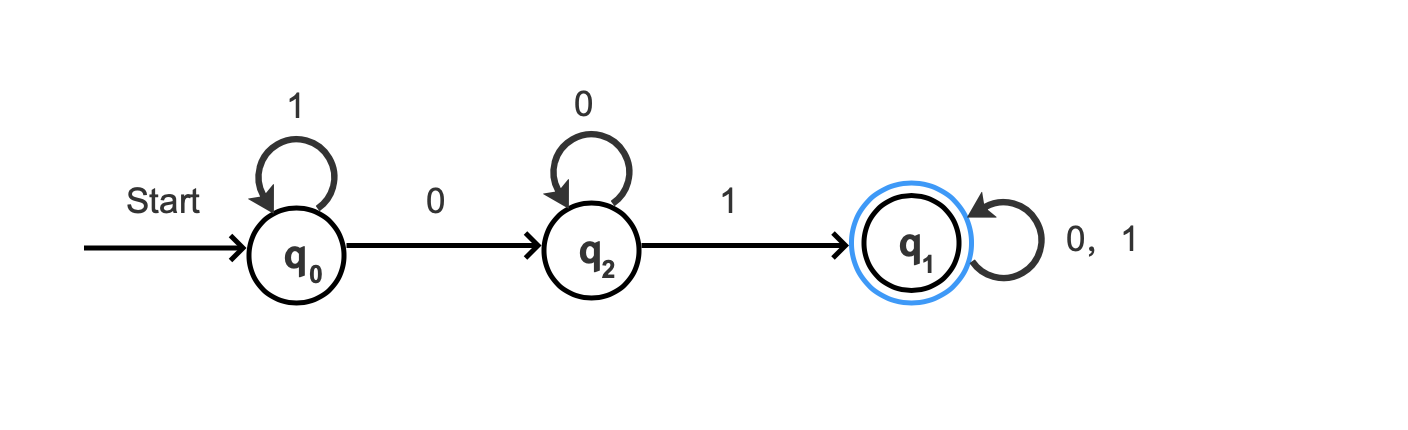
蓝色圆圈表示当前状态只处在接受状态。
DFA 在 Lucene 中的应用
在 Lucene,跟 DFA 相关功能有 通配符查询(WildcardQuery)、正则表达式(Regular Expression)、范围查询 TermRangeQuery 等。本篇文章中仅介绍 TermRangeQuery。
TermRangeQuery 中的 DFA
TermRangeQuery 利用 DFA 来使得在查询阶段能获得查询范围的所有 term,或者说所有的域值。我们直接通过一个例子来介绍 DFA。
例子
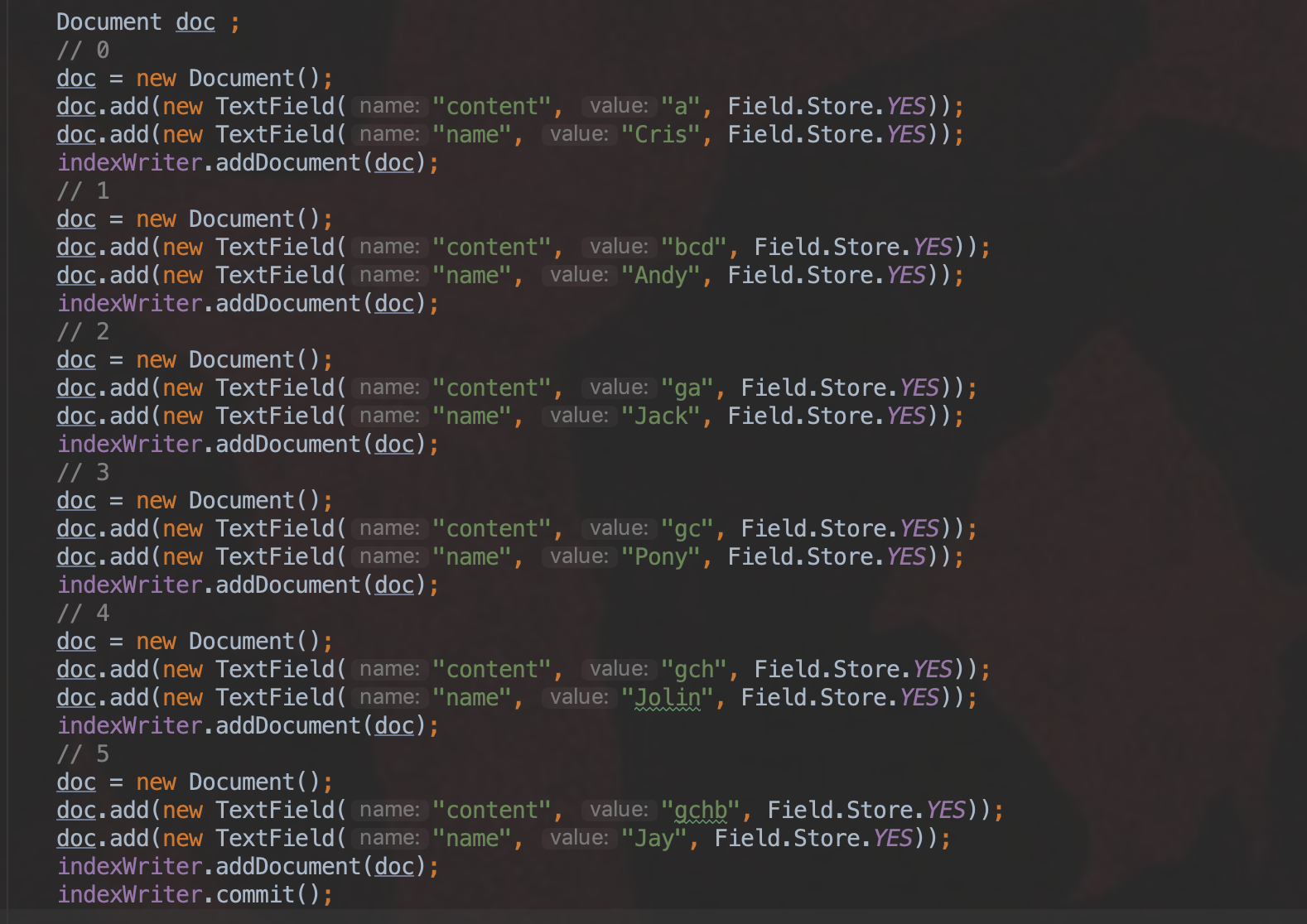
索引阶段的数据:
图 2:
查询条件:
图 3:

生成 DFA 的过程本篇文章不会详细介绍,理由是如果能弄明白上面提到的 DFA 的概念,然后再去根据我注释的源码,相信很快能明白其逻辑过程。生成 DFA 全部过程的源码都在 Automata.java 文件中的 Automaton makeBinaryInterval(…)方法中。GitHub 地址: https://github.com/luxugang/Lucene-7.5.0/blob/master/solr-7.5.0/lucene/core/src/java/org/apache/lucene/util/automaton/Automata.java
转移图:
图 4:
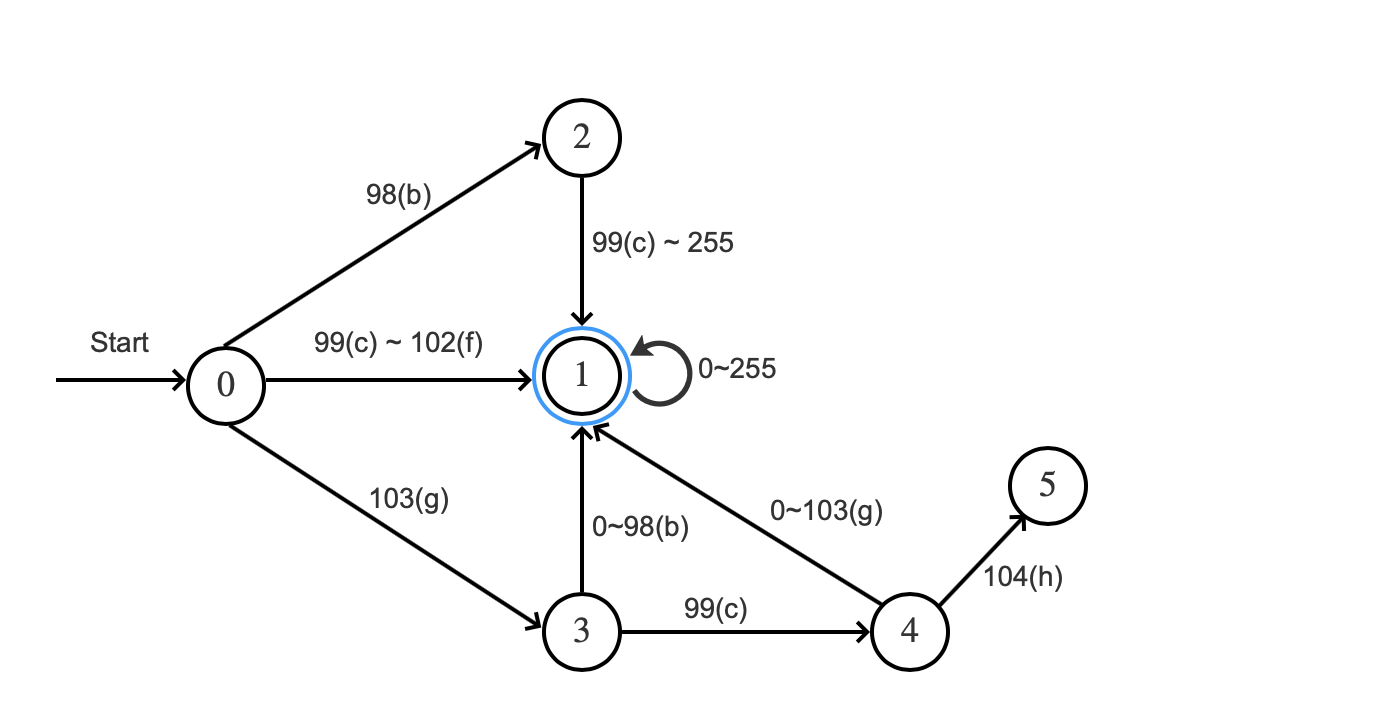
上图中 数字为 ASCII。
接受语言 L(域值大于等于"bc"并且小于等于"gch")的自动机 A 的完整描述是
A = ({0,1,2,3,4,5}, {0,… ,255}, \delta,0,{0,5})
筛选满足查询范围要求的域值
由于我们在 TermRangeQuery 中指定的域名为“content”,所以 Lucene 会按照从小到大的顺序遍历所有域名为"content"的域值,即"a"、“bcd”、“ga”、“gc”、“gch”、“gchb”,然后对这些域值逐个的去 DFA 中查找,比如说"bcd", 总是从状态 0 开始,检查每一个字符"b"、“c”、“d"能否在 DFA 中通过转移分别找到各自的状态,或者找到一个可接受的状态(蓝色圆圈的状态),如果前面两个条件之一满足,那么我们认为"bcd"是满足在范围"bc”~“gch"中的。
转移函数
状态 0 的转移函数
状态 0 有到状态 1、状态 2、状态 3 一共三种转移方式,转移函数为:
\delta(0,ASCII)\begin{cases}1,\qquad 99(c) ≤ ASCII ≤ 102(f)\\2,\qquad ASCII = 98(b)\\3,\qquad ASCII = 103(g)\end{cases}
状态 1 的转移函数
状态 1 是一个可接受状态,转移函数为:
\delta(1,ASCII) = 1,\qquad 所有的ASCII
状态 2 的转移函数
状态 2 有到状态 1 的一种转移方式,转移函数为:
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%BA%90%E7%A0%81%E7%B3%BB%E5%88%97%E6%9C%89%E7%A9%B7%E8%87%AA%E5%8A%A8%E6%9C%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


