源码系列索引文件的生成三之跳表
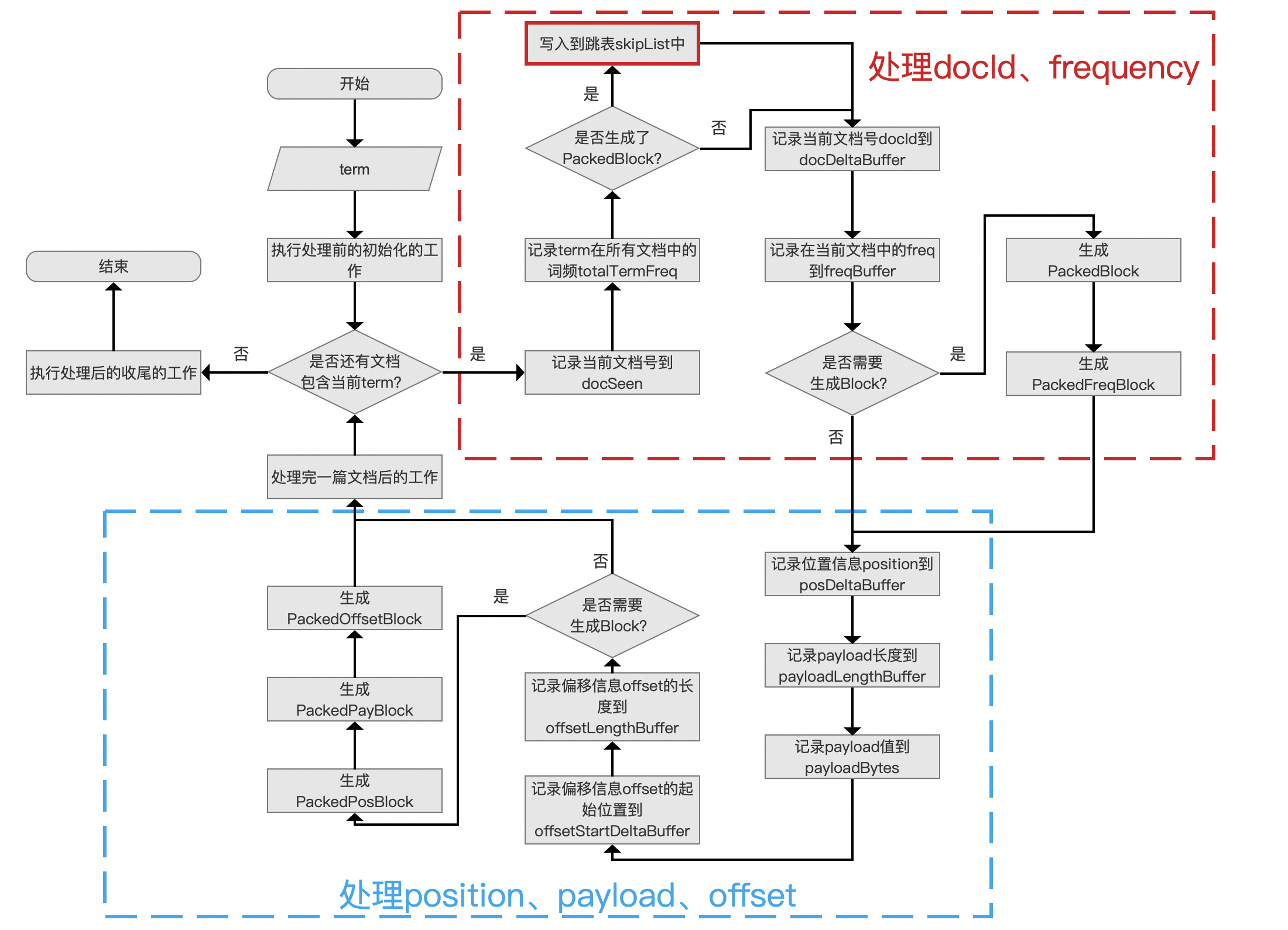
在文章 索引文件的生成(一) 中我们说到,在生成 索引文件.doc、 .pos、.pay 的过程中,当处理了 128 篇文档后会生成一个 PackedBlock,并将这个 PackedBlock 的信息写入到跳表 skipList 中,使得在读取阶段能根据文档号快速跳转到目标 PackedBlock,提高查询性能。
将 PackedBlock 的信息写入到跳表 skipList 的时机点如下图红色框所示:
图 1:
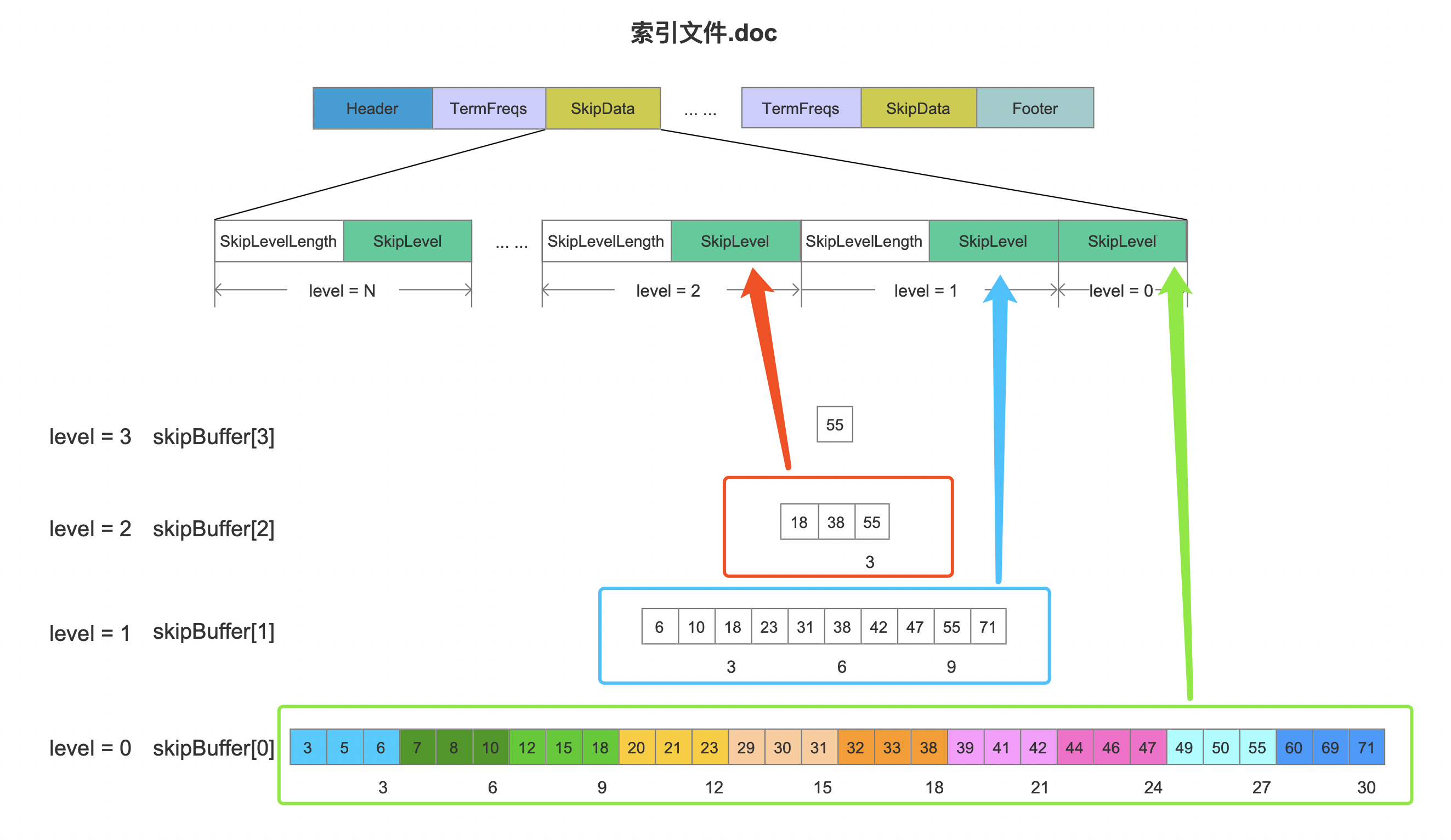
本篇文章介绍下 skipList 的写入/读取的过程,在介绍之前,我们先大致的描述下跳表是什么,如下图所示:
图 2:
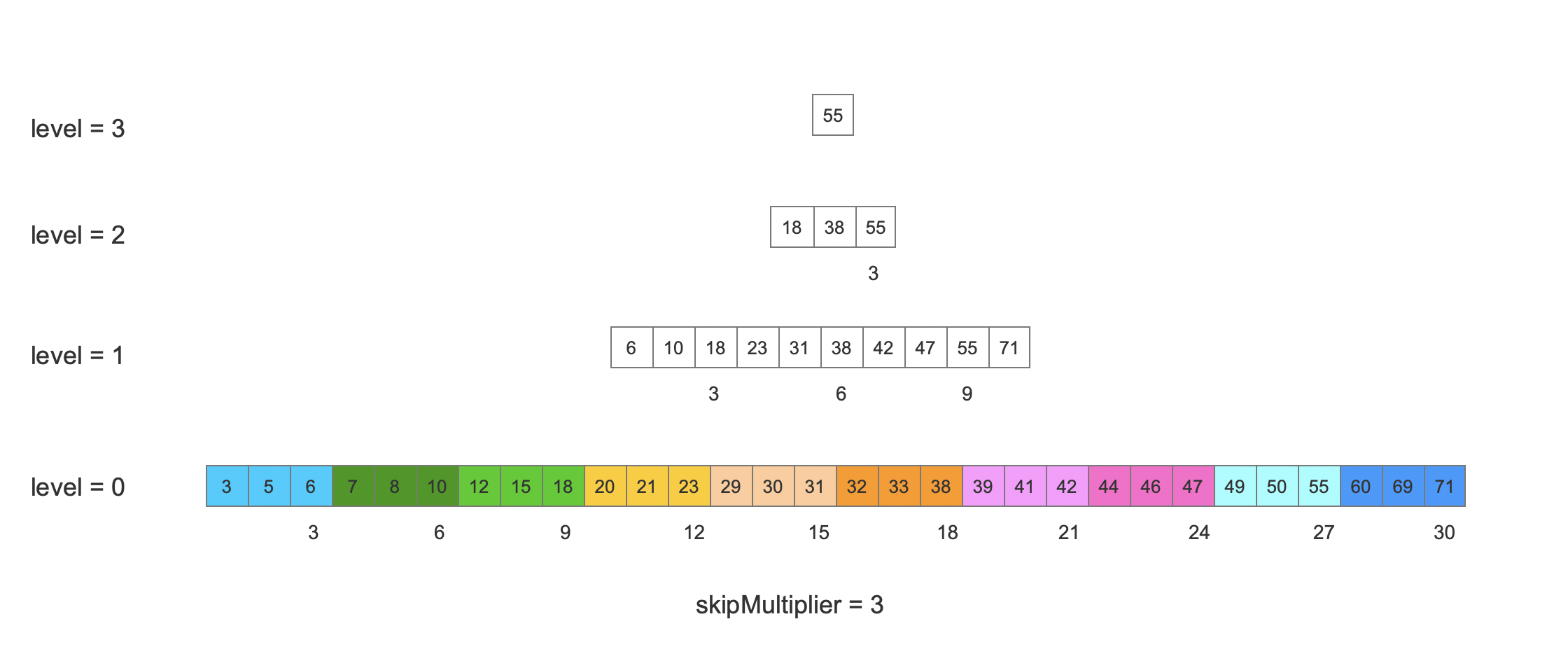
图 2 中每一层中的数值描述的是信息的编号,例如在 level=0 中的数值"3"描述的是第 3 条信息,在写入的过程中,每处理 skipMultiplier 个信息就在上一层生成一个索引,例如在 level=1 中的第 6 条信息中有一个索引,他指向 level=0 的一个位置;level=2 中的第 38 条信息,它包含一个索引,指向 level=1 中的一个位置。由此可见跳表是一个多层次的数据结构,除了第 0 层外,其他层中的每一条信息中拥有一个指向下一层的索引。
接着我们开始介绍在 Lucene 中如何生成以及读取 SkipList。
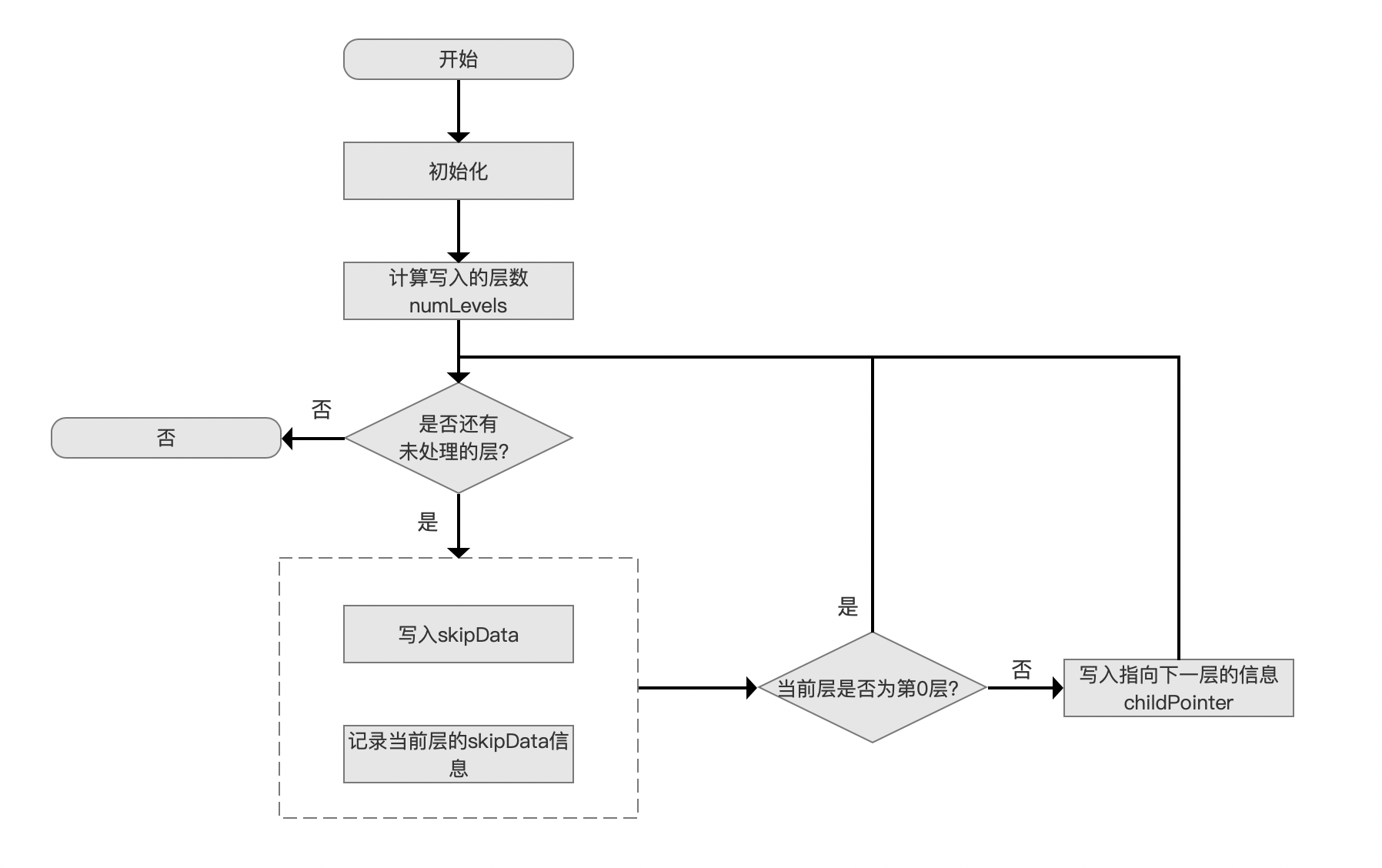
写入到跳表 skipList 中的流程图
图 3:
初始化
图 4:

需要初始化的内容如下所示:
- skipInterval:该值描述了在 level=0 层,每处理 skipInterval 篇文档,就生成一个 skipDatum,该值默认为 128
- skipMultiplier:该值描述了在所有层,每处理 skipMultiplier 个 skipDatum,就在上一层生成一个新的 skipDatum,该值默认为 8
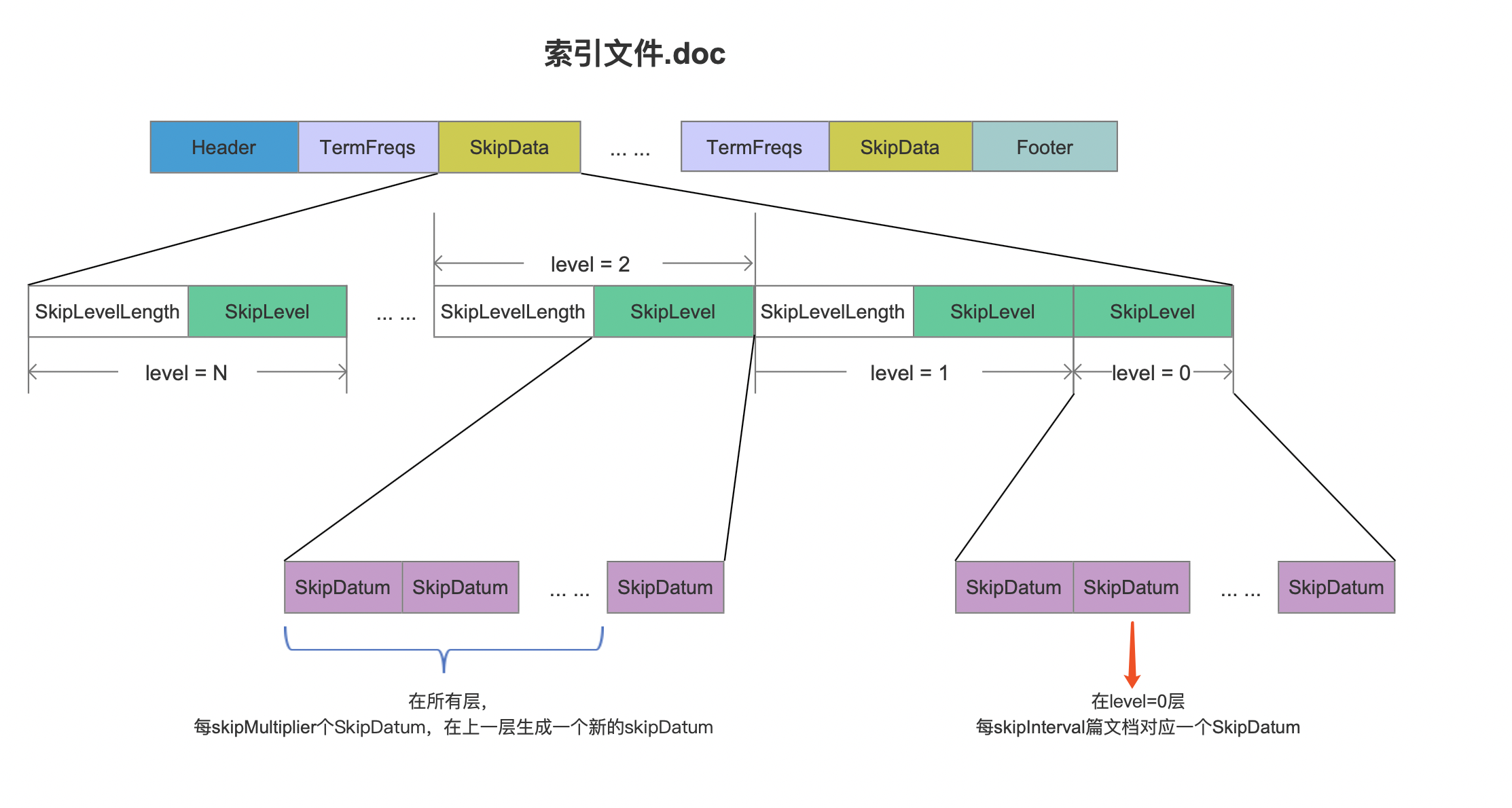
skipInterval、skipMultiplier、skipDatum 的关系在 索引文件.doc 中的关系如下所示:
图 5:
- numberOfSkipLevels:该值描述的是我们即将生成的 skipList 中的层数,即图 2 中的 level 的最大值
如何计算 numberOfSkipLevels:
根据上文中,skipInterval 跟 skipMultiplier 的介绍,可以看出我们根据待处理的文档数量就可以计算出 numberOfSkipLevels,计算公式如下:
|
|
上述公式中,df(document frequency)即待处理的文档数量。
待处理的文档数量是如何获得的:
在 索引文件的生成(一) 中我们介绍了生成索引文件.doc 的时机点,即在 flush 阶段,所以就可以根据的段的信息获得待处理的文档数量。
- skipBuffer[ ]数组:该数组中存放的元素为每一层的数据,根据图 2 可以知道,该数据就是 SkipDatum 的集合,并且数组的元素数量为 numberOfSkipLevels,skipBuffer[ ]中每一个元素在 索引文件.doc 中对应为一个 SkipLevel 字段,如下所示:
图 6:
计算写入的层数 numLevels
图 7:

根据当前已经处理的文档数量,预先计算出将待写入 SkipDatum 信息的层数,计算方式如下:
|
|
是否还有未处理的层?
图 8:

在上一个流程中,如果 numLevels 的值 > 1,那么按照 level 从小到大依次处理。
层内处理
图 9:
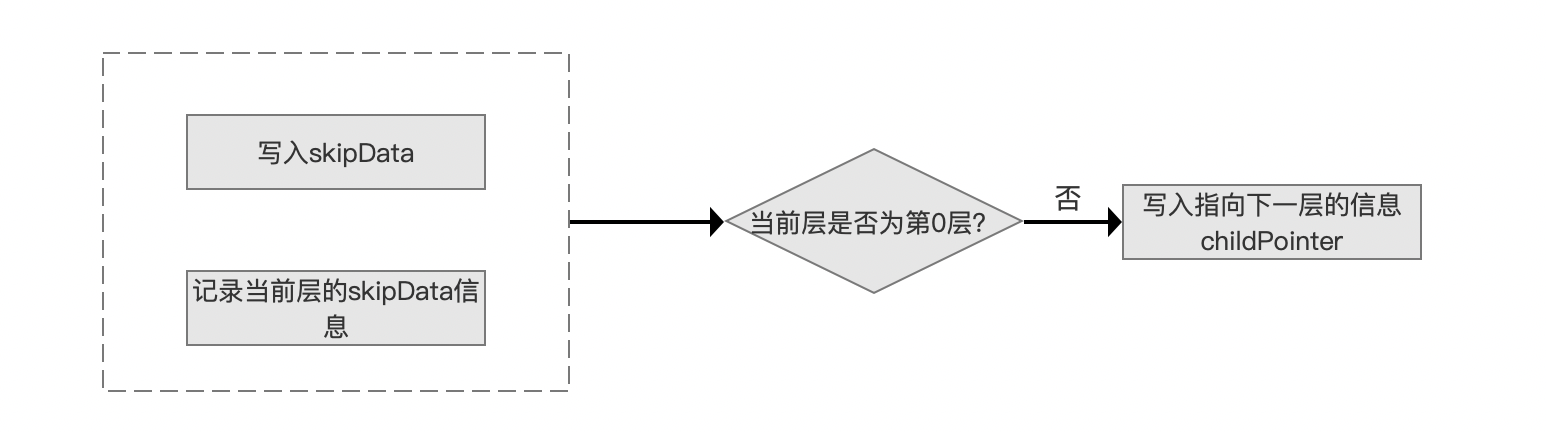
在 层内处理 的流程中,首先将在图 1 中 是否生成了PackedBlock 流程中生成的 block 信息生成一个 SkipDatum 写入到 skipData 中,block 包含的信息如下图红框所示:
图 10:
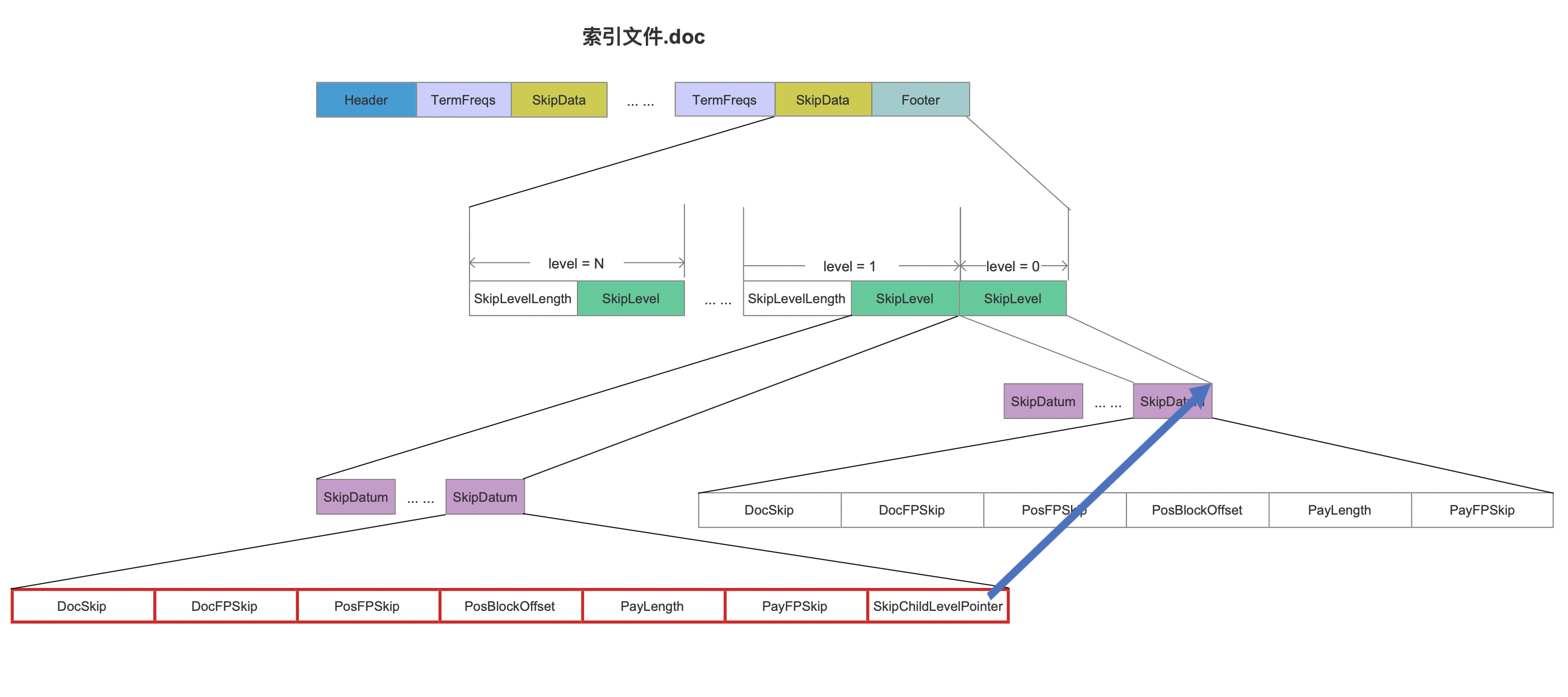
另外,在图 10 中,如果在 level>0 的层写入一个 SkipDatum 后,相比较在 level=0 中的 SKipDatum, 它多了一个字段 SkipChildLevelPointer,它是一个指针,指向下一层的一个 SkipDatum。
SkipDatum 中的字段含义在文章 索引文件之.doc 中已经介绍,不赘述,另外图 10 中的 SkipDatum 中的信息除了 SkipChildLevelPointer,其他所有的字段都是用 差值存储,所以在图 9 中,我们需要执行 记录当前层的skipData信息 的流程,使得下一个同一层内的新生成的 SkipDatum 可以用来进行差值计算。
SkipDatum 中的字段干什么用的
这些字段的作用正是用来展示跳表 SkipList 跳表在 Lucene 中的功能,它们作为指针来描述当前 block 在的其他索引文件中的位置信息。在文章 索引文件的生成(二) 中我们介绍图 1 中的 处理完一篇文档后的工作 流程点时,说到在该流程点生成了几个信息,他们跟 SkipDatum 中的字段的对应关系如下:
- lastBlockDocID:记录刚刚处理完的那篇文档的文档号,即 DocSkip
- lastBlockPayFP:描述是处理完 128 篇文档后,在索引文件。pay 中的位置信息,即 PayFPSkip
- lastBlockPosFP:描述是处理完 128 篇文档后,在索引文件。pos 中的位置信息,即 PosFPSkip
- lastBlockPosBufferUpto:在 posDeltaBuffer、payloadLengthBuffer、offsetStartDeltaBuffer、offsetLengthBuffer 数组中的数组下标值,即 PosBlockOffset
- lastBlockPayloadByteUpto:在 payloadBytes 数组中的数组下标值,即 PayLength
另外还有 DocFPSkip 值并没有在 处理完一篇文档后的工作 流程中获取,该值描述的是在索引文件.doc 当前可写入的位置,故直接可以获取。
SkipDatum 中的字段与索引文件.doc、.pos、.pay 的关系如下所示:
图 11:
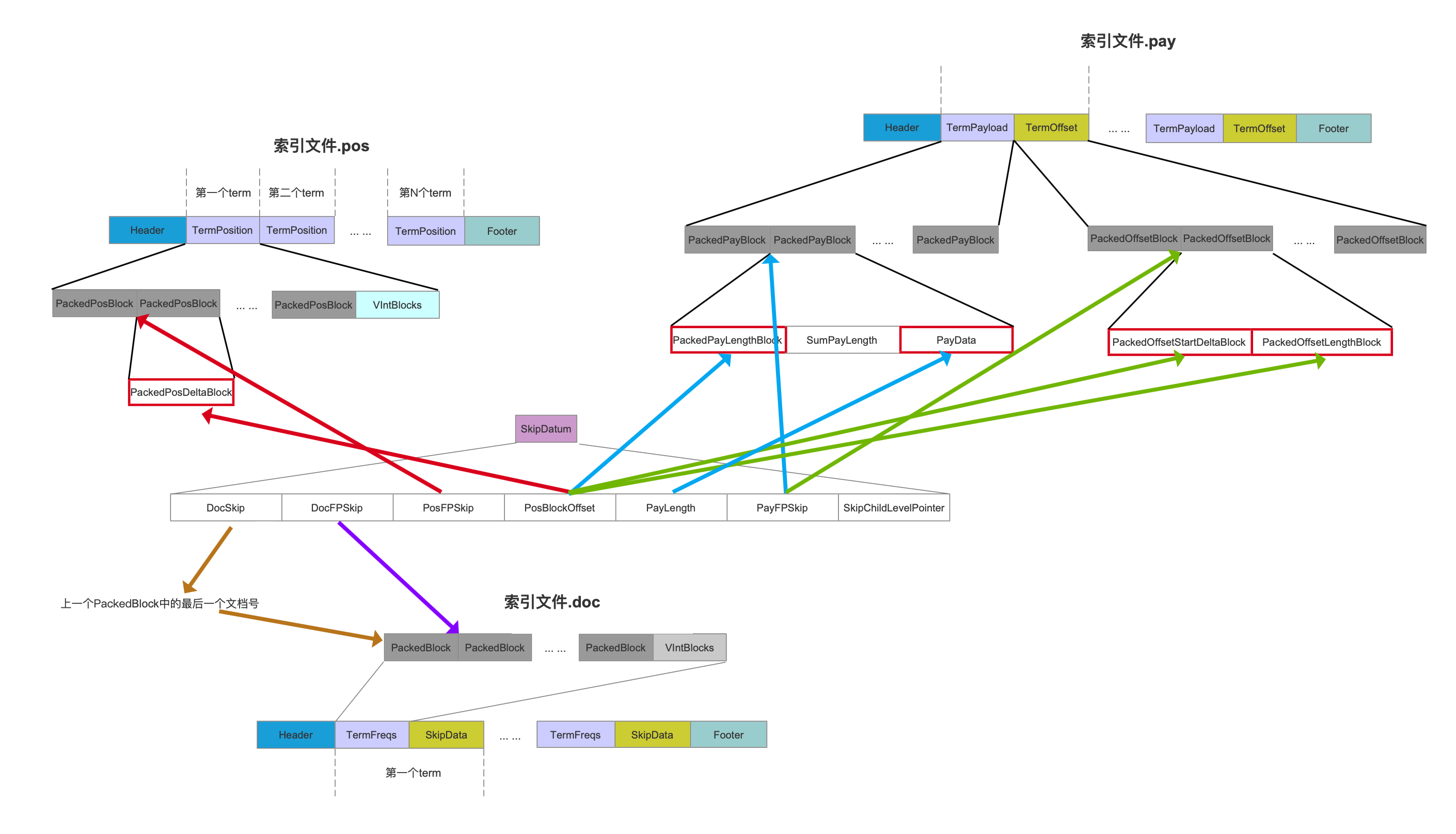
图 10 中,由于是按照每处理 128 篇文档才执行 写入到跳表skipList中 的流程,那么有可能此时位置信息 position、偏移信息 offset,payload 信息没有生成一个 PackedBlock,那么 SkipDatum 需要两个指针的组合才能找到在索引文件。pos、.pay 中的位置,比如说我们需要 PosFPSkip+PosBlockOffset 的组合值才能找到位置信息(没明白的话说明你没有看文章 索引文件的生成(一) 以及 索引文件的生成(二))
结语
基于篇�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%BA%90%E7%A0%81%E7%B3%BB%E5%88%97%E7%B4%A2%E5%BC%95%E6%96%87%E4%BB%B6%E7%9A%84%E7%94%9F%E6%88%90%E4%B8%89%E4%B9%8B%E8%B7%B3%E8%A1%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


