源码系列索引文件的生成二之
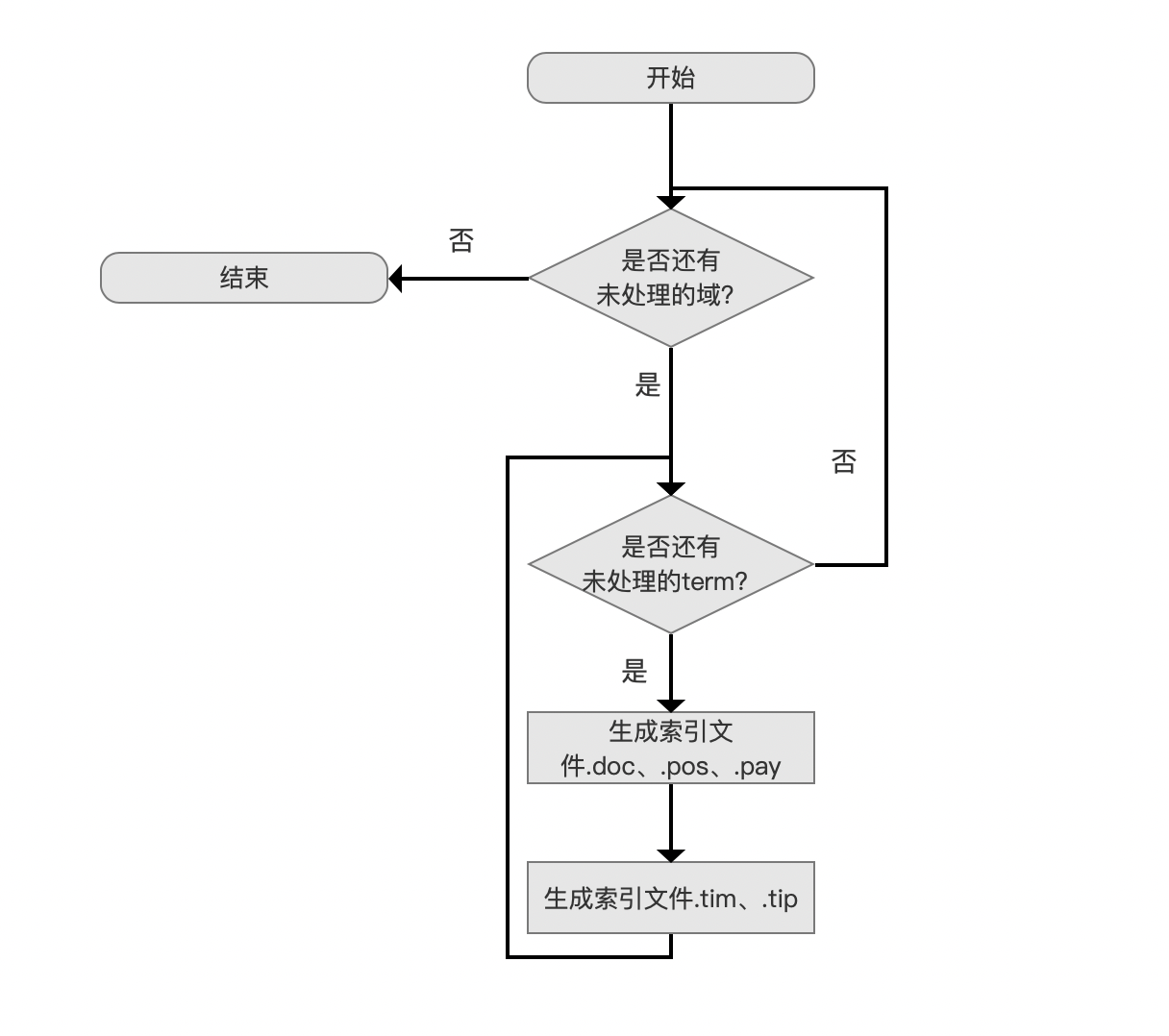
生成索引文件。tim、.tip、.doc、.pos、.pay 的流程图
图 1:
我们继续介绍流程点 生成索引文件.doc、.pos、.pay。
生成索引文件.doc、.pos、.pay 的流程图
图 2:
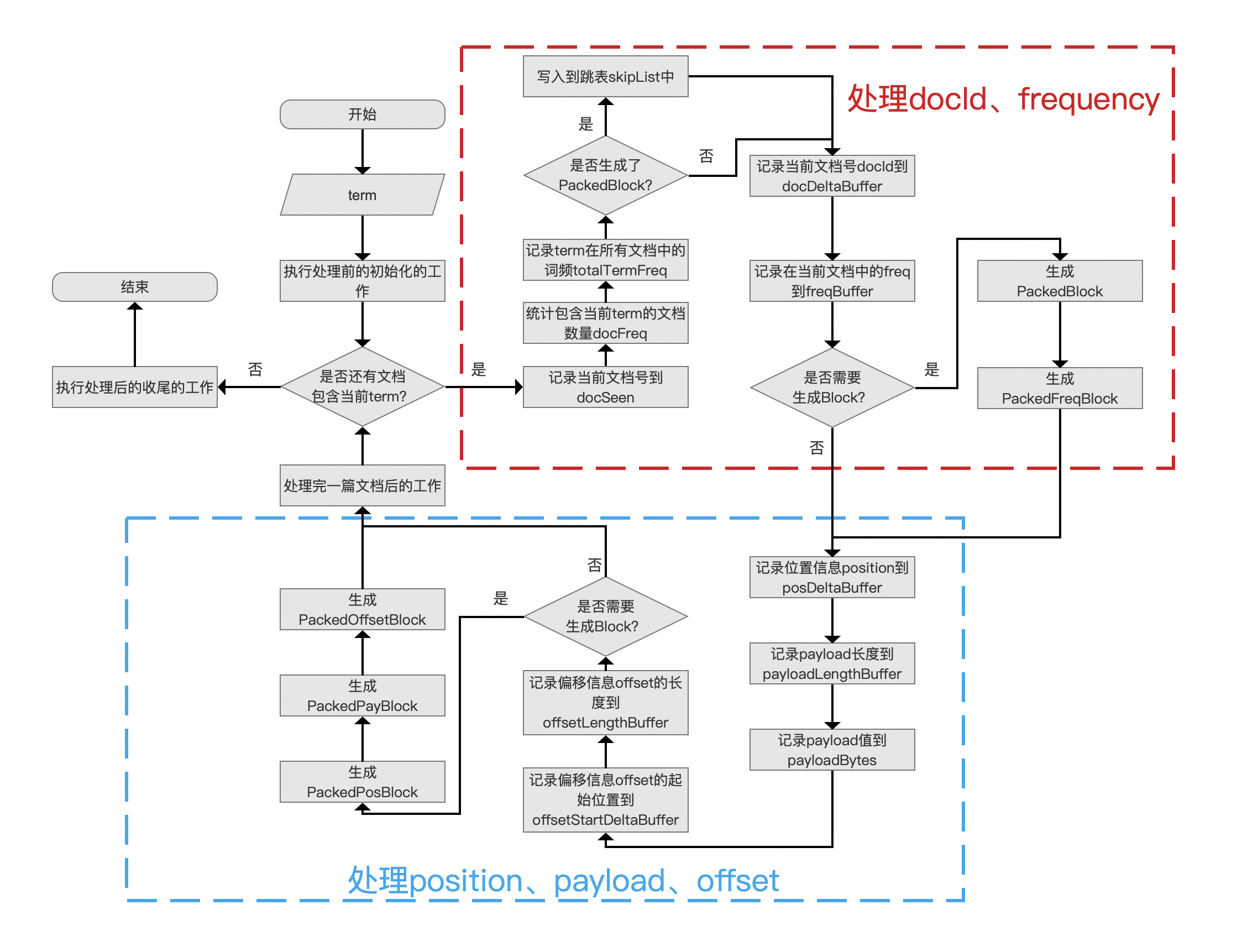
记录位置信息 position、payload、偏移信息 offset
图 3:
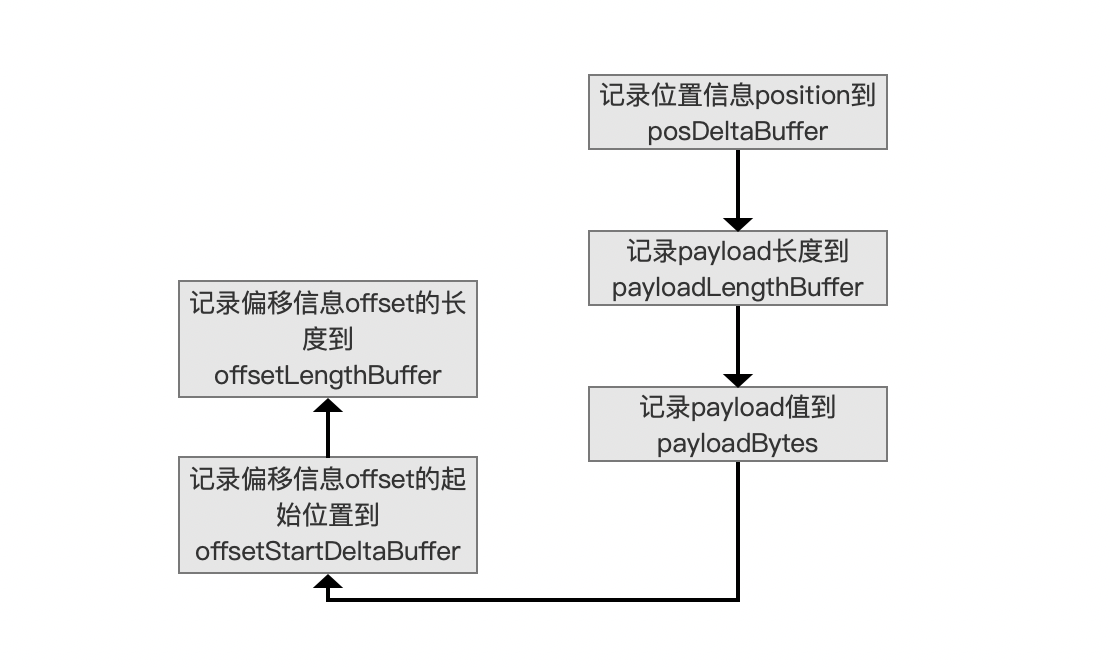
当前 term 在一篇文档中的所有位置信息 position 以及偏移信息 offset 的起始位置是有序的,所以可以跟文档号一样(见 索引文件的生成(一) 关于数组 docDeltaBuffer 的介绍),分别使用差值存储到数组 posDeltaBuffer、offsetStartDeltaBuffer 中,而图 3 中其他数组,payloadLengthBuffer、payloadBytes、offsetLengthBuffer 则只能存储原始数据。另外要说的是,在处理的过程中,有些位置是不带有 payload 信息,那么对应 payloadLengthBuffer 中的数组元素为 0。
这几个数组对应在 索引文件.pos、.pay 中的位置如下所示:
图 4:
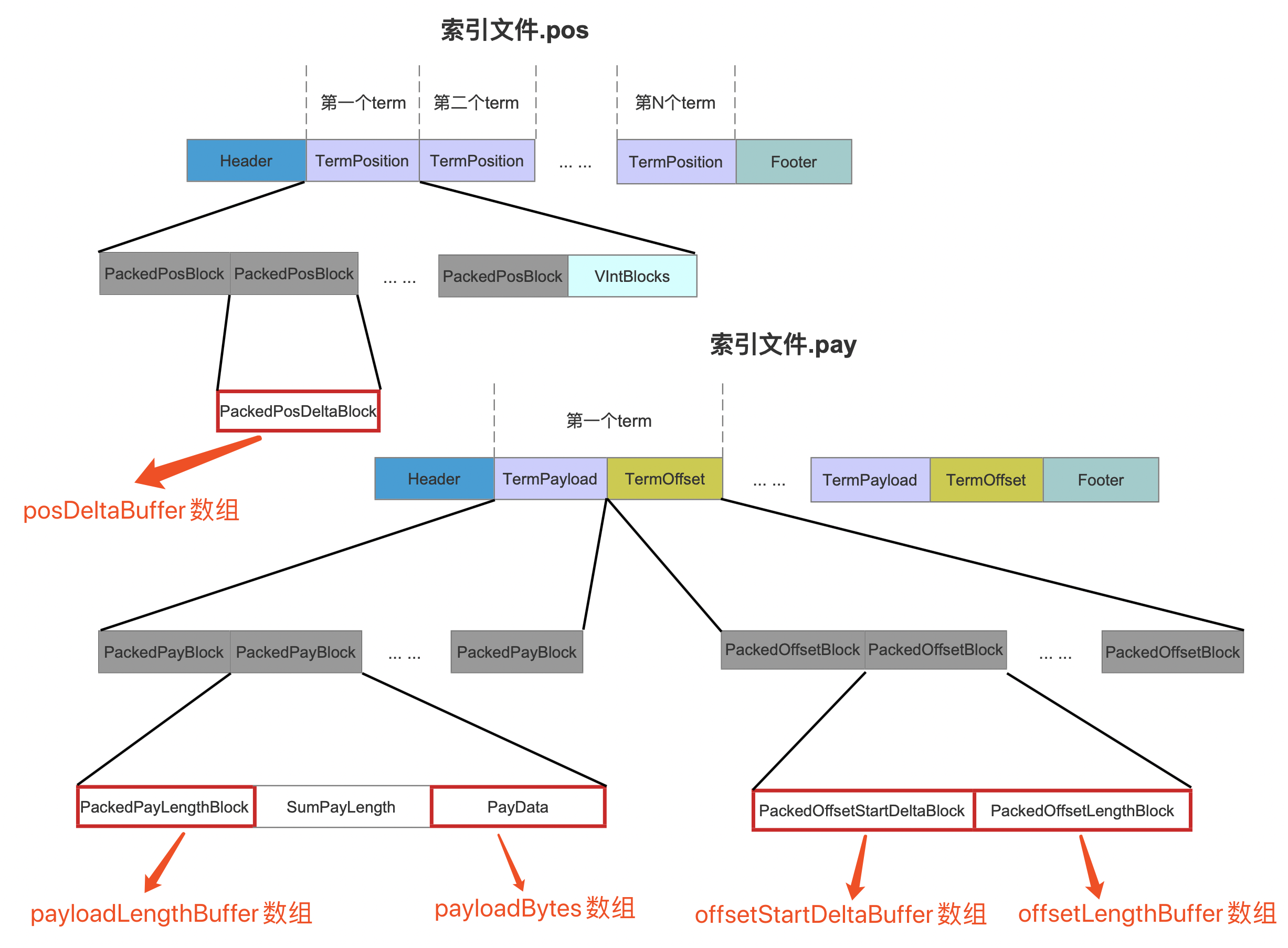
另外图 4 中的索引文件。pay 中的字段 SumPayLength 描述的是当前 block 中 PayData 的的长度,在读取阶段用来确认 PayData 在索引文件。pay 中的数据区间。
是否需要生成 Block?
图 5:
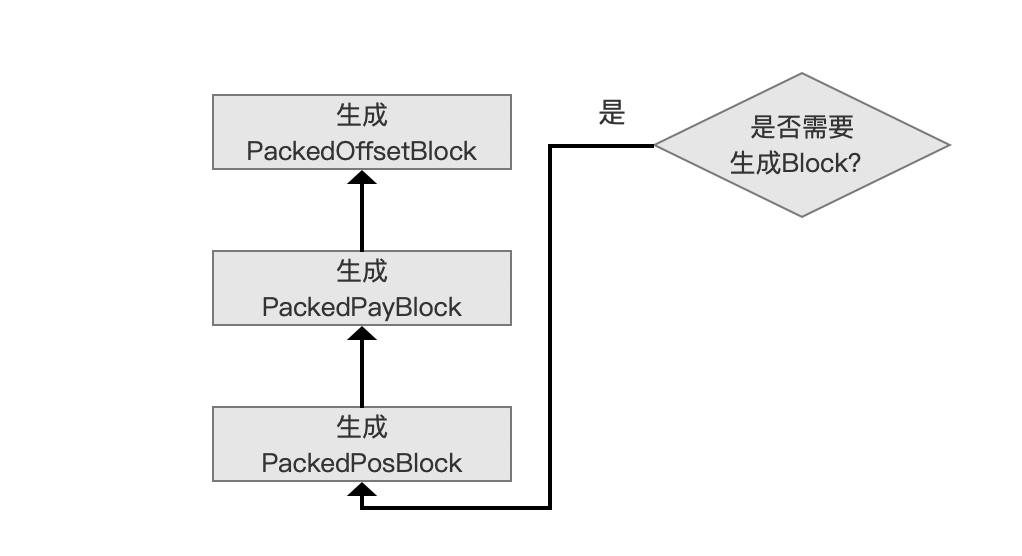
当处理 128 个当前 term 的位置信息 position 后,即 posDeltaBuffer 数组中的元素个数达到 128,那么就要生成三个 block:PackedPosBlock、PackedPayBlock、PackedOffsetBlock,即图 4 中的灰色标注的字段。
为什么要生成 PackedBlock:
当然是为了降低存储空间的使用量,至于能压缩率是多少,可以看 PackedInts 文章的介绍。
为什么选择 128 作为生成 PackedBlock 的阈值:
先给出源码中的注释:
|
|
注释中要求阈值只要是 64 的倍数就行,目的是能字节对齐。因为在使用 PackedInts 实现压缩存储后的数据用 long 类型的数组存储,如果待处理的数据集(例如 posDeltaBuffer 数组)使用 固定字节按位存储(见 PackedInts(一)),那么只要数据集中的数量是 64 的倍数,就能按照 64 对齐,即 long 类型数组中的每一个 long 中每一个 bit 位都是有效数据。至于为什么是 128,本人不做妄加猜测,目前没有弄明白。
处理完一篇文档后的工作
图 6:

每处理完一篇包含当前 term 的文档,我们需要判断下我们目前处理的文档总数是否达到 128 篇,如果没有达到,那么该流程什么也不做,否则需要记录下面的信息:
- lastBlockDocID:记录刚刚处理完的那篇文档的文档号
- lastBlockPayFP:描述是处理完 128 篇文档后,在索引文件。pay 中的位置信息
- lastBlockPosFP:描述是处理完 128 篇文档后,,在索引文件。pos 中的位置信息
- lastBlockPosBufferUpto:在 posDeltaBuffer、payloadLengthBuffer、offsetStartDeltaBuffer、offsetLengthBuffer
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%BA%90%E7%A0%81%E7%B3%BB%E5%88%97%E7%B4%A2%E5%BC%95%E6%96%87%E4%BB%B6%E7%9A%84%E7%94%9F%E6%88%90%E4%BA%8C%E4%B9%8B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


