源码系列索引文件的生成六之
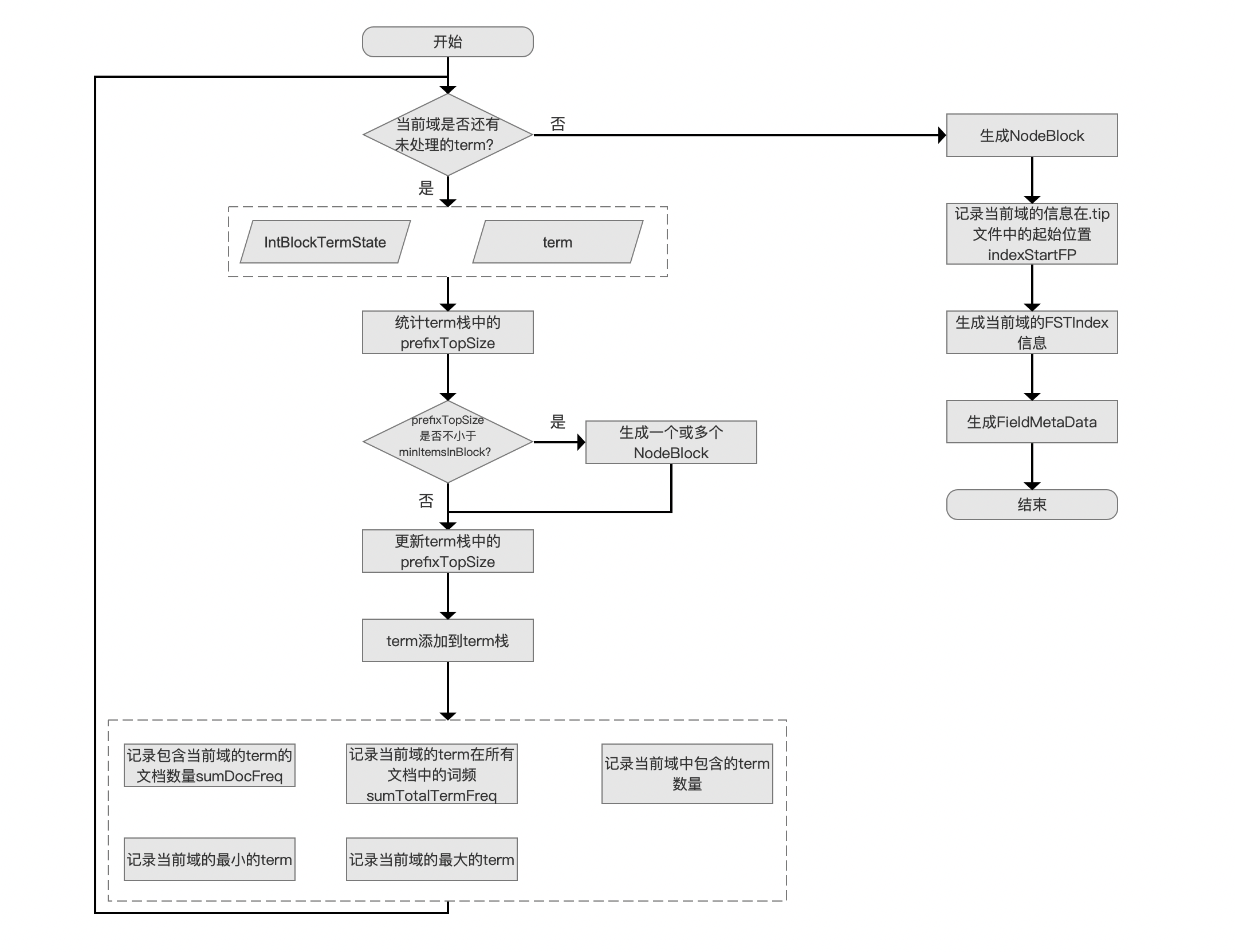
本文承接 索引文件的生成(五) 继续介绍剩余的内容,下面先给出生成索引文件。tim、.tip 的流程图。
生成索引文件。tim、.tip 的流程图
图 1:
上一篇文章中,我们介绍了执行 生成一个或多个NodeBlock 的触发条件,本文就其实现过程展开介绍,同样的,下文中出现的并且没有作出解释的名词,说明已经在文章 索引文件的生成(五) 中介绍,不在本文中赘述。
生成一个或多个 NodeBlock 的流程图
图 2:
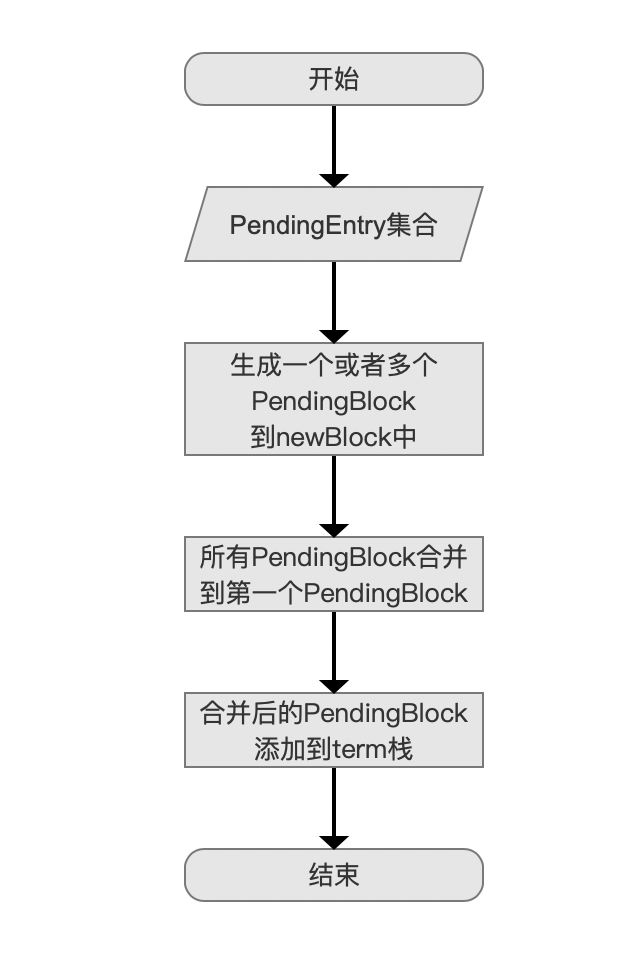
PendingEntry 集合
图 3:

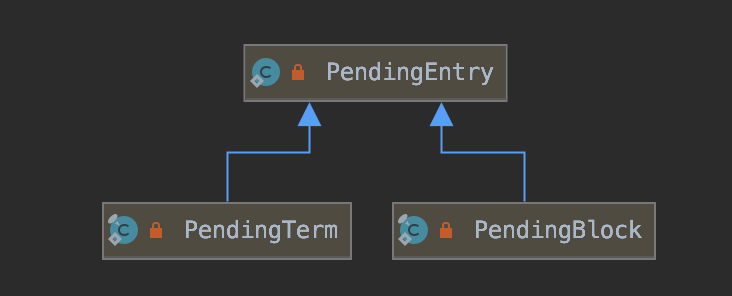
我们在上一篇文章中说到,term 栈中存放了两种类型的信息:PendingTerm 和 PendingBlock,它们两个的类图关系如下所示:
图 4:
故图 2 流程图的准备数据是一个 PendingEntry 集合,它就是 term 栈(本人对该集合的称呼 😂),在源码中即 pending 链表,定义如下:
|
|
生成一个或者多个 PendingBlock 到 newBlock 中
图 5:

在介绍该流程点之前,我们需要了解下 PendingBlock 类中的一些信息,PendingBlock 类的定义如下:
图 6:
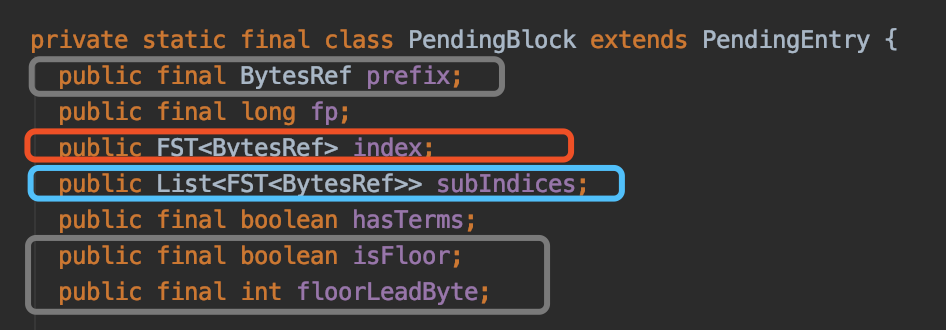
第一次执行图 2 的流程时,PendingEntry 集合中 总是 只存在 PendingTerm 信息,集合中的每一个元素代表了一个 term 包含的信息,在执行完图 2 的流程之后,PendingEntry 集合中的信息就转化为一个 PendingBlock(我们记为 block1),它用来描述具有相同前缀的 term 集合的信息,并且重新添加到 term 栈中;如果下一次执行图 2 的流程时,PendingEntry 集合中包含了 PendingTerm 和 PendingBlock(block1)两种类型信息,那么在执行完图 2 的流程后,PendingEntry 集合中的信息就会转化为一个新的 PendingBlock(我们记为 block2),由此可见执行图 1 的流程点 生成一个或多个NodeBlock 实际是通过 嵌套 的方式将所有 term 的信息转化为一个 PendingBlock。
图 6 中红框标注的 index 描述的是一个 PendingBlock 自身的信息,而蓝框标注的 subIndices 描述的是该 PendingBlock 中嵌套的 PendingBlock 信息的集合(即每一个 PendingBlock 的 index 信息),对于 block1 跟 block2 来说,block2 对象中的 subIndices 中包含了一条信息,该信息为 block1 中的 index 信息,至于 index 中包含了具体哪些信息,下文中会展开介绍。
我们回到 生成一个或者多个PendingBlock到newBlock中 的流程点的介绍。
为什么可能会生成多个 PendingBlock
对于待处理的 PendingEntry 集合,它包含的信息数量至少有 minItemsInBlock 个(为什么使用 至少 这个副词,见文章 索引文件的生成(五)),因为这是图 2 的流程的触发条件,如果 PendingEntry 集合中的数量过多,那么需要处理为多个 PendingBlock,这么处理的原因以及处理方式在源码中也给出了解释,见 https://github.com/LuXugang/Lucene-7.5.0/blob/master/solr-7.5.0/lucene/core/src/java/org/apache/lucene/codecs/blocktree/BlockTreeTermsWriter.java 中的 void writeBlocks(int prefixLength, int count)方法:
|
|
上述的注释大意为:如果一个 block 太大,那么就划分为多个 floor block,并且在每个 floor block 中记录后缀的第一个字符作为 leading label,使得在搜索阶段能通过前缀以及 leading label 直接跳转到对应的 floor block,另外每生成一个 floor block,该 block 中至少包含了 minItemsInBlock 条 PendingEntry 信息,这种划分方式通常会使得最后一个 block 中包含的信息数量较少。
对于上述的注释我们会提出以下几个问题:
- 问题一:划分出一个 floor block 的规则是什么
- 问题二:在搜索阶段,如何通过前缀跟 leading label 快速跳转到对应 floor block
问题一:划分出一个 floor block 的规则是什么
使用下面两个阈值作为划分参数:
- minItemsInBlock:默认值为 25
- maxItemsInBlock:默认值为 48,它的值可以设定的范围如下所示:
|
|
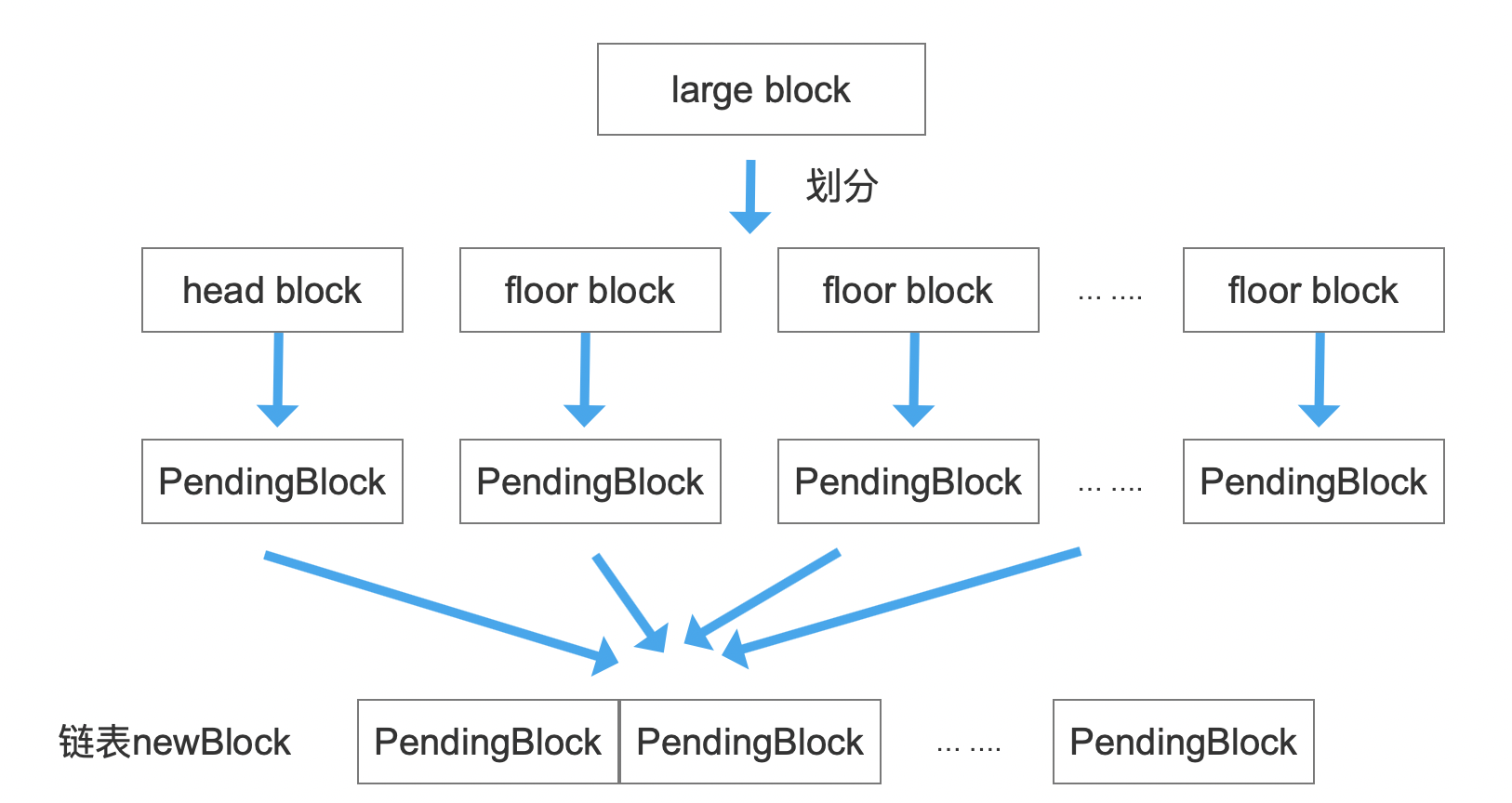
划分的规则:每处理图 3 中 PendingEntry 集合中 N 个信息,就生成一个 block,除了第一个 block(我们称之为 head block),其他 block 都是 floor block,其中 N 值不小于 minItemsInBlock,并且 PendingEntry 集合中未处理的信息不小于 maxItemsInBlock,如下所示:
图 7:
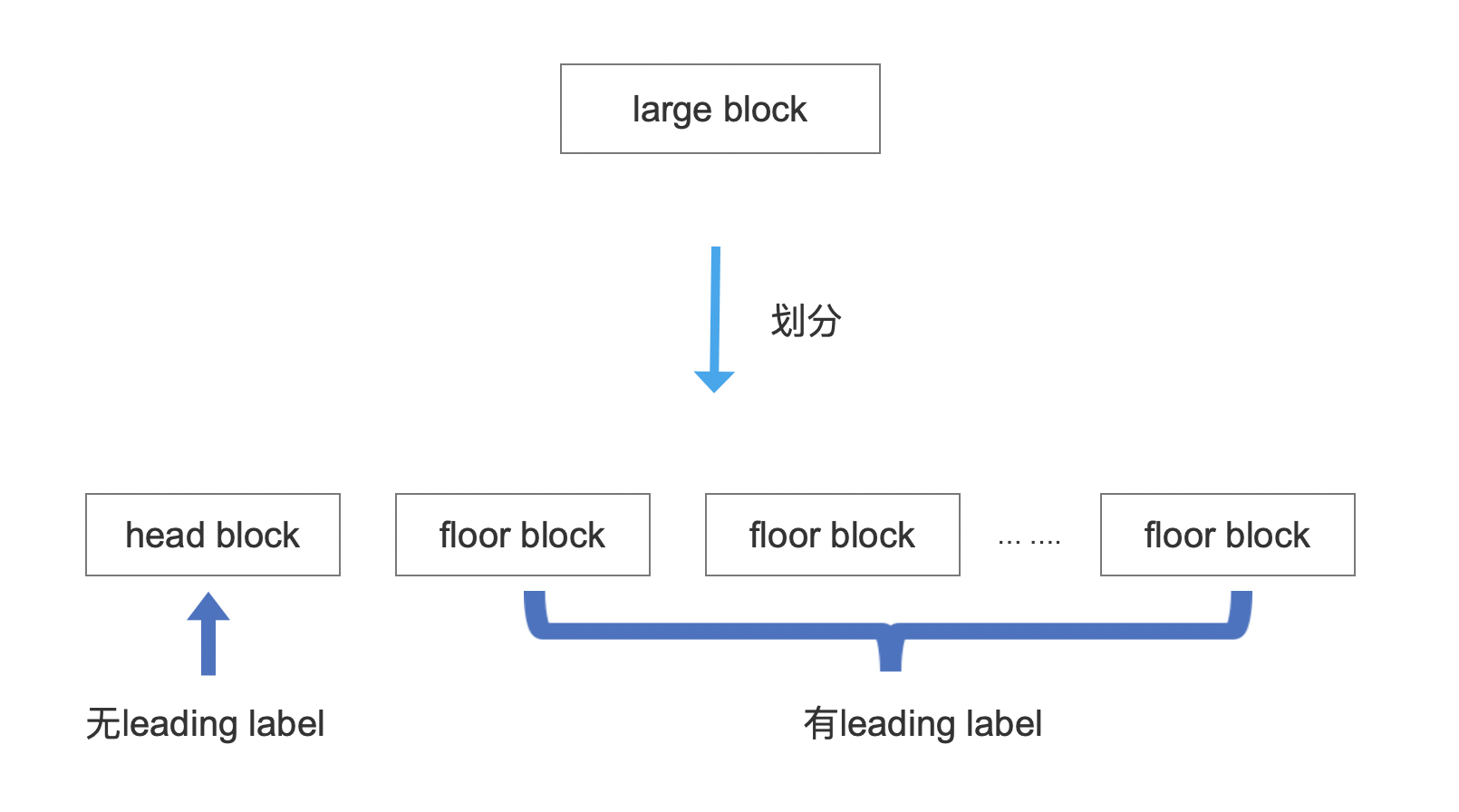
随后将 head block 以及 floor block 中包含的 PendingEntry 信息分别生成 PendingBlock,两种类型的 block 生成的 PendingBlock 的差异性用图 6 中黑灰色标注的三个信息来区分:
- prefix:相同前缀 + leading label,所有 block 的相同前缀都是一样的,对于 head block,它生成的 PendingBlock 对应的 prefix 的值只有相同前缀
- isFloor:是否为 floor block
- floorLeadByte:该字段即 leading label
在生成 PendingBlock 的过程中,同时也是将 term 信息写入到 索引文件.timp 文件的过程,即生成 NodeBlock 的过程,其中一个 block(head block 或者 floor block)对应生成一个 NodeBlock,上文中我们说到 PendingEntry 信息可分为两种类型:PendingTerm 和 PendingBlock,根据 block 中的不同类型的 PendingEntry,在索引文件。timp 中写入的数据结构也是不同的。
block 中只包含 PendingTerm
图 8:
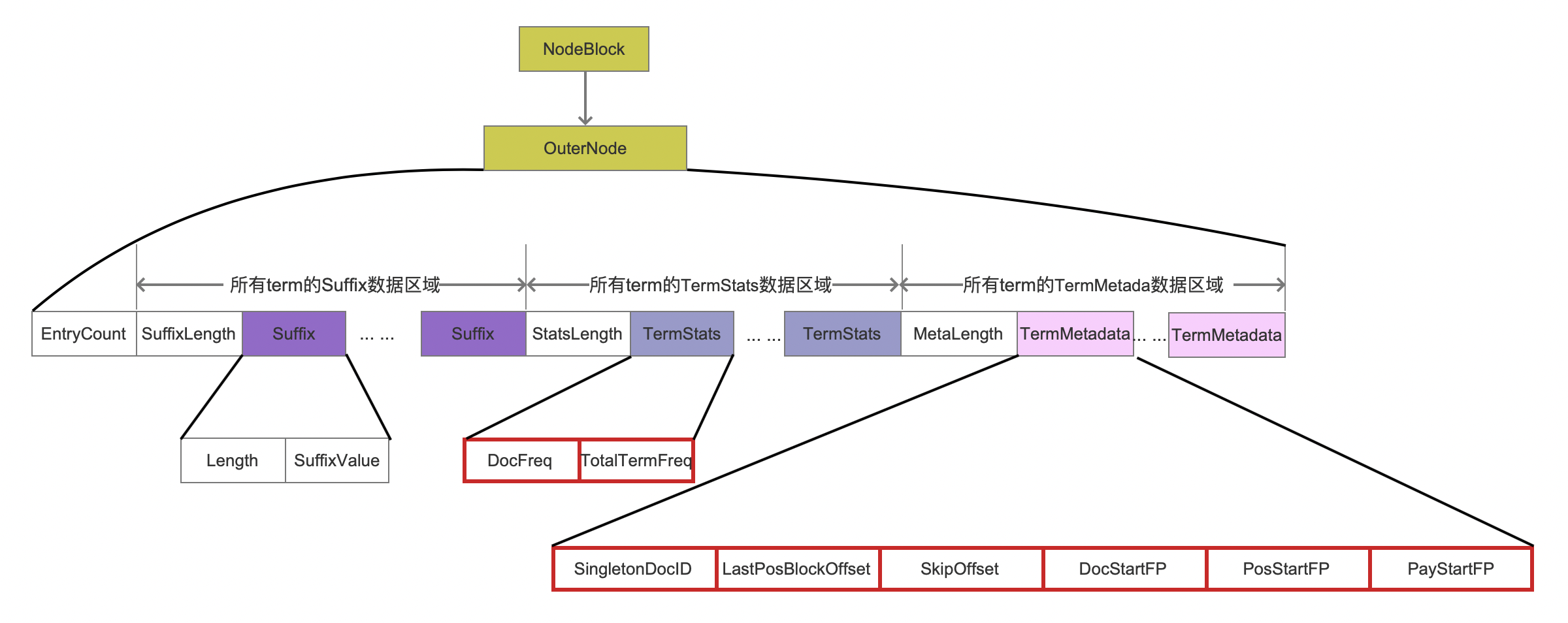
根据 block 中包含的 PendingEntry 的类型,可以细化的将 block中只包含PendingTerm 对应生成的 NodeBlock 称为 OuterNode, block中至少包含PendingBlock(至少包含 PendingBlock 意思是只包含 PendingBlock 或者同时包含 PendingBlock 以及 PendingTerm)对应生成的 NodeBlock 称为 InnerNode。
图 8 中,所有的字段的含义已经在文章 索引文件之 tim&&tip 介绍,不一一展开介绍,这里注意的是红框标注的 8 个字段描述的是一个 term 的信息,该信息在生成 索引文件.doc、 pos、.pay 之后,使用 IntBlockTermState 封装这些信息,并且通过做为图 1 中的准备数据存储到索引文件。tim 中,这 8 个字段的介绍见文章 索引文件的生成(五)之 tim&&tip。
当 outerNode 写入到索引文件。tim 之后,它在索引文件中。tim 的起始位置就用图 6 的 fp 信息描述,由于 block 中存在 PendingTerm,故图 6 中的 hasTerms 信息被置为 true,至此,图 6 中 PendingBlock 包含的所有信息都已经介绍完毕,并且我们也明白了 PendingBlock 的作用:用来描述一个 NodeBlock 的所有信息。
block 中至少包含 PendingBlock
我们结合一个例子来介绍这种情况。
图 9:
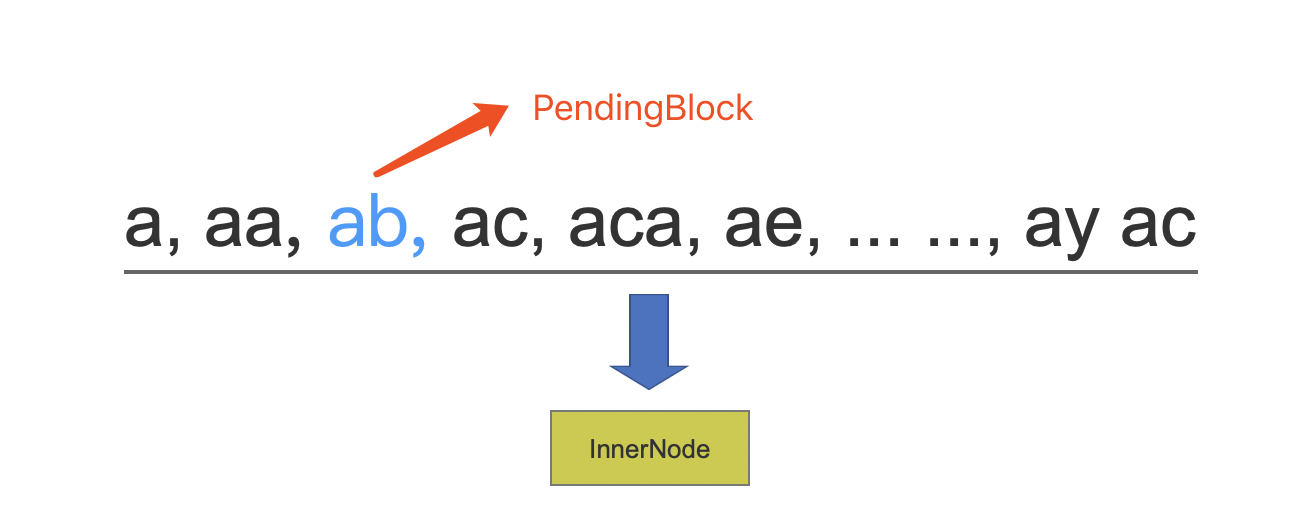
待处理的 PendingEntry 集合如图 9 所示,其中除了"ab"是一个 PendingBlock,其他都是 PendingTerm,将该 PendingEntry 集合生成一个 NodeBlock,它是 InnerNode。
图 10:
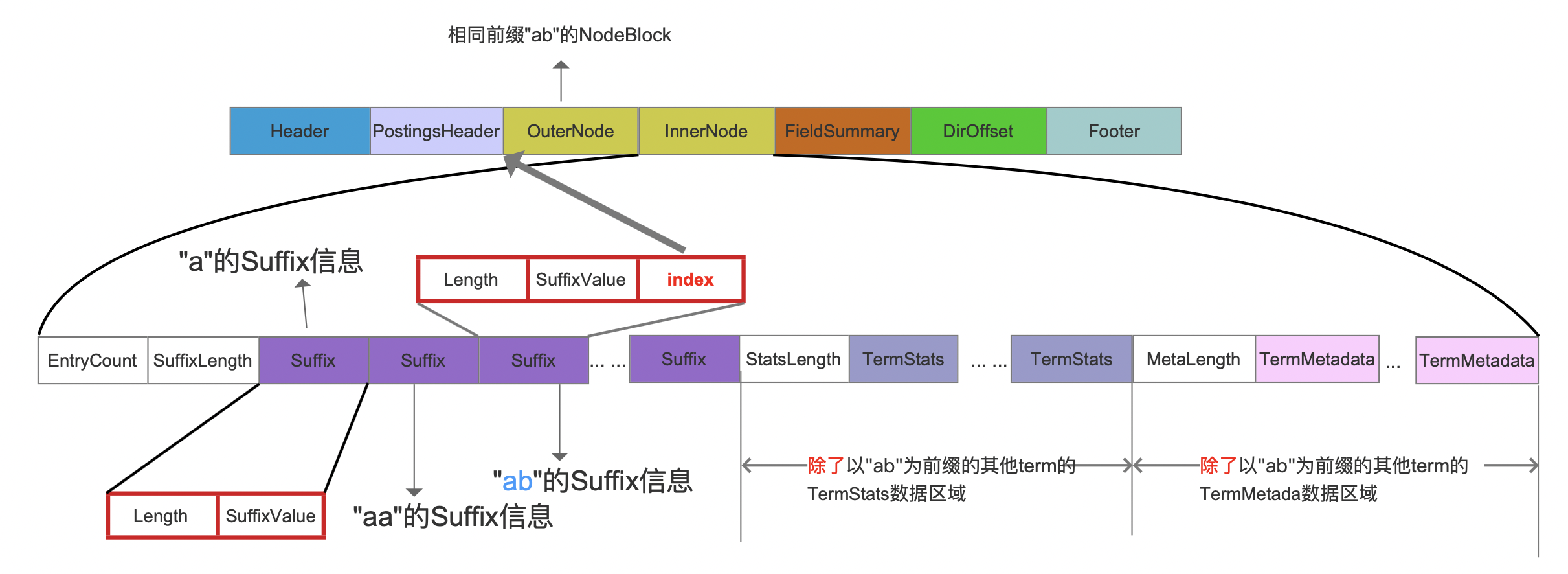
由图 10 中红框标注的信息描述了 PendingTerm 以及 PendingBlock 对应的 Suffix 字段的差异性,对于 PendingBlock,它对应的 Suffix 中多了一个 index 字段,该字段的值就是以"ab"为前缀的 PendingBlock 中的 fp 信息(即图 6 中的 fp 信息),它描述了"ab"为前缀的 PendingBlock 对应的 NodeBlock 信息在索引文件。tim 中的起始位置。
最后根据图 7 中划分后的 block 在分别生成 PendingBlock 之后,将这些 PendingBlock 添加到链表 newBlock 中,newBlock 的定义如下:
|
|
添加到链表 newBlock 中的目的就是为下一个流程 合并PendingBlock 做准备的。
问题二:在搜索阶段,如何通过前缀跟 leading label 快速跳转到对应 floor block
在下一篇文章介绍索引文件。tip 时回答该问题。
所有 PendingBlock 合并到第一个 PendingBlock
图 11:
在上文中,根据图 2 中的 PendingEntry 集合,我们生成了一个或多个 PendingBlock,并且添加到了 newBlock 中,如下所示:
图 12:
在当前流程中,我们需要将 newBlock 中第二个 PendingBlock 开始后面所有的 PendingBlock 的信息合并到第一个 PendingBlock 中,合并的信息包含以下内容:
- floorLeadByte
- fp
- hasTerms
随后将这些信息写入到 FST 中,其中相同前缀值(即图 2 中 PendingEntry 集合的最长相同前缀值)作为 FST 的 inputValue,合并的信息作为 FST 的 outValue。inputValue、outValue 的概念见文章 FST 算法(上),不赘述。
图 12 中,如果 block中至少包含PendingBlock,那么对应 PendingBlock 中的 subIndices 中的信息也需要写入到 FST 中。
合并后的 PendingBlock 添加到 term 栈
图 13:

最后合并的 PendingBlock 添加到 term 栈,等待被嵌套到新的 PendingBlock 中,最终,经过层层的嵌套,一个域中产生的所有的 PendingBlock 都会被嵌套到一个 PendingBlock 中,该 PendingBlock 的 index 信息在后面的流程中将会被写入到索引文件。tip 中。
结语
基于篇幅,剩余的内容将在下一篇文章中展开。
原文地址: [https://www.amazingkoala.com.cn/Lucene/Index/2020/0115
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%BA%90%E7%A0%81%E7%B3%BB%E5%88%97%E7%B4%A2%E5%BC%95%E6%96%87%E4%BB%B6%E7%9A%84%E7%94%9F%E6%88%90%E5%85%AD%E4%B9%8B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


