滴滴出行基于构建企业级消息队列服务的实践
作者: 江海挺
2018-11-20

本文整理自滴滴出行消息队列负责人 江海挺 在 Apache RocketMQ 开发者沙龙北京站的分享。
滴滴出行的消息技术选型
历史
初期,公司内部没有专门的团队维护消息队列服务,所以消息队列使用方式较多,主要以 Kafka 为主,有业务直连的,也有通过独立的服务转发消息的。另外有一些团队也会用 RocketMQ、Redis 的 list,甚至会用比较非主流的 beanstalkkd。导致的结果就是,比较混乱,无法维护,资源使用也很浪费。
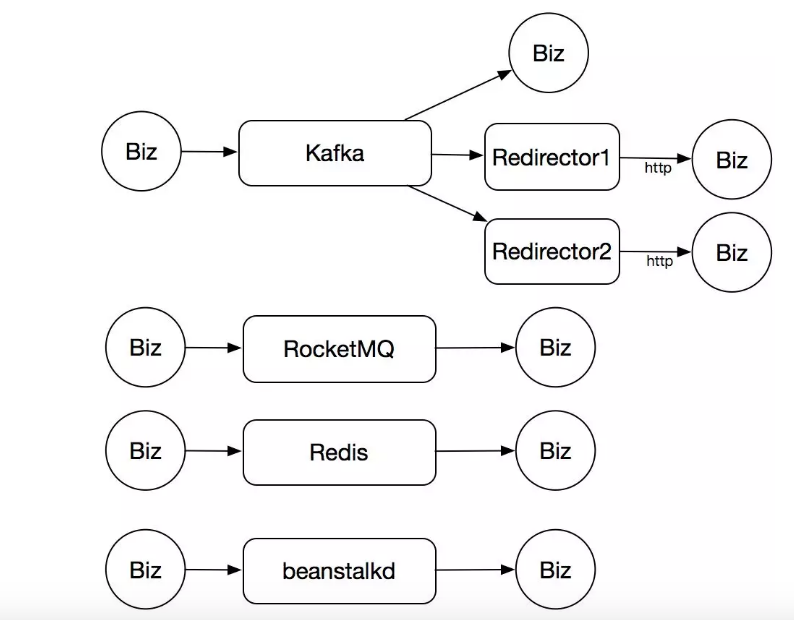
为什么弃用 Kafka
一个核心业务在使用 Kafka 的时候,出现了集群数据写入抖动非常严重的情况,经常会有数据写失败。
主要有两点原因:
-
随着业务增长,Topic 的数据增多,集群负载增大,性能下降;
-
我们用的是 Kafka0.8.2 那个版本,有个 bug,会导致副本重新复制,复制的时候有大量的读,我们存储盘用的是机械盘,导致磁盘 IO 过大,影响写入。
所以我们决定做自己的消息队列服务。
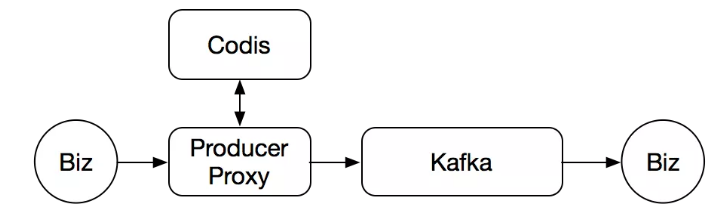
首先需要解决业务方消息生产失败的问题。因为这个 Kafka 用的是发布 / 订阅模式,一个 topic 的订阅方会有很多,涉及到的下游业务也就非常多,没办法一口气直接替换 Kafka,迁移到新的一个消息队列服务上。所以我们当时的方案是加了一层代理,然后利用 codis 作为缓存,解决了 Kafka 不定期写入失败的问题,如上图。当后面的 Kafka 出现不可写入的时候,我们就会先把数据写入到 codis 中,然后延时进行重试,直到写成功为止。
为什么选择 RocketMQ
经过一系列的调研和测试之后,我们决定采用 RocketMQ,具体原因在后面会介绍。
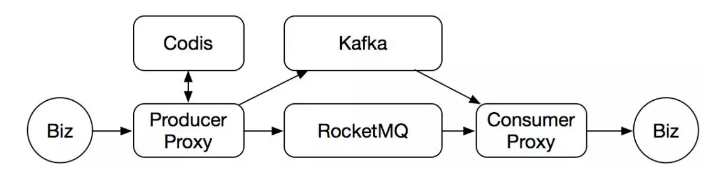
为了支持多语言环境、解决一些迁移和某些业务的特殊需求,我们又在消费侧加上了一个代理服务。然后形成了这么一个核心框架。业务端只跟代理层交互。中间的消息引擎,负责消息的核心存储。在之前的基本框架之后,我们后面就主要围绕三个方向做。
-
迁移,把之前提到的所有五花八门的队列环境,全部迁移到我们上面。这里面的迁移方案后面会跟大家介绍一下。
-
功能迭代和成本性能上的优化。
-
服务化,业务直接通过平台界面来申请资源,申请到之后直接使用。
演进中的架构
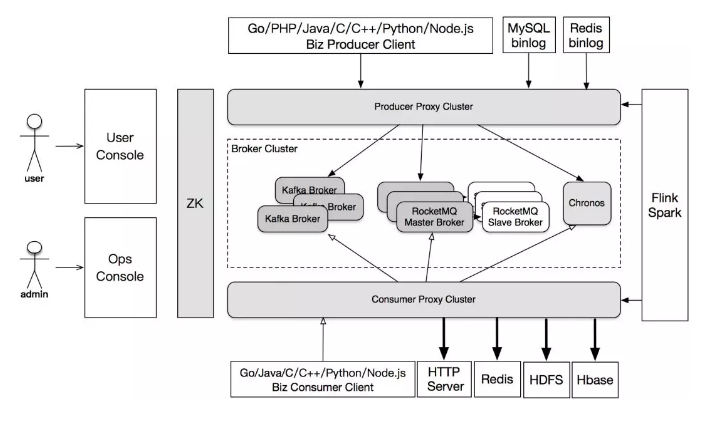
这张图是我们消息队列服务的一个比较新的现状。先纵向看,上面是生产的客户端,包括了 7 种语言。然后是我们的生产代理服务。在中间的是我们的消息存储层。目前主要的消息存储引擎是 RocketMQ。然后还有一些在迁移过程中的 Kafka。另一个是 Chronos,它是我们延迟消息的一个存储引擎。
再下面就是消费代理。消费代理同样提供了多种语言的客户端,还支持多种协议的消息主动推送功能,包括 HTTP 协议 RESTful 方式。结合我们的 groovy 脚本功能,还能实现将消息直接转存到 Redis、Hbase 和 HDFS 上。此外,我们还在陆续接入更多的下游存储。
除了存储系统之外,我们也对接了实时计算平台,例如 Flink,Spark,Storm,左边是我们的用户控制台和运维控制台。这个是我们服务化的重点。用户在需要使用队列的时候,就通过界面申请 Topic,填写各种信息,包括身份信息,消息的峰值流量,消息大小,消息格式等等。然后消费方通过我们的界面,就可以申请消费。
运维控制台,主要负责我们集群的管理,自动化部署,流量调度,状态显示之类的功能。最后所有运维和用户操作会影响线上的配置,都会通过 ZooKeeper 进行同步。
为什么选择 RocketMQ
我们围绕以下两个纬度进行了对比测试,结果显示 RocketMQ 的效果更好。
测试 -topic 数量的支持
测试环境:Kafka 0.8.2,RocketMQ 3.4.6,1.0 Gbps Network,16 threads
测试结果如下:
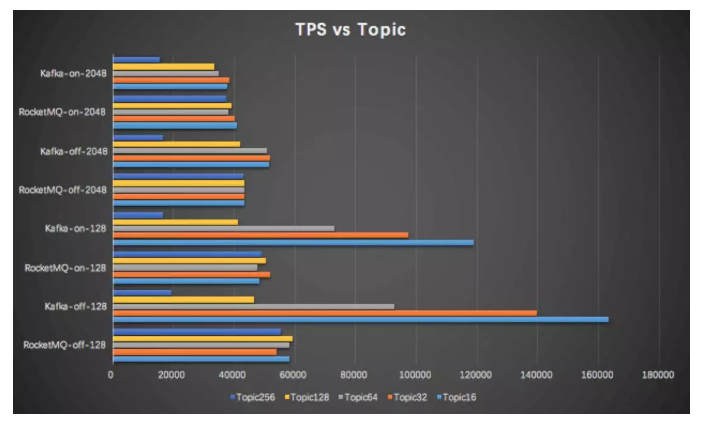
这张图是 Kafka 和 RocketMQ 在不同 topic 数量下的吞吐测试。横坐标是每秒消息数,纵坐标是测试 case。同时覆盖了有无消费,和不同消息体的场景。一共 8 组测试数据,每组数据分别在 Topic 个数为 16、32、64、128、256 时获得的,每个 topic 包括 8 个 Partition。下面四组数据是发送消息大小为 128 字节的情况,上面四种是发送 2k 消息大小的情况。on 表示消息发送的时候,同时进行消息消费,off 表示仅进行消息发送。
先看最上面一组数据,用的是 Kafka,开启消费,每条消息大小为 2048 字节可以看到,随着 Topic 数量增加,到 256 Topic 之后,吞吐极具下降。第二组是是 RocketMQ。可以看到,Topic 增大之后,影响非常小。第三组和第四组,是上面两组关闭了消费的情况。结论基本类似,整体吞吐量会高那么一点点。
下面的四组跟上面的区别是使用了 128 字节的小消息体。可以看到,Kafka 吞吐受 Topic 数量的影响特别明显。对比来看,虽然 topic 比较小的时候,RocketMQ 吞吐较小,但是基本非常稳定,对于我们这种共享集群来说比较友好。
测试 - 延迟
- Kafka
测试环境:Kafka 0.8.2.2,topic=1/8/32,Ack=1/all,replica=3
测试结果:
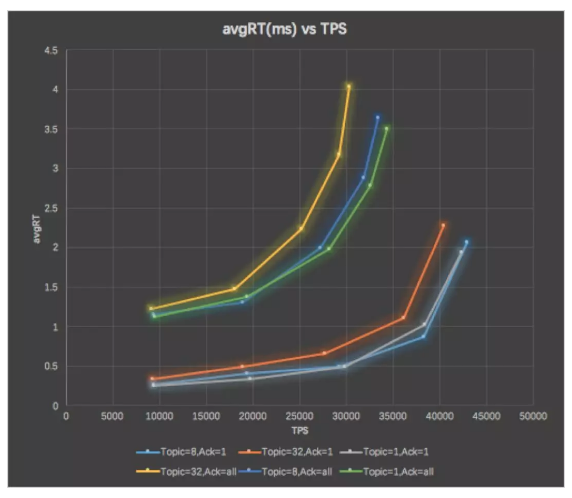
横坐标对应吞吐,纵坐标对应延迟时间
上面的一组的 3 条线对应 Ack=3,需要 3 个备份都确认后才完成数据的写入。下面的一组的 3 条线对应 Ack=1,有 1 个备份收到数据后就可以完成写入。可以看到下面一组只需要主备份确认的写入,延迟明显较低。每组的三条线之间主要是 Topic 数量的区别,Topic 数量增加,延迟也增大了。
- RocketMQ
测试环境:
RocketMQ 3.4.6,brokerRole=ASYNC/SYNC_MASTER, 2 Slave,
flushDiskType=SYNC_FLUSH/ASYNC_FLUSH
测试结果:
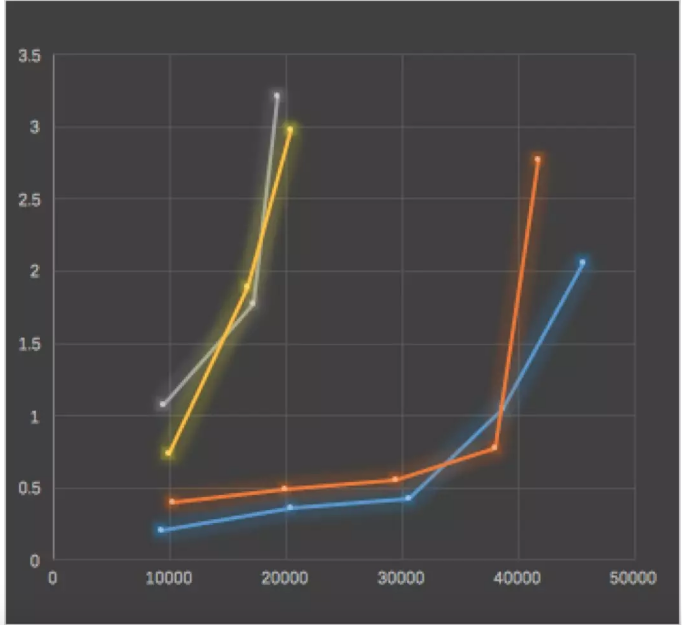
上面两条是同步刷盘的情况,延迟相对比较高。下面的是异步刷盘。橙色的线是同步主从,蓝色的线是异步主从。然后可以看到在副本同步复制的情况下,即橙色的线,4w 的 TPS 之内都不超过 1ms。用这条橙色的线和上面 Kafka 的图中的上面三条线横向比较来看,Kafka 超过 1w TPS 就超过 1ms 了。Kafka 的延迟明显更高。
如何构建自己的消息队列
问题与挑战
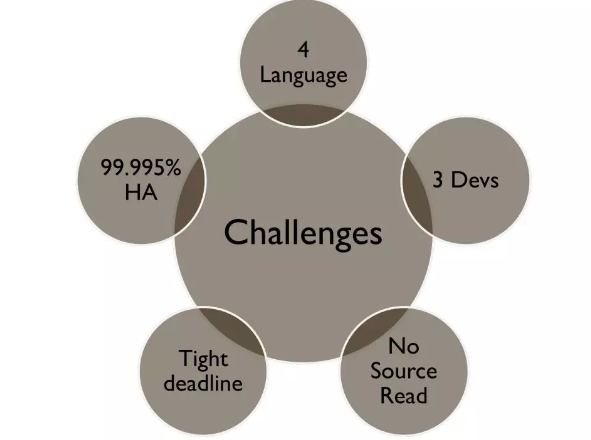
面临的挑战(顺时针看):
-
客户端语言,需要支持 PHP、Go、Java、C++;
-
只有 3 个开发人员;
-
决定用 RocketMQ,但是没看过源码;
-
上线时间紧,线上的 Kafka 还有问题;
-
可用性要求高。
使用 RocketMQ 时的两个问题:
-
客户端语言支持不全,以 Java 为主,而我们还需要支持 PHP、Go、C++;
-
功能特别多,如 tag、property、消费过滤、RETRYtopic、死信队列、延迟消费之类的功能,但这对我们稳定性维护来说,挑战非常大。
针对以上两个问题的解决办法,如下图所示:

-
使用 ThriftRPC 框架来解决跨语言的问题;
-
简化调用接口。可以认为只有两个接口,send 用来生产,pull 用来消费。
主要策略就是坚持 KISS 原则(Keep it simple, stupid),保持简单,先解决最主要的问题,让消息能够流转起来。然后我们把其他主要逻辑都放在了 proxy 这一层来做,比如限流、权限认证、消息过滤、格式转化之类的。这样,我们就能尽可能地简化客户端的实现逻辑,不需要把很多功能用各种语言都写一遍。
迁移方案
架构确定后,接下来是我们的一个迁移过程。
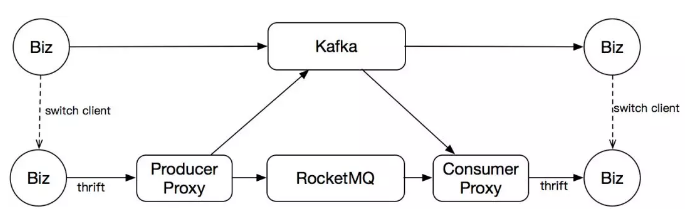
迁移这个事情,在 pub-sub 的消息模型下,会比较复杂。因为下游的数据消费方可能很多,上游的数据没法做到一刀切流量,这就会导致整个迁移的周期特别长。然后我们为了尽可能地减少业务迁移的负担,加快迁移的效率,我们在 Proxy 层提供了双写和双读的功能。
-
双写:ProcucerProxy 同时写 RocketMQ 和 Kafka;
-
双读:ConsumerProxy 同时从 RocketMQ 和 Kafka 消费数据。
有了这两个功能之后,我们就能提供以下两种迁移方案了。
双写
生产端双写,同时往 Kafka 和 RocketMQ 写同样的数据,保证两边在整个迁移过程中都有同样的全量数据。Kafka 和 RocketMQ 有相同的数据,这样下游的业务也就可以开始迁移。如果消费端不关心丢数据,那么可以直接切换,切完直接更新消费进度。如果需要保证消费必达,可以先在 ConsumerProxy 设置消费进度,消费客户端保证没有数据堆积后再去迁移,这样会有一些重复消息,一般客户端会保证消费处理的幂等。
生产端的双写其实也有两种方案:
- 客户端双写,如下图:
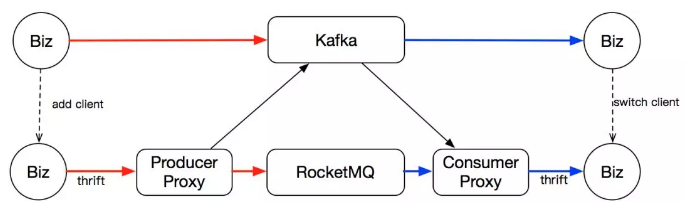
业务那边不停原来的 kafka 客户端。只是加上我们的客户端,往 RocketMQ 里追加写。这种方案在整个迁移完成之后,业务还需要把老的写入停掉。相当于两次上线。
- Producer Proxy 双写,如下图:
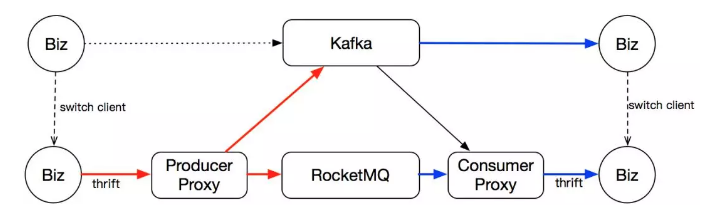
业务方直接切换生产的客户端,只往我们的 proxy 上写数据。然后我们的 proxy 负责把数据复制,同时写到两个存储引擎中。这样在迁移完成之后,我们只需要在 Proxy 上关掉双写功能就可以了。对生产的业务方来说是无感知的,生产方全程只需要改造一次,上一下线就可以了。
所以表面看起来,应该还是第二种方案更加简单。但是,从整体可靠性的角度来看,一般还是认为第一种相对高一点。因为客户端到 Kafka 这一条链路,业务之前都已经跑稳定了。一般不会出问题。但是写我们 Proxy 就不一定了,在接入过程中,是有可能出现一些使用上的问题,导致数据写入失败,这就对业务方测试质量的要求会高一点。然后消费的迁移过程,其实风险是相对比较低的。出问题的时候,可以立即回滚。因为它在老的 Kafka 上消费进度,是一直保留的,而且在迁移过程中,可以认为是全量双消费。
以上就是数据双写的迁移方案,这种方案的特点就是两个存储引擎都有相同的全量数据。
双读
特点:保证不会重复消费。对于 P2P 或者消费下游不太多,或者对重复消费数据比较敏感的场景比较适用。
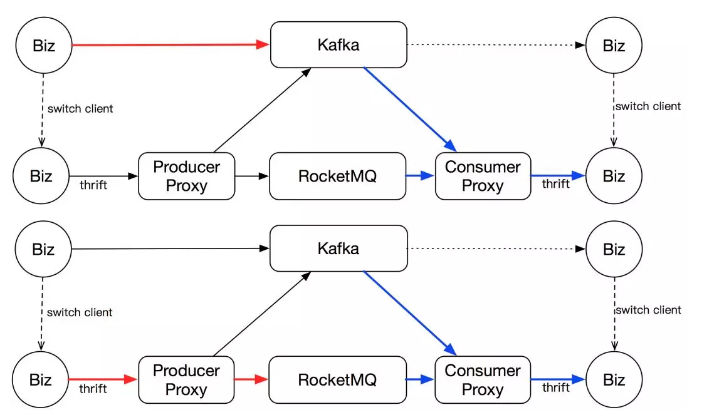
这个方案的过程是这样的,消费先切换。全部迁移到到我们的 Proxy 上消费,Proxy 从 Kafka 上获取。这个时候 RocketMQ 上没有流量。但是我们的消费 Proxy 保证了双消费,一旦 RocketMQ 有流量了,客户端同样也能收到。然后生产方改造客户端,直接切流到 RocketMQ 中,这样就完成了整个流量迁移过程。运行一段时间,比如 Kafka 里的数据都过期之后,就可以把消费 Proxy 上的双消费关了,下掉 Kafka 集群。
整个过程中,生产直接切流,所以数据不会重复存储。然后在消费迁移的过程中,我们消费 Proxy 上的 group 和业务原有的 group 可以用一个名字,这样就能实现迁移过程中自动 rebalance,这样就能实现没有大量重复数据的效果。所以这个方案对重复消费比较敏感的业务会比较适合的。这个方案的整个过程中,消费方和生产方都只需要改造一遍客户端,上一次线就可以完成。
RocketMQ 扩展改造
说完迁移方案,这里再简单介绍一下,我们在自己的 RocketMQ 分支上做的一些比较重要的事情。
首先一个非常重要的一点是主从的自动切换。
熟悉 RocketMQ 的同学应该知道,目前开源版本的 RocketMQ broker 是没有主从自动切换的。如果你的 Master 挂了,那你就写不进去了。然后 slave 只能提供只读的功能。当然如果你的 topic 在多个主节点上都创建了,虽然不会完全写不进去,但是对单分片顺序消费的场景,还是会产生影响。所以呢,我们就自己加了一套主从自动切换的功能。
第二个是批量生产的功能。
RocketMQ4.0 之后的版本是支持批量生产功能的。但是限制了,只能是同一个 ConsumerQueue 的。这个对于我们的 Proxy 服务来说,不太友好,因为我们的 proxy 是有多个不同的 topic 的,所以我们就扩展了一下,让它能够支持不同 Topic、不同 Consume Queue。原理上其实差不多,只是在传输的时候,把 Topic 和 Consumer Queue 的信息都编码进去。
第三个,元信息管理的改造。
目前 RocketMQ 单机能够支持的 Topic 数量,基本在几万这么一个量级,在增加上去之后,元信息的管理就会非常耗时,对整个吞吐的性能影响相对来说就会非常大。然后我们有个场景又需要支持单机百万左右的 Topic 数量,所以我们就改造了一下元信息管理部分,让 RocketMQ 单机能够支撑的 Topic 数量达到了百万。
后面一些就不太重要了,比如集成了我们公司内部的一些监控和部署工具,修了几个 bug,也给提了 PR。最新版都已经 fix 掉了。
RocketMQ 使用经验
接下来,再简单介绍一下,我们在 RocketMQ 在使用和运维上的一些经验。主要是涉及在磁盘 IO 性能不够的时候,一些参数的调整。
读老数据的问题
我们都知道,RocketMQ 的数据是要落盘的,一般只有最新写入的数据才会在 PageCache 中。比如下游消费数据,因为一些原因停了一天之后,又突然起来消费数据。这个时候就需要读磁盘上的数据。然后 RocketMQ 的消息体是全部存储在一个 append only 的 commitlog 中的。如果这个集群中混杂了很多不同 topic 的数据的话,要读的两条消息就很有可能间隔很远。最坏情况就是一次磁盘 IO 读一条消息。这就基本等价于随机读取了。如果磁盘的 IOPS(Input/Output Operations Per Second)扛不住,还会影响数据的写入,这个问题就严重了。
值得庆幸的是,RocketMQ 提供了自动从 Slave 读取老数据的功能。这个功能主要由 slaveReadEnable 这个参数控制。默认是关的(slaveReadEnable = false bydefault)。推荐把它打开,主从都要开。这个参数打开之后,在客户端消费数据时,会判断,当前读取消息的物理偏移量跟最新的位置的差值,是不是超过了内存容量的一个百分比(accessMessageInMemoryMaxRatio= 40 by default)。如果超过了,就会告诉客户端去备机上消费数据。如果采用异步主从,也就是 brokerRole 等于 ASYNC_AMSTER 的时候,你的备机 IO 打爆,其实影响不太大。但是如果你采用同步主从,那还是有影响。所以这个时候,最好挂两个备机。因为 RocketMQ 的主从同步复制,只要一个备机响应了确认写入就可以了,一台 IO 打爆,问题不大。
过期数据删除
RocketMQ 默认数据保留 72 个小时(fileReservedTime=72)。然后它默认在凌晨 4 点开始删过期数据(delete
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%BB%B4%E6%BB%B4%E5%87%BA%E8%A1%8C%E5%9F%BA%E4%BA%8E%E6%9E%84%E5%BB%BA%E4%BC%81%E4%B8%9A%E7%BA%A7%E6%B6%88%E6%81%AF%E9%98%9F%E5%88%97%E6%9C%8D%E5%8A%A1%E7%9A%84%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


