滴滴在性能与可用性上的探索与实践

桔妹导读:HBase作为Hadoop生态中表现较为突出的分布式在线数据存储产品,在滴滴有着非常广泛的应用,但同样存在比较突出的短板问题——例如可用性较弱、毛刺严重等,一定程度上限制了它的业务边界。本文主要介绍在此背景下,HBase团队近期进行的一些探索工作。
1. 背景
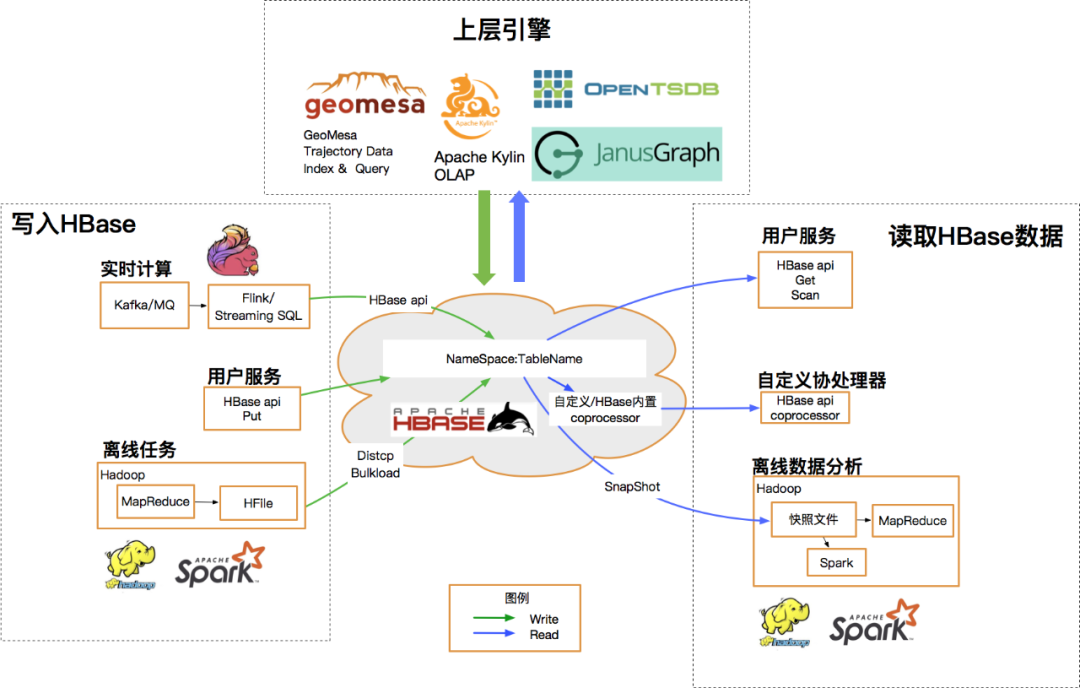
HBase 是一个基于 HDFS 的低成本、分布式LSM结构数据库,可以支持毫秒级别查询;支持海量的PB级的大数据存储,适用于高QPS的随机读写和前缀范围查询等场景。此外,优秀的开源环境使得HBase还可以支持丰富的上下游生态与离线任务。
目前在滴滴内部,HBase基本覆盖了全部业务线,数据量PB规模,吞吐超千万级别;业务包含司乘轨迹、订单、特征工程、推荐引擎、IOT、APM等各种场景,基于HBase的多模生态诸如OLAP(Kylin)、时序(OpenTSDB)、时空(GeoMesa)、图(JanusGraph)亦均有应用。
2020年下半年,HBase团队逐渐将视野投向端上/类端上业务,希望能够承载更加重要的流量。然而对于HBase自身架构和实现而言,主要存在两方面痛点:
▍1.可用性问题
架构层面看,HBase在CAP定理中选择了C,以较弱的可用性为代价换取强一致性,数据层面依赖HDFS保证数据安全,计算层面region无副本。
这样当region迁移、分裂、合并、RS宕机等情况发生时,对应region都会有短时不可用;而作为高吞吐的数据服务,客户端往往都会大量使用线程池,少量region不可用会迅速形成木桶短板,进而放大为整体TPS掉底。
而这种“预期内的”抖动、掉底,是无法满足互联网行业端上场景的可用性要求的。
社区提供的region replica功能一定程度上可以缓解这一问题,但一方面目前这个feature可靠性还不算高,社区仍在推进各种加固和改善,目测稳定的目标release版本可能要放到未发布的3.0了;另一方面端上服务需要双机房,保证容灾和降级,而replica是集群内的region副本,显然也不能支持。
▍2.毛刺问题
HBase主要受Java GC和底层HDFS共用影响,HBase的毛刺相对突出,是进一步提升性能的瓶颈点。
基于以上两个痛点问题,HBase团队近半年进行了一些尝试与探索,主要是基于 replication的客户端多路读功能 与 HBase-ZGC应用实践,预期能够优化HBase的可用性与毛刺问题,简单分享给大家。
2. 基于replication的客户端多路读功
2020年来,为提升HBase可用性,我们大体经历了两个阶段:
1. replication主备
replication是HBase的异步数据同步机制,和Mysql利用Binlog实现主从库类似,HBase利用WAL实现主备集群的数据同步。大致流程为主集群记录写入的WAL,并将数据异步发送给备集群,备集群接收数据并将其转换为put/delete操作,批量写入备集群。提供最终一致性保证。
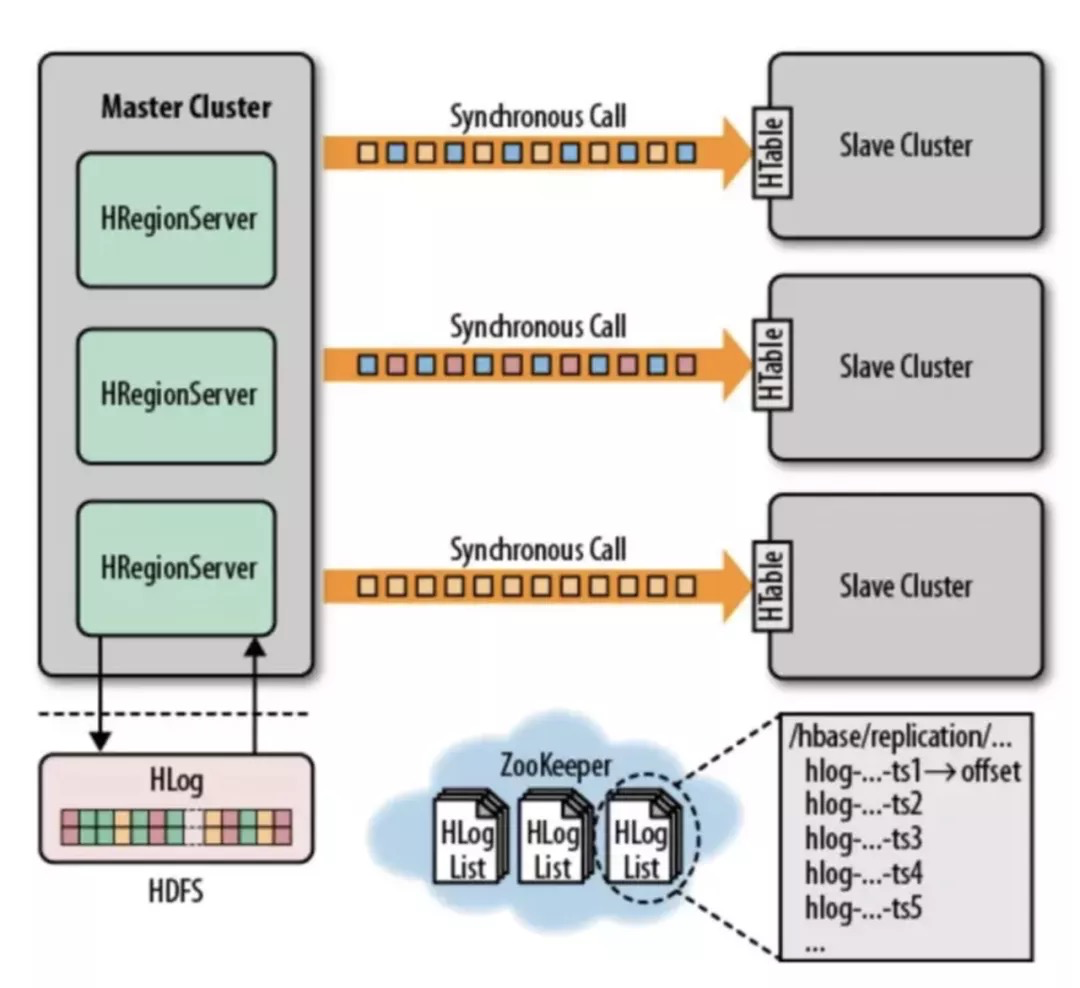
图片来源:HBase官方文档
detailed_information_about_cluster_replication
这一阶段存在的问题:
- 故障时用户有感知,需用户侧切读;
- 备集群利用率较低,资源闲置存在浪费;
2. replication + failover
failover是滴滴HBase团队基于replication自研的增强feature,架构如下图:
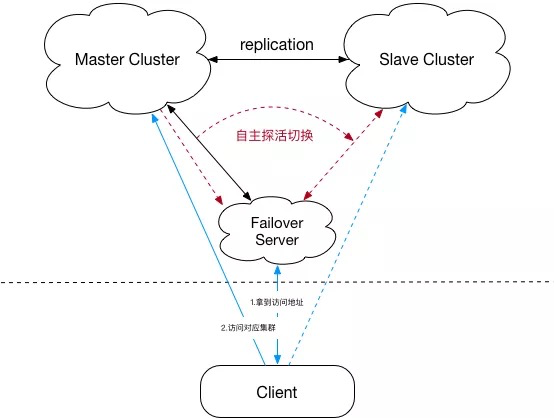
- 相比第一阶段,failover可以基于zk实现服务切换,不需用户操作。但仍然存在用户有感知、备集群无法充分利用的问题;
- 基于以上背景,我们又开发了基于replication的客户端多路读功能,预期解决以下问题:
- 故障时用户无感知;
- 提升备集群利用率;
- 打磨HBase毛刺;
▍1. 设计
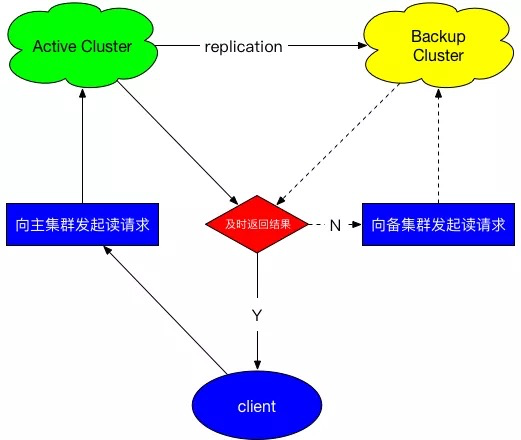
整体设计参考HDFS的hedgedRead功能,客户端首先向主集群发起读请求,一定时间没有返回结果则并发向备集群发起请求,两者取先完成者返回。
实际上HBase的regionReplica也是类似的实现。
▍2.新增配置
paramdefault valuedeschbase.client.hedged.readfalse是否开启多路读hbase.client.hedged.read.timeout50启动备集群读线程的时间阈值hbase.zookeeper.quorum.hedged.read-备集群zk地址
▍3.性能测试
3.1 用例设计
- 两个集群分别创建主备测试表,构建replication
- ycsb打入100w测试数据
- 测试组打开多路读,对照组关闭多路读,各发起10w次scan
- 客户端统计max、P999、P99
3.2 测试结论
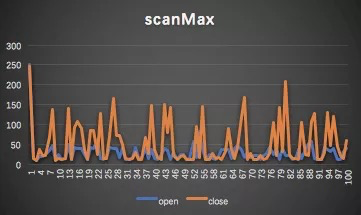
max对比
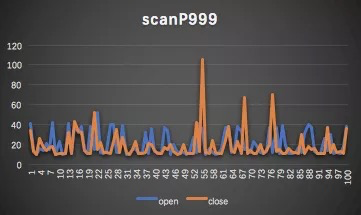
P999对比
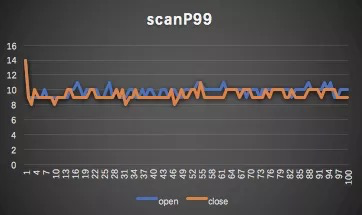
P99对比
多路读对于max和P999有较佳优化效果,可以有效打磨毛刺。
▍4.未尽事项和思考
- 多路读功能基于replication实现,因此只能实现最终一致性,备集群读到的数据有可能和主集群存在差异;
- 目前此功能仅作用于查询,主集群宕机时,最新数据无法同步,因此备集群查询最新数据可能查询不到;
- HBase的scan操作可能分解为多次RPC,由于相关session信息在不同集群间没有同步,数据也不能保证完全一致,因此多路读只在第一次RPC时生效,之后的请求会固定访问第一次RPC时最终使用的集群。
多路读本质上是多活建设,但CAP较难跨越,多活可以提供高可用能力,但强一致性很难得到保障。
但我们可以通过“让用户选择”的方式来解决这一问题:
- 方案一:多活 + 最终一致性
- 方案二:主备 + 强一致性
对于方案一,当前的多路读实现了读链路的多活,写链路仍有优化空间,例如提升replication效率、降低两集群间数据lag等;
对于方案二,可以基于社区的同步replication实现,此外failover的功能仍需我们做更多工作,实现更加智能的自动切换,降低用户感知。
***3. *** HBase-ZGC应用实践
▍1.为什么要更换GC算法?
随着滴滴内部越来越多的端上和类端上业务使用HBase作为存储引擎,用户对HBase读写延迟稳定性的要求也越来越高,HBase的GC毛刺问题尤为突出,G1无法满足性能需求。
好消息是JDK15在9月15号正式发布,划时代的ZGC正式转正,我们决定尝试用ZGC来解决GC毛刺问题。

ZGC(The Z Garbage Collector):ZGC是JDK11之后发布的一款可伸缩的低延迟JVM垃圾收集器。
ZGC官方的设计目标如下:
- Max pause times of a few milliseconds(*)
- Pause times do not increase with the heap or live-set size (*)
- Handle heaps ranging from a 8MB to 16TB in size
ZGC 是一个并发的、单代的、基于区域的、NUMA 感知的压缩收集器,Stop-the-world 阶段仅限于根扫描,因此 GC 暂停时间不会随堆或活动集(live set)的变大而增加。
ZGC 的核心设计原则是将Load barriers与染色对象指针结合使用,这使得 ZGC 能够在 Java 应用程序线程运行时执行并发操作,例如对象重定向。从 Java 线程的角度来看,在 Java 对象中加载引用字段的行为受到加载屏障的影响。除了对象地址之外,colored oops 还包含加载屏障使用的信息,以确定在允许 Java 线程使用指针之前是否需要采取某些操作。********
ZGC相比G1
- 更低延迟:GC停顿时间更短,不超过 10ms
- 更大内存:堆内存支持范围�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%BB%B4%E6%BB%B4%E5%9C%A8%E6%80%A7%E8%83%BD%E4%B8%8E%E5%8F%AF%E7%94%A8%E6%80%A7%E4%B8%8A%E7%9A%84%E6%8E%A2%E7%B4%A2%E4%B8%8E%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


