滴滴技术滴滴语音交互自然语言理解探索与实践

桔妹导读: 滴滴是一个让出行变得更美好的公司,语音交互作为出行领域最安全,最自然的交互方式在滴滴内部有着广泛的应用前景,目前滴滴语音交互已经应用在智能外呼,司机端,地图,车机系统多个领域中。语音交互离不开自然语言理解,用户说的每一句话都应该得到正确的理解和反馈,自然语言理解技术让语音助手变得像人一样和用户进行交流。本文主要讲解滴滴语音交互中自然语言理解技术的一些探索和实践。
1. 模块介绍
语音交互在滴滴有非常丰富的应用场景,因为它可以解放双手,让人们在出行过程中更方便,更安全,实现我们美好出行的愿景。目前语音交互已经应用在滴滴司机端,四轮车,外呼等多个业务中。
滴滴语音交互的整体算法框架如下:
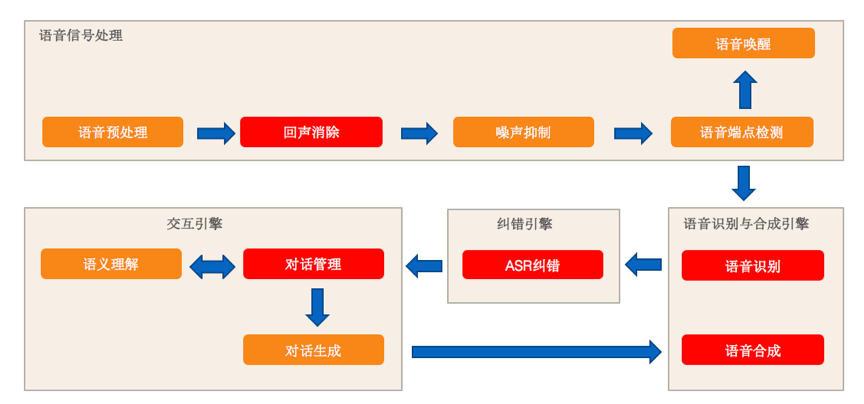
图1 语音交互整体流程
下面着重介绍下交互引擎和纠错引擎中用到的一些算法和算法使用中的一些思考。
2. ASR纠错

▍2.1 概述
2.1.1背景介绍
语音识别结果的纠错是语音理解过程中的一项重要工作。由于受限于语音识别的准确性,语音识别的结果常常会出现错误,这将对语音理解的后续工作造成障碍,增加了语音理解的难度。语音识别结果的纠错可以对一些识别的错误结果进行纠正,从而提高语义理解及后续对话链路的成功率。
2.1.2 研究现状
在ASR纠错任务上,目前学术界主要使用的是端到端模型,输入是原始文本,输出是纠错后的文本。ACL2020的一篇论文[1],通过联合训练基于BiGRU的错误检测网络和基于soft-masked BERT的错误修正网络,预测输入序列每个位置对应的纠正词。另一篇ACL2020的论文[2], 用GCN网络增加了混淆集信息,每个字不仅是它自己融合上下文特征后的embedding,在embedding里也加入了音近、形近字的信息。从上面两篇较新的端到端纠错论文中都有几个共同点,仅使用无任何添加的bert基线模型效果相比其他模型都能独占鳌头,另外再在扩展特定任务上增强数据,性能又能提升一些。但端到端纠错方法同时也存在的问题如下:
- 模型都需要大量高质量的训练数据保障模型效果;
- 无法直接更新纠错词库,需要重新训练模型或增加额外模块。
在ASR纠错任务上由于需要的训练数据不够多样,另外在实际项目中的纠错功能需要及时的更新易错词汇, 在工业应用上大多使用的是传统的纠错框架,主要分为错误检测、候选召回、纠错排序等。多个子模型针对性优化,可以快速高效地在多个项目中落地。友商的纠错系统,有的是基于通用领域的纠错,有的是针对文法、拼写错误场景的纠错,有的是面向任务型对话垂直领域的纠错,而我们的是在特定语音对话场景下基于发音混淆的语音识别纠错。
2.1.3 待解决问题
在确定好在实际项目中使用传统的纠错方式后,我们系统地分析了这套纠错系统存在的难点和痛点:
- 如何高效地检测错误位置和错误纠正?
- 在实际项目中如何实现可复用?
- 如何实现纠错效果的持续性优化?
针对以上等问题,我们希望能够搭建一个高效、可复用、可持续优化的纠错系统。
▍2.2 技术方案
2.2.1 基础方案
我们采用分阶段的纠错架构,来解决任务型语音交互中的识别错误问题。纠错系统主要有三个模块组成,分别是错误检测、候选召回和候选排序。纠错系统的最终输出,可以用于后续链路的解析处理。
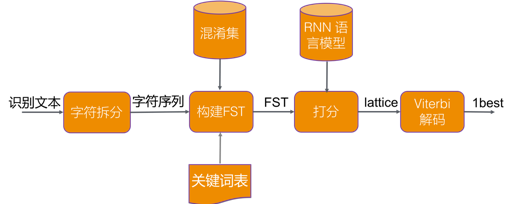
图2 纠错整体框架
2.2.2 错误检测
根据语音识别的评价指标,语音识别项目中的错误分为3种类型,分别是替换错误、删除错误和插入错误,其中替换错误占70~80%左右。这里的错误检测主要针对的是发音相同或相似的替换错误。使用的方法是利用识别的混淆集和关键词构建AC自动机,将待纠句子的音节序列来寻找适配的热词。
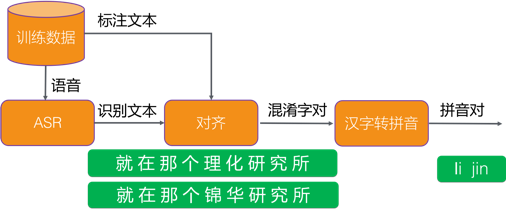
图3 纠错技术方案
**混淆集的构建:**基于识别结果和标注文本进行对齐得到混淆字对,对应的不同音节则视为发音混淆集。当然由于识别结果中删除错误和插入错误的存在,获取的混淆集并非可能性都一致。此处不同发音混淆集的概率由出现的频次来决定,概率和门限值均是经验值。
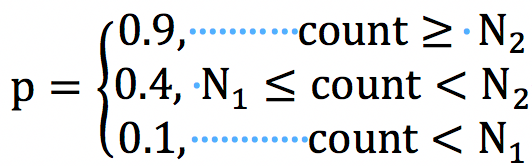
**AC自动机构建错误检测网络:**以关键词表的音节作为模式串,如yu shi ju jin, yu ren wei shan, ju jing hui shen, shan gu作为模式串,以音节为单位,在初步的图网络上再创建fail指针。
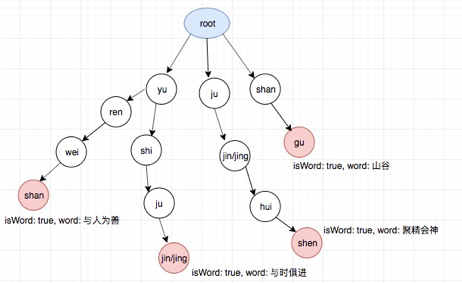
图4 音节图网络
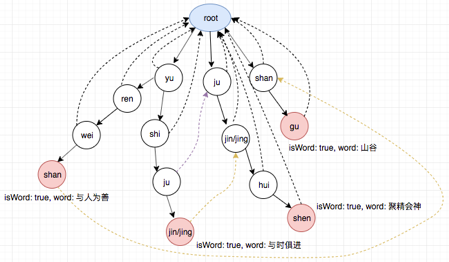
图5 创建FAIL指针
图6 AC自动机错误检测网络
2.2.3 候选召回
在上面的AC自动机错误检测网络中,利用待纠句子的音节序列在网络中进行匹配,匹配到的叶子节点上的word即为召回的候选词。另外增加了基于ngram拼音的回退召回,增加对少数的同音删除错误的召回概率,多个索引词最大长度优先。具体过程如下,建立索引时使用各阶拼音n-gram作为键值:
- 召回时优先查询高阶键值;
- 无法满足数量阈值时回退到低阶键值查询,保证召回数量。
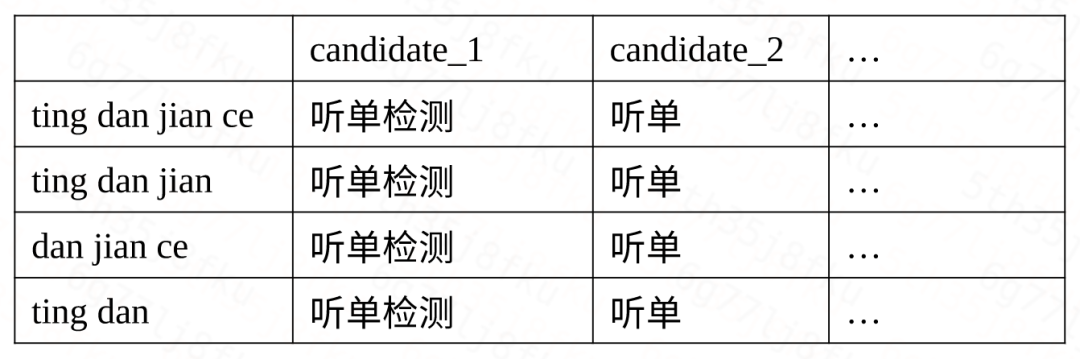
表1 拼音ngram候选
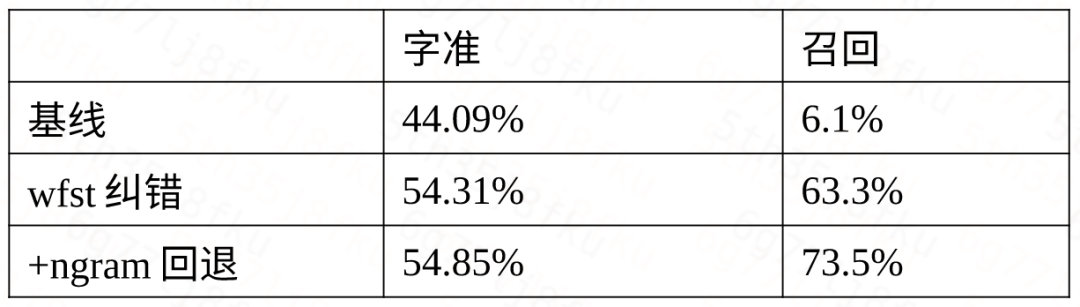
表2 badcase上性能结果
2.2.4 候选排序
RNNLM转换成WFST后,compose到包含错误候选的句子主题上,对FST的候选排序进行打分,维特比解码后最终输出1best的结果。当然对于ngram语言模型也适用,在相同的合适语料上,RNNLM的效果相对较好,ngram模型的优点在于简单高效。在智能客服项目上,此种方式纠错后字准提升2% (90.17%-92.16%)。
图7 结果示例

图8 打分路径示例
▍2.3 应用
纠错系统已经在多个业务上落地,均取得了相对不错的效果。
滴滴司机语音助手可以通过语音交互的方式实现接单、查询天气、规划路线等能力,帮助司机解放双手。在司机语音助手项目中,目前支持的设置温度、查询天气等意图中的实体部分容易识别错,我们支持了这些实体词的纠错能力,在语音识别字准优化上,提升了绝对1%的字准确率,交互成功率平均提升7.24%。
▍2.4 未来展望
ASR纠错在语音对话场景中的重要性不言而喻,虽然上面的纠错系统在实际项目中取得一定收益,但我们的纠错系统还有有待优化的空间,如:
- 结合更多类型的识别结果(如lattice等)来进行检错和纠错;
- 引入更多的信息对错误候选进行排序,可以是声音信息、用户的个性化特征或项目的特定状态信息等;
- 结合端到端方法来改善纠错性能,BERT预训练方法或者是利用seq2seq模型以机器翻译的方式来纠错;
*3. 意图分类
▍3.1 概述
在此说的意图分类是广义上的意图分类,目前主要有两种做法,这两种做法都有其相应的优点和缺点。
(1) 使用端到端的分类模型,像FastText[3], TextCNN[4], Bert-Classifier[5]等直接输出类别label和其对应的置信度,此方法多用于任务型意图理解。
- 优点:
- 直接模型端到端输出结果,不需要中间环节,infer速度相对较快;
- 方差小,模型的拟合和泛化能力相对较强;
- 可以使用联合模型和NER任务一起完成。
- 缺点:
- 需要比较多的数据训练才会有较好的效果;
- 如果要删减数据或者意图需要重新训练模型,实时性差。
(2) 使用检索的方法去识别意图,通过计算query与候选doc的相似度做召回,排序,最后得到相应的意图,此方法多用于问答型意图理解。在此用到的算法有BM25, DSSM[6], Siamese-LSTM[7], Sentence-BERT[8]等。
- 优点:
- 在数据更新时可以做到即时生效;
- 在召回和排序的模型选择上比较灵活,可以适应各种场景;
- 对数据数量的要求较低。
- 缺点:
- 如果候选doc的数量过多,infer速度会变慢;
- 对数据质量有较高的要求。
▍3.2 技术方案
分类算法作为nlp领域中最常见的任务之一,在很多情况下我们都会用到,但是在选择算法模型的时候不能只考虑模型的准召,还需要考虑模型的训练速度,推理速度,是否可以支持数据的热更新等因素,然后根据当前业务的实际情况去选择模型。滴滴目前语音交互的业务场景较多,每个业务我们会根据其业务场景选择相应的算法。
3.2.1 文本分类算法
在比较稳定的任务型场景中我们是使用的端到端文本分类模型。
在粗粒度的领域分类中,我们使用了TextCNN的方法,TextCNN可以在效率和精度之间达到一个比较好的平衡,我们在其中对TextCNN模型做了一些优化:
- 把entity整体作为一个token输入,增强模型对于特定领域的识别性能;
- 因为是通过ASR模型取得的query,可能会有个别字识别错误,所以加入拼音的embedding,提高模型对ASR数据识别的准确率;
- 同时使用预训练好字向量和随机初始化的字向量,解决OOV问题,增强模型的泛化能力;
- 使用k-max-pooling代替max-pooling,可以获取更多的局部信息。
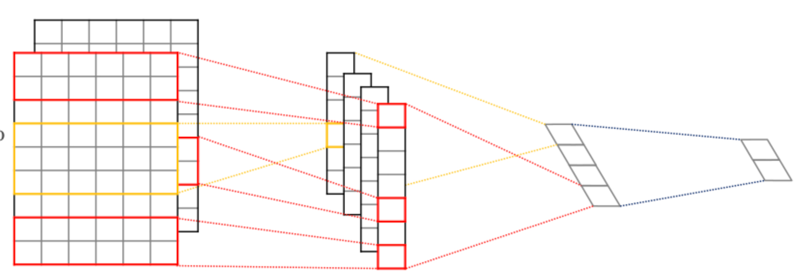
图9 TEXTCNN网络
在细粒度的意图分类中,我们使用了bert-classifier模型,我们用来fine-tune的bert base版本做了相应领域的adaptation训练(word mask+ sentence prediction),因为用来做adaptation的领域数据噪声较大,所以在训练的时候固定前9层取得最好的效果。
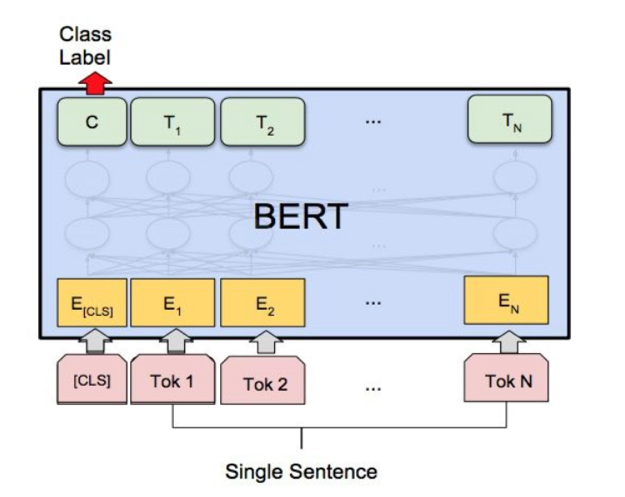
图10 BERT-CLA网络
3.2.2 文本匹配算法
在外呼和问答场景下我们采用的是检索式意图分类方案,其主要分为两步,召回和排序。
从特征提取的方法来说相似度计算方法分为基于表征信息统计的相似度计算和基于深度语义向量表示的相似度计算。
基于表征信息统计的相似度计算主要是根据query和doc的字面匹配度来计算其相关性,如编辑距离、TFIDF、BM25等,这是我们的召回策略之一。这种方案有他的优点,比如计算量小,速度快。也有他的局限性:(1)缺少语义的理解能力,无法处理同义词的匹配,比如“建议”和“意见”就无法匹配。(2)忽略了字词之间相对顺序对语义的影响。
基于深度语义向量表示的相似度计算又分为基于表示的匹配方法(Representation-based)和基于交互的匹配方法(Interaction-based):
- 基于表示的匹配方法最大的优势在于doc的语义表示向量可以离线计算,在做相似度排序的时候只需要重新计算query的语义表示向量,然后可以直接进行排序;它的缺点是在进行相似度计算的时候query和doc两者没有细粒度的交互,所以会有精确度的损失。这种方法我们主要用来做召回策略。
- 基于交互的匹配方法优势在于query和doc在模型训练时能够进行充分的交互匹配,语义匹配效果好;缺点是query和每个doc的相似度都要做实时计算来得到他们的相似度,需要消耗大量的计算时间。这种方法只适用于召回之后的精排策略中。
在我们召回策略中的Representation-based方法中又分为有监督和无监督两种方法,无监督的方法是直接通过预训练好的词向量做pooling或者是预训练好的语言模型直接输出来得到句向量表示,这种方法的无需额外的数据进行fine-tune训练,成本较低,适用性较强。有监督的方法是将query和doc作为模型的输入,使用siamese性质的网络结构,把他们的相似度打分作为输出来训练一个模型,然后将末端某一层特征向量作为句向量表示。
下面来介绍一下我们在深度语义向量表示的实践中用到的方法。
对于Representation-based中的无监督方法,我们是使用我们的BERT Adaptation模型,然后在他的输出结果上增加了一个pooling操作,从而生成一个固定大小的句子embedding向量可以作为这句话的语义表示。一共有三种pooling的方法,CLS,Mean,Max。
- CLS-pooling是直接把bert头部CLS位置的向量作为句向量;
- Mean-pooling是把某一层或者某几层的所有token输出向量的平均值作为句向量;
- Max-pooling是把某一层或者某几层的所有token输出向量的最大值作为句向量。
在我们的任务中,我们做了一些实验,发现对BERT第一层的token做mean-pooling得到的句向量表示效果最好。
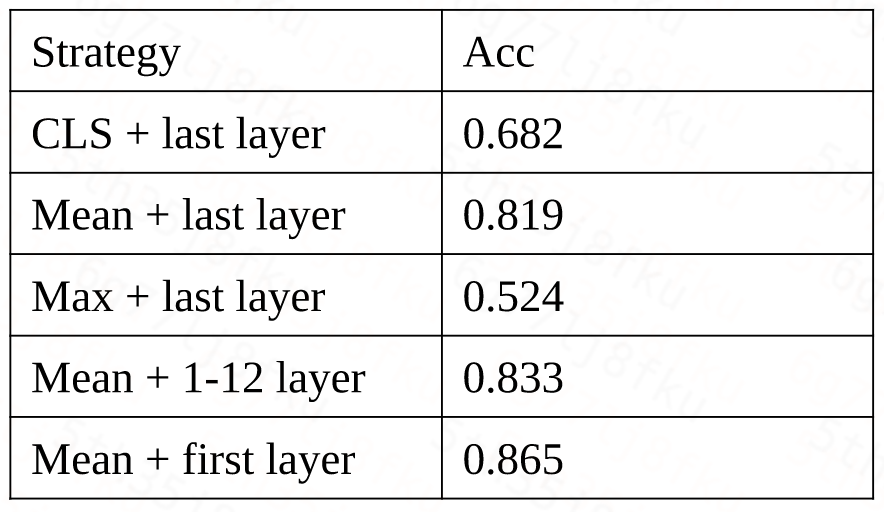
可以看到Mean-pooling的效果远好于CLS-pooling和Max-pooling,使用第一层的特征优于使用其他层的。
有监督的方法是使用的基于Regression Objective Function的Siamese-BERT网络。两个句向量u和v的相似度计算结构如下:
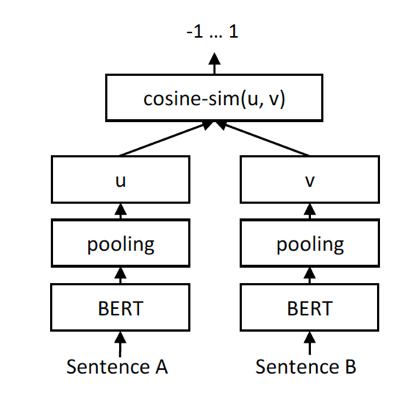
图11 REGRESSION OBJECTIVE FUNCTION
此方法使用MSE(mean squared error)作为损失函数。
在离线计算时将doc从Sentence A位置输入,得到u为此doc的句向量,然后缓存在索引中。当输入一个query时,只有计算query的句向量才用到在线计算,此方法需要很小的在线计算量,可以作为召回策略。
对于基于交互的匹配方法,我们是使用Siamese-BERT中的Classification Objective Function,在这种方法中会将u和v拼接在一起组成一个新的向量去做分类,他们的相似度计算结构如下:
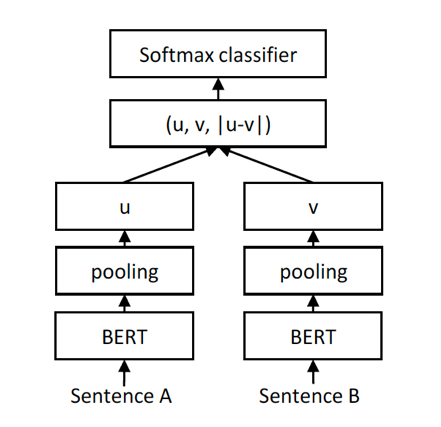
图12 REGRESSION OBJECTIVE FUNCTION
在这个地方我们的实验结果和论文中一样,把u,v以及它们的差拼接在一起,然后乘以权重参数Wt最终得到的效果最好。此方法使用交叉熵作为损失函数。
使用这种方法必须是在线计算才能得到候选doc和query相似度,doc从Sentence A输入,query从Sentence B输入,输出结果直接得到它们的相似度。此种方法需要的在线计算量较大,只能作为精排的策略之一。
4. 命名实体识别
命名实体识别(NER)是一种序列标注任务,近些年NER主流模型的演变是从CRF->RNN-CRF->BERT-CRF,顶会中NER任务相关的文章主要集中在NER多任务的联合模型中,单纯NER任务只是加入了一些tricks比如引入多种特征,但是这些相较主流模型提升不大,目前我们对于单NER任务主要采用Bi-GRU-CRF[9]和BERT-CRF[10]模型。
- Bi-GRU-CRF 模型
Bi-GRU 即 Bi-directional GRU,也就是有两个 GRU cell,一个得到前向表征向量 l,一个得到反向表征向量 r,然后两层向量加一起得到最终向量。
如果不使用CRF的话,这里就可以直接接一层全连接层过softmax得到输出结果了;如果用CRF的话,CRF 层以 Bi-GRU 层的输出为输入,其可以通过学习数据集中不同 label 间的转移概率从而修正 Bi-GRU层的输出,这时损失函数由预测结果的softmax和CRF中的转移概率共同决定,这样可以在条件随机场里面考虑预测结果之间的合理性(比如说B-city后面不可能跟着I-music,更有可能是I-city)。
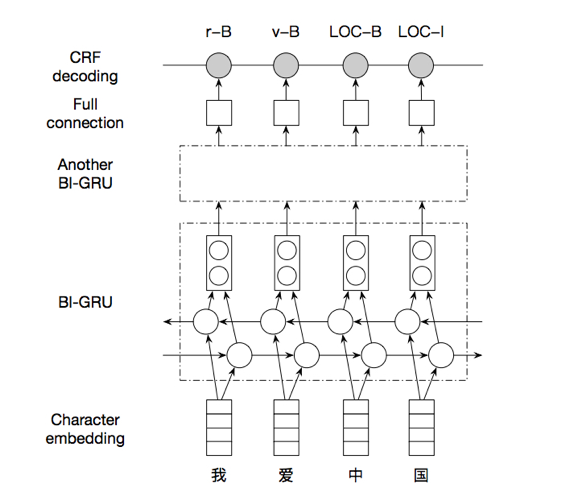
图13 BI-GRU-CRF
这里说一下用于表示序列标注结果的 BIO 标记法。序列标注里标记法有很多,主流的是 BIO 与 BIOES 这两种。B 就是标记某个实体词的开始,I 表示某个实体词的中间,E 表示某个实体词的结束,S 表示这个实体词仅包含当前这一个字。因为交互相关的业务中有很多实体变量,BIOES方法会引入过多的label类型,所以我们使用的是BIO标记法。
- BERT-CRF模型
在某些业务中我们使用的是BERT-CRF模型,BERT-CRF的结构和Bi-GRU-CRF类似,只不过把Bi-GRU换成了BERT,其实在实验中相比较单纯使用 BERT,增加了 CRF 后效果有所提高但区别不大,F1值大概提升了0.8%,这是因为BERT庞大的网络结构已经基本学习到了CRF结构中所包含的转移矩阵信息,如果条件不允许的话也可以直接使用BERT模型在最后一层输出实体label。由于BERT语言模型的特性,相对于Bi-GRU-CRF模型,BERT-CRF有它的优点和缺点。
优点:
- 由于预训练语言模型已经在高维空间学习到了大量的语言信息,所以在做NER任务的fine-tune时需要少量的语料就可以得到很好的效果。
- 效果很好,F1值可以由84%提升到92%。
缺点:
- 最大的缺点是慢,训练慢,infer慢,消耗的机器资源多。
5. 总结
nlp算法在滴滴语音交互场景下有着非常广阔的应用场景,由于篇幅限制我们还有很多算法模块没办法和大家一一介绍,比如对话管理,分词,指代消解,数据增强,聚类算法等。
另外在这里介绍一下我们开发的delta平台项目( https://github.com/didi/delta),它是滴滴第一个开源的AI项目,它可以实现语音语义算法训练、测试、上线一体化,帮助我们快速完成算法的从实现到部署的整个pipeline,提升生产效率。
参考文献:
[1] Zhang, S., Huang, H., Liu, J., & Li, H. (2020). Spelling Error Correction with Soft-Masked BERT. arXiv preprint arXiv:2005.07421
[2] Cheng, X., Xu, W., Chen, K., Jiang, S., Wang, F., Wang, T., … & Qi, Y. (2020). SpellGCN: Incorporating Phonological and Visual Similarities into Language Models for Chinese Spelling Check. arXiv preprint arXiv:2004.14166.
[3] Joulin, A., Grave, E., Bojanowski, P., & Mikolov, T. (2017). Bag of Tricks for Efficient Text Classification. ArXiv, abs/1607.01759.
[4] Y. Kim. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, EMNLP 2014, October 25-29, 2014, Doha, Qatar, A meeting of SIGDAT, a Special Interest Group of the ACL, page 1746–1751. (2014)
[5] Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In J. Burstein, C. Doran & T. Solorio (eds.), NAACL-HLT (1) (p./pp. 4171-4186), : Association for Computational Linguistics. ISBN: 978-1-950737-13-0
[6] Huang, P.-S., He, X., Gao, J., Deng, L., Acero, A. & Heck, L. P. (2013). Learning deep structured semantic models for web search using clickthrough data.. In Q. He, A. Iyengar, W. Nejdl, J. Pei & R. Rastogi (eds.), CIKM (p./pp. 2333-2338), : ACM. ISBN: 978-1-4503-2263-8
[7] Mueller, J. & Thyagarajan, A. (2016). Siamese Recurrent Architectures for Learning Sentence Similarity.. In D. Schuurmans & M. P. Wellman (eds.), AAAI (p./pp. 2786-2792),: AAAI Press.
[8] Reimers, N., & Gurevych, I.
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%BB%B4%E6%BB%B4%E6%8A%80%E6%9C%AF%E6%BB%B4%E6%BB%B4%E8%AF%AD%E9%9F%B3%E4%BA%A4%E4%BA%92%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E7%90%86%E8%A7%A3%E6%8E%A2%E7%B4%A2%E4%B8%8E%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


