滴滴数据驱动利器之实践

桔妹导读:在各大互联网公司都提倡数据驱动的今天,AB 实验是我们进行决策分析的一个重要利器。一次实验过程会包含多个环节,今天主要给大家分享滴滴实验平台在分组环节推出的一种提升分组均匀性的新方法。本文首先会介绍一下滴滴 AB 实验的相关情况,以及在实验分组环节中遇到的问题。然后介绍目前在实验对象分组方面的通用做法,以及我们对分组环节的改进。最后是新方法的效果介绍。
一 AB 实验概述

互联网公司中,当用户规模达到一定的量级之后,数据驱动能够帮助公司更好的决策和发展。在滴滴各个团队中,我们经常会面临不同的产品设计方案的选择或者多个算法方案的决策,比如顶部导航栏的排序方案一二三,派单算法一二三等等。传统的解决方法通常是由该领域经验丰富的专家来决定,或者由团队成员讨论决定,有时候甚至是随机选择一个方案上线。虽然在某些情况下传统解决办法也是有效的,但是让 AB 实验后的数据说话,会让方案选择更加有信服力。
滴滴 Apollo AB 实验平台,支持了滴滴诸多业务的功能优化、策略优化以及运营活动,提供了在线实验以及离线实验的能力,并行实验数达到 6000+ / 周。在分组方法上提供随机分组以及时间片分组来应对不同的实验场景。效果分析方面,我们对基础指标、率指标、均值指标、留存指标等多种类型的指标提供了均值检验、VCM、Bootstrap 等多种分析手段。
二 分组的问题

一次完整的 AB 实验可以分为以下几步:

第一步:
设计实验方案,包括确定实验对象,划分实验组,确定实验提升目标等。
第二步:
进行人群分组,一般是一个空白组加一个或多个实验组
第三步:
将需要实验的策略,方案或者功能施加到各个组,收集数据
第四步:
对实验关心的指标进行分析观察
本文主要讨论其中第二步的实现。业界在进行实验对象分组的时候,最常用的是随机分组方式。这也是滴滴诸多实验中占比最大的分组方式。随机分组的做法可以实现为对实验对象的某个 ID 字段进行哈希后对 100 取模,根据结果值进入不同的桶,多个不同的组分别占有一定比例的桶。实验对象在哈希取模之后,会得到 0 ~ 99 的一个数,即为该实验对象落入的桶。这个桶所属的组就是该实验对象的组。

上述的这种分组方式称为 CR(Complete Randomization)完全随机分组。进行一次 CR,能将一批实验对象分成对应比例的组。但是由于完全随机的不确定性,分完组后,各个组的实验对象在某些指标特性上可能天然就分布不均。均值,标准差等差异较大。如果分组不均,则将会影响到第四步的实验效果分析的进行,可能遮盖或者夸大实验的效果。
待分流的个体具备一定的内在特点,比如就 GMV 这个指标来说,人群中会存在高 GMV,中等 GMV,低 GMV 等不同层次的用户。如下图所示,对于实验人群进行完全随机分流的方式,存在一定概率的不均匀,比如高 GMV 人群在某个组中的分配比例偏高,导致两个组的 GMV 相对差异较大。比如一次实验中,希望提升北京市的 GMV 1%,在进行分组之后,实验组的人群 GMV 天然就比对照组的人群 GMV 高 2%。这样实验进行的结果就变的无法比较。如果没有注意到实验前的组间不均情况,甚至可能验证出错误的结论。
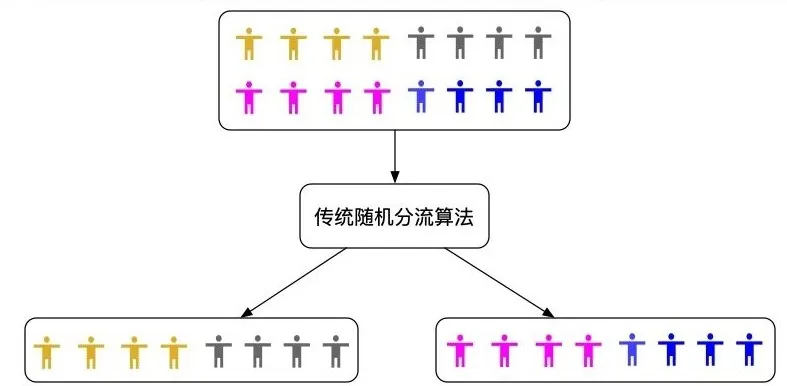
随机分流人群分组不均示意图
基于 CR 的风险较大的情况,一般会对 CR 进行简单的一步优化,即进行 RR(Rerandomization)。RR 是在每次跑 CR 之后,验证 CR 的分组结果组间的差异是否小于实验设定的阈值。当各组的观察指标小于阈值或者重新分组次数大于最大允许分组次数后,停止分组。
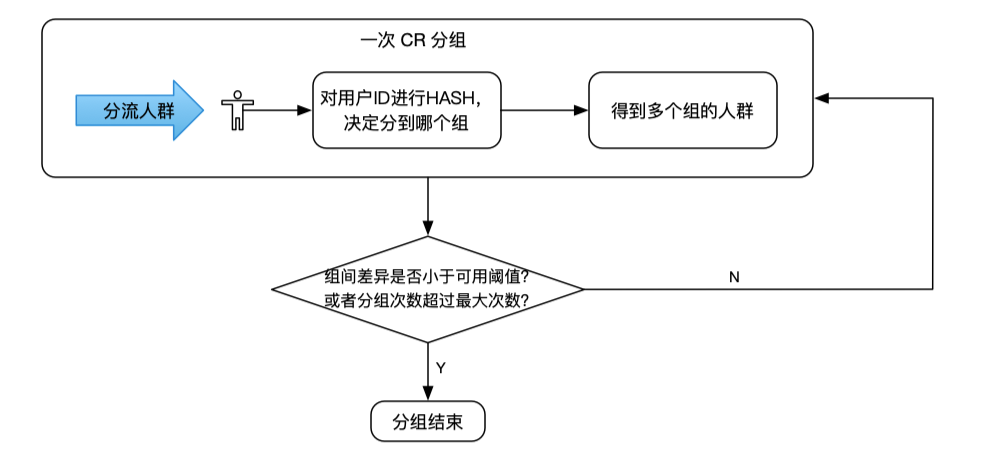
相比于 CR,RR 通过牺牲计算时间,能在一定概率上得到符合要求的分组。重分组次数与输入的实验对象样本大小相关。样本量越大,需要进行重分的次数一般较少。但是 RR 分组能得到符合要求的分组有一定的概率,且需要花更多的时间。所以,我们希望通过对分组算法的改进,在一次分组过程中分出观察指标均匀的分组结果,如下图所示。
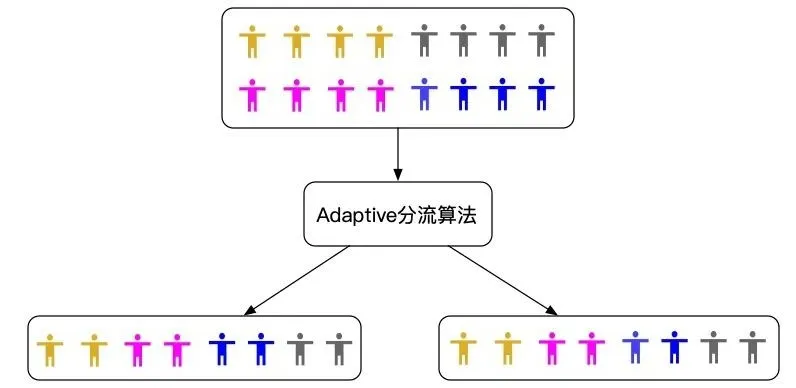
分流人群分组均匀示意图
三 自适应分组

Apollo 实验平台实现了滴滴 AI LAB 团队设计的 Adaptive(自适应)分组算法。Adaptive 分组方法可以在只分组一次的情况下,让选定的观测指标在分组后每组分布基本一致,可以极大的缩小相对误差。相比于传统的 CR 分组,Adaptive 分组的算法更加复杂,在遍历人群进行分组的同时,每个组都需要记录目前为止已经分配的样本数,以及已经分配的样本在选定的观测指标上的分布情况。从分流人群中拿到下一个要分的对象后。会对实验的各个组进行计算,计算该对象如果分配到本组。本组的观测指标分布得分情况。然后综合各个组的预分配得分情况,得到最终各个组对于该实验对象的分配概率。
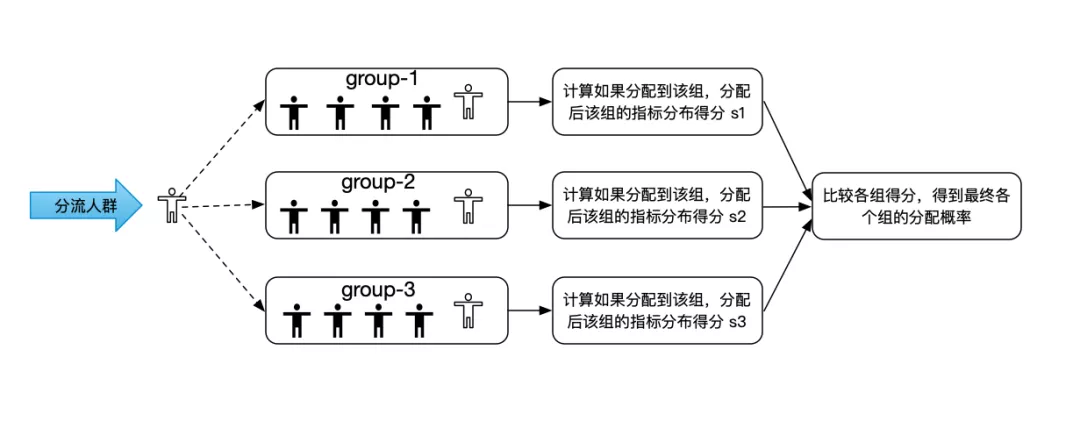
Adaptive 分组流程
四 系统设计

系统交互流程如下:
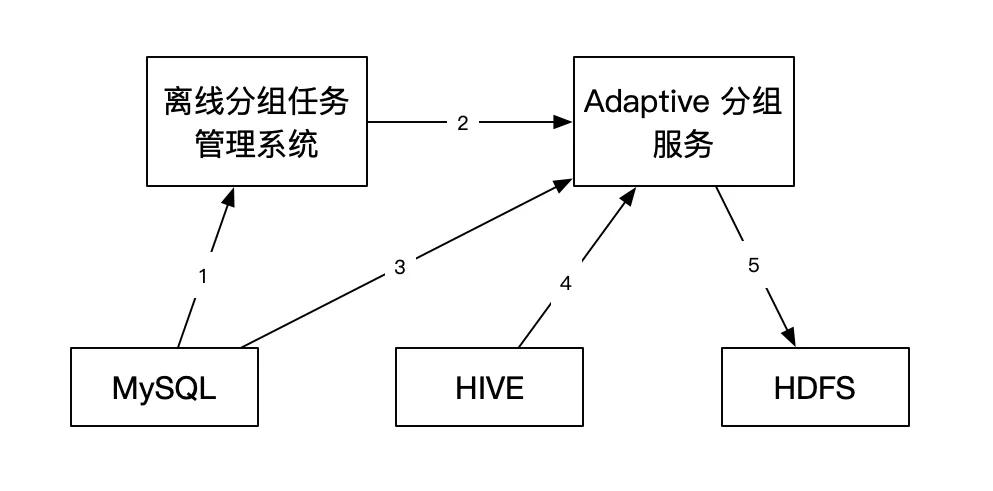
Adaptive 分组方案的设计与实现复用了 Apollo AB 实验已有离线分组架构的能力。用户在实验平台通过 API 接口或者页面创建完 Adaptive 实验之后,实验平台会将分组需求发送到分组任务管理系统,生成分组任务存入数据库中。Adaptive 分组执行分为以下几个步骤:
首先分组任务管理系统从数据库中获取需要进行分组的任务。然后根据任务类型调用不同的分组服务。Adaptive 分组服务从数据库中获取实验对应的计算信息。根据实验计算信息中的观察指标,从 HIVE 中获取指标数据,根据人群信息的地址获取人群数据。执行完分组算法之后,将分组结果写入 HDFS。
五 算法介绍

▍样本打乱&随机分配
将人群 shuffle 打乱之后,对于人群的前 2 * K(K 是组数)的人进行随机分组,保证每个组中至少有两个样本之后再开始进行 Adaptive 分组。
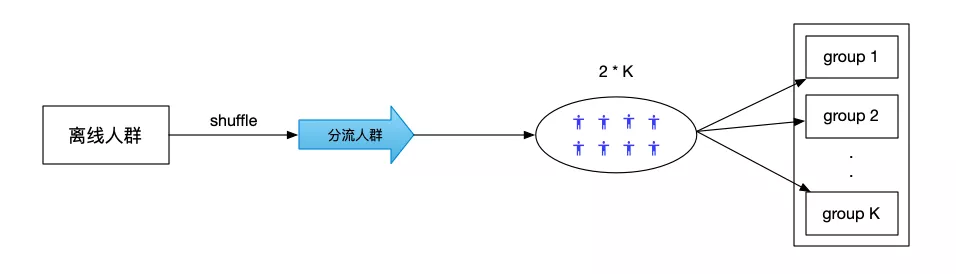
▍组参数初始化
根据实验的组以及每个组的人群比例计算出各个组的直接分配概率和间接分配概率。每个组上的直接分配概率和间接分配概率,分别表示了在直接分配以及间接分配情况下,选中该组后,样本分配到各个组的概率。根据已经分配的样本数据,初始化观测指标分布情况。
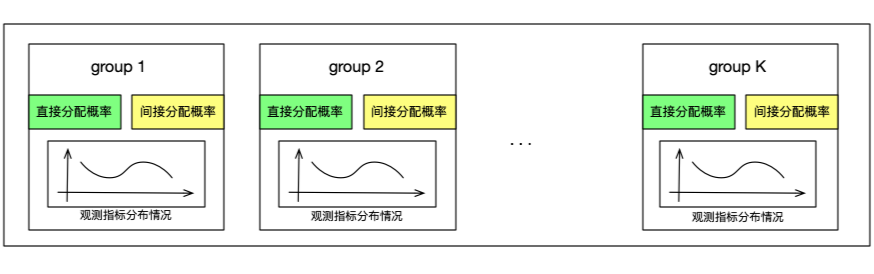
▍判断直接或间接分配
计算各组已分配样本数和组所占比例之间的关系,得到各个组的平衡系数 BS,如果各个组的比例平衡�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%BB%B4%E6%BB%B4%E6%95%B0%E6%8D%AE%E9%A9%B1%E5%8A%A8%E5%88%A9%E5%99%A8%E4%B9%8B%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


