爱奇艺搜索排序算法实践
7月3日下午,爱奇艺技术产品团队举办了“ i技术会”线下技术沙龙,本次技术会的主题是“ NLP与搜索”。我们邀请到了来自字节跳动、去哪儿和腾讯的技术专家,与爱奇艺技术产品团队共同分享与探讨NLP与搜索结合的魔力。
其中,来自爱奇艺的技术专家张志钢为大家带来了 爱奇艺搜索排序算法实践 的分享。
以下为“爱奇艺搜索排序算法实践”干货分享,根据【i技术会】现场演讲整理而成。
01 背景介绍
1.爱奇艺搜索场景
爱奇艺的搜索场景主要有以下 三个特点:
(1) 多产品线,如爱奇艺主端、随刻、极速版、TV等;
(2) 多业务形态,包括综合搜索及各垂类业务;
(3) 多数据类型,包括专辑、短视频、爱奇艺号等。
我们以下图这个具体的搜索场景为例,首先,我们在搜索框输入对应的Query,点击搜索按钮,跳转到最终的结果页。
结果页的情况如图所示:第一个是专辑长视频,下面是三个短视频,接着是相关小说, 数据类型是比较多样的。
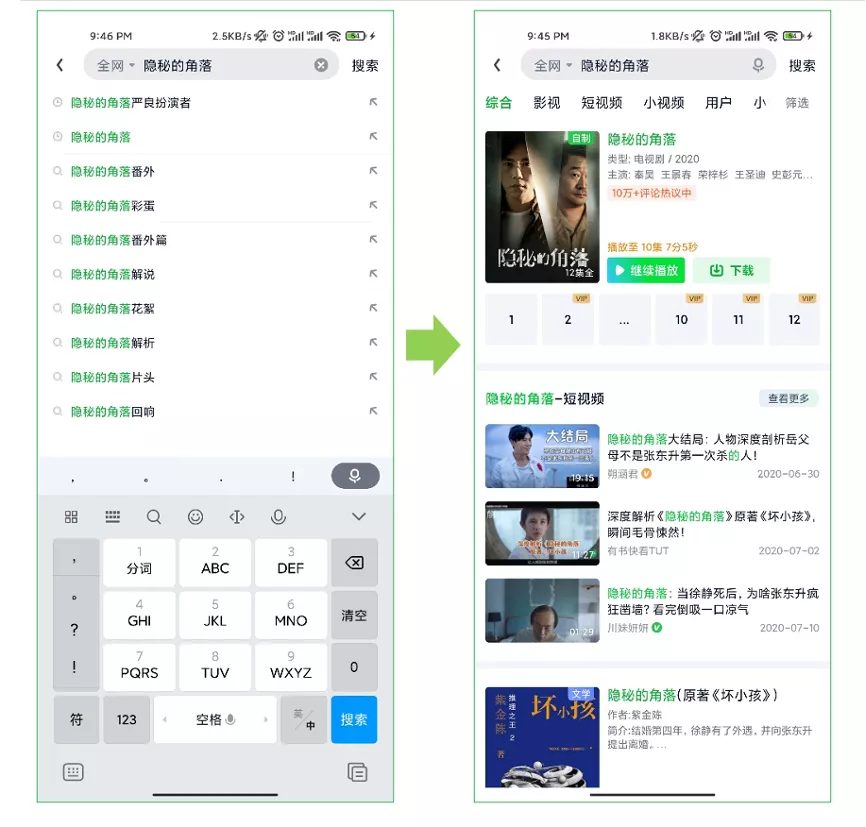
此外,结果页 顶部的Tab栏 还分为综合、影视、短视频、小视频等等, “综合”栏对应的是我们的综合搜索业务,后面的“影视”“短视频”等对应的则是我们的多垂类搜索业务。
本文将主要介绍我们基于 综合搜索 的实践。
2.业务优化目标
我们的业务优化目标主要分为 四大块:
(1) 提升搜索效率。 这里主要有 三个衡量指标,都与 用户的体验 有关。第一个指标是 Session CTR,就是用户一次请求对应的点击率;第二个指标是 UCTR,指的是用户整体点击率;第三是 二次搜索率,也就是一个用户在短时间内有多次搜索行为,说明对当前搜索结果不是特别满意;
(2) 促进用户消费。 用户消费的衡量指标目前包括三大类: 用户播放时长、点击次数及互动次数。
(3) 完善内容生态。 目前我们搜索的范围包括全网视频(站内及站外)、优质垂类分发、爱奇艺号等等。
(4) 新热多样,包括针对新视频的冷启动、时效性提升、多样性优化等。
3.整体架构
下图是我们的 整体架构图。
最上方是 用户业务方的调用接口,之后进入到 综合调度模块,这块主要负责URL的接收,以及整体业务逻辑的处理。
综合调度会读取一系列数据,包括 Query的分词解析纠错以及Query的意图识别,例如Query本身要查询哪些品类?是电影、电视剧还是综艺?要查询查询长视频还是短视频?
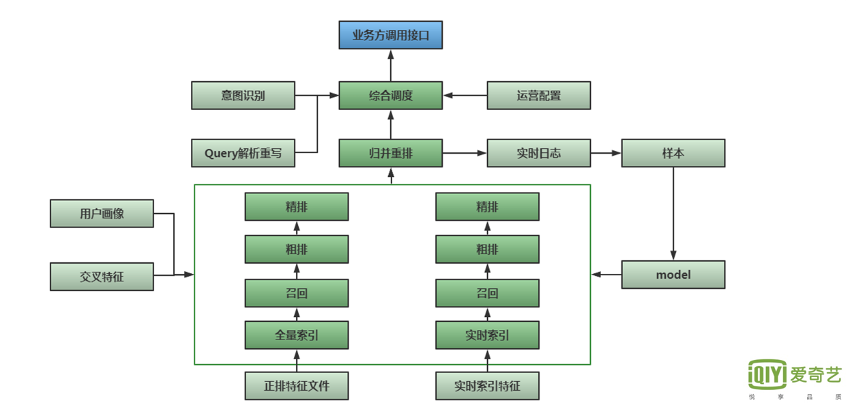
另外,还有 运营配置模块,这里我们支持 人工定义,在特定的Query和场景下,吐出相应的Doc。
中间这一部分是归并重排,负责合并从多个分片的Doc并去重,同时进行重排以及策略调权。
下方部分的预测服务采用Lambda架构,索引部分主要分为 两大块——全量索引和实时索引,均匹配对应的召回、粗排、精排流程。
同时,我们的预测服务也会 读取用户画像和交叉特征。交叉特征计算是独立的一个服务,主要内容为 当前Query和当前候选Doc的交叉统计后验特征,包括点击率、时长等维度,另外会进行Term扩展,将Query分词后的多个Term分别与候选Doc计算交叉特征,然后聚合形成新的特征。
此外, 归并重排这部分会打印实时日志,然后产生样本,进行模型训练。
4.算法策略框架
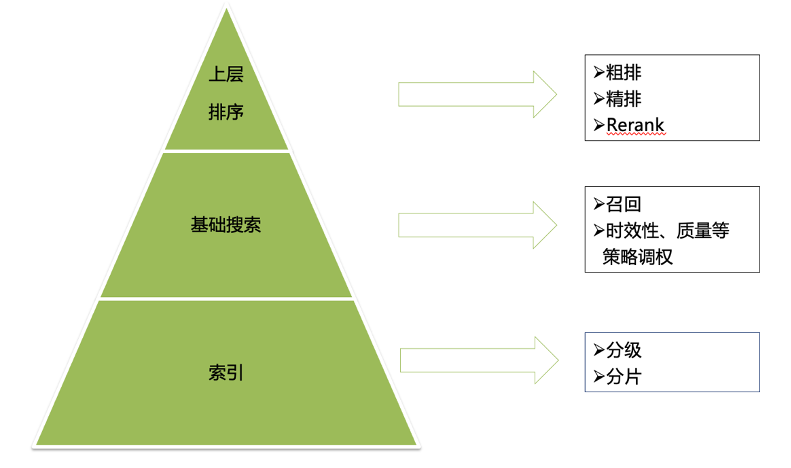
我们的整体算法策略框架也分为 三大块: 第一部分是索引,这部分主要进行分级、分片的处理。
分级策略 包括规则和模型,比如站内视频、长视频、新视频、模型分数较高的优先进入一级索引。
此外, 我们还需要对不同的分级进行分片,分片主要按照天级、小时级、实时等生成时间窗口划分, 并基于索引进行基础搜索,即召回流程,如倒排索引、向量召回等。
框架的最上方则是上层排序,包括粗排、精排、Rerank的功能。
5.排序流程
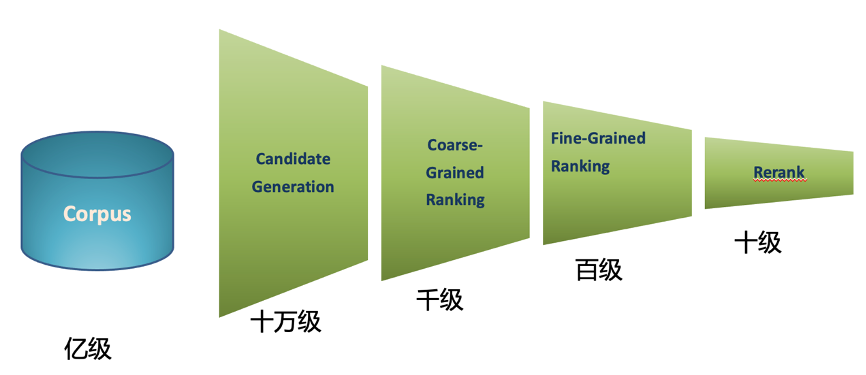
爱奇艺综搜场景下, 全量Corpus为亿级别,召回阶段候选集为十万量级,粗排为千级,精排为百级,Rerank为十级,最终展现到用户UI界面中。
02 爱奇艺搜索排序算法实践
接下来我们按照下图的搜索排序流程来依次进行介绍。
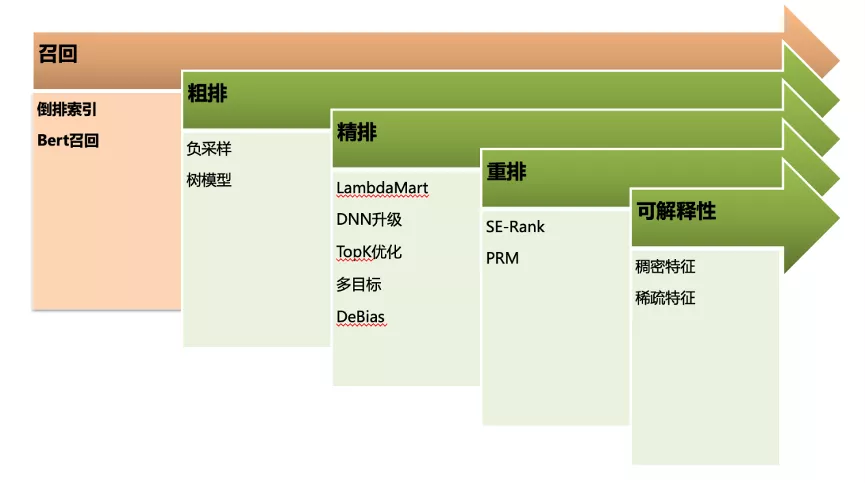
STEP1:选择攻击对象
首先是 召回Trigger 的选取。
我们会先对用户的Query进行 对应分词。 单纯的分词会存在一些问题,比如“台媒”和“台湾媒体”本身是相同意义的词,另外还有一些中英文的对照,这些词之间需要一定的映射匹配。
这里会涉及到Term的翻译问题。
下图最右侧是Term翻译模型实现的流程:
首先,我们提取一定时间窗内点击次数较高的 Query-Doc_title对,为翻译模型提供平行语料;
第二步, 构建翻译模型的训练挖掘,进行词对齐和短语对齐。
第三步,我们 基于翻译模型输出的候选对,进行一系列的特征的抽取,如翻译模型对应的 输出概率、分词特征、字向量 等,然后建立二分类质量模型。
最后,我们会对模型分数较高的候选对进行 筛选评测,把质量较高的候选对存储到线上词表进行应用。
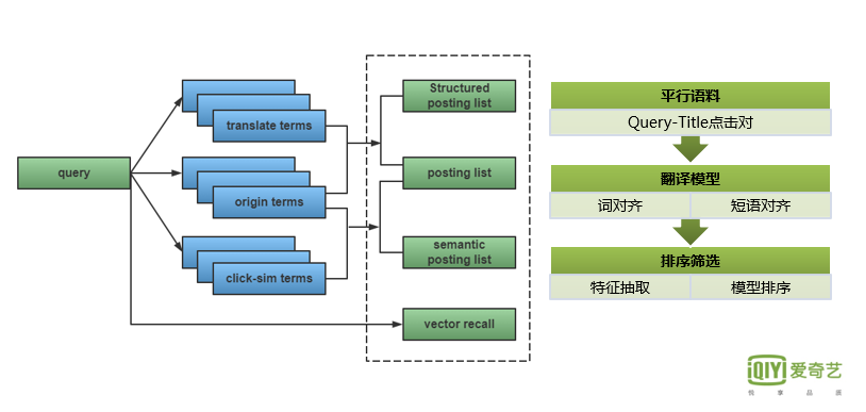
整体来看, Term可以分为三类:原始Term、对齐Term还有点击相似Term。 其中点击相似Term是通过构建Query-Doc的点击二部图,对 Query/Doc 的表达向量进行无监督的迭代训练获取。
上图虚线框对应的是召回的种类,如 常规、结构化、语义的倒排索引以及向量召回等。向量召回包括DSSM召回、Bert召回等,线上采用ANN计算方式。
下面主要详细介绍一下 Bert召回。
离线训练主要采用三元组的构建方式,同时Query和Doc共享相同的Bert参数。Query和Doc的Bert输出层接入多层MLP后进行相似度计算。具体可以分为以下四部分介绍:
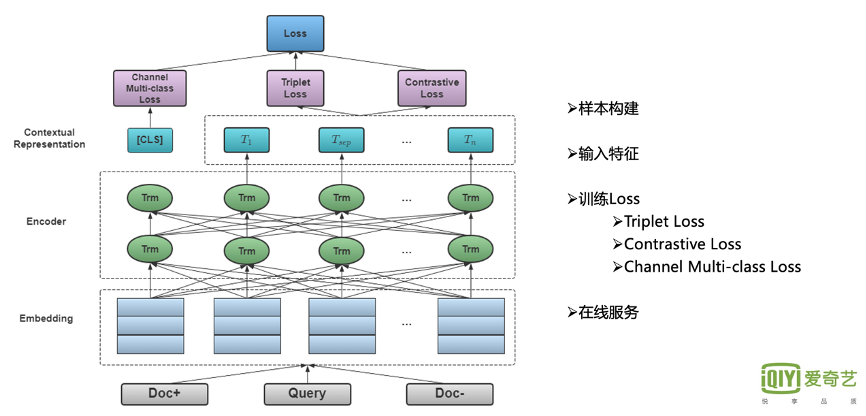
1.样本训练
正样本主要包含当前Query下用户的长点击Doc。
对负样本,我们会做一些相关的处理。 整体负样本来主要自三个方面:
首先,用户有展无点隐式负反馈样本的随机采样。
第二,我们会把与当前Query有一些少量点击Doc交集的相似Query中,点击位置较低的Doc作为负样本,加速模型的收敛。
最后,我们对全局的Doc进行一定比例的随机负采样。
2.特征建构
Query侧特征是 Query本身字的序列。Doc侧则包含它的原始title、别名、对应的英文翻译以及导演、演员、角色等多Field的信息。每个Field信息以 [SEP] 进行分隔。
横向部分主要包括多Field对应的字ID的拼接,纵向部分会加入 Position、Field ID以及Mask标记。
3.训练loss
整体Loss中, 首先是Triplet Loss,主要学习正负Doc之间的序关系。 另外,我们会加一个 对比学习的Loss,以避免模型坍塌。 第三,我们还会加入频道多分类的loss,用以提高整体语义的学习。
最终Loss为这三者的线性加和。
4.在线服务
训练之后我们会进行在线服务。由于Doc侧量较大,多Field字特征也比较长, 90%分位的字特征长度在128左右。 因此这部分进行离线刷库,线上直接调用。
由于 Query字特征较短,因此进行在线实时预测,并与Doc侧向量进行相似度学习计算, 获取对应倒排拉链。
STEP2:粗排
我们知道粗排的主要功能是 为精排提供候选集,其中最主要的就是负样本的选取。由于线上计算耗时的原因,对于比较重的精排, 如果对全量的召回Doc进行预测,将会带来极大的延时,因此需要增加粗排来进一步过滤筛选。
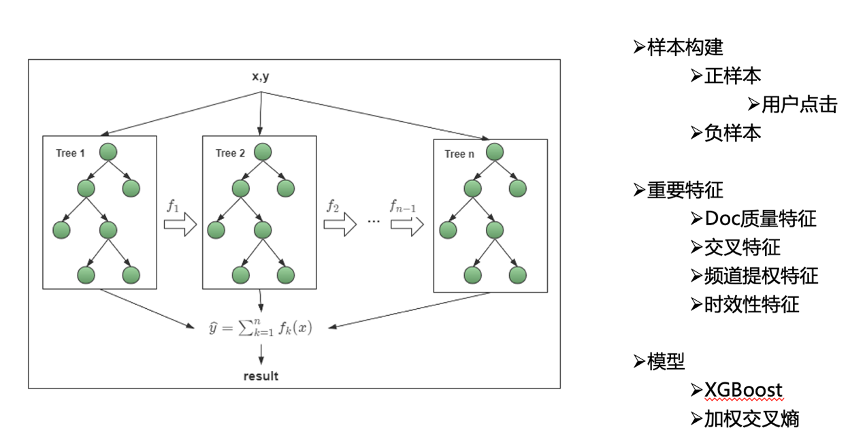
粗排主要是把精排输出的 TopK以及用户的最终点击作为优化的目标。正样本为用户的正向点击,负样本除有展无点样本外,会按一定比例加入 精排分数较低的doc,同时 对相关性较差的样本进行负采样,以提高相关性。
整体模型构建采用 树模型 的方式,以减小线上压力。整体来看,粗排阶段的Doc 质量分、交叉特征、时效性 等特征重要性较高。
STEP3:精排
1.Learning to Rank
首先,我们回顾一下 Learning to Rank的基础概念。
一是 Point-wise,把全局所有的单个Doc进行学习,当前Doc的Loss和其他Doc是相对独立的。
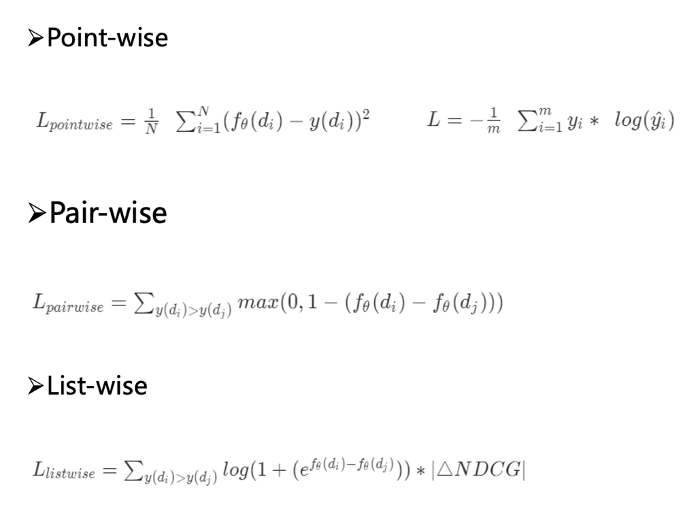
二是Pair-wise。 这部分主要通过所有Doc两两组合,生成不同的Pair,学习各样本之间的大小关系。
这种情况下会出现一个问题:没有考虑同一个Query对应的Doc Pair间的 内部依赖性,同时也没考虑Doc Pair的 相对位置,比如排行第一与排行第十的Pair之间的重要性比排行第四、第五之间的Pair重要性高很多, 因此引入IR评价指标作为样本的权重显得非常重要。
这其实是 List-wise 的一个思路。
2.RankNet & LambdaMart
Pair-wise目前比较常用的模型是 RankNet,按照Doc Pair的点击 质量大小关系,打标为1、0和-1,之后采用 交叉熵Loss 进行学习,对应的计算公式如下图所示。

在RankNet最终的梯度基础上,加入评估指标 NDCG 的变化量,可以将其转化为List-wise的学习,同时可以达到 损失可导的效果。
另外,我们的训练框架采用 MART,其训练效率较高,而且支持不同特征组合及热启动等。
我们目前采用点击质量来构建Label,在不同的数据类型下将对应的播完率划分成0到3档。 同时样本按Query不同搜索频次分段进行不同比例的采样,着重学习搜索量分布中,躯干部分的Query。
整体来看,LambdaMart适用于排序场景,对比大小并非绝对值,对正负样本比例不敏感。
3.LambdaRank DNN
但是LambdaMart模型 仍然存在以下问题有待解决:
(1)对高维稀疏的支持较差;
(2)当样本达到亿级,树模型会存在一定的训练效率低下的问题;
(3)对一些多目标还有增量学习支持不太好。
因此, 我们做了DNN模型的升级。
从其升级情况来看,首先,和树模型相比,只有稠密特征的前提下,DNN模型想要超越前者仍然较为困难。因此, 我们新增了一部分稀疏特征,具体如下。
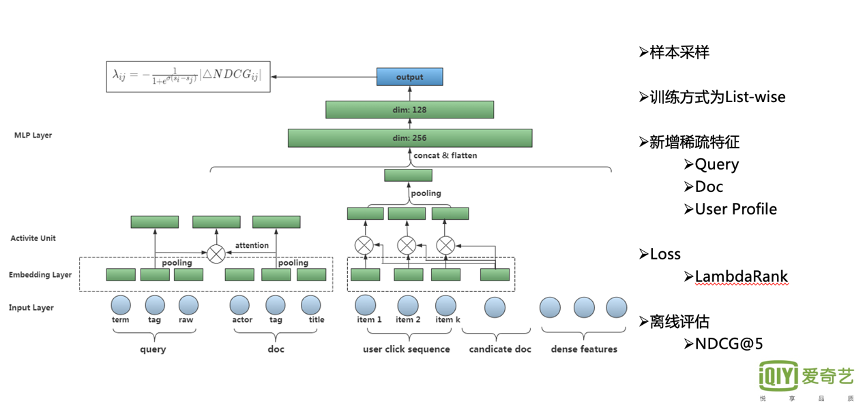
Query侧主要加入了 Query分词、意图识别标签等。
Doc侧加入了 演员、内容标签、Title、Clicked-query等特征。
Query侧和Doc侧的 多值Meta特征 分别Pooling后进行交叉学习。
另外,我们还会加入一些 用户画像的序列,比如用户的 长期、短期画像,用户按时间序列的点击序列等。目前我们采用的是一个 DIN的结构,学习用户的多兴趣表达。另一部分是原始的稠密统计特征,以及候选Doc的ID特征。Loss采用的是树模型相同的LambdaRank。
DNN升级在整体点击率指标上有 百分位以上的提升。
4.TopK Optimization – Hot Query
在DNN升级的基础上下,我们进行了针对性的 TopK业务优化。
从搜索业务来看, TopK位置的展示效果 对用户体验的影响非常大,如果Top位置的内容质量及相关性较差,会直接导致用户跳出。
因此,我们对其进行了特定优化。下图所展示的是热门Query部分的优化方案。
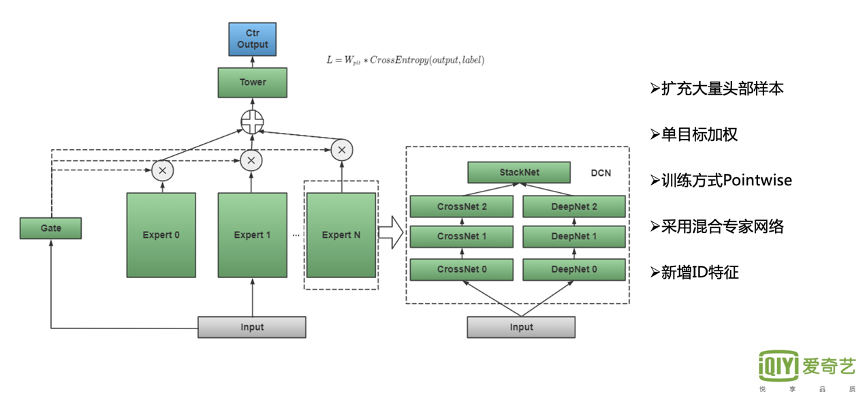
首先,我们扩充大量 头部样本,对采样逻辑进行了大幅调整。从统计情况来看,TopK样本所在的List往往较短,用户点击并看完第一个位置的Doc后,可能会马上离开。在这种情况下,List内的Doc只能有两个左右。因此,我们调整样本采样策略, 同时把List长度放开到大于等于2。
另外,List-wise的训练模型也存在一定的问题。不同的List下的Doc长度是不一样的,点击的总次数也不同,因此,整体Query会面临学习不是特别稳定的情况,构造权重也相对比较复杂。
因此,我们直接将训练方式切换成 Point-wise,采用对 CTR单目标 进行时长加权,不仅有利于克服以上问题,还有一个好处就是头部的样本对应时长的权重非常高,以此加强整个模型对头部样本的学习。
在模型上,我们采用 混合专家网络,以提升整体模型的精度。
另外,我们也增加了 ID特征。我们将QueryID和DocID直接Concat,并做低频过滤,这样做主要是加强TopK的记忆功能。热门Query部分TopK优化后,Top区点击率大幅提升。
5.TopK Optimization-Longtail Query
接下来,我们再来看一下长尾部分的优化。
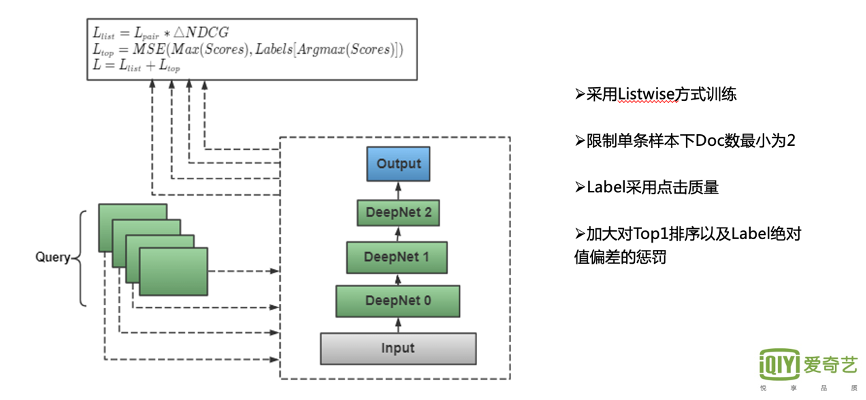
我们主要是加大了对Top1的惩罚,具体实现的逻辑是:在当前模型训练中,对应Query下所有的Doc中,我们会把模型得分 最大的Doc对应的Label 取出来,二者进行 MSE计算,并加入到原始LambdaRank Loss中,这样就可以加大对Top1的排序和绝对值偏差的惩罚,长尾Query部分的点击率提升显著。
6.Residual PLE
下面是多任务学习这一部分,我们参考的是PLE的结构。如下图左边的网络所示,首先是 Input层,再往上是 点击以及时长的多任务多专家网络。
首先,PLE结构能够使不同的专家网络分工更加明确,如图所示, Experts Shared模块 是 多任务共享 的网络,Experts A模块则专门学习CTR目标,Experts B模块则专门学习播放时长目标。从Label层面来看, 点击部分主要为点击率,时长部分则由于时长值域分布较广, 模型学习非常困难,因此对播放时长的原始值进行Log平滑处理,相对于指数平滑,这种方式更注重时长腰部的提升。
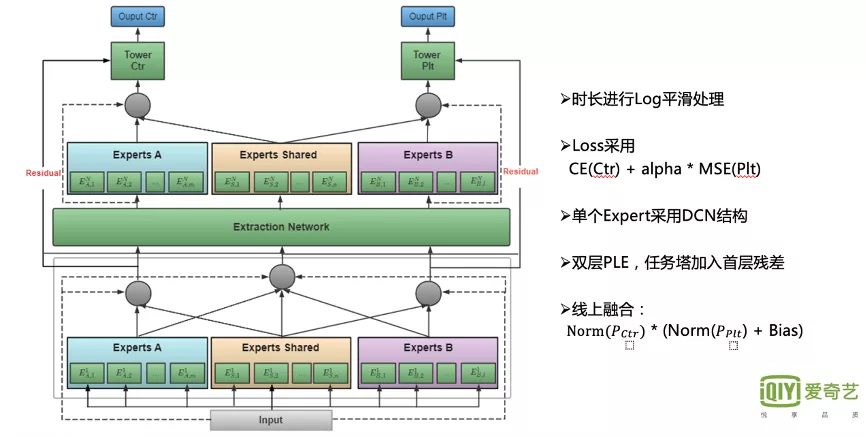
Loss部分我们采用的是 交叉熵与MSE的线性加权。
从模型结构来看,单个Expert采用的是DCN结构,在我们的业务中,由于后验统计特征重要性是最高的,且DCN结构中融合了 线性与非线性交叉 的特征,同时包含残差的功能,因此非常适用于我们的场景。
整体PLE结构采用了两层,我们曾经做过相关尝试,如果直接使用,效果较差,下限比较低。但若 将第一层叠加到最后一层进行残差的学习,将可以极大地提升离线效果。
最后是 线上融合,乘法相对加法更能兼顾不同目标的独立性。在热门部分,长点击率获得了明显提升。
7.Position Bias
下面,我们再介绍一下搜索场景比较常见的 Position偏差 的问题。
图中蓝色部分代表的是 点击率,红色代表 曝光占比。从点击率来看,我们可以发现 Top1点击率要远远高于其他所有位置,并且Top1与其之后的位置间有着极大的落差。曝光占比也是头部远高于其他位置。其实这种情况说明了一个问题——当前所有Doc随机分发, Top区位置的Doc存在更大的概率被用户注意到并点击,因此存在一个较为明显的偏差问题。
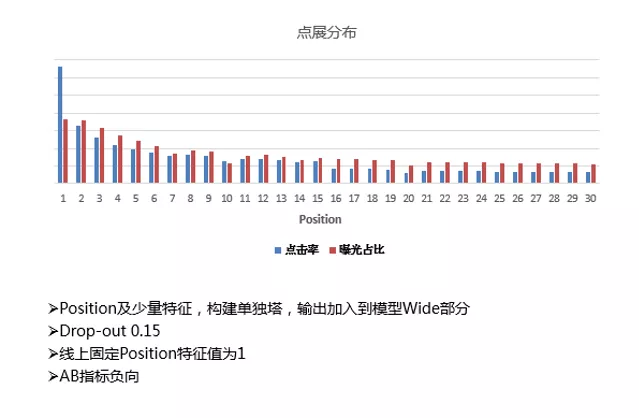
另外,如果有的Doc一直排行在Top1位置,特征积累非常丰富,也会造成特征的偏差。 这样会使得有些Doc虽然效果并不好,但却常常处于Top1的位置。
于是,我们开展了 去Position Bias的工作。首先采用了较为常规的方法,利用Position特征以及少量上下文特征,构建了单独的 Position塔,并将其输出加入到 模型Wide部分。上线实验后效果较差,经分析,我们发现了Position特征与Label相关性过高,离线的模型非常依赖它,Position特征线上线下不一致性对指标影响非常严重,线上全部填1后AB指标降幅较大。
因此,我们继续做了一些优化,加入了 当前Doc被用户看到(注意到)的概率建模。
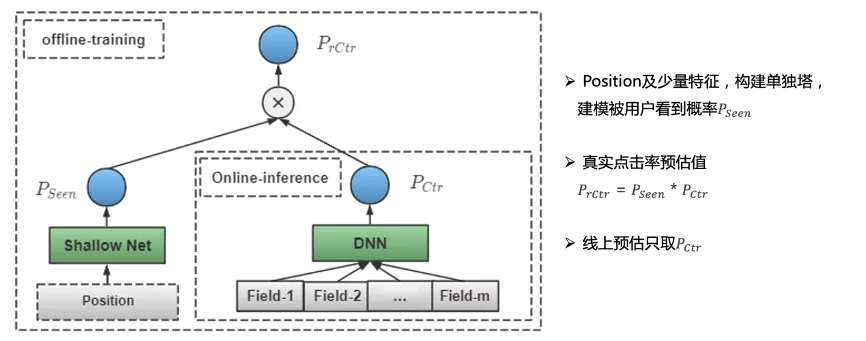
整体来看,用户真实的点击率存在着一个 条件概率。
首先,这个用户在这个Position下能注意到它,如果排行靠前,用户更容易被它吸引。
另外,我们会对原始的CTR进行建模,会复用之前的精排模型结构。之后再将二者的整体输出进行相乘,对真实CTR进行建模。
线上预测时直接用右侧DNN模型,整体来看,长尾部分取得了明显的正向收益。
STEP4:重排
这部分主要采用的是 SE-Rank模型。我们之所以要进行重排,是因为精排部分是分片的,没法加入上下文感知,比如同一个Query下,每一个Doc在精排阶段都是相对独立的,并不清楚要对比的候选集是怎样的,存在所有候选Doc的特征值相似,导致Doc之间的精排得分区分度不高,因此需要把上下文感知加进去,并进行重排。
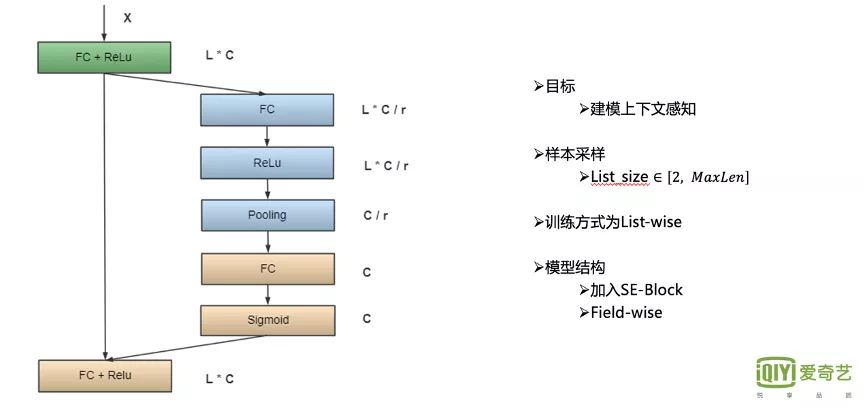
SE-Rank中的X就是对应一系列输入的Doc及其对应的特征,上图中的L则表示对应 Doc的个数,C是特征的个数。在目前采用多Field的情况下, 每一种特征都单独学习对应的上下文感知模块。
首先将原始Query下所有 候选Doc的特征联结起来,同时,对网络进行一定比例的压缩,降低模型复杂度,避免过拟合,效果有一定提升。
然后进行Pooling,构建上下文感知,学习当前的全局情况。
最终我们将Pooling后FC的结果返回给所有的候选Doc,这样完成上下文感知的构建。
这里使用的训练的方式也是List-wise。
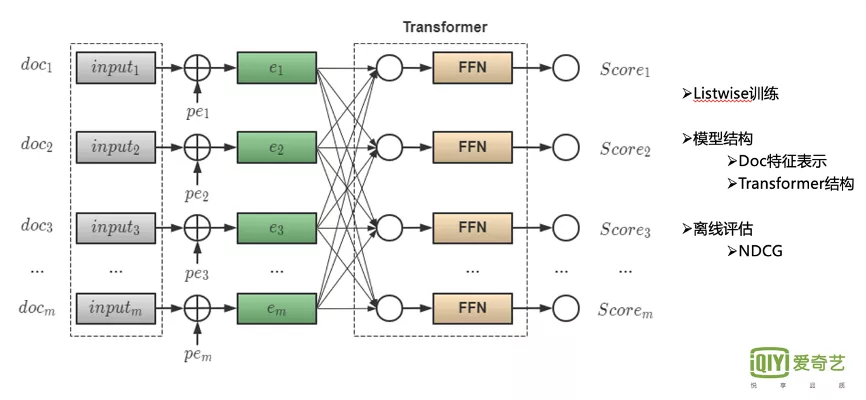
由于Transformer非常适合上下文场景感知的学习,于是我们在SE-Rank的基础上进行了优化。整体模型结构是 输入层接入Transformer结构,更利于当前Doc对所有候选Doc注意力及上下文影响的学习。
我们的离线评估采用的是 NDCG,线上也取得了不错的效果。从离线NDCG来看,能够提升百分位以上。
STEP5:可解释性
由于我们进行了一系列深度模型升级和优化,会面临一个问题: 深度模型越来越复杂,应该如何解释?
这个问题的解决有助于我们后续的一系列模型和特征优化。
1.可解释性—稠密特征
稠密特征解释性部分,我们采用了 LIME框架。
LIME是一个 局部可解释的框架,在我们场景中,以 Query-Doc Pair的粒度,获取线上的准确实时特征,并进行局部扰动,生成一系列衍生样本。
具体实现逻辑为: 稠密特征扰动主要是对当前每个特征
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%88%B1%E5%A5%87%E8%89%BA%E6%90%9C%E7%B4%A2%E6%8E%92%E5%BA%8F%E7%AE%97%E6%B3%95%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


