用户画像之标签权重算法
作者:超人赵,人工智能爱好者社区专栏作者
知乎:
https://www.zhihu.com/people/chao-ji-sai-ya-ren/posts
感谢大家长期以来对文章的关注,最近工作比较忙,好久没更新了。接下来的几篇文章想和大家分享下关于用户画像的一些东西。今天我们先从用户画像的标签权重开始聊起吧。
用户画像: 即用户信息标签化,通过收集用户社会属性、消费习惯、偏好特征等各个维度数据,进而对用户或者产品特征属性的刻画,并对这些特征分析统计挖掘潜在价值信息,从而抽象出一个用户的信息全貌,可看做是企业应用大数据的根基,是定向广告投放与个性化推荐的前置条件。
先举个场景,程序员小Z在某电商平台上注册了账号,经过一段时间在该电商平台的web端/app端进行浏览、所搜、收藏商品、下单购物等系列行为,该电商平台数据库已全程记录该用户在平台上的行为,通过系列建模算法,给程序员小Z打上了符合其特征的标签(如下图所示)。此后程序员小Z在该电商平台的相关推荐版块上总能发现自己想买的商品,总能在下单前犹豫不决时收到优惠券的推送,总是在平台上越逛越喜欢….

上面的例子是用户画像一些应用场景。而本文主要分享的是打在用户身上标签的权重是如何确定的。
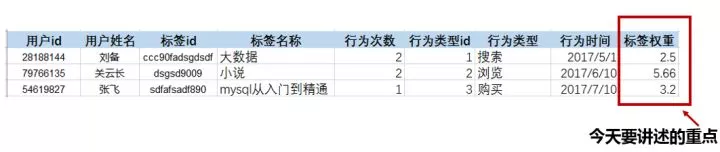
如上图所示,一个用户标签表里面包括常见的字段如:用户id、用户姓名、标签id、标签名称、用户与该标签发生行为的次数(如搜索了两次“大数据”这个关键词)、行为类型(不同的行为类型对应用户对商品不同的意愿强度,如购买某商品>收藏某商品>浏览某商品>搜索某商品),行为时间(越久远的时间对用户当前的影响越小,如5年前你会搜索一本高考的书,而现在你会搜索一本考研的书)。最后非常重要的一个字段是标签权重,该权重影响着对用户属性的归类,属性归类不准确,接下来基于画像对用户进行推荐、营销的准确性也就无从谈起了。下面我们来讲两种权重的划分方法:
1、基于TF-IDF算法的权重归类
TF-IDF算法是什么思想,这里不做详细展开,简而言之:一个词语的重要性随着它在该文章出现的次数成正比,随它在整个文档集中出现的次数成反比。
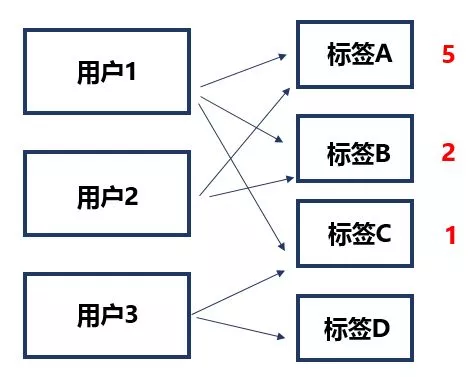
比如说我们这里有3个用户和4个标签,标签和用户之间的关系将会在一定程度上反应出标签之间的关系_。_这里我们用w(P , T)表示一个标签T被用于标记用户P的次数。TF(P , T)表示这个标记次数在用户P所有标签中所占的比重,公式如下图:

对上面的图来说,用户1身上打了标签A 5个,标签B 2个,标签C 1个,那么用户1身上的A标签TF=5/(5+2+1) 。
相应的IDF(P , T)表示标签T在全部标签中的稀缺程度,即这个标签的出现几率。如果一个标签T出现几率很小,并且同时被用于标记某用户,这就使得该用户与该标签T之间的关系更加紧密。
,商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


