用户画像标签聚类
作者: 超人赵,人工智能爱好者社区专栏作者
知乎:
https://www.zhihu.com/people/chao-ji-sai-ya-ren/posts
链接推送: 如何构建用户画像—打用户行为标签
这次想继续和大家聊聊用户画像。用户画像是个体系性比较强的内容模块,分一两次博客也写不完,我争取分多次博客把各个模块都搭建起来。上次把用户画像方面的内容开了一个头,讲了关于标签权重的计算方法,这次就聊聊标签聚类的方法。其实聚类不限于方法和形式,只要能将同类物品 / 内容进行准确聚类的,都是好的方法。好啦,开篇结束啦,下面让我们进入正题吧:
一、应用背景:
继上一篇中提到的用户标签表,存储了用户在平台上每次操作(来自日志数据)、购买(来自业务数据)等行为带来的标签。随着时间的累计,各用户在平台上积累的标签数以亿计,如何对这些不同类型的标签进行归类,找到每个标签所属的某一类别,是本次讲述的重点。
二、标签聚类:
Step1:从用户标签表抽取数据
用户标签表结构长这个样子(字丑 ╥﹏╥)
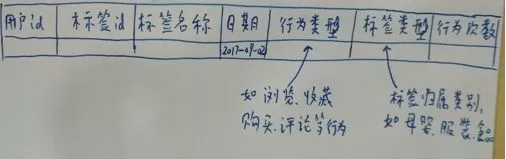
首先从用户标签表抽取两种类型的标签(我们暂命名为A类标签和B类标签),
创建临时表1,抽取A类标签:
create table gdm.tag_relation_cluster_function_01
as
select user_id,
org_id,
org_name,
cnt,
date_id,
tag_type_id,
act_type_id
from wedw.peasona_user_tag_relation --用户标签表
where date_id >='2017-01-01'
and date_id <='2017-08-24'
and tag_type_id in (1) -- A 类标签
group by user_id,
org_id,
org_name,
cnt,
date_id,
tag_type_id,
act_type_id
创建临时表2,抽取B类标签:
create table gdm.tag_relation_cluster_function_02
as
select user_id,
org_id,
org_name,
cnt,
date_id,
tag_type_id,
act_type_id
from wedw.peasona_user_tag_relation --用户标签表
where date_id >='2017-01-01'
and date_id <='2017-08-24'
and tag_type_id in (7) -- B 类标签
group by user_id,
org_id,
org_name,
cnt,
date_id,
tag_type_id,
act_type_id
Step2:计算每类标签对应的用户人数
这里用到了共现矩阵的思想,即两个标签上同时拥有的用户人数。即用户甲身上既有A类标签,又有B类标签则记为数字1,两两标签之间拥有的用户数越多,说明用户在平台上的行为在带来A类标签的同时也带来了B类标签,即两个标签之间的相关性越大。在HQL中的逻辑如图:
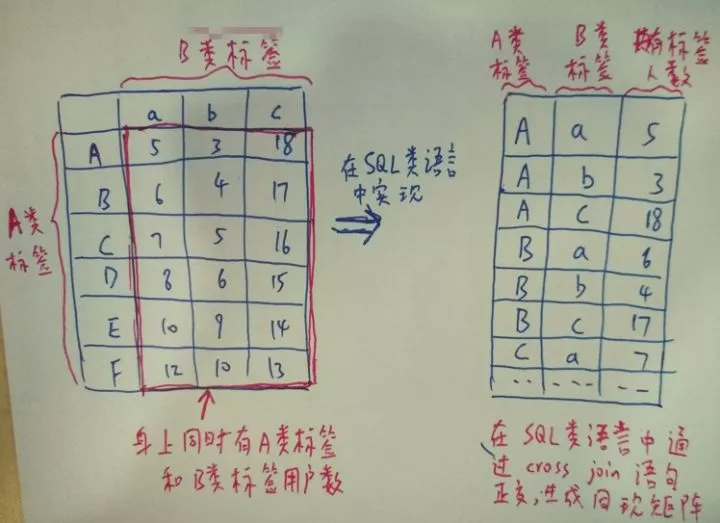
创建临时表3,计算A类标签下每个标签对应的用户人数:
create table gdm.tag_relation_cluster_function_03
as
select org_id,
org_name,
count(distinct user_id) user_num,
row_number() over (order by count(distinct user_id) desc) rank
from gdm.tag_relation_cluster_function_01
group by org_id,
org_name
创建临时表4,计算B类标签下每个标签对应的用户人数:
create table gdm.tag_relation_cluster_function_04
as
select org_id,
org_name,
count(distinct user_id) user_num,
row_number() over (order by count(distinct user_id) desc) rank
from gdm.tag_relation_cluster_function_02
group by org_id,
org_name
创建临时表5,计算A、B两类标签共同关注人数的共现矩阵:
create table gdm.tag_relation_cluster_function_05
as
select t.org_id_1,
t.org_name_1,
t.tag_type_id_1,
t.org_id_2,
t.org_name_2,
t.tag_type_id_2,
t.num
from (
select t1.org_id as org_id_1,
t1.org_name as org_name_1,
t1.tag_type_id as tag_type_id_1,
t2.org_id as org_id_2,
t2.org_name as org_name_2,
t2.tag_type_id as tag_type_id_2,
count(distinct t2.user_id) as num
from gdm.tag_relation_cluster_function_01 t1
cross join gdm.tag_relation_cluster_function_02 t2
--on t1.user_id = t2.user_id
where t1.org_id <> t2.org_id
group by t1.org_id,
t1.org_name,
t1.tag_type_id,
t2.org_id,
t2.org_name,
t2.tag_type_id
) t
Step3:用余弦相似度函数计算两两标签之间的相关性
余弦相似度函数怎么用,这里简单举个例子:标签a打在了10000个用户身上,标签b打在了20000个用户身上,有5000个用户的身上同时用户a标签和b标签,则a、b标签之间的相似度即为:5000 / sqrt(10000*20000).在HQL语言中执行如下:
create table gdm.tag_relation_cluster_function_06
as
select t1.org_id_1 as org_id_1, --标签a id
t1.org_name_1 as org_name_1, --标签a名称
t1.tag_type_id_1 as tag_type_id_1, --标签a type_id
t2.user_num_1 as user_num_1, --标签a 人数
t1.org_id_2 as org_id_2,
t1.org_name_2 as org_name_2,
t1.tag_type_id_2 as tag_type_id_2,
t3.user_num_2 as user_num_2,
t1.num as num, -- 同时有两个标签的用户数
(t1.num/sqrt(t2.user_num_1 * t3.user_num_2)) as power,
row_number() over(order by (t1.num/sqrt(t2.user_num_1 * t3.user_num_2)) desc) rank
from gdm.tag_relation_cluster_function_05 t1
left join (select org_id,
user_num as user_num_1
from gdm.tag_relation_cluster_function_03 --标签a 对应的用户人数
) t2
on t1.org_id_1 = t2.org_id
left join (select org_id,
user_num as user_num_2
from gdm.tag_relation_cluster_function_04 --标签b 对应的用户人数
) t3
on t1.org_id_2 = t3.org_id
group by t1.org_id_1,
t1.org_name_1,
t1.tag_type_id_1,
t2.use
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%94%A8%E6%88%B7%E7%94%BB%E5%83%8F%E6%A0%87%E7%AD%BE%E8%81%9A%E7%B1%BB/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


