百度图谱相关技术在风控反作弊中的应用和探索

百度安全策略团队 稿
导读:互联网黑产不断发展壮大,作弊模式逐渐变得规模化、产业化,团伙作弊行为日益猖獗。为了进一步提升百度账号的安全和用户体验,维护公司核心利益,百度账号安全策略团队结合自身在账号安全领域的优势,构建了可以处理海量数据、具备丰富扩展性的关联图谱黑产团伙挖掘能力,充分实践应用并不断拓展落地场景,同时也在图神经网络等前沿领域探索相关技术在风控反作弊场景中的应用价值,致力于构建高效、完备的基于图谱的风控反作弊能力。
一、简介
《中国互联网络发展状况统计报告》显示,截止2021年6月,中国网民规模达到了10.11亿。基于如此庞大的用户群体,使得互联网业务不断飞速发展。围绕着不断成长的互联网生态,自然而然也就催生出了一系列躲藏在隐秘角落里的黑灰产业务。随着技术的进步发展,黑灰产从最初的作坊式的作弊方式也转变成了流程化、规模化、产业化作弊模式,目前网络黑灰产规模也已超千亿,并且已经深入到多种业务场景进行作弊,首当其冲的即是账号系统,接着进入到具体业务场景,从事刷单、薅羊毛、引流、诈骗、洗钱等等欺诈作弊行为。黑灰产行为不仅使互联网公司蒙受金钱损失,长此以往更会影响用户的服务体验和财产安全,威胁到业务持续健康发展。
为了有效打击黑产作弊团伙,保障公司的基础安全,安全策略团队从账号维度出发,积极构建基于图谱的反黑产作弊架构,不断探索图谱相关技术在风控反作弊场景的应用落地。目前基于图谱技术构建了主要包括团伙挖掘能力、图谱节点表示能力。
二、团伙挖掘
众所周知,在实际业务场景下的黑产作弊团伙通常受限于资源、成本等现实条件,往往会出现共用资源的情况。这就成了挖掘黑产团伙入手的点,传统的方法是:可以通过统计特征因子筛选方式来筛选出一部分相关的账号,但这种方法很难进一步挖掘出整个相关的作弊团伙,只能case by case的处理这种问题。下面对比了传统手段与基础的关联图谱挖掘作弊团伙的差异(案例相关数据已做脱敏处理):
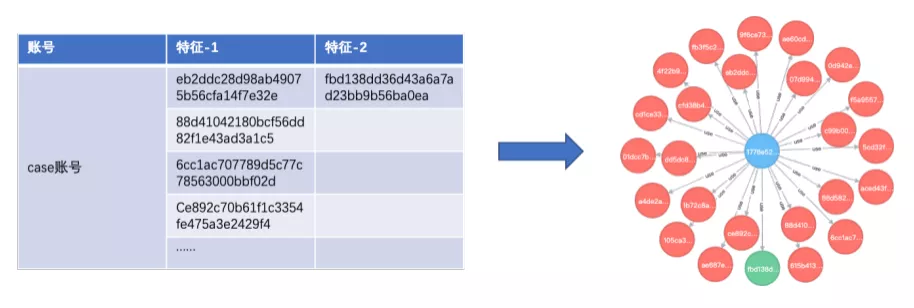
图- 1 案例 分析
如图-1左侧所示,图表中可以看出该案例账号使用过相当数量的特征因子和一个设备,这些关系转变为图结构即是图片右侧的图谱结构(账号:蓝色标记,特征因子:红色标记,设备:绿色标记)。通过这些关联因子进行挖掘,可以得到一批使用过这些可疑因子的账号,这其实也是图谱团伙挖掘的核心思想,但是想要通过这种方法挖掘出整个团伙却需要耗费大量时间。事实上,如图-2所示,该帐号只是整个黑产团伙中的冰山一角,传统方法挖掘的难度可想而知。
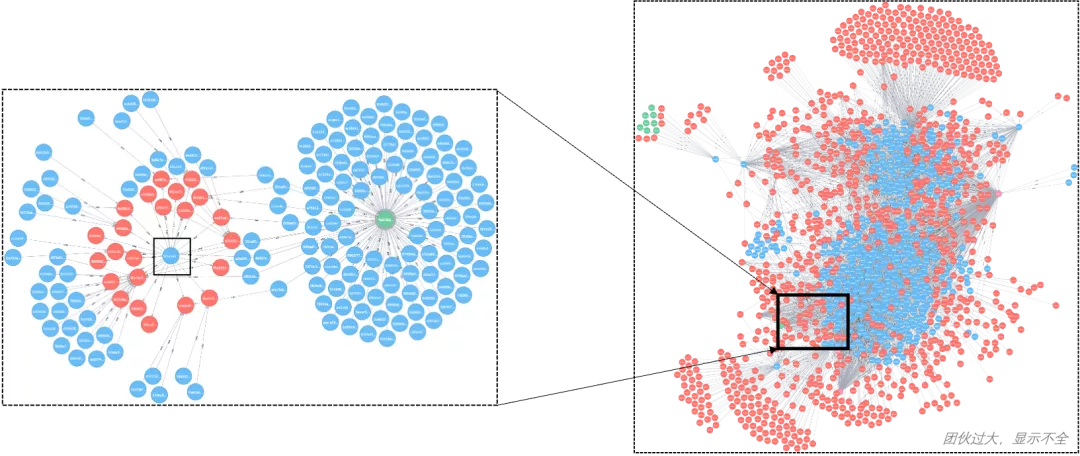
图-2 案例所属团伙
上述的例子展现了关联图谱在团伙挖掘中的优势。结合现有业务场景,团队构建了覆盖不同场景、不同粒度(天、周、月)、不同特征关系类型(同构图、异构图)相结合的关联图谱框架,涉及到了多种不同类型的节点、多种复杂边关系特征。关联图谱框架如图-3所示。
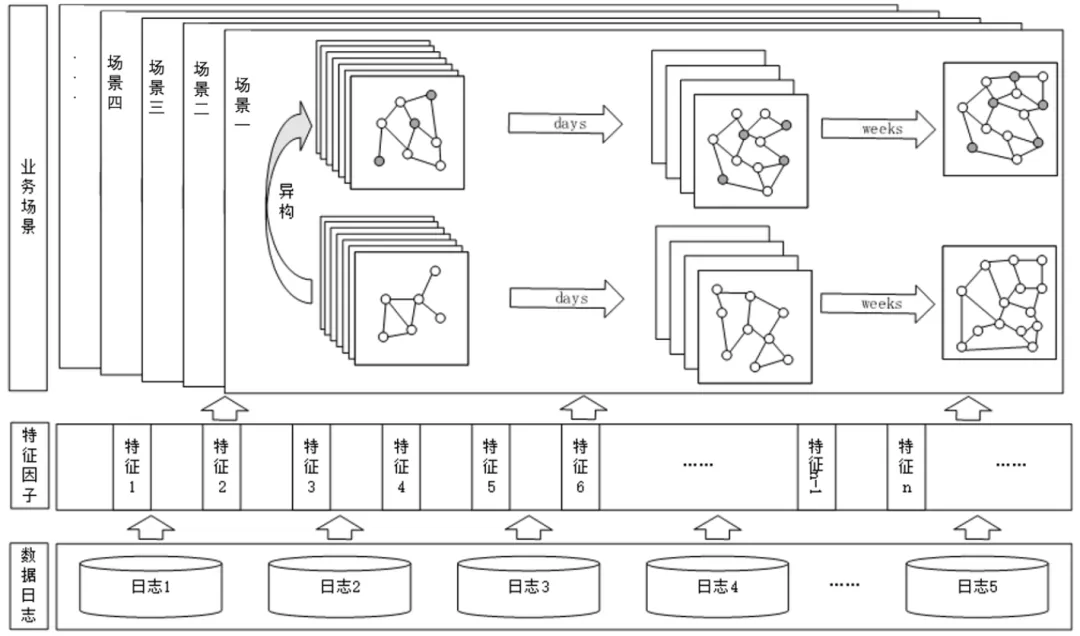
图-3 关联图谱基础架构
实际生产环境中的图谱都要处理几十亿节点和边数据,这是一个巨大的挑战,经过重新设计优化整个算法计算流程,该架构能够处理海量的数据并且具有丰富的扩展性,通过简单配置即可以挖掘不同异构情况下的团伙,也支持拓展新业务场景,通过跨场景的融合,在原有业务数据的基础上结合账号系统特有的账号安全信息,可以更全面挖掘分析黑产团伙。此外,利用关联图谱进行CASE分析扩召的能力也已经落地到实际业务中了。
实际业务中,使用关联图谱进行团伙挖掘可以找出CASE相关的可疑团伙,也可以监控业务中出现的异常团伙作弊行为,在新接入的业务场景中,通过关联图谱挖掘出来的可疑团伙都存在不同程度的团伙作弊行为。然而,新的技术也会带来一些新的挑战,正是因为基于特征的关联关系即绑定将不同账号进行绑定,这也使得账号之间的相关性并不牢靠,往往会存在以下一些问题:
- 通过设备信息等硬关联关系关联出的团伙也并非一定都是黑产作弊团伙,普通账号也可能存在共用设备、使用公共网络等情况,并不是关联出挖掘得到的所有团伙都是黑产团伙,所以需要对团伙进行分类定性;
- 实际业务中会因为脏数据、长时间跨度、黑产团伙间资源交叉、账号买卖等因素而产生规模巨大的团伙图谱,团伙图谱中可能会包含一些正常账号或者不同团伙的账号;
因此,也就有了更多的图谱相关的实践和探索。
三、团伙节点表示
针对关联图谱中所存在的问题,虽然有些可以通过一些条件限制、定义权重等进行过滤来减缓上述问题对整个关联图谱的影响,但是,这种一刀切的做法对于处理复杂边关系、多种节点类型的图谱很难做到恰到好处。因此,也就有了关于图谱技术更深入的探索——团伙中节点的表示。
节点表示,即将单个账号节点的特征信息通过深度学习的方法抽象为一个固定维度的向量,这个向量就表示这个账号,通过将账号特征向量化后,可以进一步做更多的下游工作,比如:节点间相关性的预测、节点的聚类、节点的分类等等。而图谱中的节点表示,不仅仅只考虑了该账号节点本身的特征信息,更包含了账号节点所处图谱中的结构信息,主要是节点的邻居信息和边关系信息。
团队调研了多种节点表示模型的方法,比如:Deepwalk[1]、LINE[2]、node2vec[3]等基于随机游走的方法,也包括GCN[4]、GAT[5]、GraphSAGE[6]、PinSAGE[7]等方法。
结合账号业务场景账号特征稀疏、节点规模庞大且没有显式标签的特点,所以通过链接预测任务来训练节点表示模型,考虑到整个数据的量级以及动态变化的问题,改进了GraphSAGE模型用于节点间链接预测,首先对目标节点进行基于随机游走的局部采样得到其邻居节点,通过两层GraphSAGE结构聚合目标节点两跳的邻居信息,结合两目标节点的表示向量交叉得到预测结果。通过半监督学习的方式,使用交叉熵作为损失函数,结合mini-batch的训练方式训练模型。模型架构如下图-4所示。
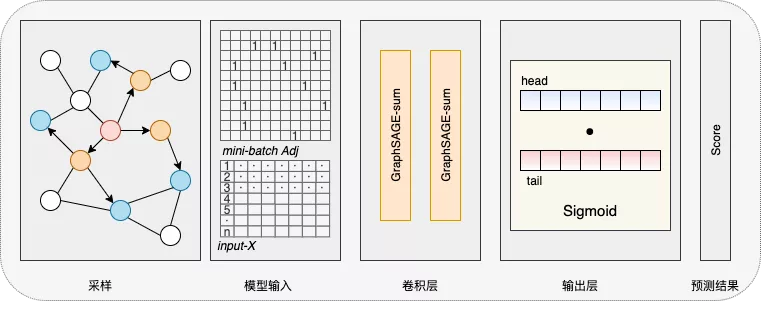
图-4 链接预测框架
如公式(1)所示模型输入的节点特征,此外还需要目标节点的子图结构和目标节点关系对。通过公式(2-4)是模型第层节点融合其邻居节点的过程。
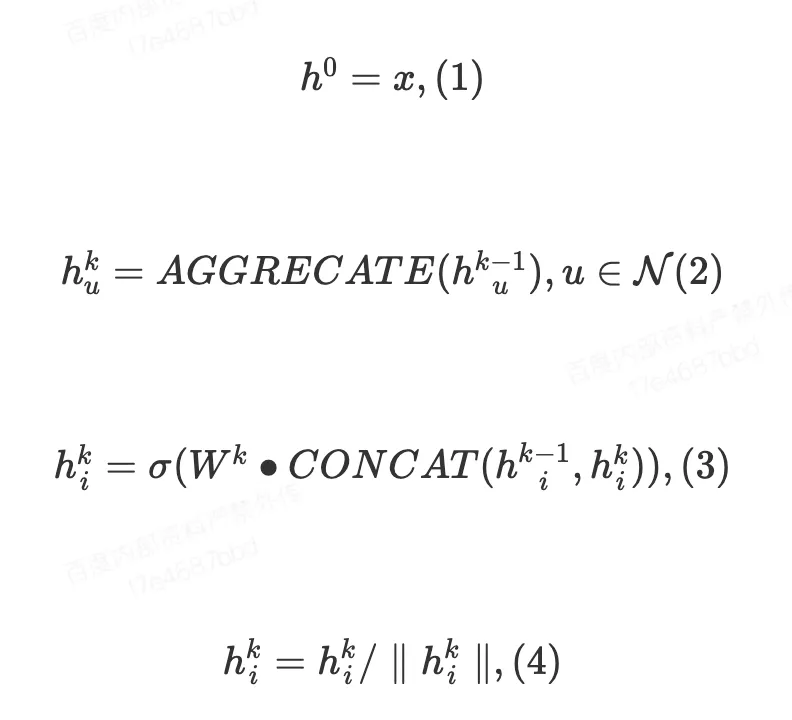
模型通过生成目标节点关系对的表示向量做点积得到最终的链接预测结果,通过随机梯度下降优化模型参数。即公式(5)所示。
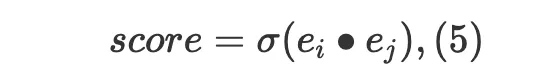
为了进行对比,同时实现了MLP、GCN进行向量表示的基础模型,相同超参数的条件下,分别生成了同一组账号的表示向量,为了直观展示模型生成表示向量的区分性,这里选取�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%99%BE%E5%BA%A6%E5%9B%BE%E8%B0%B1%E7%9B%B8%E5%85%B3%E6%8A%80%E6%9C%AF%E5%9C%A8%E9%A3%8E%E6%8E%A7%E5%8F%8D%E4%BD%9C%E5%BC%8A%E4%B8%AD%E7%9A%84%E5%BA%94%E7%94%A8%E5%92%8C%E6%8E%A2%E7%B4%A2/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


