百度技术图数据库在百度汉语中的应用

揽月 百度Geek说
导读:随着各行业的快速发展,数据间的关联性越来越高,但是传统数据库很难处理层次深、种类多的关系运算,由此图数据库应运而生。而本文则是介绍了图数据库在百度汉语中种类多样的场景下的应用。
一、前言
百度汉语业务包含字、词、古诗、成语、歇后语等10多种分类,共涉及实体数据1千多万条,虽然涉及的数据量级不大,但每个实体类型的属性繁多。比如一首古诗就包含内容、诗体、释意、作者、诗名、赏析、背景、标签等几十种属性,同时产品上需要支持“静夜思的作者是那个朝代的人”这样多种关联条件的查询。面对以上情况,如果采用传统的关系型数据库,比如Mysql,就需要给每种分类数据建一张表,并且为每个查询属性建立索引条件,这样在面对一些复杂的查询场景,需要一次性关联多张表才能取到结果,这明显不符合一般在线的业务的做法;另外除了满足一般的要求,百度汉语还需支持阿拉丁卡片快速召回的规范,响应结果做到200ms以内,支持峰值单机过千QPS的请求量;综上,面对这种层次深、关系种类多的海量复杂数据关系上,图数据库应运而生。
二、图数据库选型
2.1 图数据库介绍
图数据库(graph database,GDB)是一个使用图结构进行语义查询的数据库,它使用节点、边和属性来表示和存储数据。该系统的关键概念是图,它直接将存储中的数据项,与数据节点和节点间表示关系的边的集合相关联。这些关系允许直接将存储区中的数据链接在一起,并且在许多情况下,可以通过一个操作进行检索。图数据库将数据之间的关系作为优先级。查询图数据库中的关系很快,因为它们永久存储在数据库本身中。可以使用图数据库直观地显示关系,使其对于高度互连的数据非常有用。
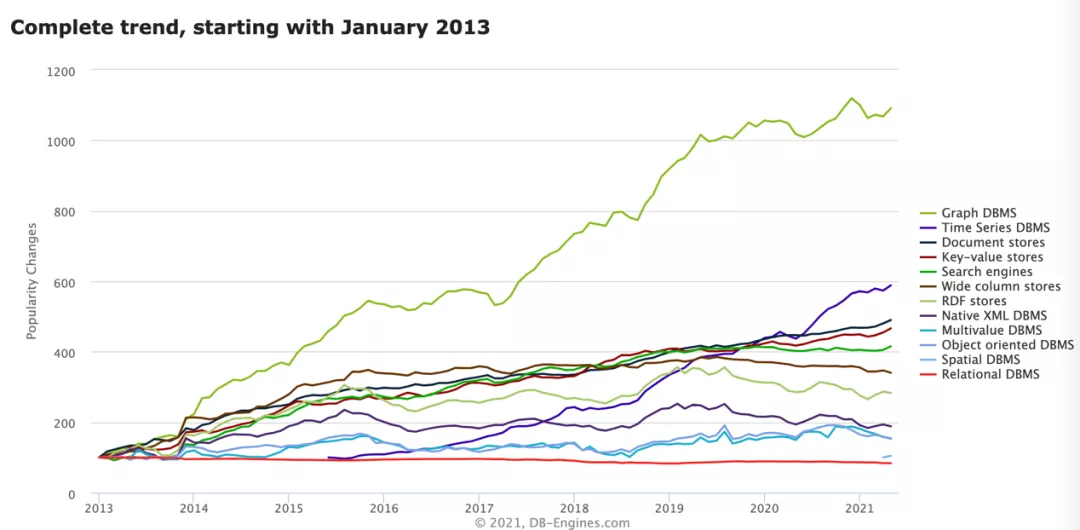
图一为db-engines网站各类数据库的趋势图,可以看出从2014年开始,图数据库一直处于领先地位。
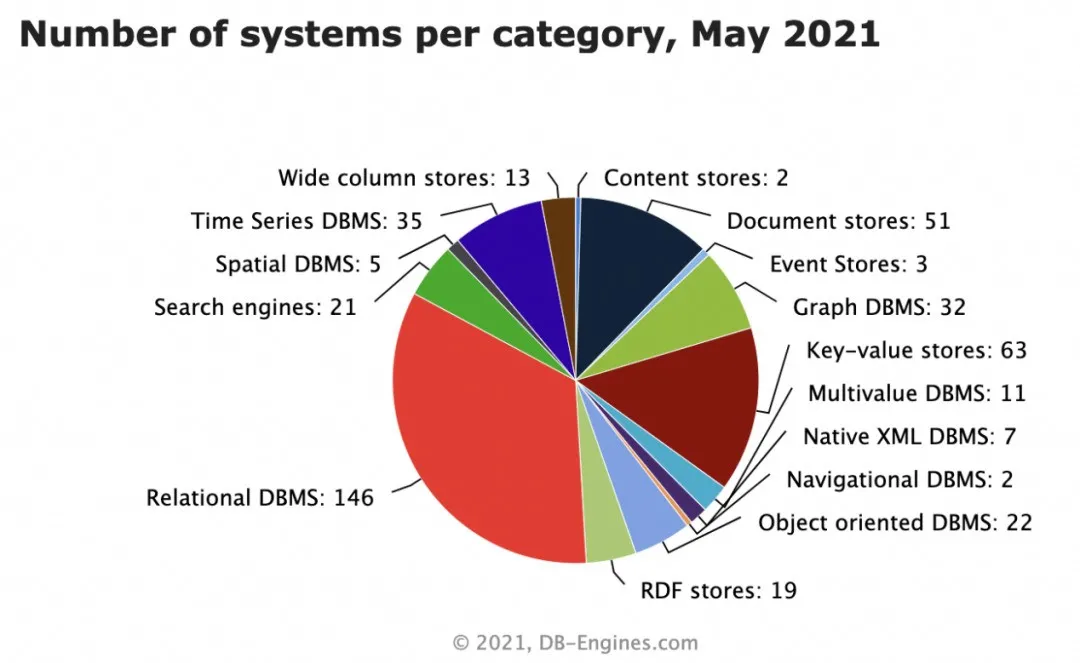
图二 是不同种类数据库系统数量,可以看出,常见的关系型数据库、kv型数据库占比最高,除此之外,图数据库占比也非常大。
2.2 图数据库选型
根据上图也可以看出,目前主流的图数据库至少有32种,业务方需要根据自己的业务特性进行选择,对于百度汉语这种业务来说,我们主要考虑了以下几点:
1)开源项目
2)项目成熟可扩展
3)部署运维成本低,稳定性高
4)文档丰富,最好社区活跃
5)支持批量数据导入和导出能力
目前使用最广泛的是neo4j,历史悠久,经得住时间的考验长期处于图数据库领域的龙头地位。然而很不幸,neo4j有两个大的硬伤: 1.开源社区版本只支持单机,不支持分布式;2.使用了商业不友好的GPL V3协议。
对于百度汉语来说,因部门调整、业务调整等需要,需要转移底层的存储引擎。因此,考虑到业务中的复杂在于查询场景的多样,而不是层次多,而且在数据大部分为静态数据的情况下,因此使用的是百度开源的HugeGraph图数据库(链接: https://HugeGraph.github.io/HugeGraph-doc/)。
这里可以提到的是,HugeGraph本身提供了多种存储引擎以供使用(Memory、Cassandra、ScyllaDB、RocksDB、Mysql等),在百度汉语中, 相比于其他kv存储引擎,Rocksdb对我们来说了解比较多一点,数据以文件的形式保存在文件夹内,方便移动拷贝,而且对SSD的支持、吞吐量更好,因此我们使用的是Rocksdb。此外HugeGraph对数据的维护支持更好,本身提供了RESTful Api和大批量数据干预的loader工具,轻松支持亿级数据的导入。
而且HugeGraph支持Apache TinkerPop3的图形遍历查询语言Gremlin。SQL是关系型数据库查询语言,而Gremlin是一种通用的图数据库查询语言,Gremlin可用于创建图的实体(Vertex和Edge)、修改实体内部属性、删除实体,也可执行图的查询操作。Gremlin可用于创建图的实体(Vertex和Edge)、修改实体内部属性、删除实体,更主要的是可用于执行图的查询及分析操作。
三、百度汉语图数据库建设
3.1 汉语服务部署
HugeGraph的部署十分简单,百度汉语内部使用统一的虚拟化技术加PaaS平台直接部署。对于汉语类这种高读极低写的使用场景,为了保证业务的低耗时与高可用,我们并没有采用分布式的部署方式,而是直接采用多主的的方式进行部署,每份实例上存储全量的数据,这样可以在同机房的图数据库中快速获取数据;当然这种部署方式最大的缺点是可能存在数据不一致,为了解决这一问题,百度汉语采用数据统一干预平台来保证整个集群数据的一致性。
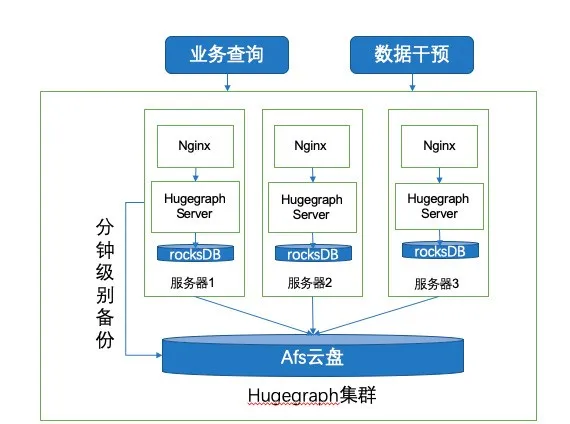
对于汉语搜索这种场景,对内容召回的耗时有着极高的要求,为了避免一些长尾耗时,我们没有将HugeGraph的接口直接对外暴露,而是在上层添加一层Nginx转发服务,主要有以下两个作用:1)灵活控制业务的超时时间,避免上层业务未主动断开造成影响 2)使用nginx proxy_cache来缓存数据,加速结果的返回。因为汉语类检索的实体内容并不多,在数据库层使用缓存,可以直接返回30%左右的热点数据。各个服务器之间通过Afs云盘实现数据文件共享。
3.2 汉语干预平台
上面介绍了百度汉语使用HugeGraph的部署方式:采用横向冗余的方式进行部署,这就对数据更新时,多个集群数据一致性提高了要求。汉语类的的一些数据错误、网络新词出现时,都需要手动更新原数据,百度汉语为了支持快速的数据干预,为此搭建了数据统一干预平台,此平台可以对线上数据进行实时干预,同时为了能够将数据进行离线分析,为此数据平台还需要支持批量数据的导入和导出。
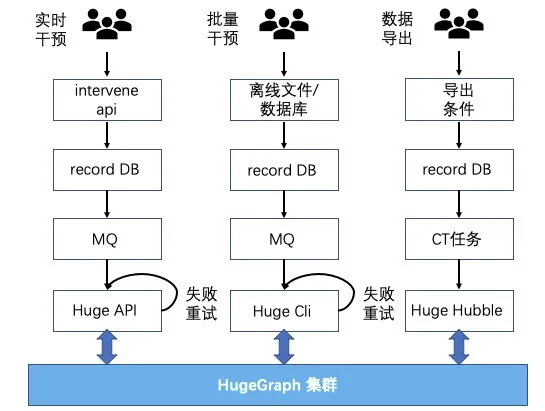
目前干预平台支持实时数据干预、批量数据干预和数据导出三种基本功能。在服务层,干预平台会记录每次的操作内容,会定期检查干预的结果是否符合预期,同时对于历史的操作能够进行数据回溯。为了保证HugeGraph集群的同时更新成功的“事务性”,这里增加了N次重试的机制,当重试仍然失败时,会主动触发报警进行人工干预。
在集群未部署前,需要我们先把数据准备好,由于百度汉语使用的是RocksDb引擎,所以我们把准备好的数据打包之后上传到Afs云盘上,当HugeGraph服务开始部署时,从Afs中拉取数据包,按照我们配置好的目录加载数据,启动HugeGraph服务。
当服务器异常的时候,需要进行迁移,我们采用的是把当前异常服务器的数据打包,上传到Afs云盘,更新备份,并且新挖掘一台新的服务器,再次从Afs拉取数据包,在此期间在干预平台中标记服务异常,在此期间,阻止数据的干预,从而保证数据的一致性。分钟级别的定时备份和服务器迁移时的更新备份已经满足汉语中的备份需要。在数据可视化上,干预平台提供了JSON化视图模式和HugeGraph-Studio Web图形化两种能力,方便运营同学快速定位数据的属性信�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%99%BE%E5%BA%A6%E6%8A%80%E6%9C%AF%E5%9B%BE%E6%95%B0%E6%8D%AE%E5%BA%93%E5%9C%A8%E7%99%BE%E5%BA%A6%E6%B1%89%E8%AF%AD%E4%B8%AD%E7%9A%84%E5%BA%94%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


